一、需求来源
首先来看一下,整个需求的来源:当把应用迁移到 Kubernetes 之后,要如何去保障应用的健康与稳定呢?其实很简单,可以从两个方面来进行增强:
- 首先是提高应用的可观测性;
- 第二是提高应用的可恢复能力。
从可观测性上来讲,可以在三个方面来去做增强:
- 首先是应用的健康状态上面,可以实时地进行观测;
- 第二个是可以获取应用的资源使用情况;
- 第三个是可以拿到应用的实时日志,进行问题的诊断与分析。
当出现了问题之后,首先要做的事情是要降低影响的范围,进行问题的调试与诊断。最后当出现问题的时候,理想的状况是:可以通过和 K8s 集成的自愈机制进行完整的恢复。
二、Liveness 与 Readiness
本小节为大家介绍 Liveness probe 和 eadiness probe。
应用健康状态-初识 Liveness 与 Readiness
Liveness probe 也叫就绪指针,用来判断一个 pod 是否处在就绪状态。当一个 pod 处在就绪状态的时候,它才能够对外提供相应的服务,也就是说接入层的流量才能打到相应的 pod。当这个 pod 不处在就绪状态的时候,接入层会把相应的流量从这个 pod 上面进行摘除。
来看一下简单的一个例子:
如下图其实就是一个 Readiness 就绪的一个例子:
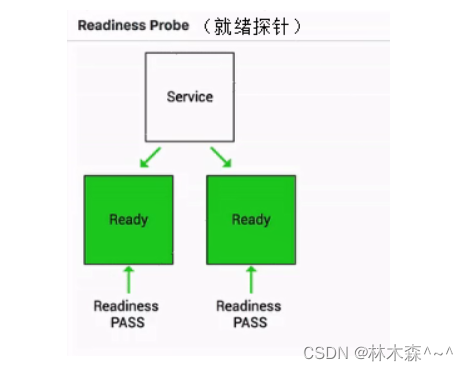
当这个 pod 指针判断一直处在失败状态的时候,其实接入层的流量不会打到现在这个 pod 上。
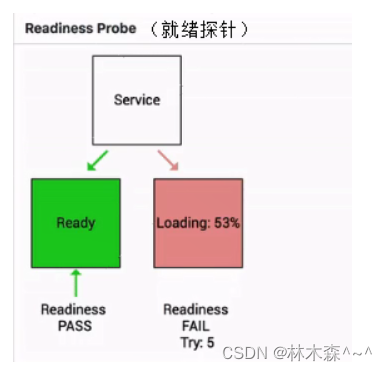
当这个 pod 的状态从 FAIL 的状态转换成 success 的状态时,它才能够真实地承载这个流量。
Liveness 指针也是类似的,它是存活指针,用来判断一个 pod 是否处在存活状态。当一个 pod 处在不存活状态的时候,会出现什么事情呢?
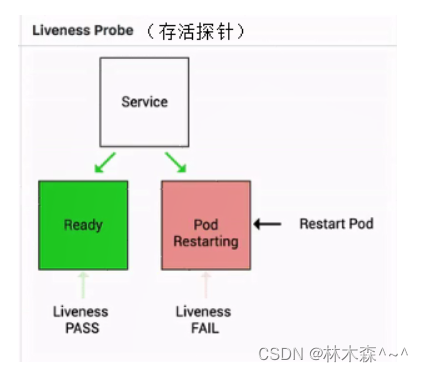
这个时候会由上层的判断机制来判断这个 pod 是否需要被重新拉起。那如果上层配置的重启策略是 restart always 的话,那么此时这个 pod 会直接被重新拉起。
应用健康状态-使用方式
接下来看一下 Liveness 指针和 Readiness 指针的具体的用法。
探测方式
Liveness 指针和 Readiness 指针支持三种不同的探测方式:
- 第一种是 httpGet。它是通过发送 http Get 请求来进行判断的,当返回码是 200-399 之间的状态码时,标识这个应用是健康的;
- 第二种探测方式是 Exec。它是通过执行容器中的一个命令来判断当前的服务是否是正常的,当命令行的返回结果是 0,则标识容器是健康的;
- 第三种探测方式是 tcpSocket。它是通过探测容器的 IP 和 Port 进行 TCP 健康检查,如果这个 TCP 的链接能够正常被建立,那么标识当前这个容器是健康的。
探测结果
从探测结果来讲主要分为三种:
- 第一种是 success,当状态是 success 的时候,表示 container 通过了健康检查,也就是 Liveness probe 或 Readiness probe 是正常的一个状态;
- 第二种是 Failure,Failure 表示的是这个 container 没有通过健康检查,如果没有通过健康检查的话,那么此时就会进行相应的一个处理,那在 Readiness 处理的一个方式就是通过 service。service 层将没有通过 Readiness 的 pod 进行摘除,而 Liveness 就是将这个 pod 进行重新拉起,或者是删除。
- 第三种状态是 Unknown,Unknown 是表示说当前的执行的机制没有进行完整的一个执行,可能是因为类似像超时或者像一些脚本没有及时返回,那么此时 Readiness-probe 或 Liveness-probe 会不做任何的一个操作,会等待下一次的机制来进行检验。
那在 kubelet 里面有一个叫 ProbeManager 的组件,这个组件里面会包含 Liveness-probe 或 Readiness-probe,这两个 probe 会将相应的 Liveness 诊断和 Readiness 诊断作用在 pod 之上,来实现一个具体的判断。
应用健康状态-Pod Probe Spec
下面介绍这三种方式不同的检测方式的一个 yaml 文件的使用。
首先先看一下 exec,exec 的使用其实非常简单。如下图所示,大家可以看到这是一个 Liveness probe,它里面配置了一个 exec 的一个诊断。接下来,它又配置了一个 command 的字段,这个 command 字段里面通过 cat 一个具体的文件来判断当前 Liveness probe 的状态,当这个文件里面返回的结果是 0 时,或者说这个命令返回是 0 时,它会认为此时这个 pod 是处在健康的一个状态。

那再来看一下这个 httpGet,httpGet 里面有一个字段是路径,第二个字段是 port,第三个是 headers。这个地方有时需要通过类似像 header 头的一个机制做 health 的一个判断时,需要配置这个 header,通常情况下,可能只需要通过 health 和 port 的方式就可以了。

第三种是 tcpSocket,tcpSocket 的使用方式其实也比较简单,你只需要设置一个检测的端口,像这个例子里面使用的是 8080 端口,当这个 8080 端口 tcp connect 审核正常被建立的时候,那 tecSocket,Probe 会认为是健康的一个状态。

此外还有如下的五个参数,是 Global 的参数。
-
第一个参数叫 initialDelaySeconds,它表示的是说这个 pod 启动延迟多久进行一次检查,比如说现在有一个 Java 的应用,它启动的时间可能会比较长,因为涉及到 jvm 的启动,包括 Java 自身 jar 的加载。所以前期,可能有一段时间是没有办法被检测的,而这个时间又是可预期的,那这时可能要设置一下 initialDelaySeconds;
-
第二个是 periodSeconds,它表示的是检测的时间间隔,正常默认的这个值是 10 秒;
-
第三个字段是 timeoutSeconds,它表示的是检测的超时时间,当超时时间之内没有检测成功,那它会认为是失败的一个状态;
-
第四个是 successThreshold,它表示的是:当这个 pod 从探测失败到再一次判断探测成功,所需要的阈值次数,默认情况下是 1 次,表示原本是失败的,那接下来探测这一次成功了,就会认为这个 pod 是处在一个探针状态正常的一个状态;
-
最后一个参数是 failureThreshold,它表示的是探测失败的重试次数,默认值是 3,表示的是当从一个健康的状态连续探测 3 次失败,那此时会判断当前这个pod的状态处在一个失败的状态。
应用健康状态-Liveness 与 Readiness 总结
接下来对 Liveness 指针和 Readiness 指针进行一个简单的总结。
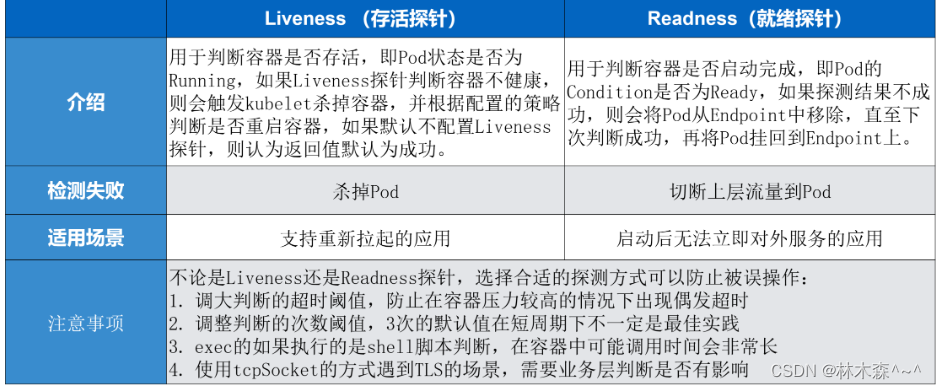
Liveness 指针是存活指针,它用来判断容器是否存活、判断 pod 是否 running。如果 Liveness 指针判断容器不健康,此时会通过 kubelet 杀掉相应的 pod,并根据重启策略来判断是否重启这个容器。如果默认不配置 Liveness 指针,则默认情况下认为它这个探测默认返回是成功的。
Readiness 指针用来判断这个容器是否启动完成,即 pod 的 condition 是否 ready。如果探测的一个结果是不成功,那么此时它会从 pod 上 Endpoint 上移除,也就是说从接入层上面会把前一个 pod 进行摘除,直到下一次判断成功,这个 pod 才会再次挂到相应的 endpoint 之上。
在使用 Liveness 指针和 Readiness 指针的时候有一些注意事项。因为不论是 Liveness 指针还是 Readiness 指针都需要配置合适的探测方式,以免被误操作。
-
第一个是调大超时的阈值,因为在容器里面执行一个 shell 脚本,它的执行时长是非常长的,平时在一台 ecs 或者在一台 vm 上执行,可能 3 秒钟返回的一个脚本在容器里面需要 30 秒钟。所以这个时间是需要在容器里面事先进行一个判断的,那如果可以调大超时阈值的方式,来防止由于容器压力比较大的时候出现偶发的超时;
-
第二个是调整判断的一个次数,3 次的默认值其实在比较短周期的判断周期之下,不一定是最佳实践,适当调整一下判断的次数也是一个比较好的方式;
-
第三个是 exec,如果是使用 shell 脚本的这个判断,调用时间会比较长,比较建议大家可以使用类似像一些编译性的脚本 Golang 或者一些 C 语言、C++ 编译出来的这个二进制的 binary 进行判断,那这种通常会比 shell 脚本的执行效率高 30% 到 50%;
-
第四个是如果使用 tcpSocket 方式进行判断的时候,如果遇到了 TLS 的服务,那可能会造成后边 TLS 里面有很多这种未健全的 tcp connection,那这个时候需要自己对业务场景上来判断,这种的链接是否会对业务造成影响。