需求
给出起始时间和终止时间,从routeview网站上,下载在这两者之间的所有数据到本机,以便于进行后续的分析工作。
例如:2022.2.23 - 2022.2.26
主要流程
主流程在遍历每个月中实现
- 当月份小于10时,前面加‘0’,对齐格式
- 拼接带点的字符串,构成所指向的第三级网址
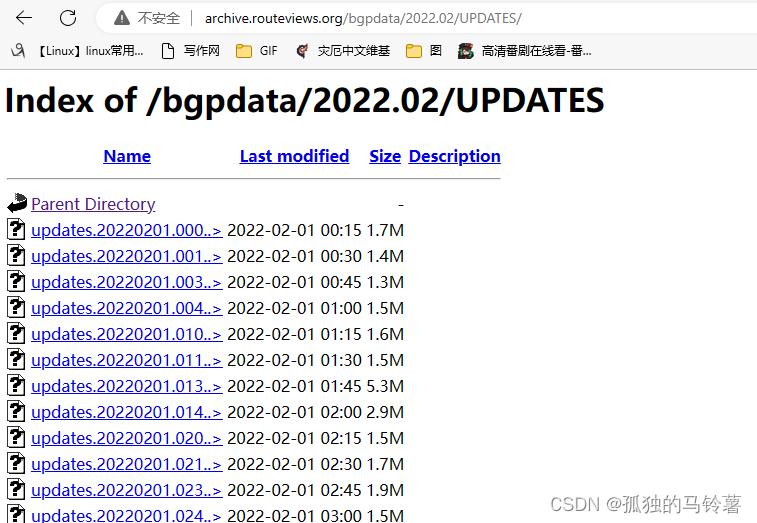
- 访问对应月份的网页,下载其html,其中包含了每个文件的文件名
- 遍历该月中,所要求的日期,同样对齐一下格式
- 构造应该命令行管道,对html进行字符匹配,获得每个文件的名称,输出到对应文件中
*grep -o "updates.bz2"" indexfiles/updates.$ymdot.html 命令的作用是:
在文件 indexfiles/updates.$ymdot.html 中查找以 “updates” 开头,以 “.bz2” 结尾的字符串,并输出到标准输出。
其中,-o 选项表示只输出匹配的部分,不包括前后的内容。\ 用于转义双引号,防止其被解释为结束符。$ymdot 是一个变量,用于表示文件名中的日期部分,例如 “updates.20230619.html”。tr -d ‘"’ 命令的作用是:将标准输入中的双引号字符删除,并输出结果到标准输出中。其中,-d 选项表示删除指定的字符。这个命令的作用是将前一个 grep 命令输出的结果中的双引号字符删除。
> 是命令行重定向符号,将前一个命令输出的结果保存到指定的文件中,覆盖原有内容(如果文件已经存在),或者创建一个新文件并写入数据(如果文件不存在)。
在这个例子中,indexfiles/filelist.updates.$ymdot 文件将会存储上述命令的最终输出结果。
综上所述,这个命令行管道的作用是在指定的 HTML 文件中查找以 “updates” 开头、以 “.bz2” 结尾的字符串,并删除其中的双引号字符,然后将结果输出到指定的文件 (indexfiles/filelist.updates.$ymdot) 中。最终实现的效果是,生成一个不带双引号的文件列表,其中包含了所有以 “updates” 开头、以 “.bz2” 结尾的字符串。
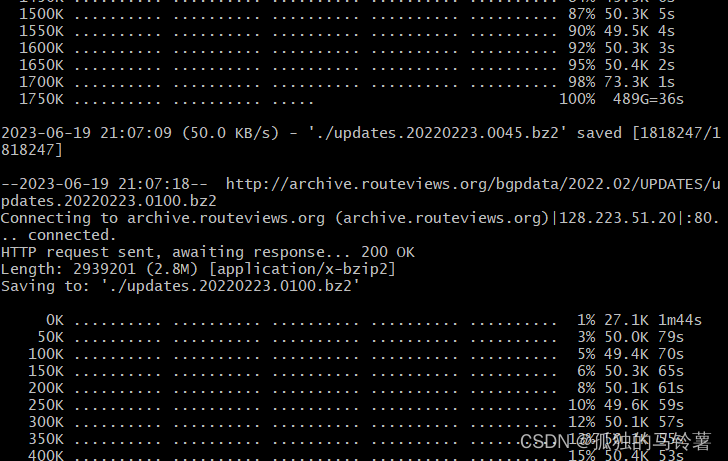
- 按照生成的文件列表,依次下载对应的BGP更新数据包
wget命令作用:
- -B http://archive.routeviews.org/bgpdata/$ymdot/UPDATES/ :设置 URL 的前缀,即下载的文件路径为 http://archive.routeviews.org/bgpdata/$ymdot/UPDATES/ 下的文件。
- –limit-rate=50k :限制下载速率为 50KB/s,以防止过多占用网络资源
- -w 10 :等待下载时间,即在两次下载之间等待 10 秒,避免下载过于频繁导致服务器拒绝连接。
- –random-wait :随机等待时间,更加真实地模拟人工下载。
- -N :只下载更新过的文件,不重新下载已经存在的文件。
- -P ./ :将文件保存在当前脚本所在文件夹内
- -i indexfiles/filelist.updates. y m d o t :从名为 i n d e x f i l e s / f i l e l i s t . u p d a t e s . ymdot :从名为 indexfiles/filelist.updates. ymdot:从名为indexfiles/filelist.updates.ymdot 的文件中读取要下载的文件列表。
代码
yearb=2022
yeare=2022
monthb=2
monthe=2
dayb=22
daye=23
for year in $(seq $yearb $yeare)
do
for month in $(seq $monthb $monthe)
do
ymdot='' # 带点的年月,访问网址(archive.routeviews.org/bgpdata/2003.02/UPDATES/)需要
ym='' # 不带点的年月,下载文件时,文件名不带点
if [ $month -lt 10 ]
then
ymdot=$year'.0'$month
ym=$year'0'$month
echo $ym
else
ymdot=$year'.'$month
ym=$year$month
echo $ym
fi
# 直接将文件页面的html下载下来
if [ ! -f indexfiles/updates.$ymdot.html ];
then
echo "Downloading index of updates"
mkdir indexfiles
# using http
wget -O indexfiles/updates.$ymdot.html http://archive.routeviews.org/bgpdata/$ymdot/UPDATES/
# using ftp
# wget -O indexfiles/updates.$ymdot.html ftp://archive.routeviews.org/route-views2/$ymdot/UPDATES/
fi
# 由于 > 是命令行重定向符号,将前一个命令输出的结果保存到指定的文件中,覆盖原有内容(如果文件已经存在)
# 因此对于一天的文件,应该通过管道筛选后,马上下载,即 循环中应该是 管道筛选+下载
for day in $(seq $dayb $daye)
do
if [ $day -lt 10 ]
then
ymd=$ym'0'$day
echo $ymd
else
ymd=$ym$day
echo $ymd
fi
# Extract the list of "updates" files and save it to another file
if [ ! -f indexfiles/filelist.updates.$ymd ];
then
echo "Creating list of updates"
grep -o "updates.$ymd.*bz2\"" indexfiles/updates.$ymdot.html | tr -d '\"' > indexfiles/filelist.updates.$ymd
fi
# Download the updates files from filelist, ignore already downloaded files
wget -B http://archive.routeviews.org/bgpdata/$ymdot/UPDATES/ --limit-rate=50k -w 10 --random-wait -N -P ./ -i indexfiles/filelist.updates.$ymd
done
done
done
最终效果