爱奇艺大播放内核运行在 Android Mobile、Android TV、Apple TV、iPhone、iPad、GPad、MAC、Windows PC 等不同业务平台,支持以“直播、点播”为核心的广告、会员、VR、AR、交互视频等业务,经过9年4个大版本迭代,对于用户长视频播放“点击/播放”场景已经达到了相对稳定阶段,性能上基本能满足了所有的长视频播放场景。期间,在播放性能优化上,不同业务均围绕着大播放内核已有的性能展开,大播放内核也会为根据业务场景的不同进行一些迭代优化,犹如同一款发动机,总会针对不同综合工况做出不一样的调校,以便最大限度发挥其性能。
01
背景
01 问题
近两年,随着极速版业务、主 APP 短视频等“瀑布流”模式“滑动/播放”场景的需求增长,原有的开播性能已经无法适应业务场景。为了更好的应对业务需求,业务开发方面,需要创建 2~3 个播放器实例,以便在界面滑动时,采用“预加载+实例切换”的方案达到“零秒”开播的目标,即当前播放的时候,创建另一个或者几个播放器准备后续播放视频,切换的时候,画面可以直接展现出来。多实例的方案在开发上简单快捷,也带来内存使用量、线程数量的暴增,典型的“空间换时间”方式,对于高端设备来讲不会存在性能上的问题,但在中低端设备,则可能会对整个 APP 带来较为严重的卡顿问题。因此,该方案在使用场景上受到了一些限制。
02 调查
从平台角度来看,主要是交互相对较多的 Android 移动设备上问题比较集中。由于在早期版本中就已经支持了“预加载”功能,即播放当前影片时,加载接下来可能要播放的视频流,播放下一个视频是否命中缓存比较容易判断。通过测试数据发现,确实如预期一样,问题并不是出在网络层。相比 Apple 的设备的统一性,Android 设备市场价格从几百元到上万元,性能差异也悬殊。
对于视频行业来讲,一般会从视频播放的能力角度,按分辨率⽀持⾼低、码流⽀持⾼低、H.265/H.264 等 Codec ⽀持等维度划分,可以将 Android 设备按性能简单的分为“⾼、中、低”不同等级的设备,我们计划从这一方面入手调查。为了简化测试流程,进一步优化测试流程,从单机的本地视频播放的测试结果来看,播放业务流程耗时大约在 60ms 左右(即内部消息、数据路由及线程切换等,不同性能会略有差异),主要耗时产生在解码器创建及打开解码器阶段,且与设备性能呈现一定相关性:高端机耗时在 20ms 左右,中低端机平均在 350ms 左右,个别机型达 500ms 以上。
02
解决方案
从上面数据可以得知,达到“零秒”开播的目标,重点解决 Codec 耗时,并优化业务逻辑层面上的耗时。业务逻辑层面耗时,通过架构层面上的优化,相对比较容易解决,但对于硬件耦合极高的解码耗时耗时,似乎没有太好的方案,只能绕开它。经过内部讨论,我们得到以下几种方案,并对这些方案进行了初步分析:
采用多解码器方案
即内核内部创建多解码器,预解码并交替使用,相比 APP 层“多播放器”来讲,可以降低内存、线程数量,也能达到目标。通过前期我们之前的实验结果来看,该方案在中高端机表现还不错,但低端机仍然大概率会有问题,仍然存在明显的弊端。
软解方案
相对来讲软件解码器的创建时间开销基本在 20ms 以内,与高端机的硬件耗时差不多,但弊端也非常明显,由于所有的解码处理都是在 CPU 里进行,解码时需要消耗大量的计算资源,外在表现就是 CPU 占用过高,从而产生功耗过高的问题,特别是高码流视频的解码时尤其明显,对于用户来讲是不可接受的。
采用直播技术架构
即播放器在整个生命周期中,仅打开一次解码器,之后一直使用,节目切换时 Android 平台采用 Adaptive Playback 技术,好处是对于任何点播节目来讲,减少了解码器创建与打开的过程,但弊端也显而易见:所有的点播节目都必须单独维护时间轴,如果涉及到用户 Seek、码流切换、广告播放等等,情况将会异常复杂,且采用单一解码器长时间解码播放也存在稳定上的风险。
01 解决之道
很明显,每种方案都存在一定的优势,也有着不同的“硬伤”问题,这对于一个拥有上亿 DAU 的平台来讲,一点点的小问题都会被无限放大,会极大地伤害一部分用户的体验,更何况明显的“硬伤”问题,完全无法接受。
工程师与科学家的区别在于,科学家会通过现象研究背后的本质或者原理,工程师则利用这些本质创造出一项项提升人们效率的技术。例如科学家会研究“指南针”这项技术背后的磁场,及电磁感应定律,工程师则利用电磁感应定律,发明创造出电磁铁、电动机、发电机、电话、电磁炉等技术,并将这些技术应用到各行各业,造福人类社会。
爱奇艺拥有大量的优秀工程师,他们开发了领先的视频平台,保持了爱奇艺技术平台的先进性,并参与制定一些行业规范。我们团队核心骨干同学在音视频行业深耕达 10 年以上,整个团队具备比较资深的流媒体方面的知识及经验。“将技术玩到极致”这个道理也深深刻入我们团队每位同学的心中,挑战面前,大家显得更加振奋。
一台复杂精密的仪器总是由多种技术通过精湛的工艺组合而成,但在提升该设备性能时,往往不是某一项技术优势决定,需要从全局出发,找出看起来不是那么重要,但又会对整体产生重要影响的那么几项问题,犹如“木桶原理”。
从每期的测试结果来看,我们的长视频播放性能一直处于领先地位。综合测试数据来看,如果能规避硬件耗时,可以将中低端设备的平均时长由 350ms 压缩至 50ms 以内,高端机可以达到 20ms 以内。“硬件耗时”就是那根最短的木板!理论分析结果就是目标!从我们对调查结果的分析来看,之前提到的每种技术方案都能在某一定程度上解决问题,但也都存在一定的弊端。似乎也找不到其他更好的方案了。最终,决定将上述三种技术方案融合在一起,将三者的优势发挥出来,同时一定程度上避免相应的弊端。技术方案存在较高的复杂性,涉及到整个播放架构的调整,为此,我们演化出了下一代播放内核。
02 播放内核5.0
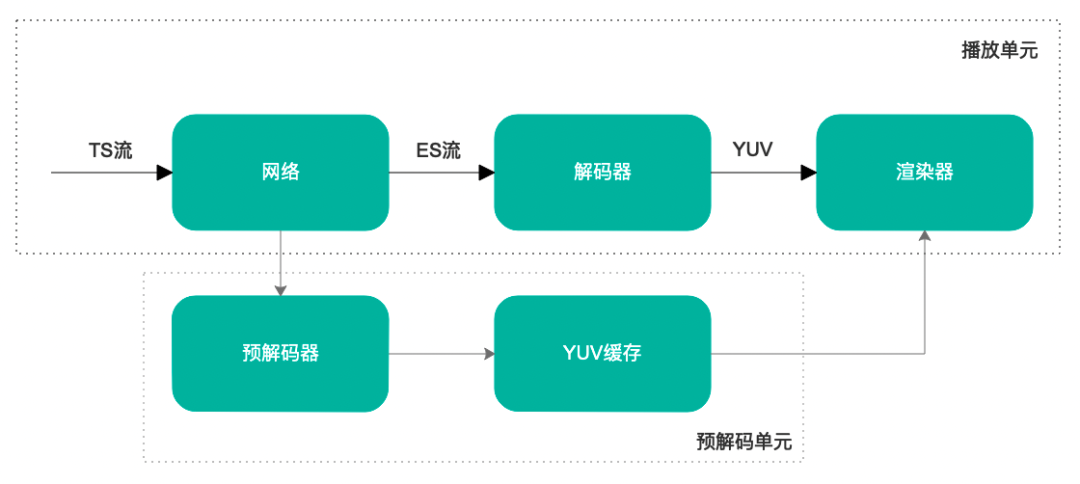
原有的点播模式的播放架构为相对简单的单一流式播放,播放器生命周期中可以播放一个节目或者连续播放多个节目,播放单元模型可以简化为下图,针对上面提到的“业务逻辑层面”耗时优化,主要在此模型中解决:

此版本最大的改进,在于播放架构的调整,为适应“零秒”启播的需求,在原有的架构上,增加了“预解码”处理单元,对接已有的“预加载”单元,与播放实例解耦合,这样就可以独立于播放实例,不影响现有 APP 层对播放内核的调用规则,最大程度降低对业务的影响,确保了 API 的向下兼容。“预解码”处理单元可以为多个播放实例提供“服务”,每个播放实例在开始播放当前节目的时候,会从“预解码”单元获取当前节目的数据,如果已经存在预解码数据,则直接渲染,这样就完全绕过最耗时的解码阶段。在整个内核周期中,独立的“预解码”单元只创建一次,并优先使用硬件解码器,在硬解码器失败后,采用“软解”兜底,在有机会的时候,仍然会重新创建硬件解码器,确保其可用性。使用该处理单元的目的是获取节目起始位置的一帧或多帧图片,不需要关注其 PTS,因此,该解码器可以使用直播模式,同时规避了维护时间戳的复杂度。简化后的播放模型如下图所示:
基于高通骁龙450芯片,测试数据对比如下(时间单位为ms):
总耗时 |
业务耗时 |
解码渲染耗时 |
|
4.0 |
395.85 |
72.30 |
323.55 |
5.0 |
35.14 |
24.21 |
10.93 |
最终的产品效果如下:
至此,300ms耗时优化基本已经达成,部分芯片上的效果超过预期。但我们前进的道路并未因此而结束,基于5.0版本,我们会继续创造出更多的惊喜。

也许你还想看
 关注我们,更多精彩内容陪伴你!
关注我们,更多精彩内容陪伴你!