C#实现读取word文件,并从中检索字符
- 本文通过C#来读取word文件中的文本,然后通过搜索框实现对文本内容的检索
- 本功能的实现是在windows、VisualStudio2015 使用C#语言实现
- 本功能的word文件读取功能参考Using-IFilter-in-C# ,该方法在读取word时并不需要安装Office,完美提取中英文,读取速度快,即使word中含有表格、图片。
- 在检索字符的过程中,本程序首先将文本内容进行句子划分,通过使用OpenNIP中的句子检测(SentenceDetect),OpenNlp可以用于文本的句子检测、人名提取、词性标注等,具体的可以参考AlexPoint的OpenNlp的C#实现,本来想着使用正则表达式来来进行分句的,但是我又不会正则,而且在英文文本中,人名、缩写什么的都会有"."这种东西。不知道为什么github上AlexPoint的OpenNlp的c#跑不通,于是我改了改代码,让它跑通了一部分功能,工程文件见“这里”。
- 在显示检索出来的字符并为其添加阴影时,我们采用RichTexBox来显示。对应实现如下:
if(i == 0)
{
tbResult.Text = "没有找到对应的结果";
}else
{
tbResult.Text = result;
int endIndex = tbResult.Text.LastIndexOf(tbIndex.Text);
int startIndex = 0;
tbResult.SelectAll();
tbResult.SelectionBackColor = Color.White;//将背景色设置为白色
while(startIndex < endIndex)
{//从第一个对应的目标单词添加红色背景,一直往后查找,知道最后一个
tbResult.Find(tbIndex.Text, startIndex, tbResult.Text.Length, RichTextBoxFinds.MatchCase);
tbResult.SelectionBackColor = Color.Red;
startIndex = tbResult.Text.IndexOf(tbIndex.Text, startIndex) + 1;
}
}
6. 最后,管饭的有要求把中文剔除,只保留英文文本,并保存到文件中
我们使用正则表达式判断是否含有中文
public static Boolean hasChines(string str)
{//判断一句话是否有中文
return (Regex.IsMatch(str, @"[\u4e00-\u9fa5]"));
}
7. 最后就实现了整个工程(叫不上工程,代码太垃圾,我太菜),工程文件见
这里
注意,本功能并没有将读取的word显示,因为感觉程序界面排版很复杂,不过很简单,直接添加一个TextBox显示读取的文本就可以了,最终界面如下图:
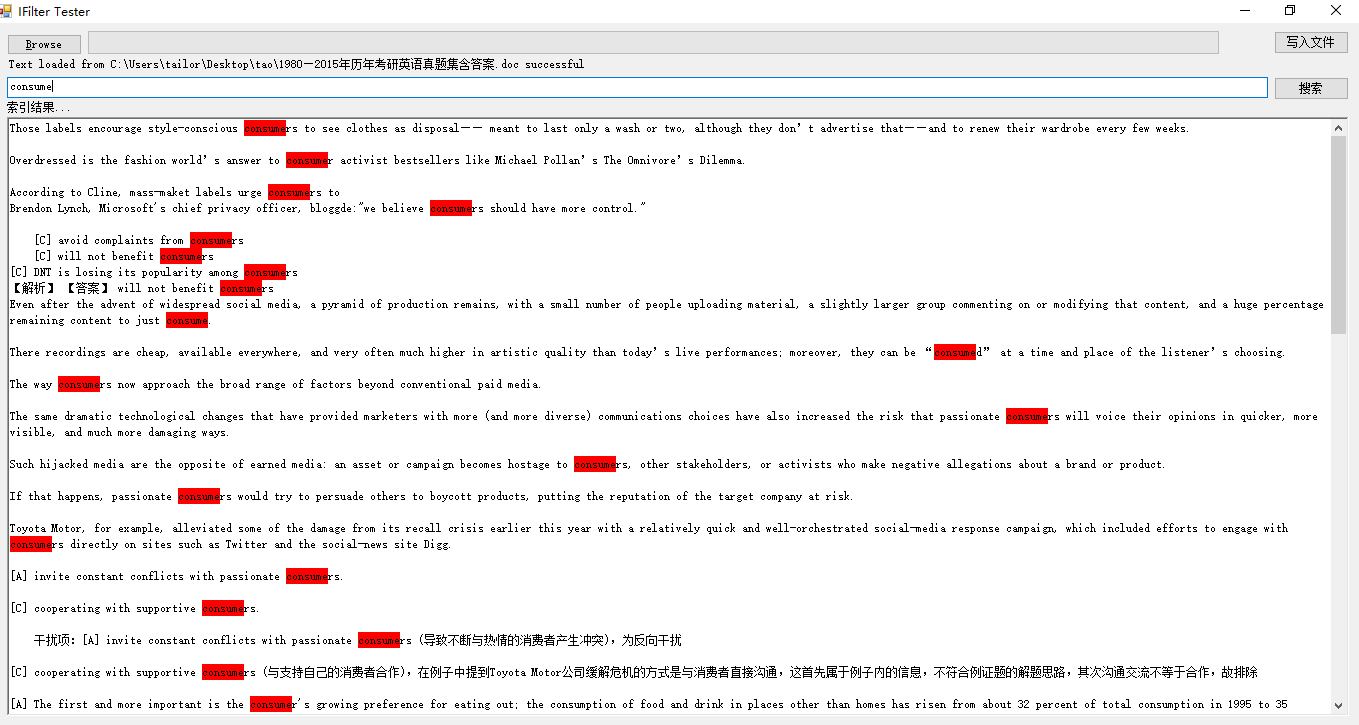
考研英语真题也可以送给你们。
/呲牙
不开心,资源没被审核通过...