一、total loss与val loss
loss:训练集整体的损失值。
val loss:验证集(测试集)整体的损失值。
我们在训练的一个模型的时候,我们都会把一个样本划分成训练集、验证集。一般来说,我们按照 训练集:验证集==9:1 来划分,那么当我们在训练模型计算出来的loss值就会分为:
训练集总体total loss 和 测试集val loss。两者之间有大致如下的关系:
当loss下降,val_loss下降:训练正常,最好情况。
当loss下降,val_loss稳定:网络过拟合化。这时候可以添加Dropout和Max pooling。
当loss稳定,val_loss下降:说明数据集有严重问题,可以查看标签文件是否有注释错误,或者是数据集质量太差。建议重新选择。
当loss稳定,val_loss稳定:学习过程遇到瓶颈,需要减小学习率(自适应网络效果不大)或batch数量。
当loss上升,val_loss上升:网络结构设计问题,训练超参数设置不当,数据集需要清洗等问题,最差情况。二、实际验证:
因为自己制作数据集少(只有30张训练集和10张验证集),目前没有gpu因此epoch只设置了10. 所以收敛效果不好,但是可以说明情况。
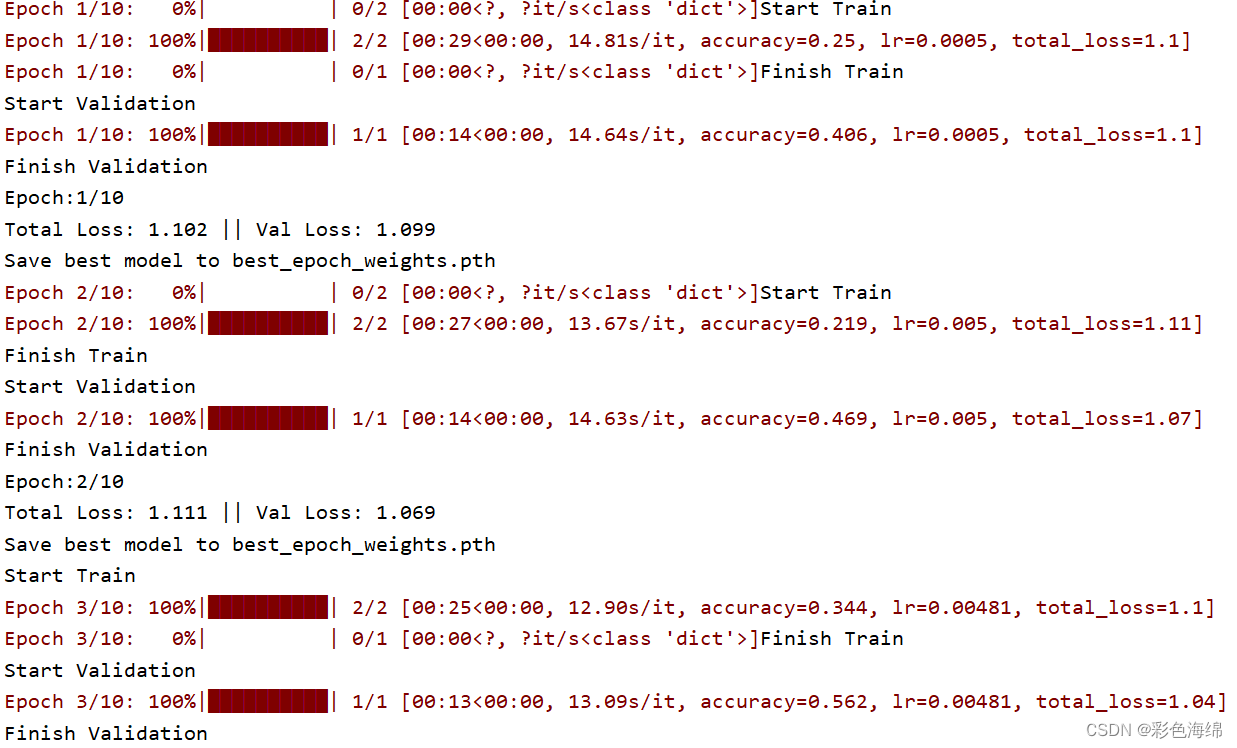


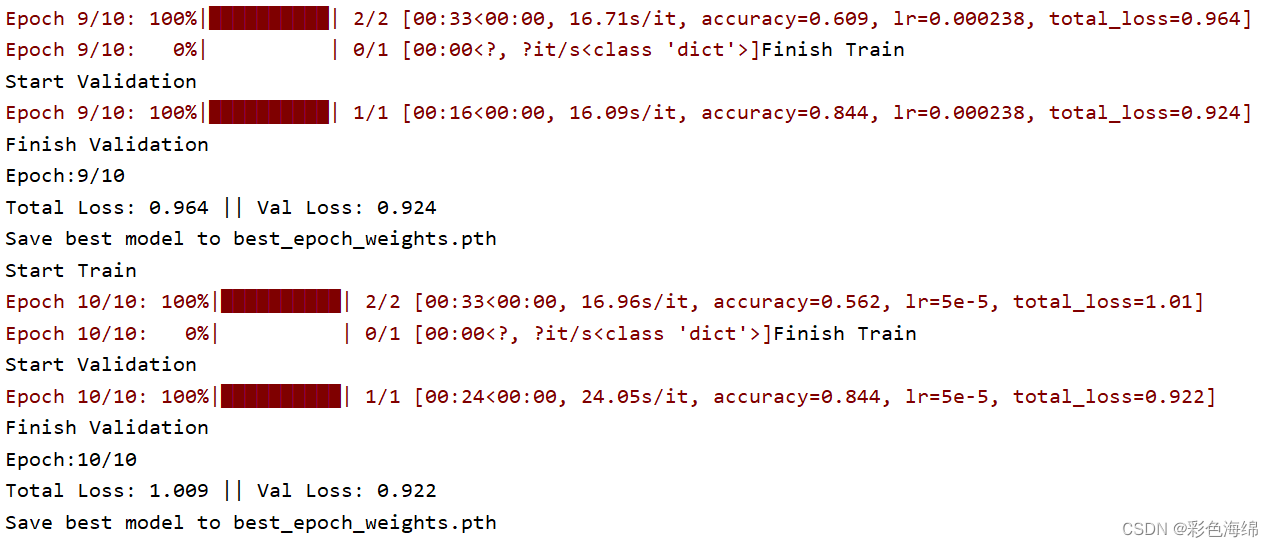 三、还有使用预训练权重和不使用区别:
三、还有使用预训练权重和不使用区别:
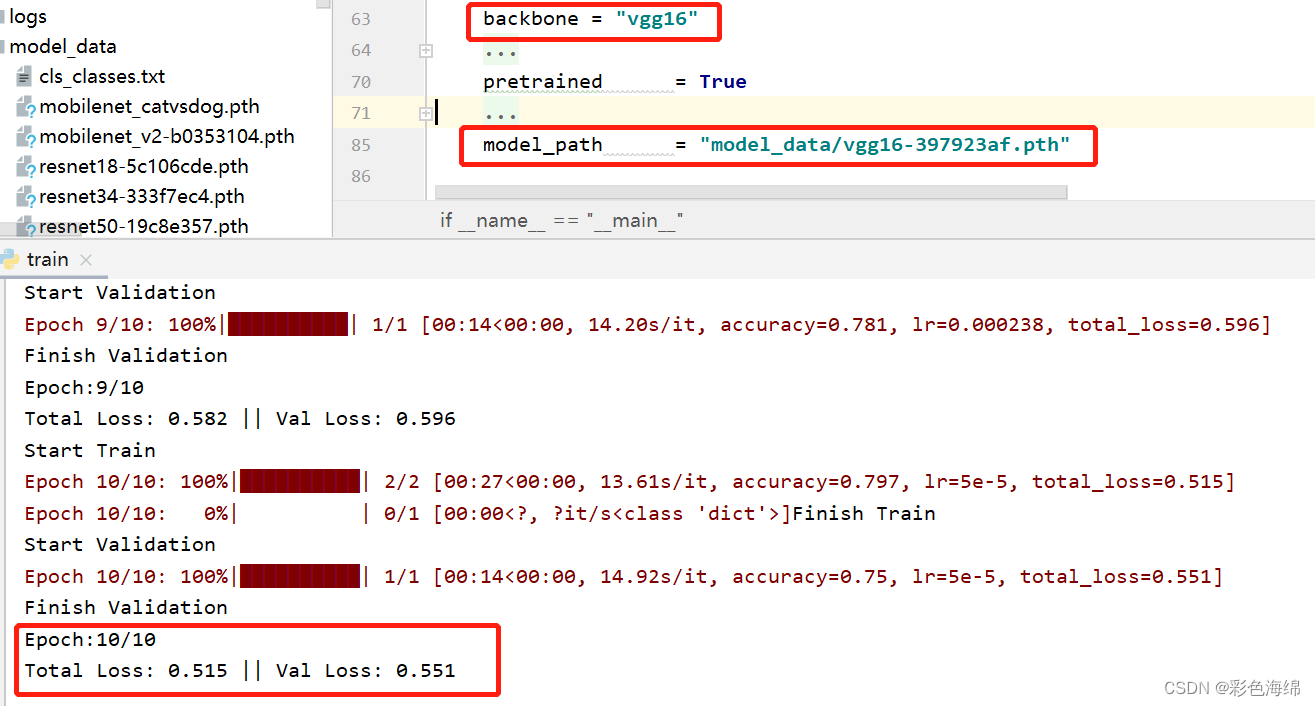
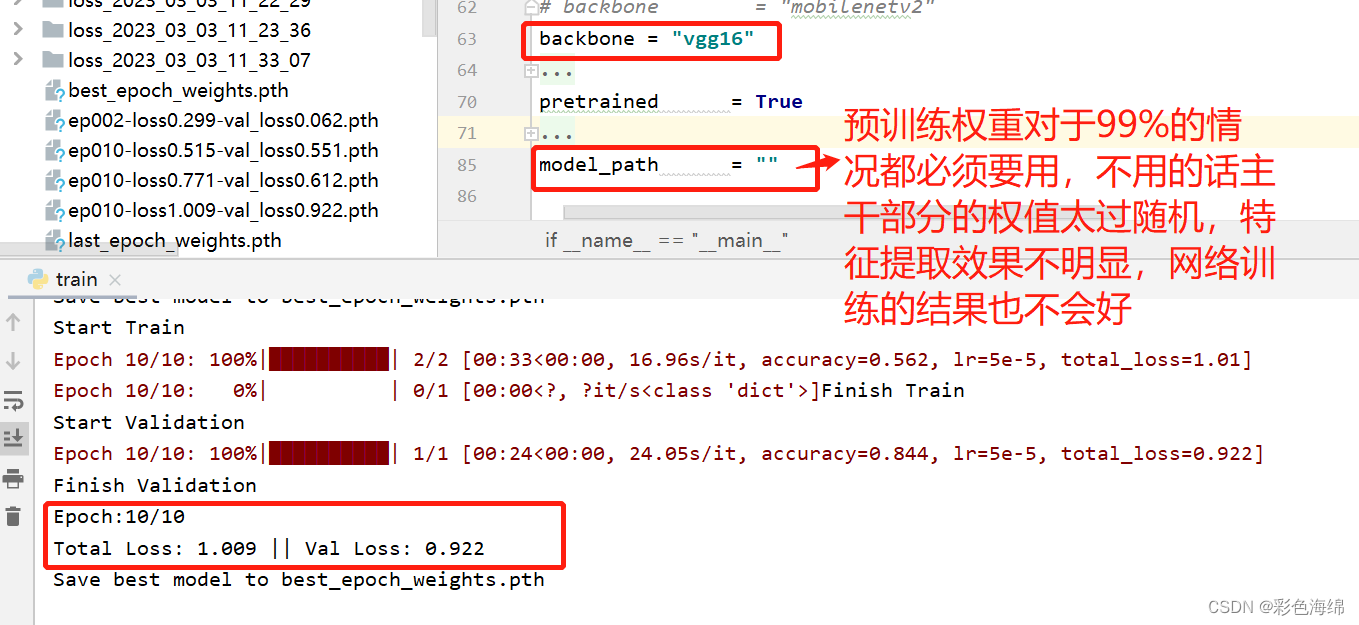
四、损失函数:L1 loss, L2 loss, smooth L1 loss
L2-loss收敛速度比L1-loss快得多,缺点是当存在离群点(outliers)的时候,这些点会占loss的主要组成部分。
smooth L1:稍微缓和一点绝对损失函数(损失),它是随着误差线性增长,而不是平方增长。
smooth L1和L1-loss函数的区别在于,L1-loss在0点处导数不唯一,可能影响收敛。smooth L1的解决办法是在0点附近使用平方函数使得它更加平滑。

"L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet."
也就是smooth L1 loss让loss对于离群点更加鲁棒,即:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。