Map接口概述
java中的Map集合使用键(key)值(value)——键值对来保存数据,其中值(value)可以重复,但键(key)必须是唯一,也可以为空,但最多只能有一个key为空,它的主要实现类有HashMap、LinkedHashMap、TreeMap。
将键映射到值的对象,个映射不能包含重复的键。每个键最多只能映射到一个值。
Map接口和collection接口的不同
Map是双列的,Collection是单列的
Map的键唯一,Collection的子体系Set是唯一的。Set集合底层依赖的是Map集合
Map集台的数据结构只针对键有效,跟值无关Collection集合的数据结构是针对元素有效
Map集合的方法概述(以HashMap为例)
HashMap:底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。要保证键的唯一性,需要覆盖hashCode方法,和equals方法。
a:添加功能
V put(K key, V value):添加元素
如果键是第一次存储,就直接存储元素,返回nu11;如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值

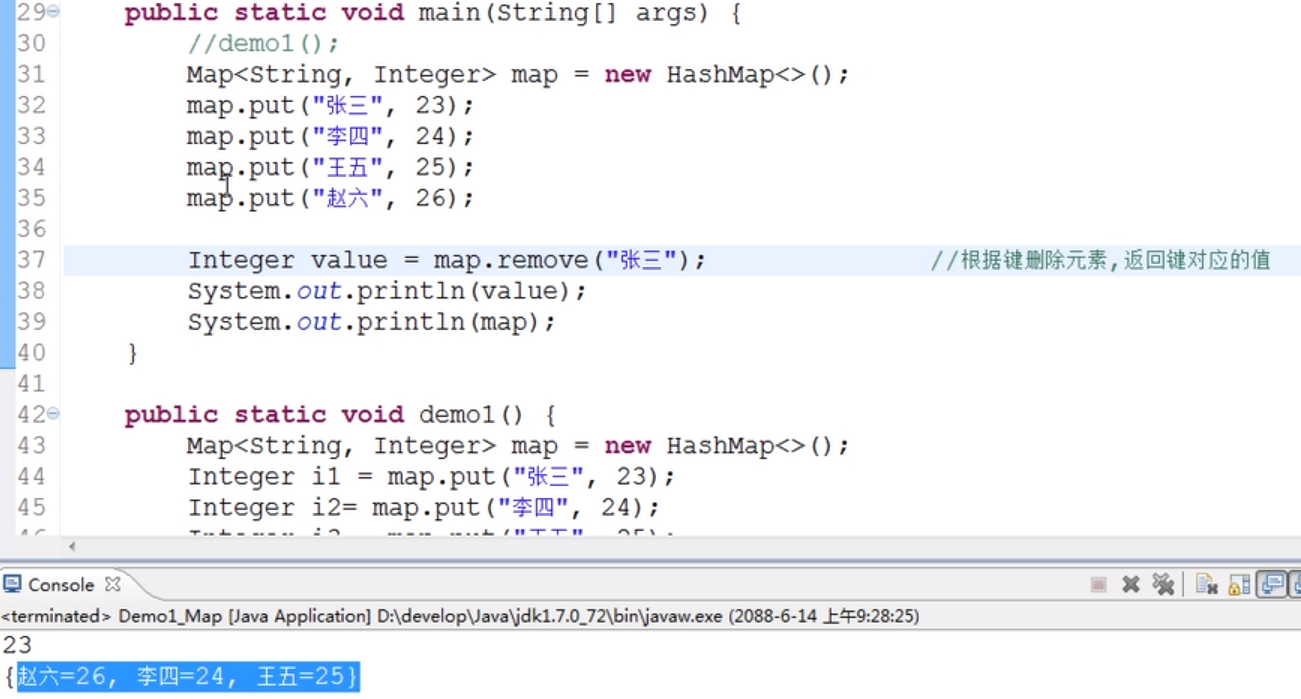
b:删除功能
void clear():移除所有的键值对元素V remove(Object key):根据键删除键值对元素,并把值返回
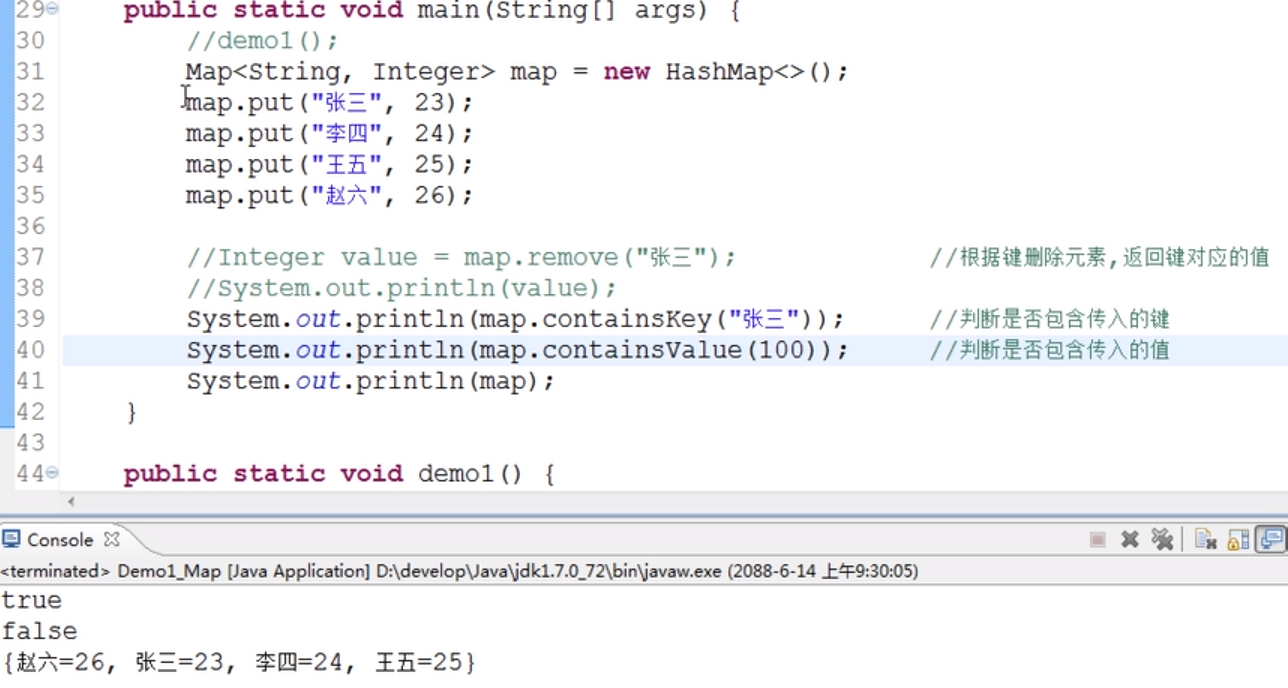
c:判断功能
boolean containsKey(Object key):判断集合是否包含指定的键boolean containsValue(Object value):判断集合是否包含指定的值
boolean isEmpty():判断集合是否为空
d:获取功能
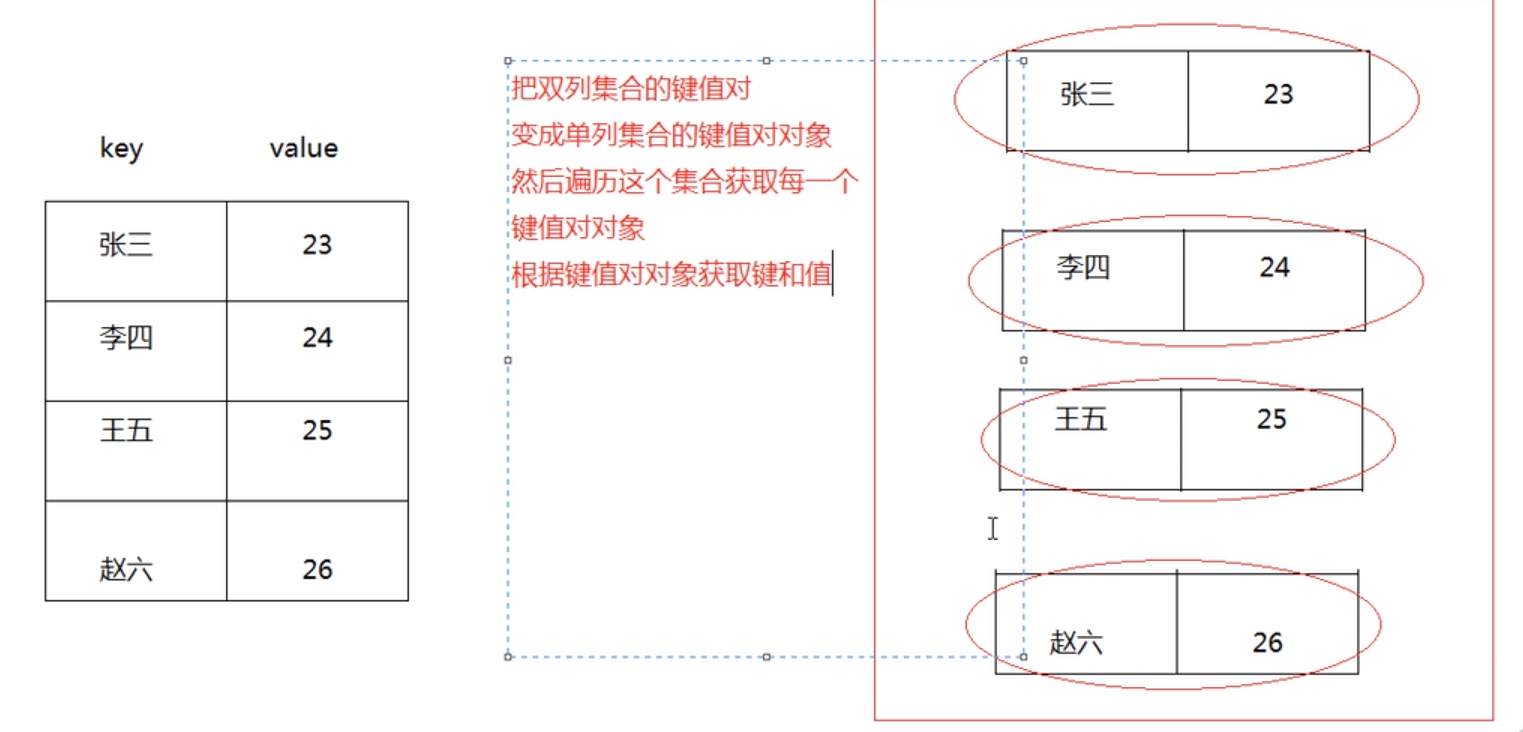
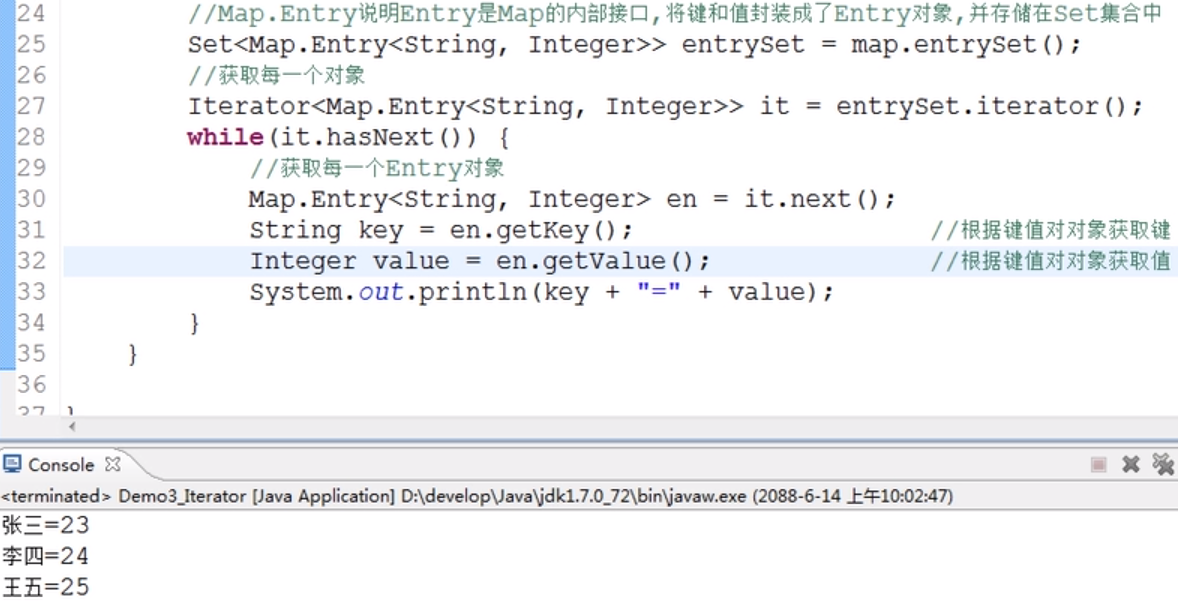
Set<Map.Entry<k, V>> entrySet():---获取所有键值对对象的集合
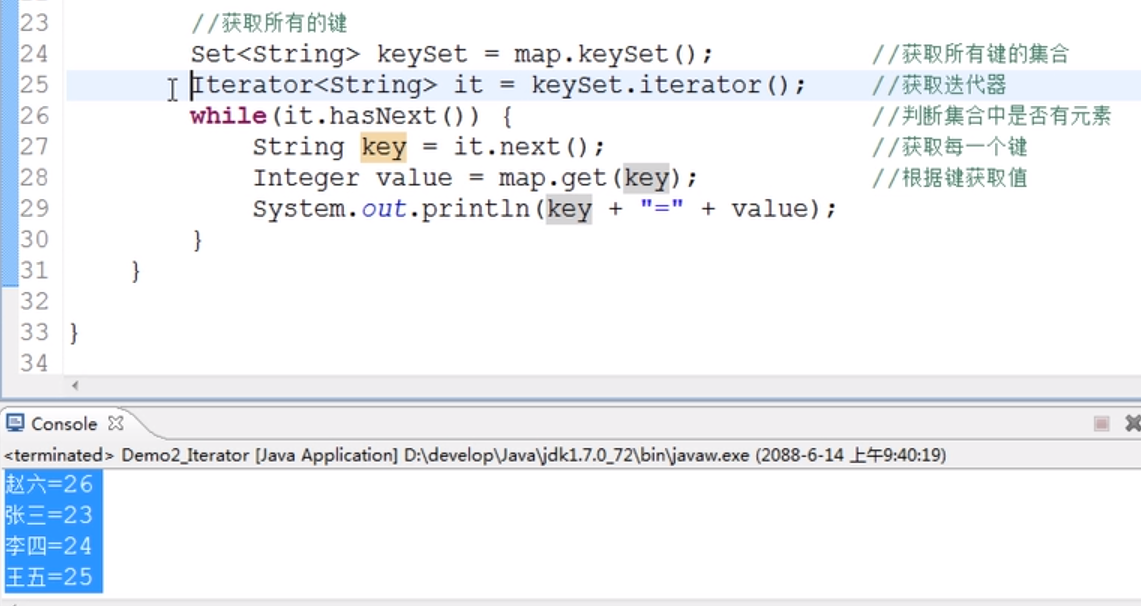
V get(Object key)----根据键获取值
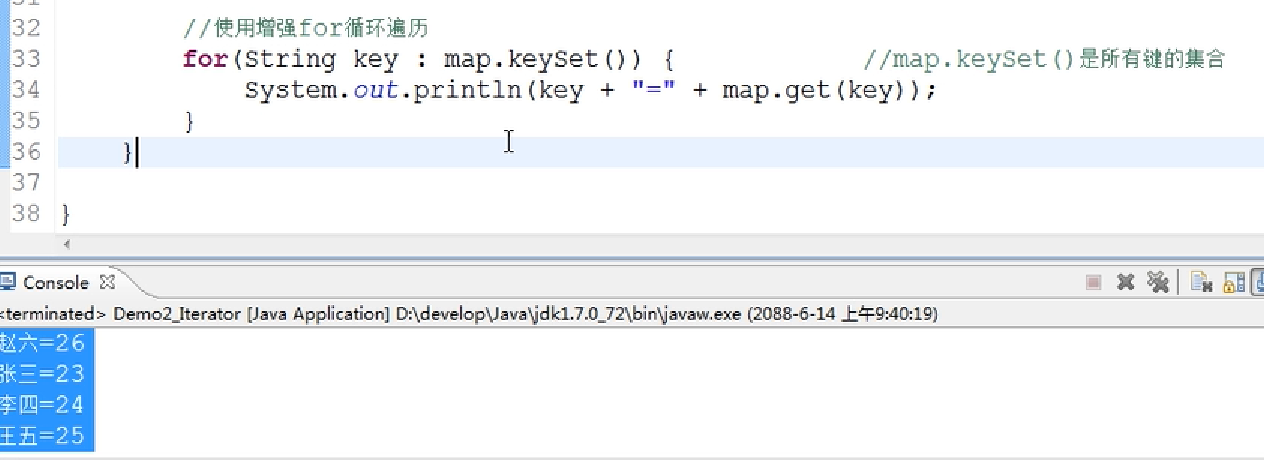
Set<K> keySet()----获取集合中所有键的集合
Collection<V> values()----获取集合中所有值的集合
Map集合中没有iterator()方法,所以Map集合不能直接迭代,需要间接的哦
方法1:
也可以用增强for循环
方法2:根据键值对对象获取键和值
用增强for循环演示

e:长度功能
int size()----返回集合中的键值对的个数
LinkedHashMap的特点:底层是链表实现的,可以保证怎么存就怎么取
TreeMap集合
TreeMap和前面学的TreeSet类似。TreeMap可以对集合中的键进行排序。
方式一:元素自身具备比较性
和TreeSet一样原理,需要让存储在键位置的对象实现Comparable接口,重写compareTo方法,让存入的元素自身具备比较性,这种方式叫做元素的自然排序也叫做默认排序。
方式二:容器具备比较性
当元素自身不具备比较性,或者自身具备的比较性不是所需要的。那么此时可以让容器自身具备。需要定义一个类实现接口Comparator,重写compare方法,并将该接口的子类实例对象作为参数传递给TreeMap集合的构造方法。
注意:当Comparable比较方式和Comparator比较方式同时存在时,以Comparator的比较方式为主;注意:在重写compareTo或者compare方法时,必须要明确比较的主要条件相等时要比较次要条件。(假设姓名和年龄一直的人为相同的人,如果想要对人按照年龄的大小来排序,如果年龄相同的人,需要如何处理?不能直接return 0,以为可能姓名不同(年龄相同姓名不同的人是不同的人)。此时就需要进行次要条件判断(需要判断姓名),只有姓名和年龄同时相等的才可以返回0.)
HashMap和Hashtable
共同点:
底层都是哈希算法,都是双列集合
区别
1.HashMap是线程不安全的,效率高,是JDK1.2版本的
Hashtable是线程安全的,效率低,是JDK1.0版本的
2.HashMap可以存储null键和null值
Hashtable不可以存储null键和nuyll值
Collections工具类
方法都是静态的,私有了构造方法---用类名.调用里面的方法
API中各个方法重载很多,作为初次入门阶段,暂时学以下常见方法
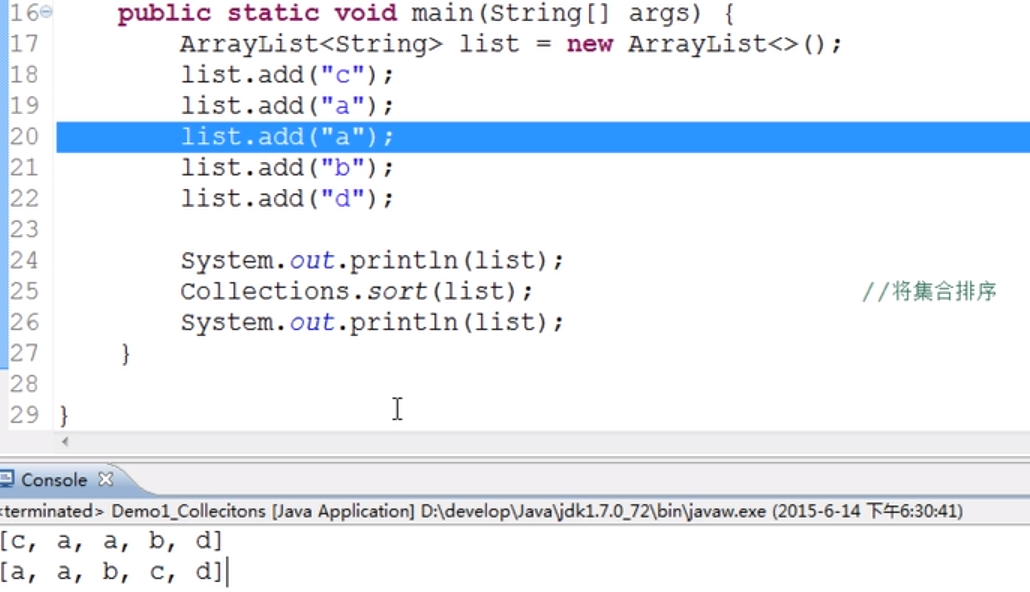
(1)public static<T> void sort(List<T> list):根据元素的自然顺序 对指定列表按升序进行排序
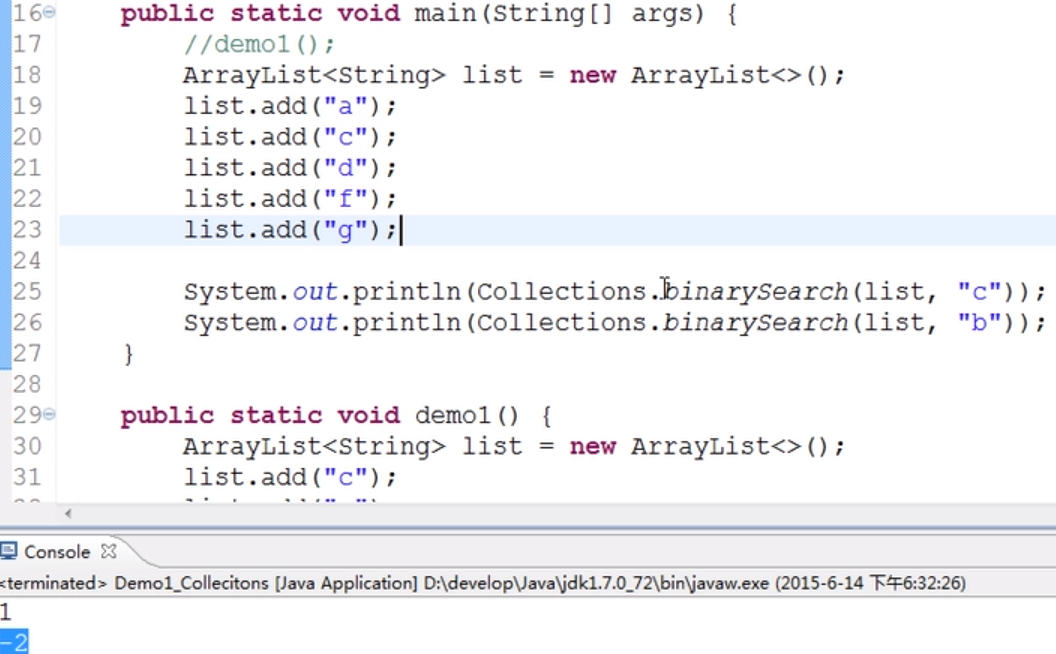
(2)public static<T> int binarySearch(List<T> list,T key):使用二分搜索法搜索指定列表,以获得指定对象在List集合中的索引。 此前必须保证List集合中的元素已经处于有序状态。
找不到元素时,会返回-(插入点)-1
(3)public static<T> T max(Collection<?> coll): 根据元素的自然顺序,返回给定collection的最大元素。
(4)public static void reverse(List<?> list): 反转列表中元素的顺序。
(5)public static void shuffle(List<?> list) : 对List集合元素进行随机排序。---类似麻将洗牌
暂时就这5个,后面学到线程的时候还要学集合关于同步控制的内容
总结:
Collection
List(存取有序,有索引,可以重复)
Arraylist
底层是数组实现的,线程不安全,查找和修改快,增和删比较慢
Linkedlist
底层是链表实现的,线程不安全,增和删比较快,查找和修改比较慢
Vector
底层是数组实现的,线程安全的,无论增删改查都慢
如果查找和修改多,用 Array1st
如果增和删多,用 Linkedlist
如果都多,用 ArrayList
Set(存取无序,无索引,不可以重复)
Hashset
底层是哈希算法实现
LinkedHashset
底层是链表实现,但是也是可以保证元素唯一,和 Hashset原理一样
Treeset
底层是二又树算法实现;一般在开发的时候不需要对存储的元素排序,所以在开发的时候大多用 Hashset, Hashset的效率比较高
Map
HashMap
底层是哈希算法,针对键
LinkedHashMap
底层是链表,针对键
TreeMap
底层是二又树算法,针对键
开发中用 HashMap比较多