and most experienced employees are leaving prematurely. The company also wishes to
predict which valuable employees will leave next.
案例说明:
本次案例需要的包包括:
library(plyr) # Rmisc的关联包,若同时需要加载dplyr包,必须先加载plyr包
library(dplyr) # filter()
library(ggplot2) # ggplot()
library(DT) # datatable() 建立交互式数据表
library(caret) # createDataPartition() 分层抽样函数
library(rpart) # rpart()
library(e1071) # naiveBayes()
library(pROC) # roc()
library(Rmisc) # multiplot() 分割绘图区域
数据分析基本步骤:
(1)业务理解;(2)明确业务需求(需求分析);(3)数据获取;(4)数据理解
(5)数据探索分析(数据的描述性分析);(6)数据预处理;(7)建模预测;(8)模型评估与应用
1、业务背景:我们所关心的问题是,为什么一些大的公司里,他们最优秀最有经验的员工会过早的离职?公司希望能够预测这些最有价值的员工接下来是否会离职。
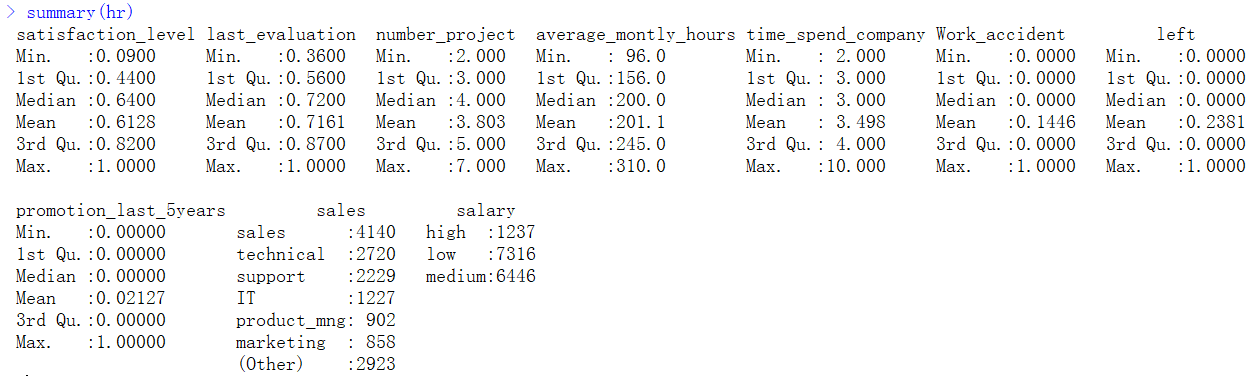
2、数据理解:我们使用的数据是CSV数据文件格式,其中自变量9个,因变量为是否离职。下表对所有变量进行了说明,以便更好的理解数据。

3、数据探索分析:上表备注中的结果是如何得到的?这就是数据探索性分析。以下是对原始数据进行数据探索分析的过程。
(1)观察各个变量的数据结构及主要描述统计量。
hr <- read.csv("E:\\HR_comma_sep.csv")
str(hr)
summary(hr)
a. str(hr)用来查看各个变量的数据结构

b. summary(hr)来查看各个变量的主要描述统计量
(2)探索员工对公司满意度、绩效评估和月均工作时长和工作年限与是否离职的关系,并绘制箱线图。
后续我们会用到决策树模型及朴素贝叶斯模型进行预测,模型要求目标变量必须为因子型(分类变量),而我们的数据中,目标变量left为int型,所以,首先我们将其数据类型转化为因子型。
hr$left<-factor(hr$left,levels = c("0","1"))
a. 探索员工对公司满意度与是否离职的关系
# 绘制对公司满意度与是否离职的箱线图
box_sat <- ggplot(hr, aes(x = left, y = satisfaction_level, fill = left)) +
geom_boxplot() +
theme_bw() + # 一种ggplot的主题
labs(x = 'left', y = 'satisfaction_level') # 设置横纵坐标标签
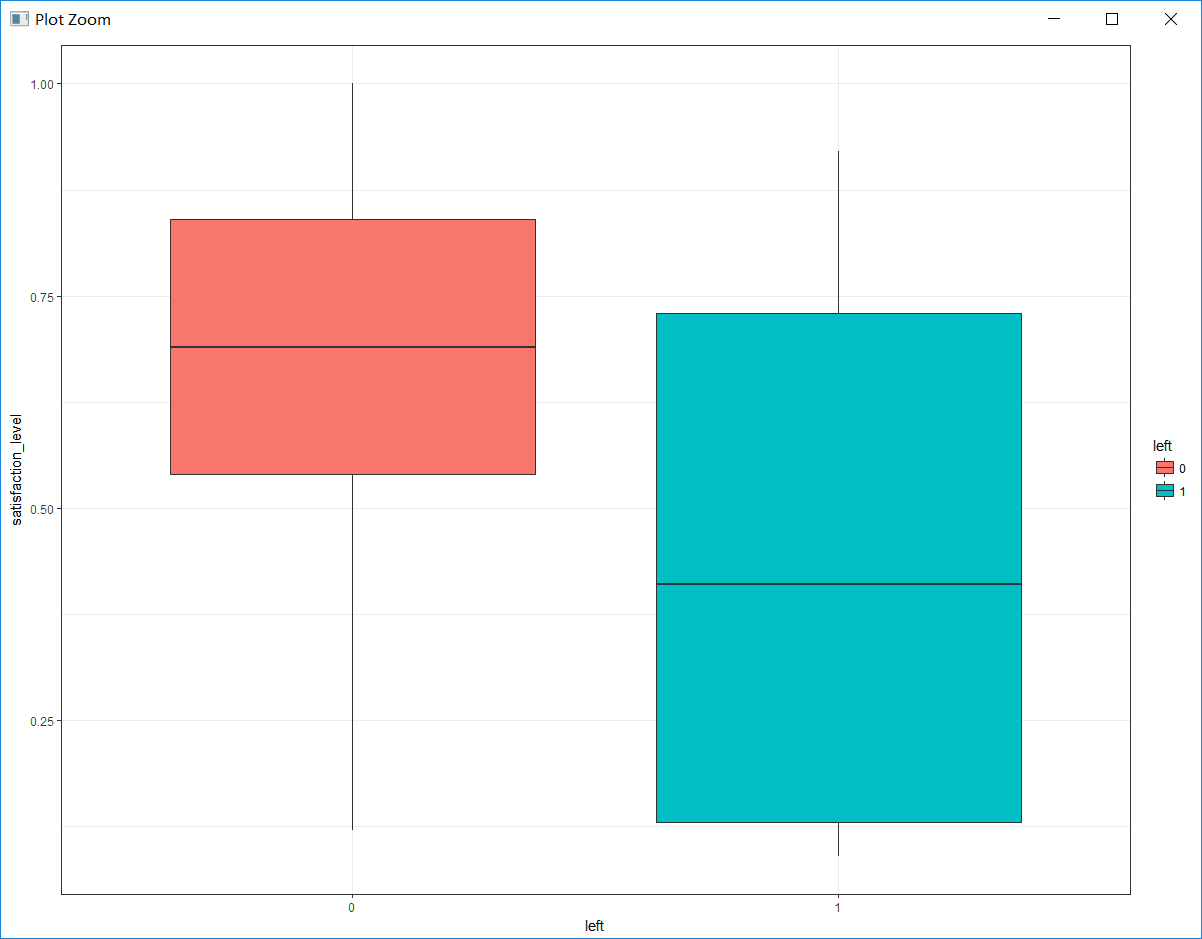
从图中可以看出,未离职员工对公司的满意度远远高于离职员工对公司的满意度,员工对公司的平均满意度大概在0.6。
b. 探索员工的绩效评估与是否离职的关系
# 绘制绩效评估与是否离职的箱线图
box_eva <- ggplot(hr, aes(x = left, y = last_evaluation, fill = left)) +
geom_boxplot() +
theme_bw() +
labs(x = 'left', y = 'last_evaluation')
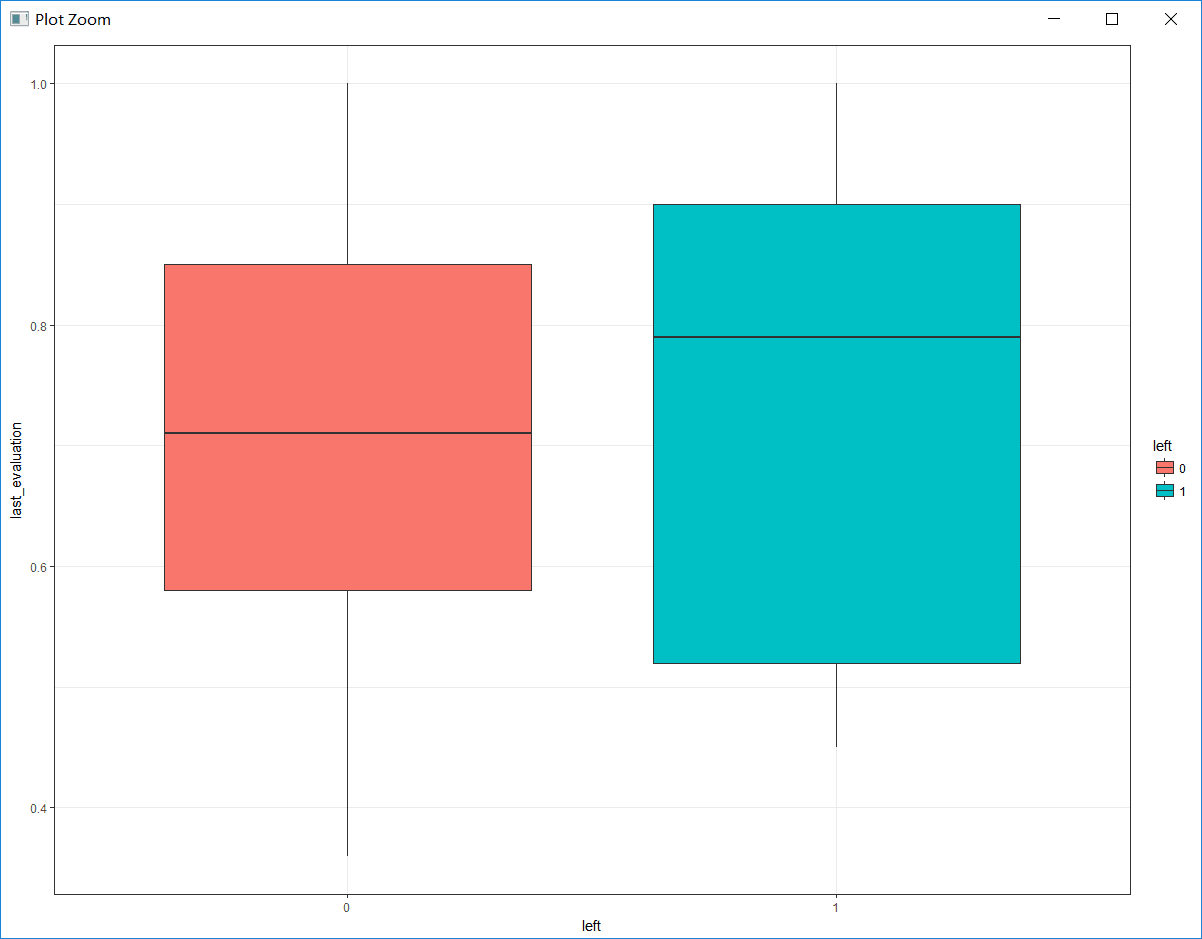
从图中可以看出,员工的平均绩效评估大概在0.7左右。
c. 探索员工的绩效评估与是否离职的关系
# 绘制平均月工作时长与是否离职的箱线图
box_mon <- ggplot(hr, aes(x = left, y = average_montly_hours, fill = left)) +
geom_boxplot() +
theme_bw() +
labs(x = 'left', y = 'average_montly_hours')
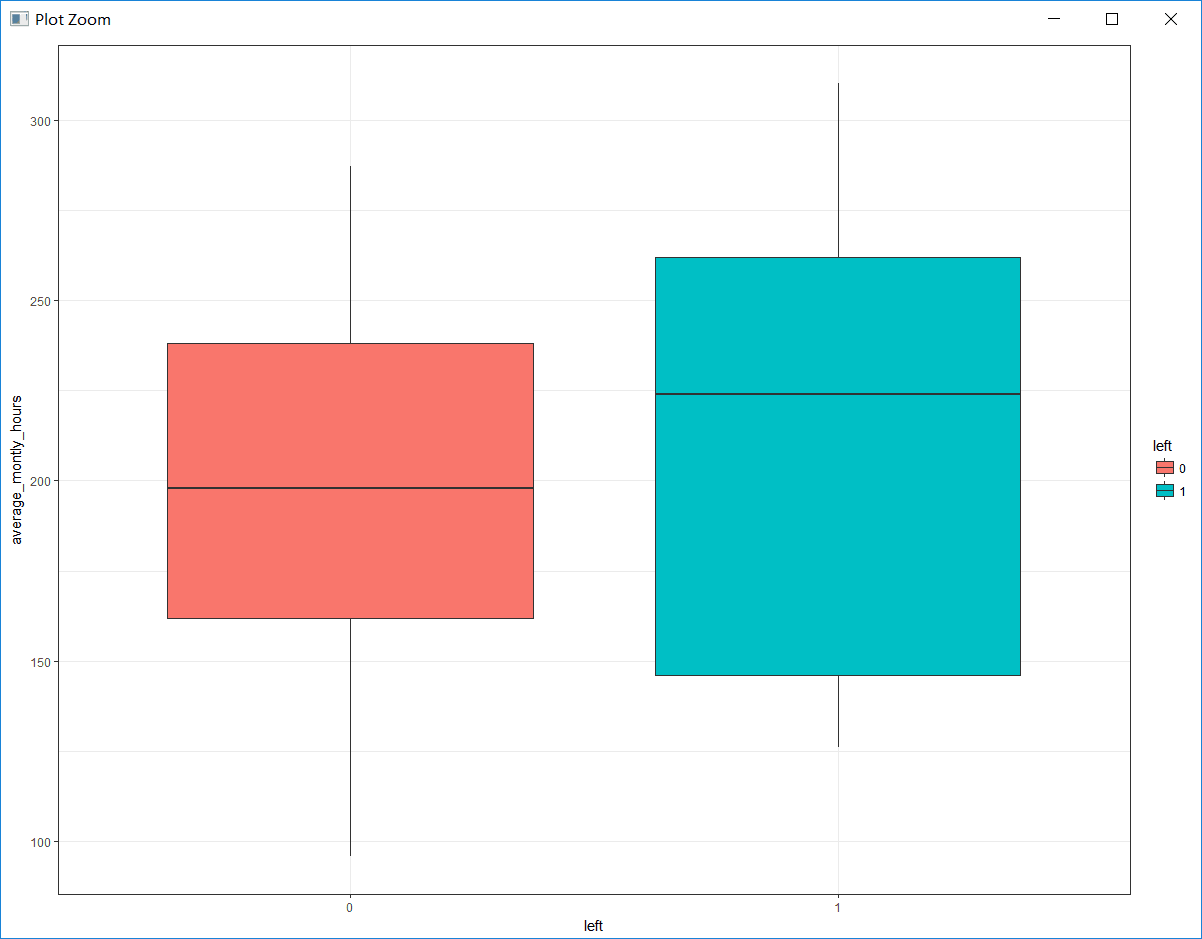
从图中可以看出,已经离职员工的月平均工作时长要高于未离职员工的月平均工作时长。
d. 探索员工在公司工作年限与是否离职的关系
# 绘制员工在公司工作年限与是否离职的箱线图
box_time <- ggplot(hr, aes(x = left, y = time_spend_company, fill = left)) +
geom_boxplot() +
theme_bw() +
labs(x = 'left', y = 'time_spend_company')

# 绘制参与项目个数条形图时需要把此变量转换为因子型
hr$number_project <- factor(hr$number_project,
levels = c('2', '3', '4', '5', '6', '7')) 绘制
参与项目个数与是否离职的百分比堆积条形图
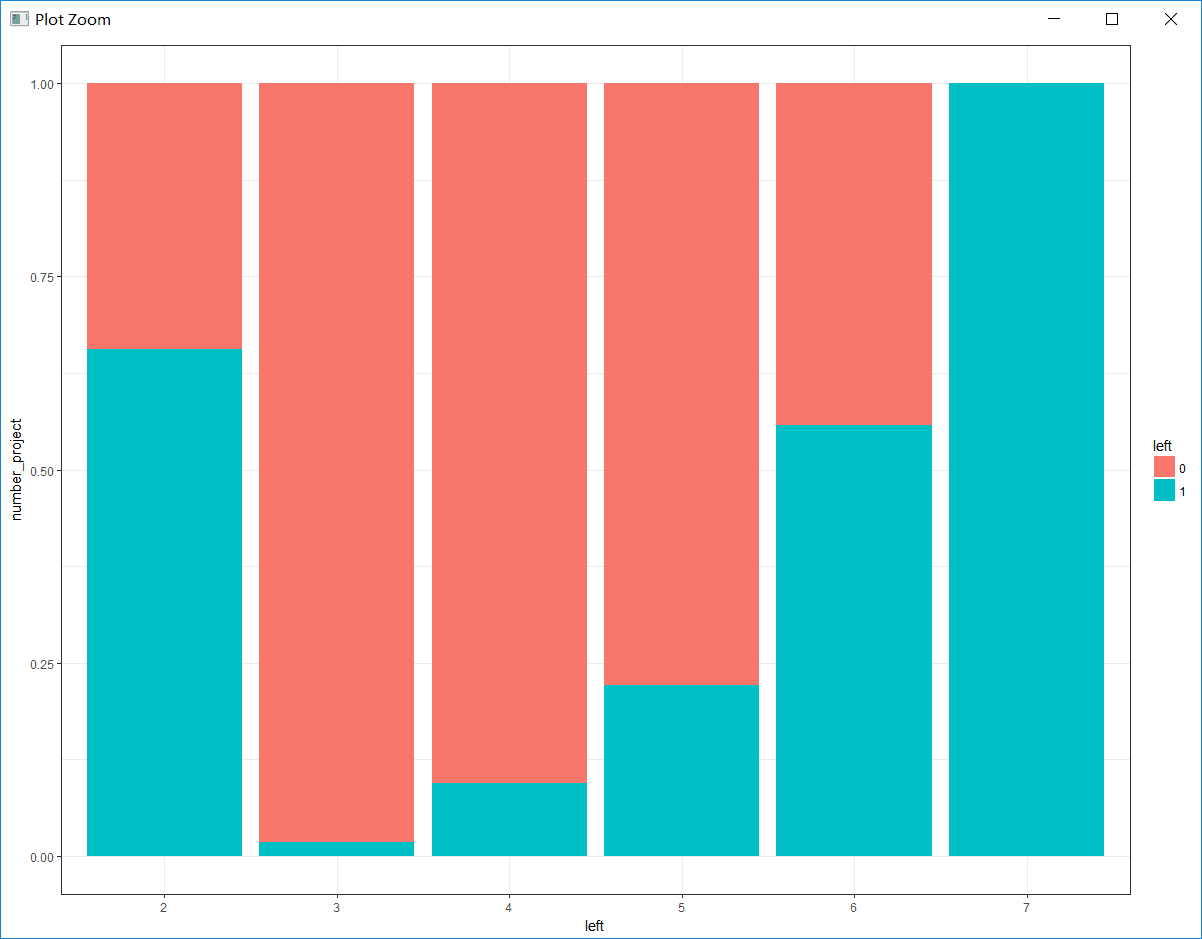
# 绘制参与项目个数与是否离职的百分比堆积条形图
bar_pro <- ggplot(hr, aes(x = number_project, fill = left)) +
geom_bar(position = 'fill') + # position = 'fill'即绘制百分比堆积条形图
theme_bw() +
labs(x = 'left', y = 'number_project')
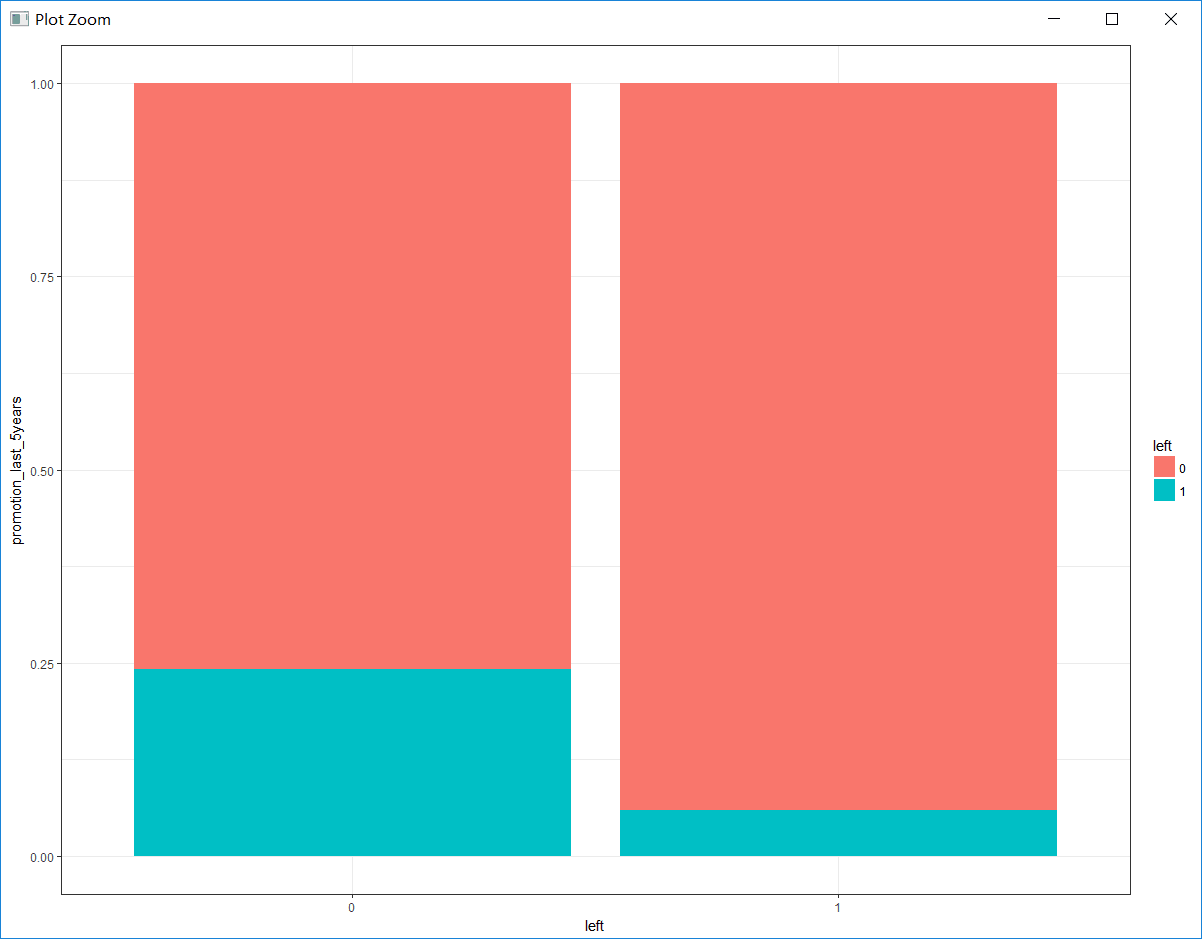
b. 探索5年内是否升职与是否离职的关系
# 绘制5年内是否升职与是否离职的百分比堆积条形图
bar_5years <- ggplot(hr, aes(x = as.factor(promotion_last_5years), fill = left)) +
geom_bar(position = 'fill') +
theme_bw() +
labs(x = 'left', y = 'promotion_last_5years')
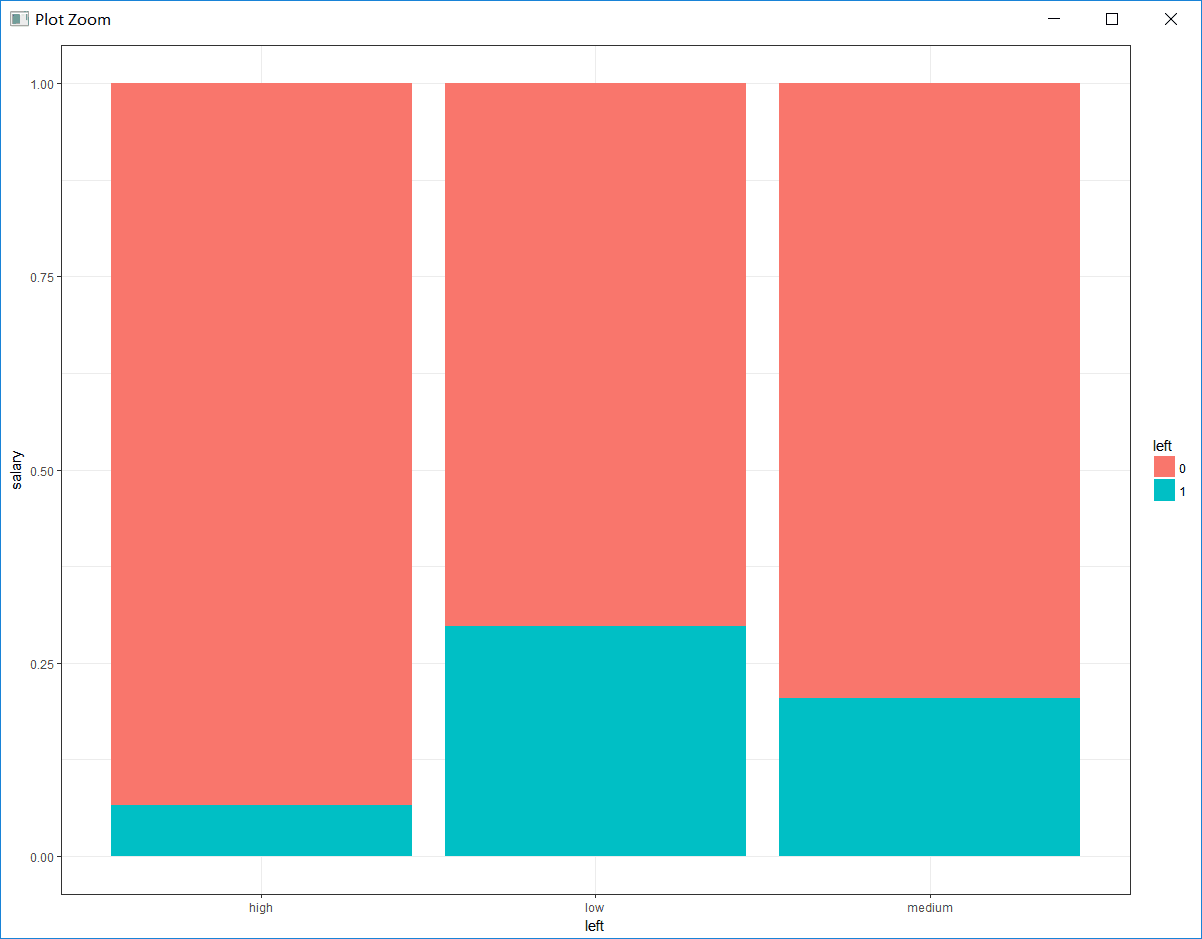
# 绘制薪资与是否离职的百分比堆积条形图
bar_salary <- ggplot(hr, aes(x = salary, fill = left)) +
geom_bar(position = 'fill') +
theme_bw() +
labs(x = 'left', y = 'salary')
4、数据预处理
由于我们的业务需求中,我们想知道的是:那些大公司里最优秀的最有经验的员工为什么会过早的离职。因此,我们关注的那些最优秀最有经验的员工,因此我们要从数据当中提取出这些人。那么什么样的员工才算是最优秀最有经验的呢?我们将绩效>=0.7,工作年限>=4,项目数>5的这些人定义为最优秀最有经验的员工。以下是如何选取优秀员工的代码。
hr_model <- filter(hr, last_evaluation >= 0.70 | time_spend_company >= 4
| number_project > 5)
5、建模预测
(1)自定义交叉验证方法
# 设置5折交叉验证 method = ‘cv’是设置交叉验证方法,number = 5意味着是5折交叉验证
train_control <- trainControl(method = 'cv', number = 5)
(2)分层抽样
set.seed(1234) # 设置随机种子,为了使每次抽样结果一致
# 根据数据的因变量进行7:3的分层抽样,返回行索引向量 p = 0.7就意味着按照7:3进行抽样,
# list=F即不返回列表,返回向量
index <- createDataPartition(hr_model$left, p = 0.7, list = F)
traindata <- hr_model[index, ] # 提取数据中的index所对应行索引的数据作为训练集
testdata <- hr_model[-index, ] # 其余的作为测试集
(3)使用决策树进行建模预测
# 使用caret包中的trian函数对训练集使用5折交叉的方法建立决策树模型
# left ~.的意思是根据因变量与所有自变量建模;trCintrol是控制使用那种方法进行建模
# methon就是设置使用哪种算法
rpartmodel <- train(left ~ ., data = traindata,
trControl = train_control, method = 'rpart')
# 利用rpartmodel模型对测试集进行预测,([-7]的意思就是剔除测试集的因变量这一列)
pred_rpart <- predict(rpartmodel, testdata[-7])
(4)使用朴素贝叶斯进行建模预测
nbmodel <- train(left ~ ., data = traindata,
trControl = train_control, method = 'nb')
pred_nb <- predict(nbmodel, testdata[-7])
6、模型评估与应用
(1)决策树模型
# 第一步,建立混淆矩阵,positive=‘1’设定我们的正例为“1”
con_rpart <- table(pred_rpart, testdata$left)

# 第二步,使用roc函数时,预测的值必须是数值型
pred_rpart <- as.numeric(as.character(pred_rpart))
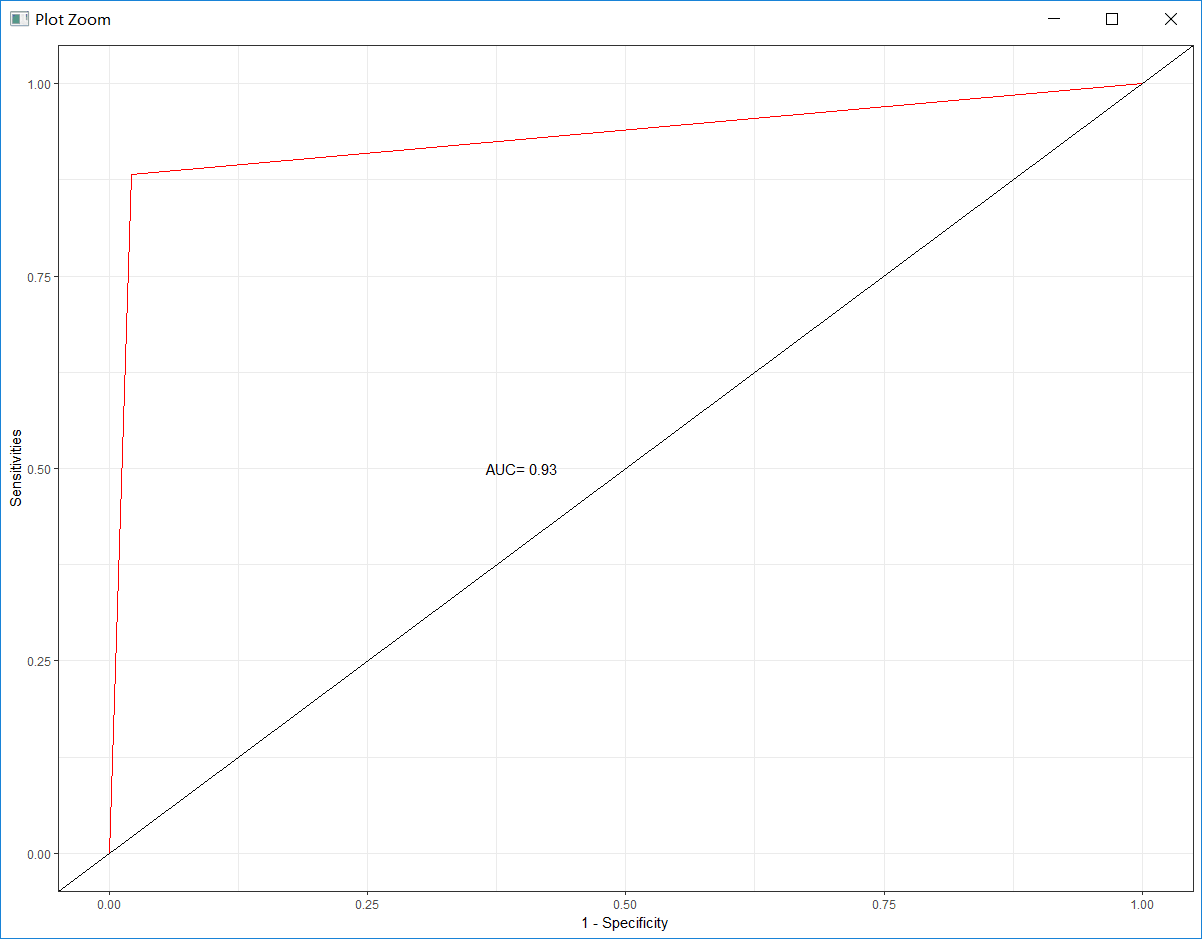
#第三步,绘制ROC曲线,ROC曲线横轴是假正例率,纵轴是真正例率
roc_rpart <- roc(testdata$left, pred_rpart) # 获取后续画图时使用的信息
#假正例率:(1-Specififity[真反例率])
Specificity <- roc_rpart$specificities # 为后续的横纵坐标轴奠基,真反例率
Sensitivity <- roc_rpart$sensitivities # 查全率 : sensitivities,也是真正例率
# 绘制ROC曲线
#我们只需要横纵坐标,NULL是为了声明我们没有用任何数据
p_rpart <- ggplot(data = NULL, aes(x = 1- Specificity, y = Sensitivity)) +
geom_line(colour = 'red') + # 绘制ROC曲线
geom_abline() + # 绘制对角线
annotate('text', x = 0.4, y = 0.5, label = paste('AUC=', #text是声明图层上添加文本注释
#‘3’是round函数里面的参数,保留三位小数
round(roc_rpart$auc, 3))) + theme_bw() + # 在图中(0.4,0.5)处添加AUC值
labs(x = '1 - Specificity', y = 'Sensitivities') # 设置横纵坐标轴标签
(2)朴素贝叶斯模型
# 第一步,建立混淆矩阵
con_nb <- table(pred_nb, testdata$left)
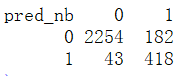
# 第二步,使用roc函数时,预测的值必须是数值型 pred_nb <- as.numeric(as.character(pred_nb))
# 第三步,绘制ROC曲线
roc_nb <- roc(testdata$left, pred_nb)
Specificity <- roc_nb$specificities
p_nb <- ggplot(data = NULL, aes(x = 1- Specificity, y = Sensitivity)) +
Sensitivity <- roc_nb$sensitivities
annotate('text', x = 0.4, y = 0.5, label = paste('AUC=',
geom_line(colour = 'red') + geom_abline() +
labs(x = '1 - Specificity', y = 'Sensitivities')
round(roc_nb$auc, 3))) + theme_bw() +
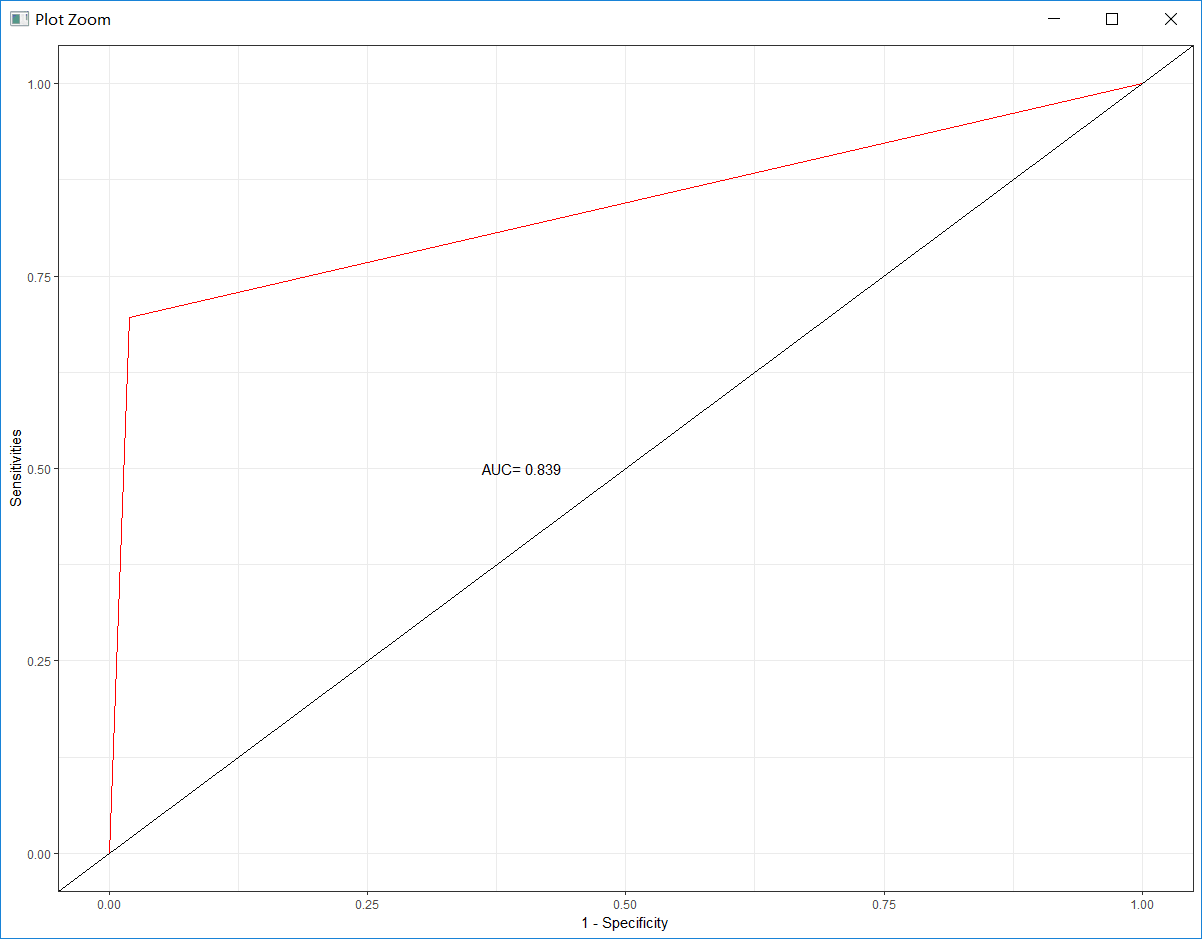
(3)模型评估
由上述结果可以看出,决策树模型的AUC=0.93,朴素贝叶斯模型的AUC=0.839。AUC值越大,则模型越好,显然决策树模型优于朴素贝叶斯模型。
(4)模型应用
一般地,当AUC值达到0.75时,我们就认为该模型可应用,下面我们就用剩余的30%的数据,采用决策树模型进行预测。
# 使用回归树模型预测分类的概率,type=‘prob’设置预测结果为离职的概率和不离职的概率
pred_end <- predict(rpartmodel, testdata[-7], type = 'prob')
# 合并预测结果和预测概率结果
data_end <- cbind(round(pred_end, 3), pred_rpart)
# 为预测结果表重命名
names(data_end) <- c('pred.0', 'pred.1', 'pred')
# 生成一个交互式数据表
datatable(data_end)
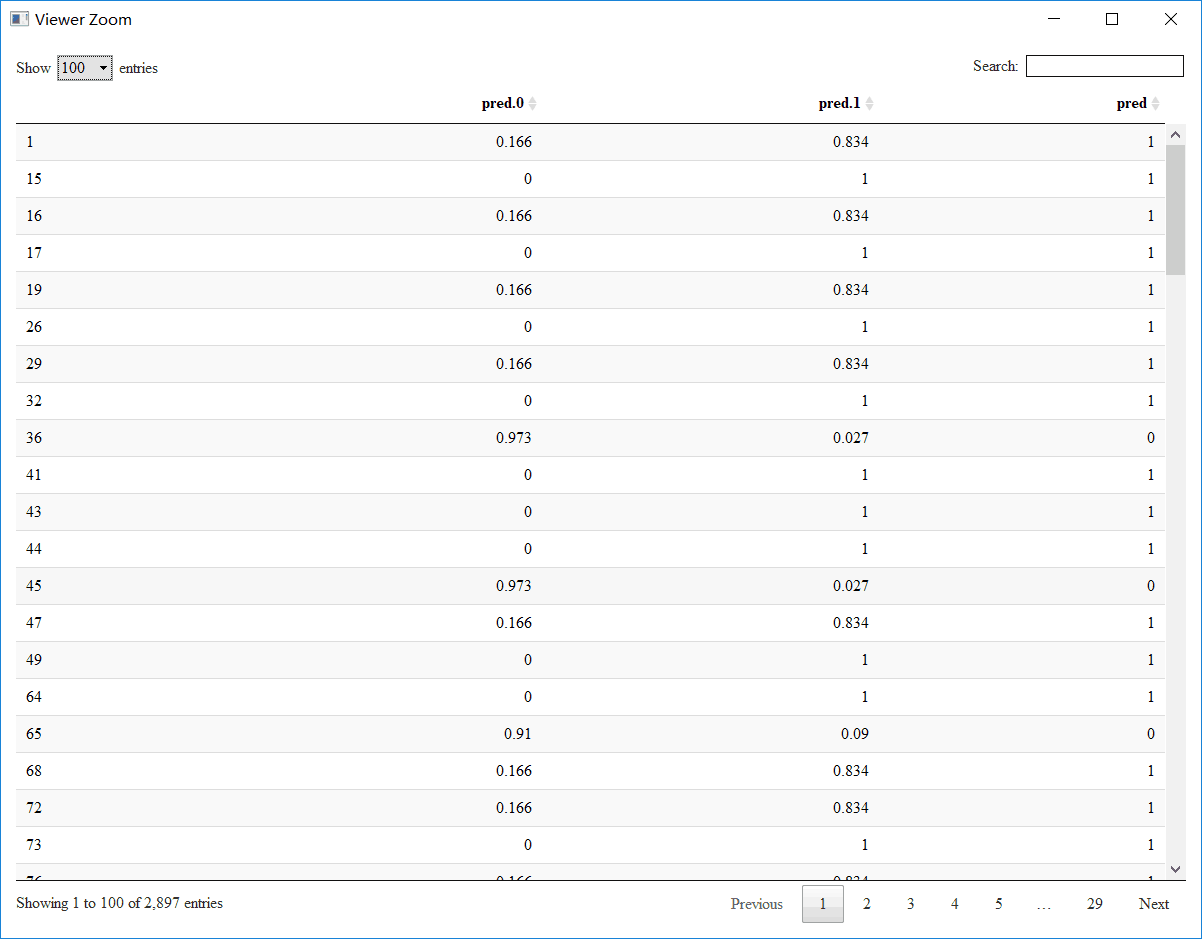
这张表的第一列表示员工编号,那为什么不是连续的呢?也就是说为什么不是所有员工呢?回到文章的最开始,我们关注的是最优秀最有经验的员工为什么会过早离职,当然,在这张表里只有我们选择出的优秀的员工。第二列表示该员工不会离职的概率,第三列表示该员工会离职的概率,最后一列表示该员工是否会离职。
温馨提示:
可能大家在做的过程中会遇到以下问题:
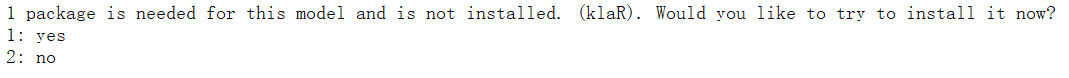
这个时候大家只需安装klaR这个包(install.packages("klaR"))即可。