multiprocessing.Process的join()方法
通过上篇博文可以看出join()方法具有清除僵尸进程的作用,与此同时带来的负面作用就是子父进程的串行执行(此处假设我们的目标是保证子父进程的执行方式是非阻塞的;对于实际需求是需要父进程阻塞等待子进程结束后在执行的应用场景,可以忽略本篇博文)。接下来将从join的底层实现出发探究其能够清楚僵尸进程的原因和阻塞执行的方式;同时基于一个demo来给出实际工作中如何准确有效的避免和消除僵尸进程。
join初探
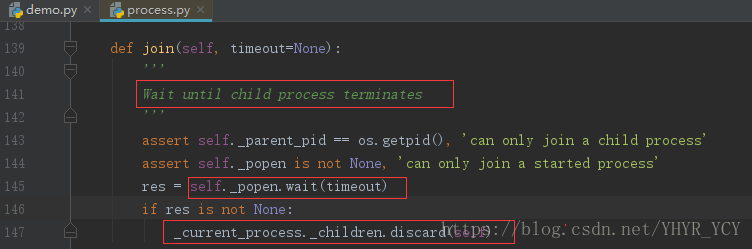
基于PyCharm查看join的源码,如上图所示;官方描述该方法的功能是“等待,直到子进程结束”;从字面意思也不难看出,该方法是一个阻塞方法;需要注意的是这里等待的主语是主进程而非子进程。该方法主要做了两件事:
(1) 通知父进程调用wait方法
(2) 将该子进程从父进程的子进程列表中移除
第一件事调用wait方法背后的实际调用链是:process模块的Process.join() => forking模块的Popen.wait(),实则是调用了os.waitpd方法【注意这里的Popen根据操作系统的不同而不同,分为Unix/Linux和Windows两种】;至于为什么要调用该方法可以看我上篇博文中有关Linux进程基本概念模块的描述。
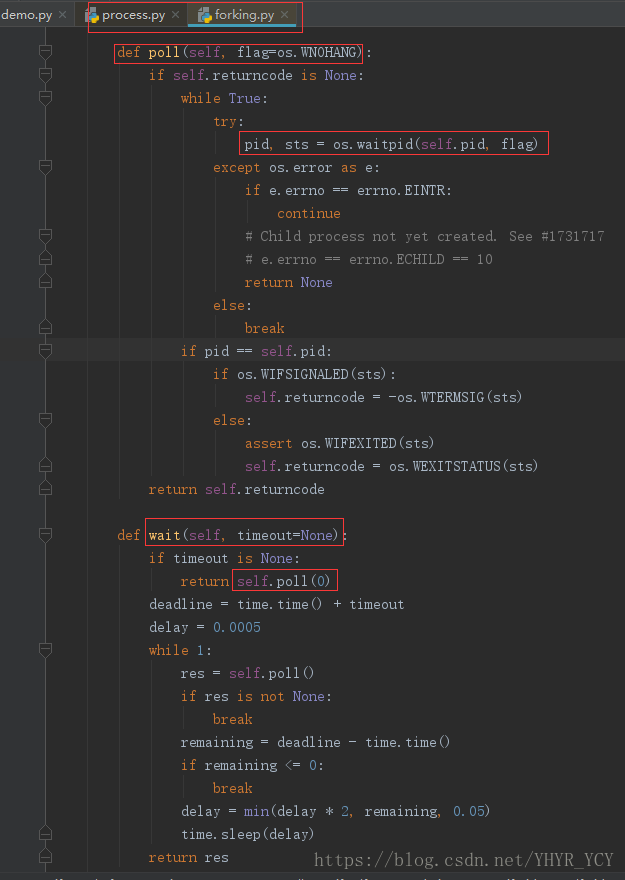
看到这,对于join()能消除僵尸进程的原因应该有了较为深刻的认识了;但是还存在一个问题:进程的串行执行问题还未解决。源码中join有一个timeout的参数,该参数的作用是设置一个该方法调用的等待时间,如果不设置,则等待子进程结束后在执行父进程;如果设置了,当子进程的运行周期大于你所设置的timeout时长时,表示过了timeout时长后(单位是秒),开始唤醒父进程,此时子父进程开始同时执行;如果子进程的运行周期小与你所设置的timeout时长时,当你的子进程结束后会立即执行父进程,而不用等待你所设置的时长结束后才开始唤醒父进程。光说这些理论可能印象不会太深刻,接下来用几组例子来抛砖引玉,在加深对join理解的同时,介绍两种僵尸进程的有效清除办法。
样例代码如下所示
# -*- coding: utf-8 -*-
import multiprocessing
import os
import time
class MainProcess:
def __init__(self, main_process_time, child_process_time):
self.main_process_time = main_process_time
self.child_process_time = child_process_time
def excutor(self):
print('main process begin, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
p = ChildProcess(self.child_process_time)
p.start()
p.join(3)
for i in range(self.main_process_time):
print('main process, pid={0}, ppid={1}, times={2}'.format(os.getpid(), os.getppid(), i))
time.sleep(1)
class ChildProcess(multiprocessing.Process):
def __init__(self, process_time):
multiprocessing.Process.__init__(self)
self.process_time = process_time
def run(self):
print('child process begin, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
for i in range(self.process_time):
print('child process pid={0}, ppid={1}, times={2}'.format(os.getpid(), os.getppid(), i))
time.sleep(1)
print('child process end, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
if __name__ == '__main__':
main_process_time = 15
child_process_time = 10
action = MainProcess(main_process_time, child_process_time)
action.excutor()场景一:子进程的运行周期大于父进程
在该应用场景下,无论是否调用join方法都不会有僵尸进程存在;如果调用join,则父进程会被挂起,子父进程串行执行;如果不调用join,子父进程并行执行;现在分析一下调用带参数的join方法(eg:p.join(3)),当父进程启动,子进程执行时间小于三秒时,执行效果如下图所示:

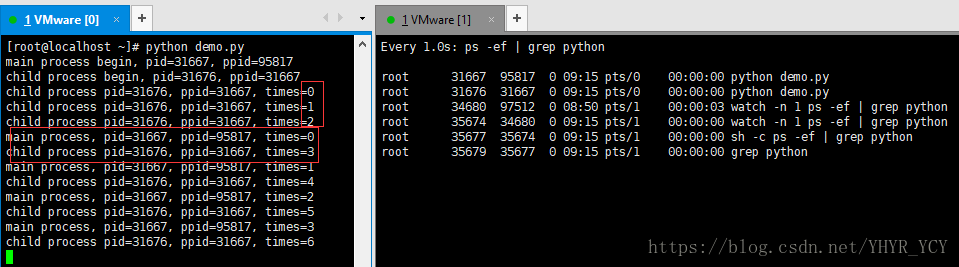
当子进程执行时间大于三秒且小于父进程的执行周期时,执行效果如下图所示:
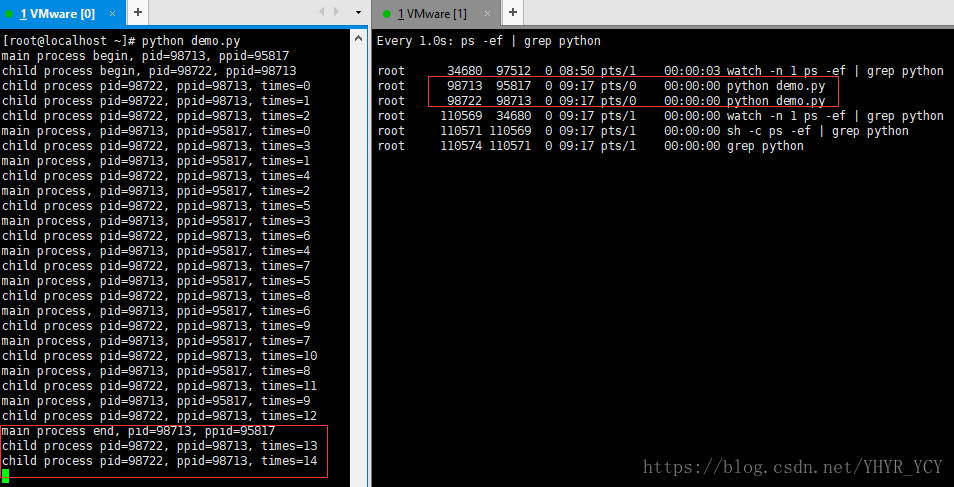
当父进程结束,而子进程继续执行,程序输出结果如下图所示:
场景二:子进程的运行周期小与父进程
在该应用场景下,如果不调用join,则会有僵尸进程产生;如果调用join,则可以消除僵尸进程,但是子父进程串行执行;这种结果也并非我们所需要的。接下来尝试一下调用带参数的join方法(eg:p.join(3)),修改上述样例代码将main_process_time设置为15,child_process_time设置为10:
当父进程启动,子进程执行时间小于三秒时,执行效果如下图所示:

当子进程执行时间大于三秒且小于子进程的执行周期时,执行效果如下图所示:
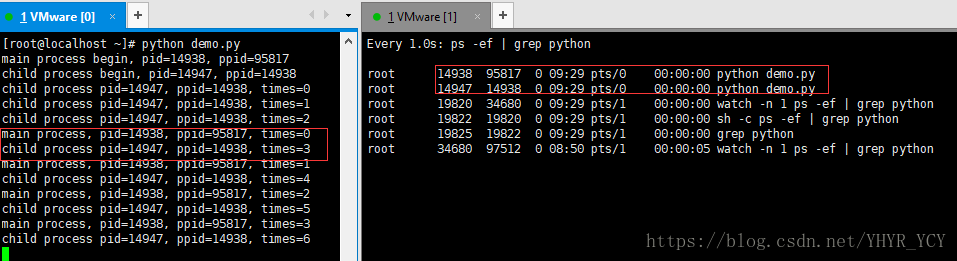
当子进程结束,父进程继续执行时,程序输出结果如下图所示:
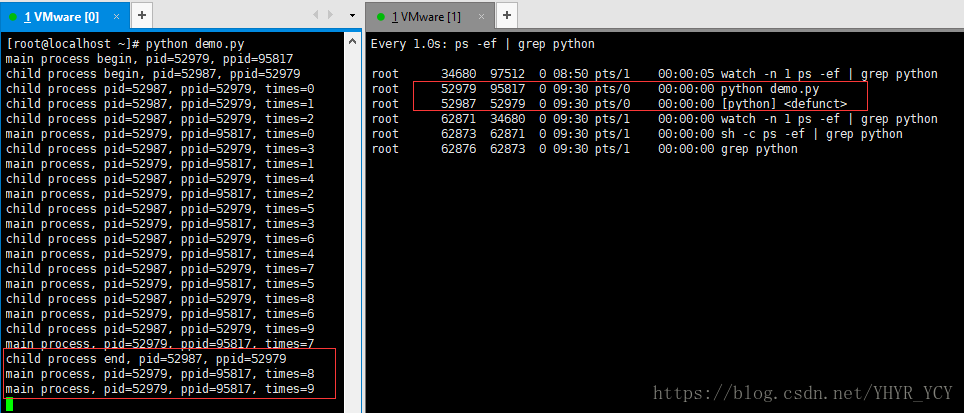
通过这个例子可以看出,在该应用场景下,不论是加了带参数的join还是不加join,都会有僵尸进程产生;相反加了不带参数的join虽可以避免僵尸进程,但是由于子父进程的串行执行导致仍无法满足我们的需求;为什么带参数和不带参数的join执行效果会如此大相径庭呢?其实通过上述源码是可以看出,join方法确实是会调用系统的os.waitpid()方法来获取子进程的退出信息,从而达到消除子进程的目的;但是这个过程是一次性的。什么意思呢?就是如果不带参数,则会一直挂起父进程,直到子进程结束后再执行p.join()方法,从而清除子进程;相反如果带参数,则会挂起父进程timeout时长后,唤醒父进程,此时父进程首先会执行p.join(3)这行代码,如果当前时刻子进程还未结束,则p.join(3)获取子进程的退出状态信息为空,则不会清除子进程,然后会紧接着执行父进程的后续逻辑;这时子父进程开始并行执行。如果子进程在次之后结束的同时父进程还未结束,则父进程会因为无法获取到子进程的退出信息而导致子进程沦为僵尸进程。(开始自己以为join(3)意味着父进程会在三秒后唤醒的同时,父进程会轮询监控子进程的退出信息,从而达到消除僵尸进程的作用,^v^ 还是太年轻~想当然了~哈哈!!!)。
消除僵尸进程
随着对Process的join()方法的深入理解,越发觉得离我们的目标渐行渐远。要不就会产生僵尸进程,要不就会挂起父进程,从而无法实现并行效果。那么问题来了,到底该如何有效的消除僵尸进程呢?
网上有些帖子和博客说可以通过os._exti(0)或者sys.exit(0)可以有效的退出子进程,这一点毋庸置疑;但是需要注意的是这种退出并没有什么太大的作用,因为主动退出子进程并不会通知父进程去获取子进程得退出状态信息,从而导致子进程还是会变成僵尸进程。在这里我将介绍两种行之有效的方法来实现彻底消除僵尸进程的同时,实现子父进程的并发。
方法一:创建两次子进程(fork两次)
如果百度过此类问题的不难发现,网上有很多说可以通过fork两次来避免僵尸进程。其实这是一个很不错的方法,也是一个比较容易理解的。只是关于该方法的解释不是很多(可能因为笔者太low,对于很多人来说都是一看就懂的^v^),在这里我将就该方法做以详细的解释和说明,希望对刚接触此类问题的小伙伴们有所帮助。
首先需要注意的是fork函数是unix/linux系统上特有的,在Windows上运行该函数会直接报错,而通常都是用Windows机器做开发,在Linux上跑代码的这种情况,直接在Linux上写代码又是比较麻烦的(如果愿意可以基于VM搭建一个桌面版的CentOS,然后装个编译器来开发),所以这里笔者从一开始就选择Python提供的一种跨平台的多进程模块 – multiprocessing来实现多进程(其实multiprocessing中基于Linux的代码实现逻辑就是fork,对于该模块源码初探可详见传送门)。
如何理解fork两次即可达到我们想要的想过呢?此处假设我们的业务场景是父进程一直存在,而子进程的执行周期短,且执行完后就退出。我们知道,当主进程创建一个子进程时,此时子进程的ppid即就是父进程的pid;而子进程结束后如果父进程没有获取子进程的退出状态信息,则子进程会变成僵尸进程;我们又知道,如果一个子进程是孤儿进程的话,那么它就是安全可靠的(不会产生僵尸进程);所以基于以上原因,可以进行如下设计:主进程的业务逻辑保持不变,只是在主进程创建子进程的时候,不直接创建子进程去执行相应的业务逻辑;而是创建一个单独进程(此处理解为爸爸进程),该进程只干一件事,就是创建原本应该有父进程创建的子进程。即就是将原本的“主进程 => 儿子进程”修改为“主进程 => 爸爸进程 => 儿子进程”,这种设计里只有主进程和儿子进程是需要关注的,而爸爸进程逻辑很简单,就是初始化儿子进程;所以当爸爸进程结束后儿子进程就沦为孤儿进程了,这样无论儿子进程执行多久,都不会产生僵尸进程。
有人就会想,爸爸进程退出不也会产生僵尸进程吗?其实这个问题很好解决,利用上述中的不带参数的join()方法即可解决。可以在主进程中创建父进程的同时,添加p.join()方法,因为爸爸进程创建儿子进程的耗时很短,所以可以在主进程创建爸爸进程的时候使用p.join()挂起,这个时间差是可以忽略和接受的,这样当父进程创建完儿子进程后父进程就会立马结束,此时主进程就会执行p.join()方法获取到爸爸进程的退出信息,从而彻底消除爸爸进程;这样进程列表里就只剩下一个主进程和一个而孤儿进程(原本的儿子进程转化而来);这样就实现了真正意义上的并发。为了测试时效果看的明显,在源码中添加了sleep(),如果在实际的业务开发中,可以注掉源码中的相关sleep()代码,具体源码如下所示(该写法可兼容Windows和Linux):
# -*- coding: utf-8 -*-
import multiprocessing
import os
import time
class MainProcess:
def __init__(self, main_process_time, child_process_time):
self.main_process_time = main_process_time
self.child_process_time = child_process_time
def excutor(self):
print('main process begin, pid={0}'.format(os.getpid()))
time.sleep(5)
p = FatherProcess(self.child_process_time)
p.start()
p.join()
for i in range(self.main_process_time):
print('main process, pid={0}, times={1}'.format(os.getpid(), i))
time.sleep(1)
print('main process end, pid={0}'.format(os.getpid()))
class FatherProcess(multiprocessing.Process):
def __init__(self, process_time):
multiprocessing.Process.__init__(self)
self.process_time = process_time
def run(self):
print('father process begin, pid={} => create childPorcess'.format(os.getpid()))
p = ChildProcess(self.process_time)
time.sleep(5)
p.start()
print('father process end, pid={}'.format(os.getpid()))
time.sleep(5)
os._exit(0)
class ChildProcess(multiprocessing.Process):
def __init__(self, process_time):
multiprocessing.Process.__init__(self)
self.process_time = process_time
def run(self):
print('child process begin, pid={0}'.format(os.getpid()))
for i in range(self.process_time):
print('child process pid={0}, times={1}'.format(os.getpid(), i))
time.sleep(1)
print('child process end, pid={0}'.format(os.getpid()))
if __name__ == '__main__':
main_process_time = 10
child_process_time = 5
action = MainProcess(main_process_time, child_process_time)
action.excutor()方法二:基于Linux信号清除僵尸进程
创建两次子进程的方法是比较好理解的,但是代码的入侵还是比较大的,基于Linux信号的方式可以只需要添加一行代码signal.signal(signal.SIGCHLD, signal.SIG_IGN)就可实现所需要的逻辑;不过该解决方案只适用于Linux/Unix系统;在Windows下执行是会报错。代码如下所示:
# -*- coding: utf-8 -*-
import multiprocessing
import os
import time
import signal
class MainProcess:
def __init__(self, main_process_time, child_process_time):
self.main_process_time = main_process_time
self.child_process_time = child_process_time
def excutor(self):
print('main process begin, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
'''
添加信号
signal.SIGCHLD的语义为:子进程状态改变后产生此信号
signal.SIG_IGN的语义为:信号的处理方式为忽略模式
默认采用SIG_DFL, 代表默认的处理方式为不会理会这个信号,但是也不会丢弃该信号量,
如果系统不调用wait/waitpid,则会变成僵尸进程
第二个参数也可以自定义处理逻辑,eg:将signal.SIG_IGN修改为自定义sigchld_handler方法,
专门用来处理对应的信号
'''
signal.signal(signal.SIGCHLD, signal.SIG_IGN)
p = ChildProcess(self.child_process_time)
p.start()
p.join(5)
for i in range(self.main_process_time):
print('main process, pid={0}, ppid={1}, times={2}'.format(os.getpid(), os.getppid(), i))
time.sleep(1)
class ChildProcess(multiprocessing.Process):
def __init__(self, process_time):
multiprocessing.Process.__init__(self)
self.process_time = process_time
def run(self):
print('child process begin, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
for i in range(self.process_time):
print('child process pid={0}, ppid={1}, times={2}'.format(os.getpid(), os.getppid(), i))
time.sleep(1)
print('child process end, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
if __name__ == '__main__':
main_process_time = 30
child_process_time = 15
action = MainProcess(main_process_time, child_process_time)
action.excutor()
已开通个人博客,欢迎来访 ^v^