前言
相信有很多人在使用百度翻译的时候会感到这样的疑惑,我该怎样把下图中单词的注音下载下来,那么今天我就教大家如何从下载单个语音到批量下载语音。
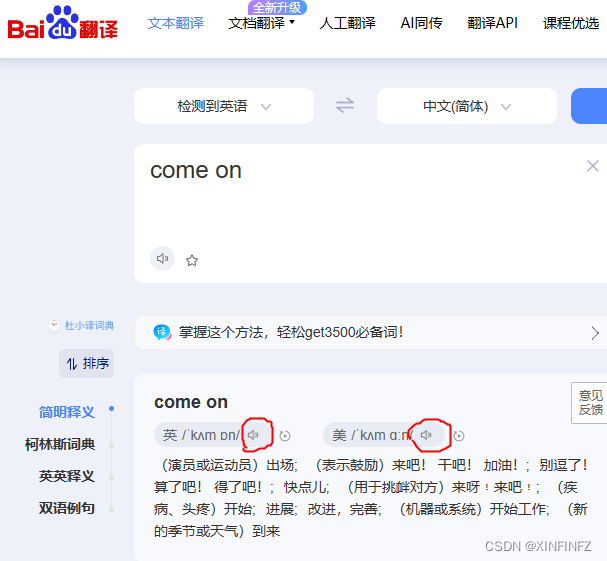
思路
首先我们的行为是在网页上浏览,然后点击语音按钮获取生成的语音,那么这个语音是肯定通过http发送过来的,只要检查网络传输即可。我们先鼠标右键页面空白处,选择“检查”(一般在菜单最下面),打开网页元素的控制台,选中网络,然后我们点击一下语音播放按钮,再点击按类型排序找到media,就可以看到我们获取的资源哩:
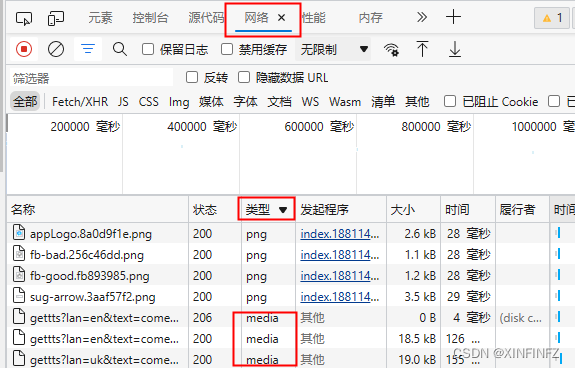
然后我们选中getts的其中一条,右键复制链接地址如下:
https://fanyi.baidu.com/gettts?lan=en&text=come%20on&spd=3&source=web
分析可以发现
lan控制的是英音美音,
text是你输入的文本,
%20表示文本中的空格,
spd表示生成语音的速度,
source表示来源。
然后我们把该链接复制到地址栏,会发现自动下载了该条语音的mp3。那么也就是说只要替换输入的文本,再添加一点小细节,咱们就可以批量下载了。
代码实现
接下来给出实现代码的简单方法,包含从txt一行一行读取文本,配置速度和语音类型,然后文件会以文本名+.mp3的形式保存在同一目录。
import urllib.request
import re
with open('test.txt') as file:
list_url = [line.rstrip() for line in file]
spd = '2' #default is 3 数字越小越慢
lan = 'uk' #uk or en uk英音 en美音
for i in list_url:
text = re.sub("\s+", "%20", i.strip())
print(text)
urllib.request.urlretrieve("https://fanyi.baidu.com/gettts?lan="+lan+"&text="+text+"&spd="+spd+"&source=web",i+".mp3")
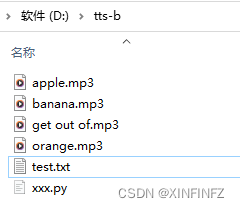
比如我这里准备好了测试文本test.txt:

把以上代码复制保存在xxx.py,然后命令行运行python xxx.py即可生成以下结果:
考虑到短时间大量下载可能造成封锁ip不响应,可以添加sleep语句来缓解执行速度,添加user-header模拟浏览器行为等等,就不说了,都是爬虫的一些简单技巧。