前言
这两个月开始学习深度学习与计算机视觉,从懵懵懂懂到初入门槛,从完全不懂科研的小白到复现第一篇论文(2023.4.1日完成MobileNet复现与Resnet复现)虽然磕磕绊绊,也算收获良多,在这里记录一下个人的学习历程与对CV领域的认知,希望对初学者有帮助
因为本人不是大佬,也没有牛导带,自己从小白到入门,从只知道学习的本科生变成有一定基本学术素养的本科生,我相信我的经历会帮助到很多人,因为多数人就跟我一样,没什么平台,也没什么好老师指导,或者老师直接放养
个人认为,这个笔记适合未来致力于计算机视觉领域学术研究的同学,因为本人更喜欢从基础开始,循序渐进的学习,然后搞清楚细节,而不是直接去看最前沿的论文(水平有限看不懂),所以不适合想快速发论文的同学
基础
想要进行学术研究,必须要有基础,我自己最开始看的是李宏毅和李沐的课程,尤其是李沐的课程给我们打下了很好的基础(虽然感觉李沐的课程细节上处理的不是特别好,但是其框架和实践部分非常nice),尤其是其对PyTorch的使用,让人可以对框架有一个清晰的认知,个人建议看先看李宏毅的理论(李宏毅对理论方面的讲解很细),然后去看李沐的(介绍框架和实践),个人感觉这样子是比较好的,然后一定要动手实践,同时还可以搭配河工大刘二老师的课程,可以对PyTorch工具的一些内部原理(如前向推理和反向传播)过程有一个更好的了解,刘二老师的课程链接如下
PyTorch实践深度学习
其实只看这些课程个人感觉是不够的,建议以后补充很多理论基础(如详细学完机器学习理论、模式识别、优化理论等),但是在基础阶段,看李宏毅与李牧的课程并且学习PyTorch就足够了,循序渐进的学,然后从基础论文看起,这样我感觉是一个很好的道路,当然那种大佬可以直接看最前沿的论文
第一篇论文:学术的开始
个人感觉学完李沐和李宏毅中基础的CNN部分就可以开始看基础论文了,这样容易理解,不然没有基础直接看论文容易懵圈;看完论文后手动进行复现,这样才可以对论文有一个更清晰的架构上的认知,同时也增强了动手能力,当然也建议在某些数据集上进行测试,当做练手(如果自己的电脑GPU不好,同时也没有GPU资源的话,就跑小数据集即可)
老师给我的第一篇论文是经典的VGG和Resnet(实际上第一次就给了两篇),因为AlexNet的结构相对简单,并且还是第一篇论文,奠定了现在深度学习在计算机视觉中的基础,课程和相关书籍中就会介绍,所以直接看VGG这些即可(当然也可以搜一下AlexNet这个开山之作,我这里给一下原版论文链接)
AlexNet
VGG
Resnet
可以直接下载PDF进行阅读
因为个人感觉课程和书籍上的内容是总结了2012年之前的情况(2012年是现代计算机视觉元年了算,深度神经网络在图像分类上的巨大进步掀起了热潮),至于2012年后的进展书上并没有提及过多(比如说Resnet,MobileNet等),所以后面的内容都需要大家自行学习,当然B站上也有很多公开课可以看,如up同济子豪兄的论文精讲课程,深度之眼的论文系列课程,都有公开课(好像资料要收费,不过不是很贵,我花几十块钱买了一份)
科研工具
工欲善其事必先利其器,想做好学术,就得有趁手工具,尤其是做人工智能领域的科研,工具就更为重要,接下来我给大家介绍一些工具
论文阅读工具
我这里使用的是Zotero,这个的好处在于可以集成到谷歌浏览器里面并且可以完成云端论文同步,在网页上阅读论文的时候,可以通过插件直接将论文上传到云端
这是我在谷歌浏览器中找到的论文,可以直接一键导入Zotero,同时Zotero中也可以进行各种分类,做笔记也可以(虽然感觉做笔记的方式有点单一)

上网
科学或者不科学的魔法上网?这里不多说
多维数据与多维数组
在这里,我讲一下我在实践过程中的一些感想
数据的重要性
人工智能的原理是从数据中学习,人的学习也是如此,那么想让人工智能有智能,那么必须准备好优质数据,这类似于人想学会某种能力,要学习理论然后进行实践,并且要进行训练,比如说一个学生想学会一种数学题(类似于人工智能实现某种功能),就要学习相关的数学理论并且做很多练习题,人工智能训练的过程也类似这样。
也就是说,数据对于人工智能来说,是非常重要的部分,没有优质数据,人工智能也就不再智能,好比一个人想学数学,但是没有书没有习题,那么即便他再天才也无法学会这些数学。
图像数据的形式
因为我只做过计算机视觉方面的工作,对NLP并不了解,所以我接下来的例子都会以CV方面为例进行说明。
我们想让人工智能实现智能,就必须让其从数据中进行学习,但是想从数据中学习,那么数据就应该是有一定规范的,不然一堆奇奇怪怪互不相同的数据,自然无法成为训练人工智能的养料,所以我们在这里先说明一下数据的形式。
先举一些例子,大家应该了解过照片或者图像的形式,有三通道(三原色),还有高和宽,为了方便说明,我们从简单的黑白照片开始说明。

这是一个很典型的黑白照片(也叫灰度图像),我们先假设它的分辨率是1920*1080,那么也就是说,有1920列像素点和1080行像素点,每个像素点由一个数字来代表他的灰度值(gray scale),取值0~255。 黑色是0,白色是255。那么我们想一想,我们应该用什么来表示这么一张黑白图片?大家是不是想到矩阵,我们可以设置一个1920*1080大小的矩阵来表示这个图片,或者一个二维数组来表示这个图片。
那么大家想一想,二维数组为什么叫二维数组呢?是不是因为其有两个维度呢?如果我们想读取到其存储的最小数据单元,就得在两个维度上声明我们想读取的元素的位置;比如说我们想读取上面那个黑白图片第100行第200列的像素点,那么我们就在高这个维度上数上100个,到第100行,然后在宽这个维度上数上200个,来到第200列,然后就可以找到我们想要的数据点了。
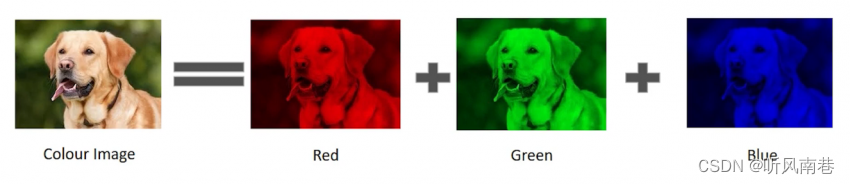
这是简单的黑白图像,如果是彩色图像,会有三个不同的通道,可以理解为三个不同颜色的灰度图像叠加在一起(三原色可以组合为任何颜色),这样就可以组成一个彩色图片了,那么我们这时候怎么表示这个图像呢?答案是用三个二维数组分别表示一个通道,然后将三个二维数组有序排列起来,做成一个三维数组。
实际上,任何一个一维及以上的数组,都是由相同属性和形状的元素有序排列组成的,比如说一个一维整数数组是由若干个整数有序排列组成,一个二维整数数组是由若干个等长的一维整数数组组成,多维数组同理。
理解多维数据的概念
大家可能在PyTorch中看到张量的概念有一些茫然,不知道张量和多维数组是什么概念,实际上多维数组和张量是差不多的概念,就是数据有序排列的对象,比如说之前说过的二维数组可以表示黑白图像,一个黑白图像就是一堆像素点在高和宽两个维度上有序排列的结果,一张彩色图片就是一堆像素点在高、宽、通道三个维度上有序排列的结果,如果再进行扩展,比如说一个视频,那么就是在彩色图片上添加了一个时间维度:彩色图片在时间维度上有序排列,可以用一个四维数组表示。
说到这里,大家可能对维度这个概念有所了解了,在我的认知中,维度就是属性的同义词,只不过维度一般指的是这个维度上有很多样本,比如说一个视频,在时间维度上有很多彩色照片,如果只有一张,那么就显得这个时间维度有点多余(当然有一个维度但是这个维度上只有一个样本和没有这个维度是有区别的,因为一个视频里面的一帧图片是有四个属性的,高宽、通道和时间,一个普通的彩色图片没有时间这个维度)。
说到这里,大家可能明白张量是干什么的了,PyTorch中的张量其实就是一种特殊的可以各种操作的多维数组,可以完成一系列的操作
PyTorch框架
大家都知道,人工智能的目的是为了让计算机具备智能,但是我们如果只有一些数学理论,自然无法让计算机实现智能,计算机目前只能运行程序来处理数据,所以我们要做的,就是基于数学原理等,设计程序,然后让计算机具备智能(实际上的过程比这个复杂很多,这里只是一种简化版的说法)。
那么,我们怎么让计算机具备智能呢?自己打造这个程序吗?实际上这是不可能的,这种程序太复杂太庞大了,个人的能力无法维护一个这种程序,所以为了方便人工智能开发者进行程序设计,各种开源框架闪亮登场,诸如PyTorch、TensorFlow等,各有长处,在这里我们使用PyTorch框架,至于为什么这么选择,我们后面会说。
框架的作用
大家小时候应该都玩过搭积木,或者拼装乐高这种,大家应该对其流程有印象:如果想搭建一个很大的城堡或者拼装一个很大的机器人,那么就需要使用最基础的零件,照着说明书或者自行设计,一步步搭建,哪个地方出错,就很容易影响后面的效果,甚至导致无法完成。
如果,我们有这么一些神奇的零件(我们不讨论为什么会有这种神奇零件):可以直接生成一些房屋模块和机器人模块,并且可以进行一些修改,我们是不是可以大大简化这个搭建过程?我们原先想搭建一个城堡,需要动手搭建几百块零件,我们有了这种神奇零件之后,我们只需要生成十几个房屋模块就可以完成,然后将一些模块按照我们的想法直接设置形状(不需要我们花太多精力),那么我们很轻松就可以搭建出我们自己的城堡,而且基本上不会出错。
实际上,我们训练人工智能的过程就是一个搭建城堡的过程,我们自己造一套程序的过程就是那个自己用最基础的零件一步步搭建的过程,容易出错而且工作量大,如果我们使用神奇零件,很轻松就可以完成,并且不容易出错,而框架就可以提供很多这种神奇框架,这也就是框架的功能,给我们提供简单易用的函数等模块,让我们可以轻松完成人工智能的训练过程,并且易于修改
为什么选择PyTorch
框架有很多,但是为什么我们独自选择PyTorch呢?
第一,PyTorch具有简单易用的特点,对新手友好,容易上手
第二,PyTorch是动态的图,方便人工智能程序的修改,在初学阶段很方便
第三,在科研领域,PyTorch是主流框架,方便大家走科研道路,如果想走工程方向,后面转其他框架也容易
第四,PyTorch的函数等API做的很好,不同版本的PyTorch的API兼容性很强,不像TensorFlow,TensorFlow的API非常混乱,版本稍有不同可能就会出现模块未定义的问题,这对初学者是很致命的,尽管TF(TensorFlow简写)在工程落地方面使用广泛,但是我们并不建议初学者使用
#未完待续