上一章: 【MySQL】数据库基础 ②

✍临时表
说明:
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
临时表在MySQL 3.23版本中添加,如果你的MySQL版本低于 3.23版本就无法使用MySQL的临时表。
如果你使用了其他MySQL客户端程序连接MySQL数据库服务器来创建临时表,那么只有在关闭客户端程序时才会销毁临时表,当然你也可以手动销毁
1、创建临时表
- 创建临时表
CREATE TEMPORARY TABLE product_temporary (
product_name VARCHAR(50) NOT NULL,
total_sales DECIMAL(10,2) NOT NULL DEFAULT 0.00,
price DECIMAL(10,2) NOT NULL DEFAULT 0.00,
sold_total INT UNSIGNED NOT NULL DEFAULT 0
);- 给临添加一条数据
INSERT INTO product_temporary (product_name, total_sales, price, sold_total) VALUES ('手机', 100.25, 90, 2);- 查看临时表中的数据
select * from product_temporary; 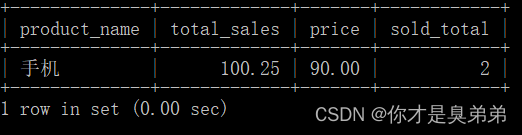
当你使用 SHOW TABLES命令显示数据表列表时,你将无法看到 product_temporary 表。
如果你退出当前MySQL会话,再使用 SELECT命令来读取原先创建的临时表数据,那你会发现数据库中没有该表的存在,因为在你退出时该临时表已经被销毁了。
2、删除临时表
说明:
默认情况下,当你断开与数据库的连接后,临时表就会自动被销毁。当然你也可以在当前MySQL会话使用 DROP TABLE 命令来手动删除临时表。
-
手动删除临时表
DROP TABLE product_temporary;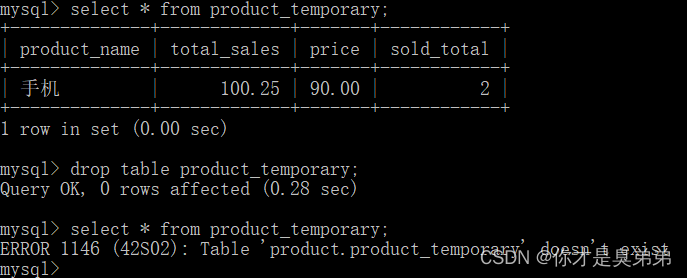
✍复制表
说明:
如果我们需要完全的复制MySQL的数据表,包括表的结构,索引,默认值等。 如果仅仅使用CREATE TABLE ... SELECT 命令,是无法实现的。
如何完整的复制MySQL数据表,步骤如下:
- 使用 SHOW CREATE TABLE 命令获取创建数据表(CREATE TABLE) 语句,该语句包含了原数据表的结构,索引等。
- 复制以下命令显示的SQL语句,修改数据表名,并执行SQL语句,通过以上命令 将完全的复制数据表结构。
- 如果你想复制表的内容,你就可以使用 INSERT INTO ... SELECT 语句来实现。
1、步骤一
- 演示复制表 text_table。
SHOW CREATE TABLE text_table \G;- 获取数据表的完整结构。
*************************** 1. row ***************************
Table: text_table
Create Table: CREATE TABLE `text_table` (
`text_id` int unsigned NOT NULL AUTO_INCREMENT,
`text_title` varchar(100) NOT NULL,
`text_author` varchar(40) NOT NULL,
`submission_date` date DEFAULT NULL,
PRIMARY KEY (`text_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb3
1 row in set (0.00 sec)2、步骤二
- 修改SQL语句的数据表名,并执行SQL语句。
CREATE TABLE `text_copy` (
`text_id` int unsigned NOT NULL AUTO_INCREMENT,
`text_title` varchar(100) NOT NULL,
`text_author` varchar(40) NOT NULL,
`submission_date` date DEFAULT NULL,
PRIMARY KEY (`text_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb3;3、步骤三
- 执行完第二步骤后,你将在数据库中创建新的克隆表 text_copy 。 如果你想拷贝数据表的数据你可以使用 INSERT INTO... SELECT 语句来实现。
INSERT INTO text_copy (text_id,text_title,text_author,submission_date)
SELECT text_id,text_title,text_author,submission_date FROM text_table;执行以上步骤后,会完整的复制表的内容,包括表结构及表数据。
- 查看克隆后的 text_copy 表
mysql> select * from text_copy;
+---------+----------------+--------------+-----------------+
| text_id | text_title | text_author | submission_date |
+---------+----------------+--------------+-----------------+
| 1 | 安徒生童话 | 臭弟弟 | 2023-06-16 |
| 2 | 小天鹅与丑小鸭 | 你才是臭弟弟 | 2023-06-16 |
| 3 | 西游记 | 我不是臭弟弟 | 2023-06-16 |
| 5 | csdn | 作者 | 2023-06-19 |
| 6 | 测试 | text | 2023-06-19 |
+---------+----------------+--------------+-----------------+
5 rows in set (0.29 sec)✍元数据
说明:
MySQL元数据(Metadata)是指MySQL数据库中关于数据结构的信息,如数据库、表、列、索引等信息。在MySQL中,元数据通常以数据字典的形式存储在系统数据库中,可以通过查询数据字典来获取元数据信息。
1、常用元数据查询语句
- 查询所有数据库
SHOW DATABASES;- 查询指定数据库中的所有表
SHOW TABLES;
- 查询指定表的列信息
DESCRIBE table_name;- 查询指定表的索引信息
SHOW INDEX FROM table_name;- 查询指定表的表空间信息
SHOW TABLE STATUS LIKE 'table_name';- 查询所有用户的权限
SELECT user, host, grant_priv, super_priv FROM mysql.user;- 查询当前登录用户的权限
SELECT * FROM information_schema.USER_PRIVILEGES;
- 查询所有数据库的表空间使用情况
SHOW TABLE STATUS;2、获取服务器元数据
| 命令 | 描述 |
|---|---|
| SELECT VERSION() | 服务器版本信息 |
| SELECT DATABASE() | 当前数据库名 (或者返回空) |
| SELECT USER() | 当前用户名 |
| SHOW STATUS | 服务器状态 |
| SHOW VARIABLES | 服务器配置变量 |
✍处理重复数据
说明:
数据表中可能存在重复的记录,有些情况我们允许重复数据的存在,但有时候我们也需要删除这些重复的数据。
主要介绍如何防止数据表出现重复数据及如何删除数据表中的重复数据。
1、防止表中出现重复数据
- 可以在 MySQL 数据表中设置指定的字段为 PRIMARY KEY(主键) 或者 UNIQUE(唯一) 索引来保证数据的唯一性。
实例:下表中无索引及主键,所以该表允许出现多条重复记录。
CREATE TABLE person_table
(
first_name CHAR(20),
last_name CHAR(20),
sex CHAR(10)
);- 如果你想设置表中字段 first_name,last_name 数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键,那么那个键的默认值不能为 NULL,可设置为 NOT NULL。
如下所示:
CREATE TABLE person_table
(
first_name CHAR(20) NOT NULL,
last_name CHAR(20) NOT NULL,
sex CHAR(10),
PRIMARY KEY (last_name, first_name)
);补充:
当然使用可视化工具 更方便效率更高,如下图
- 如果我们设置了唯一索引,那么在插入重复数据时,SQL 语句将无法执行成功,并抛出错。
- INSERT IGNORE INTO 与 INSERT INTO 的区别就是 INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
以下实例使用了 INSERT IGNORE INTO,执行后不会出错,也不会向数据表中插入重复数据:
mysql> INSERT IGNORE INTO person_table (last_name, first_name)VALUES( 'mr.xiao', 'csdn');
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> INSERT IGNORE INTO person_table (last_name, first_name)VALUES( 'mr.xiao', 'csdn');
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select * from person_table;
+------------+-----------+------+
| first_name | last_name | sex |
+------------+-----------+------+
| Thomas | Jay | NULL |
| csdn | mr.xiao | NULL |
+------------+-----------+------+
2 rows in set (0.00 sec)- INSERT IGNORE INTO 当插入数据时,在设置了记录的唯一性后,如果插入重复数据,将不返回错误,只以警告形式返回。 而 REPLACE INTO 如果存在 primary 或 unique 相同的记录,则先删除掉。再插入新记录。
另一种设置数据的唯一性方法是添加一个 UNIQUE 索引,如下所示:
CREATE TABLE person_table
(
first_name CHAR(20) NOT NULL,
last_name CHAR(20) NOT NULL,
sex CHAR(10),
UNIQUE (last_name, first_name)
);2、统计重复数据
- 统计 person_table 表中 first_name 和 last_name的重复记录数
SELECT
COUNT(*) AS repetitions,
last_name,
first_name
FROM
person_table
GROUP BY
last_name,
first_name
HAVING
repetitions > 1;以上SQL查询在person_table表中具有重复值的last_name和first_name组合。它返回每个组合的总数(repetitions)以及组合中的last_name和first_name。
具体来说,这个查询:
- 使用了COUNT(*)函数来计算每个组合的行数(即重复次数),并将其命名为repetitions。
- 使用了GROUP BY子句来分组具有相同last_name和first_name的行。
- 使用了HAVING子句来筛选出重复次数大于1的组合。
结果将按照last_name和first_name的顺序进行排序,并返回具有重复值的行。
3、过滤重复数据
- 如果需要读取不重复的数据可以在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。
SELECT DISTINCT
last_name,
first_name
FROM
person_table;- 也可以使用 GROUP BY 来读取数据表中不重复的数据
SELECT
last_name,
first_name
FROM
person_table
GROUP BY
last_name,
first_name;4、 删除重复数据
- 使用DISTINCT关键字和UNION操作符
SELECT DISTINCT * FROM (
SELECT column_name1, column_name2, ... FROM table_name
UNION
SELECT column_name1, column_name2, ... FROM table_name
) AS tmp;这个方法会将表中的所有行复制到临时表中,并使用DISTINCT关键字删除重复的行。
- 使用GROUP BY和HAVING子句
DELETE table_name
FROM table_name
WHERE column_name IN (
SELECT column_name
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1
);这个方法将使用子查询查找具有重复值的列,并在主表中删除这些行。
- 使用NOT IN或LEFT JOIN
DELETE table_name
FROM table_name
WHERE id NOT IN (
SELECT MIN(id)
FROM table_name
GROUP BY column_name
);或者使用左连接
DELETE t1
FROM table_name t1
LEFT JOIN (
SELECT MIN(id) AS id
FROM table_name
GROUP BY column_name
) t2 ON t1.id = t2.id
WHERE t2.id IS NULL;这两种方法都会从表中删除重复值,但不会删除包含重复值的列中的所有行。而是只删除重复值中的一行。
✍SQL注入
如何防止 SQL 注入攻击:
- 使用预编译语句(Prepared Statement):预编译语句是一种在执行 SQL 查询之前预编译 SQL 语句的方法。这种方法将 SQL 查询和数据分开,使得攻击者无法利用 SQL 注入攻击。
- 使用参数化查询(Parameterized Query):参数化查询是一种将 SQL 查询和数据分开的方法。它通过将查询字符串和变量参数分离来实现,从而避免了 SQL 注入攻击。
- 过滤特殊字符:在构建 SQL 查询时,可以使用过滤特殊字符的方法来防止 SQL 注入攻击。例如,可以使用正则表达式来过滤输入中的特殊字符。
- 使用最小化权限:确保应用程序使用的 MySQL 用户具有最小的权限。这意味着,应用程序只需要使用足够的权限来执行其任务,而不需要额外的权限。
- 使用安全的连接库:使用 MySQL 的连接库时,请确保使用最新版本的连接库。这些库通常包含安全性和防止 SQL 注入攻击的改进。
- 对输入进行验证和过滤:在接受用户输入之前,请对输入进行验证和过滤,以确保其符合预期的格式和类型。这可以防止恶意输入导致 SQL 注入攻击。
- 使用应用防火墙或 WAF:在应用程序级别上使用应用防火墙或 WAF,以检测和阻止 SQL 注入攻击。这些防火墙通常具有基于规则的检测和阻止功能,可以有效地保护应用程序免受 SQL 注入攻击。