不确定性区间
默认情况下,Prophet 将返回预测的不确定性区间yhat。这些不确定性区间背后有几个重要的假设。
预测中存在三个不确定性来源:趋势的不确定性、季节性估计的不确定性和额外的观测噪声。
趋势的不确定性
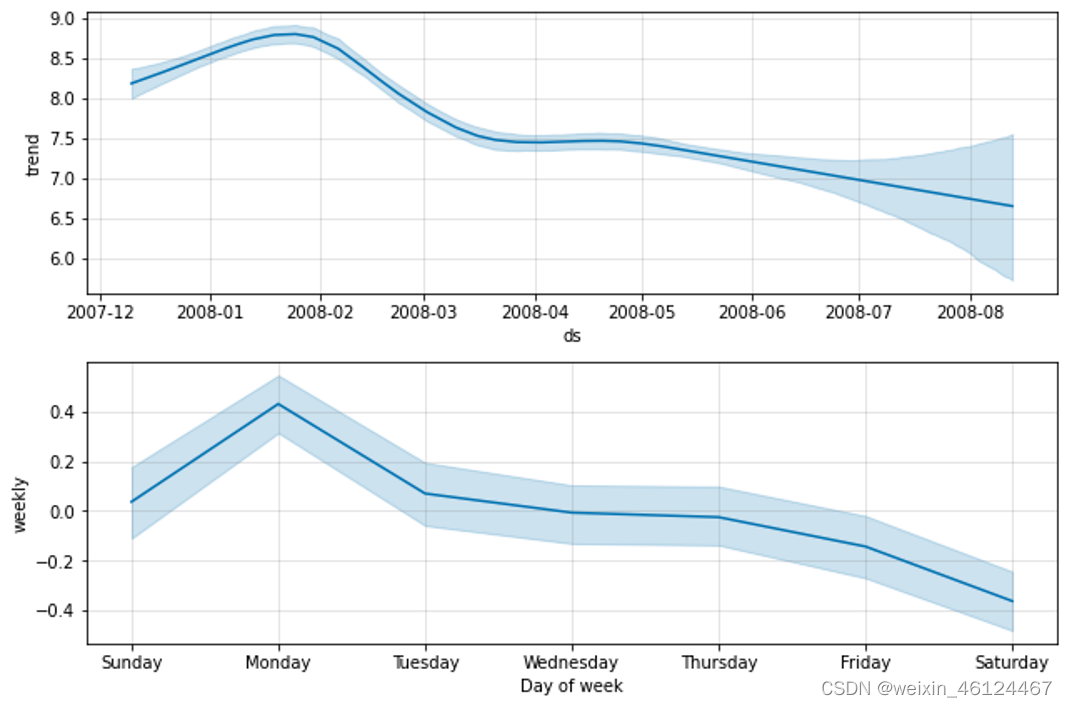
预测中最大的不确定性来源是未来趋势变化的潜力。我们在本文档中已经看到的时间序列显示了历史上明显的趋势变化。Prophet 能够检测并拟合这些,但我们应该期待哪些趋势变化?不可能确切知道,所以我们做我们能做的最合理的事情,我们假设未来会看到类似历史的趋势变化。特别是,我们假设未来趋势变化的平均频率和幅度将与我们在历史中观察到的相同。我们向前预测这些趋势变化,并通过计算它们的分布我们获得不确定性区间。
这种测量不确定性的方法的一个特性是允许速率具有更高的灵活性,通过增加changepoint_prior_scale,将增加预测的不确定性。这是因为如果我们对历史中更多的利率变化进行建模,那么我们将期望未来更多,并使不确定性区间成为过度拟合的有用指标。
不确定区间的宽度(默认为 80%)可以使用参数设置interval_width:
定义不确定性区间为95%,默认是80%
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
季节性的不确定性
默认情况下,Prophet 只会返回趋势和观察噪声的不确定性。要获得季节性的不确定性,您必须进行完整的贝叶斯采样。这是使用参数mcmc.samples(默认为 0)完成的。我们在快速入门的 Peyton Manning 数据的前六个月执行此操作:
m = Prophet(mcmc_samples=300)
forecast = m.fit(df).predict(future)
结果
异常值
什么意思?
数据中有脏数据存在,导致预测结果不准确,即不确定性区间变大
异常值影响 Prophet 预测的主要方式有两种。在这里,我们对之前记录的 Wikipedia 访问 R 页面进行了预测,但有一组错误数据:
趋势预测似乎合理,但不确定性区间似乎太宽了。Prophet 能够处理历史中的异常值,但只能将它们与趋势变化进行拟合。不确定性模型然后预期类似幅度的未来趋势变化。
处理异常值的最佳方法是删除它们 - Prophet 没有丢失数据的问题。如果您将它们的值设置为NA在历史中,但将日期保留在 中future,那么 Prophet 将为您提供对它们的值的预测。
原始没有脏数据
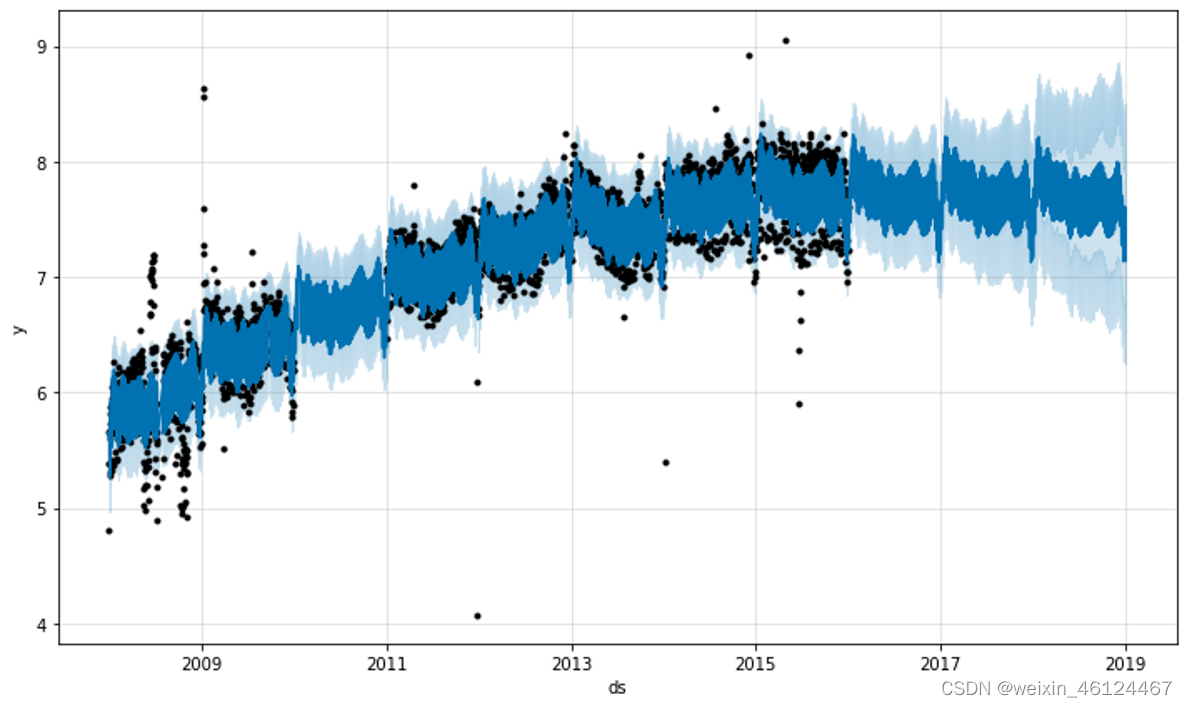
增加脏数据
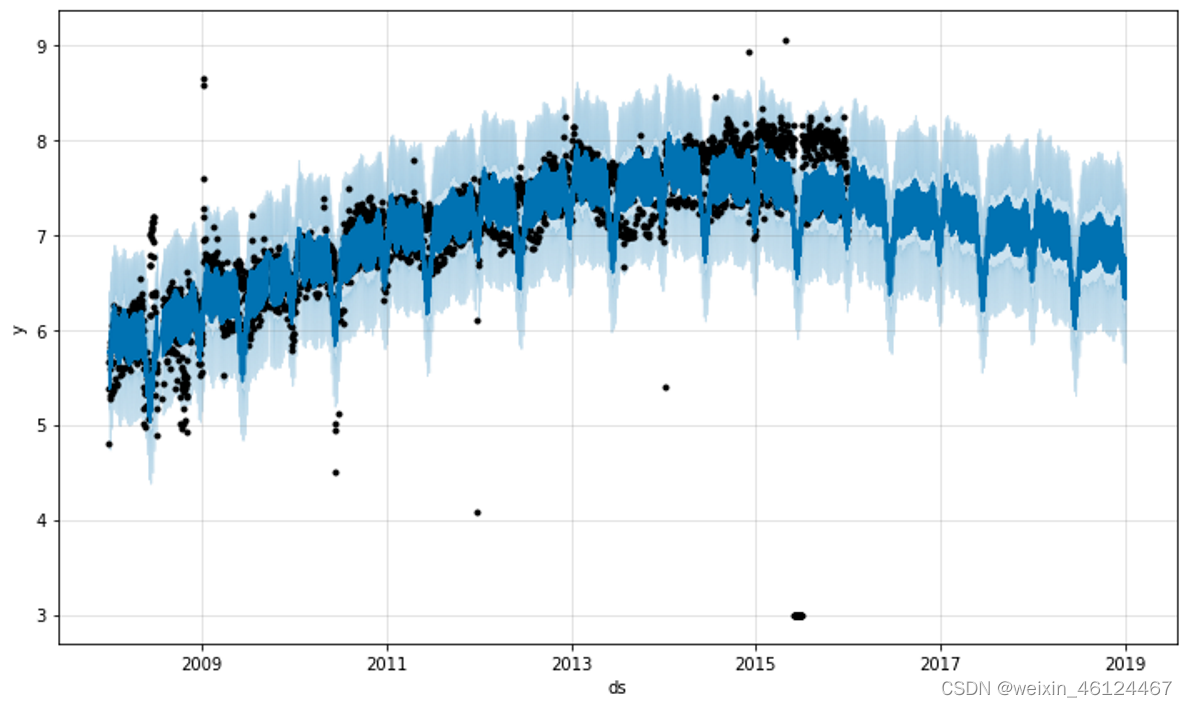
解决办法是删除脏数据