1.从 l i s t ( r a n g e ( 9 ) ) list(range(9)) list(range(9))中创建一个张量 a a a并预测检查其大小、偏移量、步长。
import torch
a=torch.tensor(list(range(9)))
print(a.storage_offset())#偏移量
print(a.stride())#步长
print(a.size())#大小
a)使用 b = a . v i e w ( 3 , 3 ) b=a.view(3,3) b=a.view(3,3)创建一个张量,简述 v i e w ( ) view() view()方法的功能,检查 a a a, b b b是否共享同一个存储
view()函数:并没有改变张量在内存中真正的形状,使用view函数后,通常会使得张量的数字在语义上是连续的,但在内存上是不连续的。
在pytorch中view函数的作用为重构张量的维度,相当于numpy中resize的功能。返回的张量共享相同的数据,必须具有相同的元素数,但可能具有不同的大小。 对于要view的张量,view后的张量尺寸必须与其原始尺寸以及维度兼容。
view方法只适用于满足连续性条件的tensor,并且该操作不会开辟新的内存空间,只是产生了对原存储空间的一个新别称和引用,返回值是视图。
b=a.view(3,3)
print(a.size())
print(b.size())
b)使用 c = b [ 1 : , 1 : , ] c=b[1:,1:,] c=b[1:,1:,]创建一个张量,并预测检查其大小、偏移量、步长。
c=b[1:,1:,]
print(b.storage_offset())#偏移量
print(b.stride())#步长
print(b.size())#大小
2.选择一个数据运算(如求余弦和平方根),能在torch库中找到相应的函数吗?
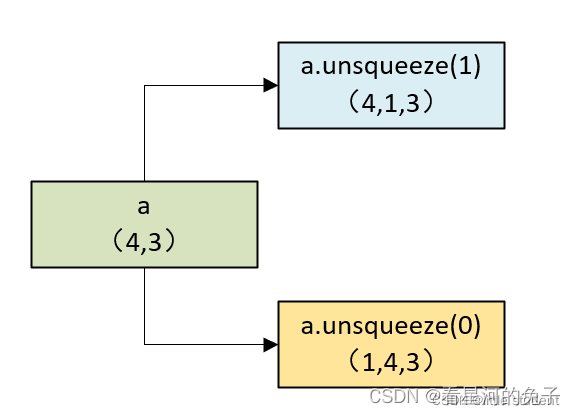
# 设置随机数种子,以保证结果可重现
torch.manual_seed(0)
c = torch.randn(4, 3)
similarity = torch.cosine_similarity(c.unsqueeze(1), c.unsqueeze(0), dim=-1)
#算余弦
a)按元素将函数作用于张量a,为什么返回一个错误?
similarity = torch.cosine_similarity(a.unsqueeze(1), a.unsqueeze(0), dim=-1)
RuntimeError: expected common dtype to be floating point, yet common dtype is Long
b)需要使用什么操作才能使函数正常操作?
a.dtype
a1=a.to(torch.float)
a1.dtype
similarity = torch.cosine_similarity(a1.unsqueeze(1), a1.unsqueeze(0), dim=-1)
本章小结
- 神经网络中输入输出表征比较好理解,中间表征不好理解
- 浮点表征存储于张量中
- 张量是多维数组,是Pytorch的基础数据结构
- 张量能够被序列化到磁盘,还能够被加载回来
- Pytorch中的所有张量操作都可以在CPU和GPU上执行,而不需要修改代码
- 以结尾以下画线标识的函数来表示该函数在张量上执行操作,如Tensor.sqrt_