前几篇已经学习了cmake 中常用的命令 command、变量 variable ,相信大家已经掌握了 cmake 工具的基本使用方法;本文我们进一步学习 cmake,看看 cmake 还有哪些东西。
定义函数
在 cmake 中我们也可以定义函数,cmake 提供了 function()命令用于定义一个函数,使用方法如下所示:
function(<name> [arg1 [arg2 [arg3 ...]]])
command1(args ...)
command2(args ...)
...
endfunction(<name>)
endfunction 括号中的可写可不写,如果写了,就必须和 function 括号中的一致。
1、基本使用方法
第一个参数 name 表示函数的名字,arg1、arg2…表示传递给函数的参数。调用函数的方法其实就跟使用命令一样,一个简单地示例如下所示:
# function 函数测试
# 函数名: xyz
function(xyz arg1 arg2)
message("${arg1} ${arg2}")
endfunction()
# 调用函数
xyz(Hello World)
打印信息如下:
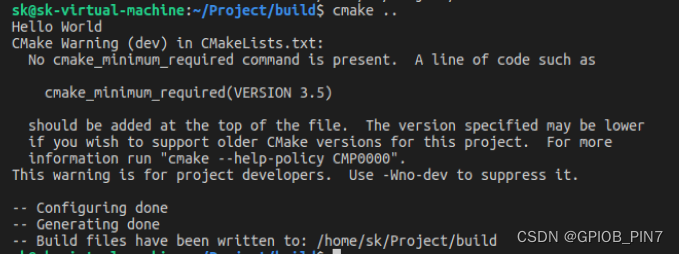
2、 使用 return()命令
在 function()函数中也可以使用 C 语言中的 return 语句退出函数,如下所示:
# function 函数测试
# 函数名: xyz
function(xyz)
message(Hello)
return() # 退出函数
message(World)
endfunction()
# 调用函数
xyz()执行结果如下:
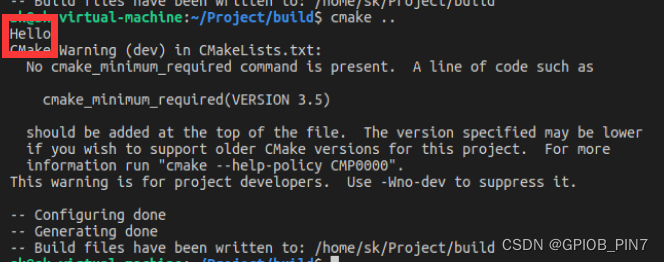
只打印了 Hello,并没有打印 World,说明 return()命令是生效的,执行 return()命令之后就已经退出当前函数了,所以并不会打印 World。
但是需要注意的是,return 并不可以用于返回参数。
3、可变参函数
在 cmake 中,调用函数时实际传入的参数个数不需要等于函数定义的参数个数(甚至函数定义时,参数个数为 0),但是实际传入的参数个数必须大于等于函数定义的参数个数,如下所示:
# function 函数测试
# 函数名: xyz
function(xyz arg1)
message(${arg1})
endfunction()
# 调用函数
xyz(Hello World China)
函数 xyz 定义时只有一个参数,但是实际调用时我们传入了 3 个参数,注意这并不会报错,是符合 function()语法规则的,会正常执行,打印信息如下:
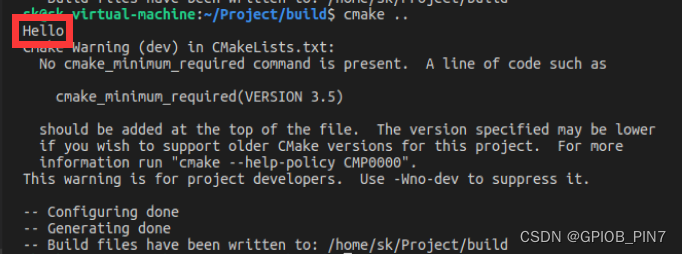
从打印信息可知,message()命令打印出了调用者传入的第一个参数,也就是 Hello。
这种设计有什么用途呢?正如我们的标题所言,这种设计可用于实现可变参函数(与 C 语言中的可变参数函数概念相同);但是有个问题,就如上例中所示,用户传入了 3 个参数,但是函数定义时并没有定义这些形参,函数中如何引用到第二个参数 World 以及第三个参数 China 呢?其实 cmake 早就为大家考虑到了,并给出了相应的解决方案,就是接下来向大家介绍的内部变量。
4、函数的内部变量
function()函数中可以使用内部变量,所谓函数的内部变量,指的就是在函数内部使用的内置变量,这些内部变量如下所示:
| 函数中的内部变量 | 说明 |
| ARGVX | X 是一个数字,譬如 ARGV0、ARGV1、ARGV2、ARGV3…,这些变量表示函数的参数,ARGV0 为第一个参数、ARGV1 位第二个参数,依次类推! |
| ARGV | 实际调用时传入的参数会存放在 ARGV 变量中(如果是多个参数,那它就是一个参数列表) |
| ARGN | 假如定义函数时参数为 2 个,实际调用时传入了 4 个,则 ARGN 存放了剩下的 2 个参数(如果是多个参数,那它也是一个参数列表) |
| ARGC | 调用函数时,实际传入的参数个数 |
试验一下:
# function 函数测试
# 函数名: xyz
function(xyz arg1 arg2)
message("ARGC: ${ARGC}")
message("ARGV: ${ARGV}")
message("ARGN: ${ARGN}")
message("ARGV0: ${ARGV0}")
message("ARGV1: ${ARGV1}")
# 循环打印出各个参数
set(i 0)
foreach(loop ${ARGV})
message("arg${i}: " ${loop})
math(EXPR i "${i} + 1")
endforeach()
endfunction()
# 调用函数
xyz(A B C D E F G)执行结果如下“
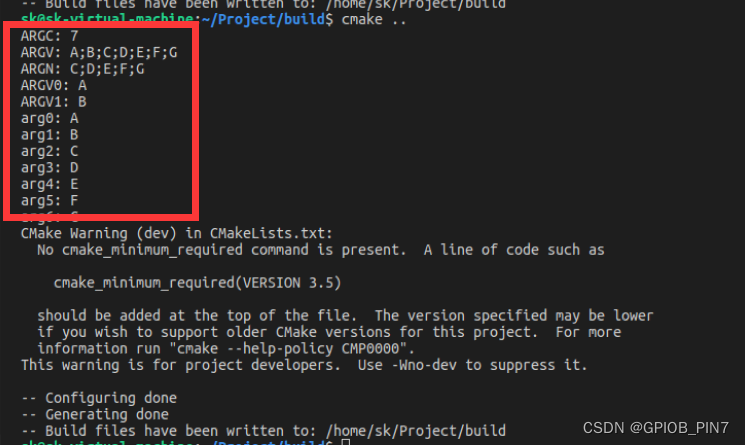
5、函数的作用域
在 cmake 中,通过 function()命令定义的函数类似于一个自定义命令(实际上并不是),当然,事实上,cmake 提供了自定义命令的方式,譬如通过 add_custom_command()来实现,如果大家有兴趣,可以自己去学习下,笔者便不再进行介绍了。 使用 function()定义的函数,我们需要对它的使用范围进行一个简单地了解,譬如有如下工程目录结构:
├── build
├── CMakeLists.txt
├── hello
├── CMakeLists.txt我们在顶层目录下定义了一个函数 xyz,顶层 CMakeLists.txt 源码内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0)
# 函数名: xyz
function(xyz)
message("Hello World!")
endfunction()
# 加载子源码
add_subdirectory(hello)
接着我们在子源码中调用 xyz()函数,hello 目录下的 CMakeLists.txt 如下所示:
# hello 目录下的 CMakeLists.txt
message("这是子源码")
xyz() # 调用 xyz()函数
大家觉得这样子可以调用成功吗?事实上,这是没问题的,父源码中定义的函数、在子源码中是可以调用的,打印信息如下:
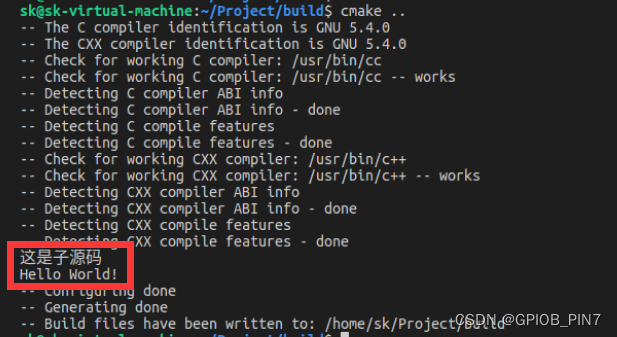
那反过来,子源码中定义的函数,在父源码中可以使用吗?我们来进行测试,顶层 CMakeLists.txt 源码内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 加载子源码
add_subdirectory(hello)
message("这是父源码")
xyz()
在父源码中调用 xyz()函数,在子源码中定义 xyz()函数,如下所示:
message("这是子源码")
# 函数名: xyz
function(xyz)
message("Hello World!")
endfunction()进入到 build 目录执行 cmake,如下所示:
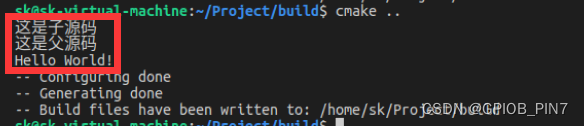
事实证明,这样也是可以的,说明通过 function()定义的函数它的使用范围是全局的,并不局限于当前源码、可以在其子源码或者父源码中被使用。