操作系统
前言
- 本篇博客是基于彭东的操作系统实战45讲的内容做的学习笔记,目的在于总结和排坑
- 专栏链接:https://time.geekbang.org/column/intro/411
- 环境是运行在VM上的Ubuntu20
- 扫码购买有优惠哦

一.程序的运行过程:从代码到机器运行
#include "stdio.h"
int main(int argc, char const *argv[])
{
printf("Hello World!\n");
return 0;
}
这段代码是每个学习C语言人的第一行代码,让我们学习一下为什么能在屏幕上输出HelloWord,它底层的原理是什么?
计算机硬件是无法直接运行这个 C 语言文本程序代码的,需要 C 语言编译器,把这个代码编译成具体硬件平台的二进制代码。再由具体操作系统建立进程,把这个二进制文件装进其进程的内存空间中,才能运行。
1.程序编译过程
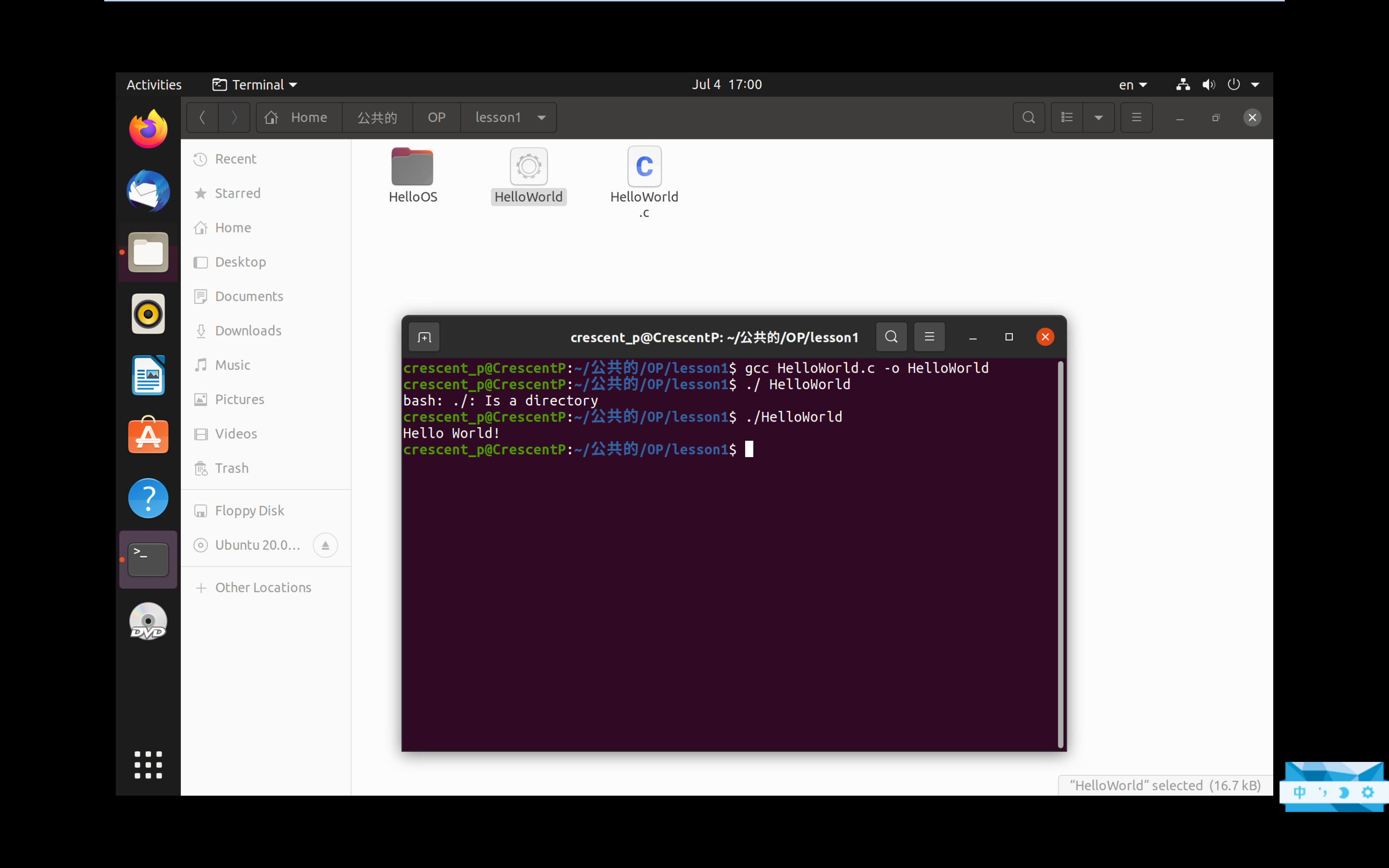
我们使用命令
gcc HelloWorld.c -o HelloWorld
可以发现编译生成了一个HelloWord的文件,接着使用
./HelloWord
可以发现打印出了HelloWorld!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b1OU7VSV-1634117695803)(操作系统.assets/image-20210831194048546.png)]
GCC 只是完成编译工作的驱动程序,它会根据编译流程分别调用预处理程序、编译程序、汇编程序、链接程序来完成具体工作。
具体流程图:
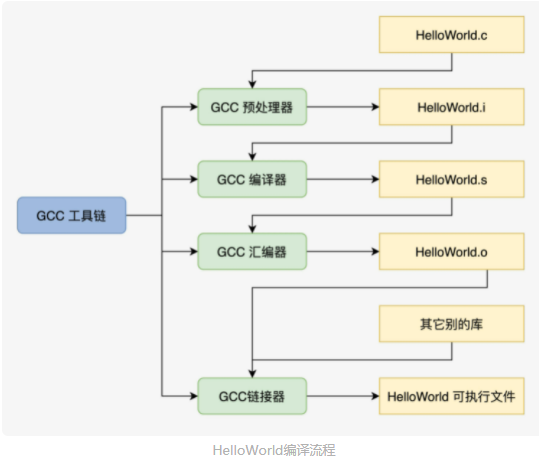
其实,我们也可以手动控制以上这个编译流程,从而留下中间文件方便研究:
- gcc HelloWorld.c -E -o HelloWorld.i 预处理:加入头文件,替换宏。
- gcc HelloWorld.c -S -c HelloWorld.s 编译:包含预处理,将 C 程序转换成汇编程序。
- gcc HelloWorld.c -c HelloWorld.o 汇编:包含预处理和编译,将汇编程序转换成可链接的二进制程序。
- gcc HelloWorld.c -o HelloWorld 链接:包含以上所有操作,将可链接的二进制程序和其它别的库链接在一起,形成可执行的程序文件。
2程序装载执行
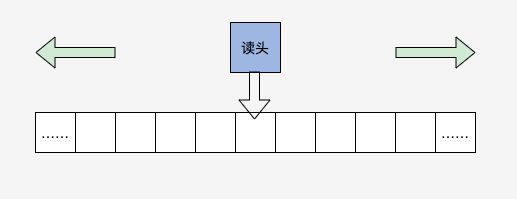
图灵机是一个抽象的模型,它是这样的:有一条无限长的纸带,纸带上有无限个小格子,小格子中写有相关的信息,纸带上有一个读头,读头能根据纸带小格子里的信息做相关的操作并能来回移动
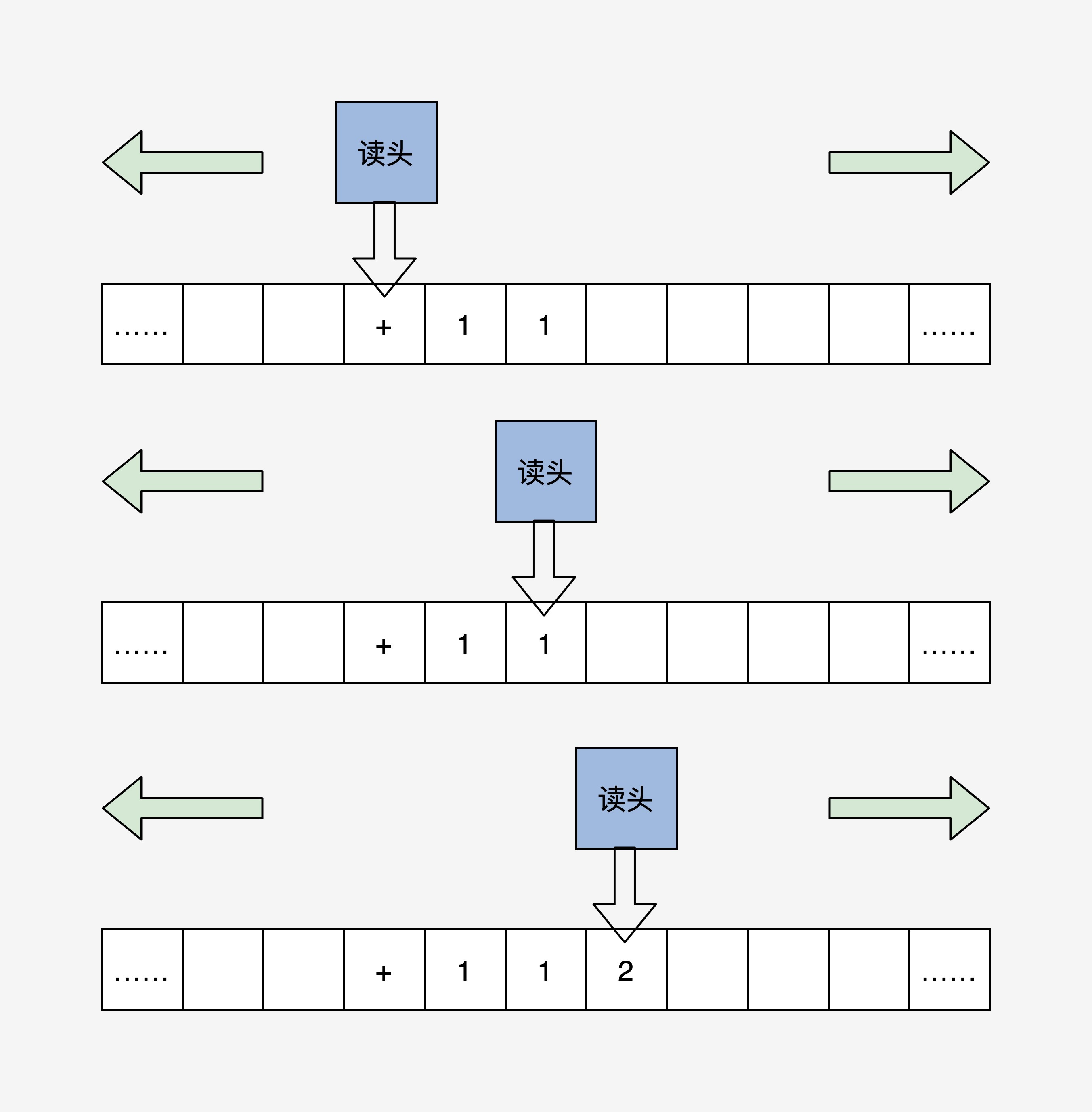
图灵机执行一下“1+1=2”的计算,我们定义读头读到“+”之后,就依次移动读头两次并读取格子中的数据,最后读头计算把结果写入第二个数据的下一个格子里,整个过程如下图
冯诺依曼提出了电子计算机使用二进制数制系统和储存程序,并按照程序顺序执行,他的电子计算机理论叫冯诺依曼体系结构
根据冯诺依曼体系结构构成的计算机,必须具有如下功能:
- 把程序和数据装入到计算机中;
- 必须具有长期记住程序、数据的中间结果及最终运算结果;
- 完成各种算术、逻辑运算和数据传送等数据加工处理;
- 根据需要控制程序走向,并能根据指令控制机器的各部件协调操作;
- 能够按照要求将处理的数据结果显示给用户。
为了完成上述的功能,计算机必须具备五大基本组成部件:
- 装载数据和程序的输入设备;
- 记住程序和数据的存储器;
- 完成数据加工处理的运算器;
- 控制程序执行的控制器;
- 显示处理结果的输出设备。
根据冯诺依曼的理论,我们只要把图灵机的几个部件换成电子设备,就可以变成一个最小核心的电子计算机
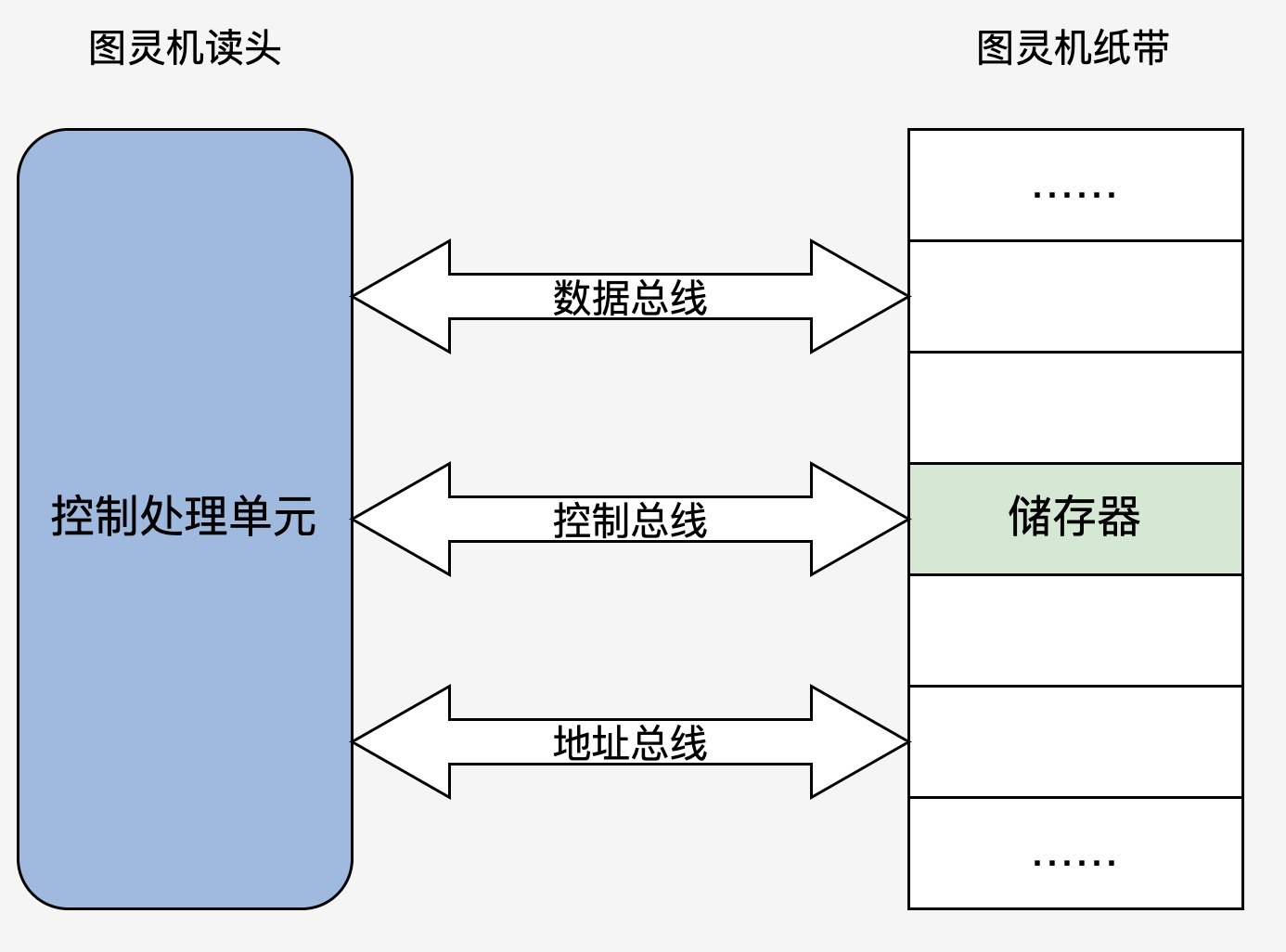
这次我们发现读头不再来回移动了,而是靠地址总线寻找对应的“纸带格子”。读取写入数据由数据总线完成,而动作的控制就是控制总线的职责了。
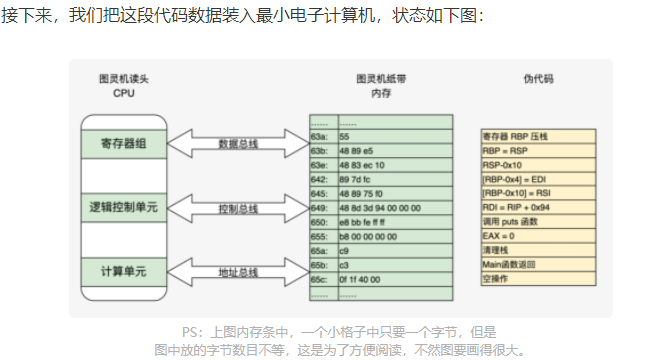
3.更形象地将 HelloWorld 程序装入原型计算机
我们尝试将 HelloWorld 程序装入这个原型计算机,在装入之前,我们先要搞清楚 HelloWorld 程序中有什么
我们通过
objdump -d HelloWorld
可以得到HelloWorld.dump,其中有很多库代码(只需关注 main 函数相关的代码),如下图:
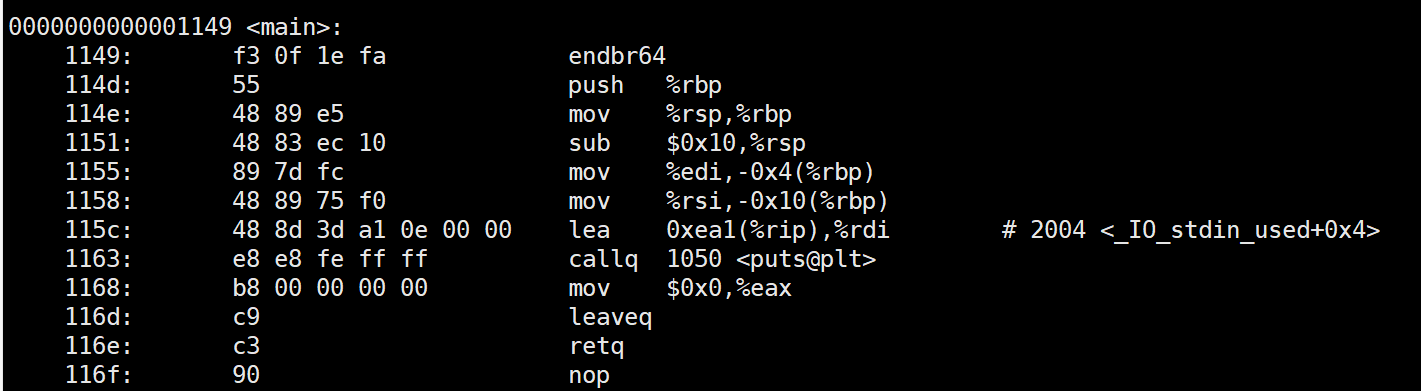
分成四列:第一列为地址;第二列为十六进制,表示真正装入机器中的代码数据;第三列是对应的汇编代码;第四列是相关代码的注释。这是 x86_64 体系的代码,由此可以看出 x86 CPU 是变长指令集。
二.几行汇编几行C:实现一个最简单的内核
在写 Hello OS 之前,我们先要搞清楚 Hello OS 的引导流程,如下图所示
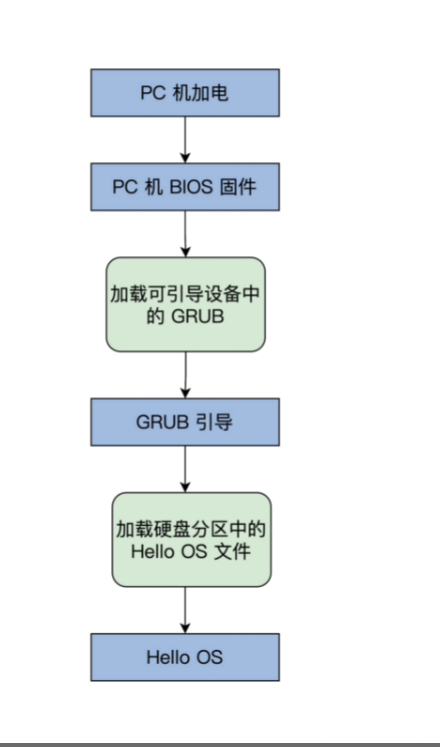
PC 机 BIOS 固件是固化在 PC 机主板上的 ROM 芯片中的,掉电也能保存,PC 机上电后的第一条指令就是 BIOS 固件中的,它负责检测和初始化 CPU、内存及主板平台,然后加载引导设备(大概率是硬盘)中的第一个扇区数据,到 0x7c00 地址开始的内存空间,再接着跳转到 0x7c00 处执行指令,在我们这里的情况下就是 GRUB 引导程序。
就是一上电,就执行BIOS的指令,CS:IP指向BIOS,BIOS指令会检查和各种硬件,将磁盘0磁道0扇区读入到内存的0x7C00中,然后设置cs=0x07c0,ip=0x000,那么cs:ip就是指向0x7c00的位置,就是刚才从磁盘读入的内容
1.Hello OS 引导汇编代码
我们先来写一段汇编代码。但是为什么不能直接用 C?
C 作为通用的高级语言,不能直接操作特定的硬件,而且 C 语言的函数调用、函数传参,都需要用栈。
栈简单来说就是一块内存空间,其中数据满足后进先出的特性,它由 CPU 特定的栈寄存器指向,所以我们要先用汇编代码处理好这些 C 语言的工作环境。
entry.asm
MBT_HDR_FLAGS EQU 0x00010003
MBT_HDR_MAGIC EQU 0x1BADB002 ;多引导协议头魔数
MBT_HDR2_MAGIC EQU 0xe85250d6 ;第二版多引导协议头魔数
global _start ;导出_start符号
extern main ;导入外部的main函数符号
[section .start.text] ;定义.start.text代码节
[bits 32] ;汇编成32位代码
_start:
jmp _entry
ALIGN 8
mbt_hdr:
dd MBT_HDR_MAGIC
dd MBT_HDR_FLAGS
dd -(MBT_HDR_MAGIC+MBT_HDR_FLAGS)
dd mbt_hdr
dd _start
dd 0
dd 0
dd _entry
;以上是GRUB所需要的头
ALIGN 8
mbt2_hdr:
DD MBT_HDR2_MAGIC
DD 0
DD mbt2_hdr_end - mbt2_hdr
DD -(MBT_HDR2_MAGIC + 0 + (mbt2_hdr_end - mbt2_hdr))
DW 2, 0
DD 24
DD mbt2_hdr
DD _start
DD 0
DD 0
DW 3, 0
DD 12
DD _entry
DD 0
DW 0, 0
DD 8
mbt2_hdr_end:
;以上是GRUB2所需要的头
;包含两个头是为了同时兼容GRUB、GRUB2
ALIGN 8
_entry:
;关中断
cli
;关不可屏蔽中断
in al, 0x70
or al, 0x80
out 0x70,al
;重新加载GDT
lgdt [GDT_PTR]
jmp dword 0x8 :_32bits_mode
_32bits_mode:
;下面初始化C语言可能会用到的寄存器
mov ax, 0x10
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
xor eax,eax
xor ebx,ebx
xor ecx,ecx
xor edx,edx
xor edi,edi
xor esi,esi
xor ebp,ebp
xor esp,esp
;初始化栈,C语言需要栈才能工作
mov esp,0x9000
;调用C语言函数main
call main
;让CPU停止执行指令
halt_step:
halt
jmp halt_step
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
k16cd_dsc: dq 0x00009e000000ffff
k16da_dsc: dq 0x000092000000ffff
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1
GDTBASE dd GDT_START

2.Hello OS 的主函数
上面的汇编代码调用了 main 函数,而在其代码中并没有看到其函数体,而是从外部引入了一个符号。
那是因为这个函数是用 C 语言写的在(/lesson01/HelloOS/main.c)中,最终它们分别由 nasm 和 GCC 编译成可链接模块,由 LD 链接器链接在一起,形成可执行的程序文件:
main.c
#include "vgastr.h"
void main()
{
printf("Hello OS!");
return;
}
以上这段代码,你应该很熟悉了吧?不过这不是应用程序的 main 函数,而是 Hello OS 的 main 函数。
其中的 printf 也不是应用程序库中的那个 printf 了,而是需要我们自己实现了。
3.控制计算机屏幕
下面,我们来看看显卡的字符模式的工作细节。
它把屏幕分成 24 行,每行 80 个字符,把这(24*80)个位置映射到以 0xb8000 地址开始的内存中,每两个字节对应一个字符,其中一个字节是字符的 ASCII 码,另一个字节为字符的颜色值。如下图所示
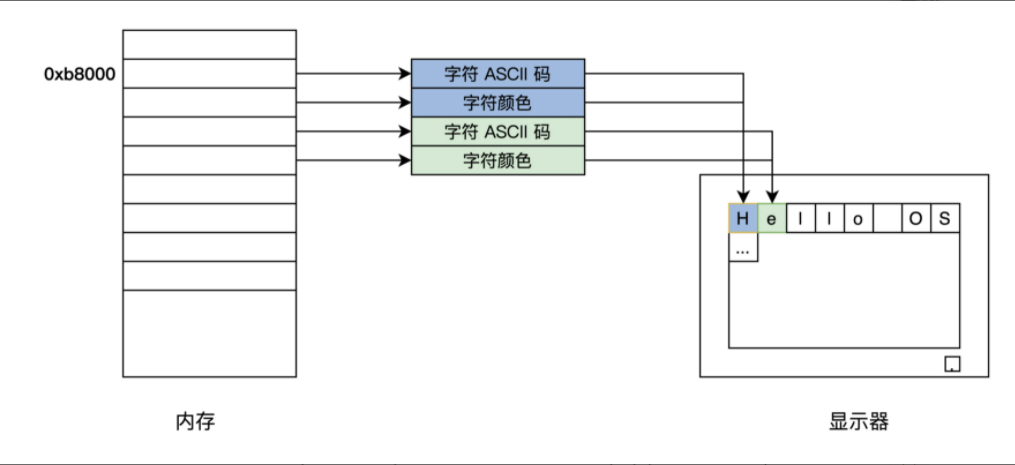
明白了显卡的字符模式的工作细节,下面我们开始写代码。
这里先提个醒:C 语言字符串是以 0 结尾的,其字符编码通常是 utf8,而 utf8 编码对 ASCII 字符是兼容的,即英文字符的 ASCII 编码和 utf8 编码是相等的(关于utf8编码你可以自行了解)。
vgastr.c
void _strwrite(char* string)
{
char* p_strdst = (char*)(0xb8000);//指向显存的开始地址
while (*string)
{
*p_strdst = *string++;
p_strdst += 2;
}
return;
}
void printf(char* fmt, ...)
{
_strwrite(fmt);
return;
}
vgastr.h
代码很简单,printf 函数直接调用了 _strwrite 函数,而 _strwrite 函数正是将字符串里每个字符依次定入到 0xb8000 地址开始的显存中,而 p_strdst 每次加 2,这也是为了跳过字符的颜色信息的空间。
void _strwrite(char* string);
void printf(char* fmt, ...);
4.编译和安装 Hello OS
在安装之前,我们要进行系统编译,即把每个代码模块编译最后链接成可执行的二进制文件。
对于我们 Hello OS 的编译工作来说特别简单,因为总共才三个代码文件,最多四条命令就可以完成。
但是以后我们 Hello OS 的文件数量会爆炸式增长,一个成熟的商业操作系统更是多达几万个代码模块文件,几千万行的代码量,是这世间最复杂的软件工程之一。所以需要一个牛逼的工具来控制这个巨大的编译过程。
make 工具
make 历史悠久,小巧方便,也是很多成熟操作系统编译所使用的构建工具。
在软件开发中,make 是一个工具程序,它读取一个叫“Makefile”的文件,也是一种文本文件,这个文件中写好了构建软件的规则,它能根据这些规则自动化构建软件。
Makefile 文件中规则是这样的:首先有一个或者多个构建目标称为“target”;目标后面紧跟着用于构建该目标所需要的文件,目标下面是构建该目标所需要的命令及参数。
与此同时,它也检查文件的依赖关系,如果需要的话,它会调用一些外部软件来完成任务。
第一次构建目标后,下一次执行 make 时,它会根据该目标所依赖的文件是否更新决定是否编译该目标,如果所依赖的文件没有更新且该目标又存在,那么它便不会构建该目标。这种特性非常有利于编译程序源代码。
为了让你进一步了解 make 的使用,接下来我们一起看一个有关 makefile 的例子:
CC = gcc #定义一个宏CC 等于gcc
CFLAGS = -c #定义一个宏 CFLAGS 等于-c
OBJS_FILE = file.o file1.o file2.o file3.o file4.o #定义一个宏
.PHONY : all everything #定义两个伪目标all、everything
all:everything #伪目标all依赖于伪目标everything
everything :$(OBJS_FILE) #伪目标everything依赖于OBJS_FILE,而OBJS_FILE是宏会被
#替换成file.o file1.o file2.o file3.o file4.o
%.o : %.c
$(CC) $(CFLAGS) -o $@ $<

1.编译
下面我们用一张图来描述我们 Hello OS 的编译过程,如下所示:
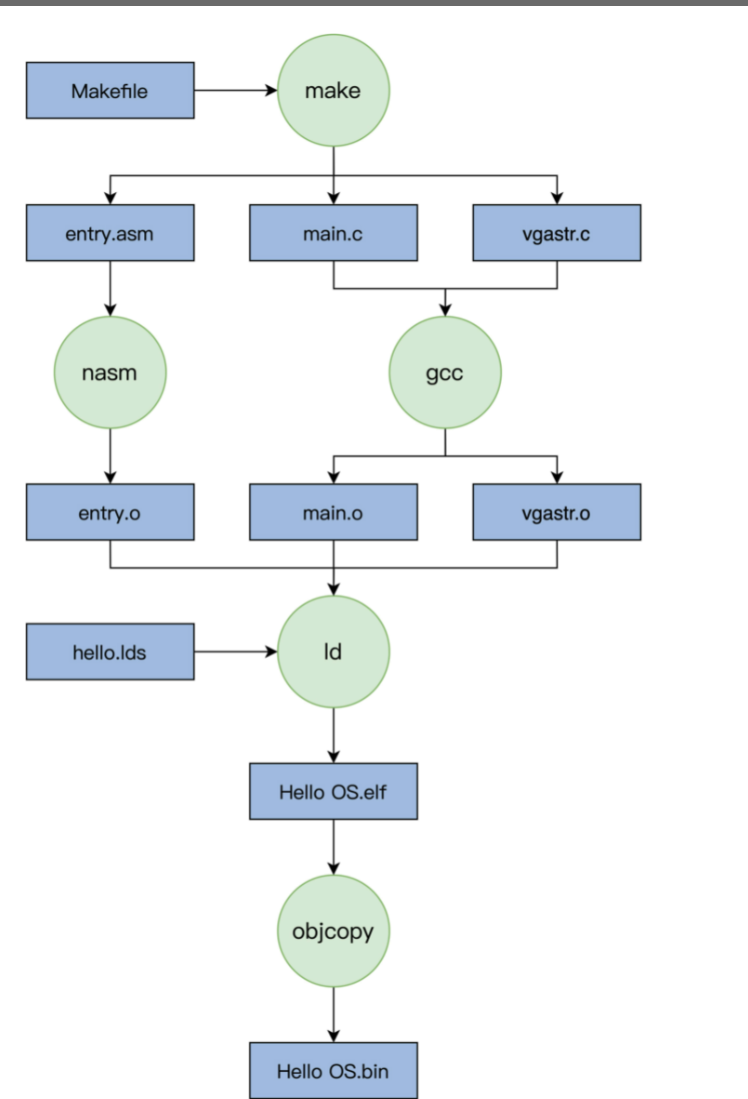
由上图可知,除了entry.asm,mian.c,vgastr.c以外还需要hello.lds,以及vgastr.c中可以看到需要vgastr.h
通过make指令就可以编译出我们需要的文件了
MAKEFLAGS = -sR
MKDIR = mkdir
RMDIR = rmdir
CP = cp
CD = cd
DD = dd
RM = rm
ASM = nasm
CC = gcc
LD = ld
OBJCOPY = objcopy
ASMBFLAGS = -f elf -w-orphan-labels
CFLAGS = -c -Os -std=c99 -m32 -Wall -Wshadow -W -Wconversion -Wno-sign-conversion -fno-stack-protector -fomit-frame-pointer -fno-builtin -fno-common -ffreestanding -Wno-unused-parameter -Wunused-variable
LDFLAGS = -s -static -T hello.lds -n -Map HelloOS.map
OJCYFLAGS = -S -O binary
HELLOOS_OBJS :=
HELLOOS_OBJS += entry.o main.o vgastr.o
HELLOOS_ELF = HelloOS.elf
HELLOOS_BIN = HelloOS.bin
.PHONY : build clean all link bin
all: clean build link bin
clean:
$(RM) -f *.o *.bin *.elf
build: $(HELLOOS_OBJS)
link: $(HELLOOS_ELF)
$(HELLOOS_ELF): $(HELLOOS_OBJS)
$(LD) $(LDFLAGS) -o $@ $(HELLOOS_OBJS)
bin: $(HELLOOS_BIN)
$(HELLOOS_BIN): $(HELLOOS_ELF)
$(OBJCOPY) $(OJCYFLAGS) $< $@
%.o : %.asm
$(ASM) $(ASMBFLAGS) -o $@ $<
%.o : %.c
$(CC) $(CFLAGS) -o $@ $<
2.安装 Hello OS
经过上述流程,我们就会得到 Hello OS.bin 文件,但是我们还要让 GRUB 能够找到它,才能在计算机启动时加载它。这个过程我们称为安装,不过这里没有写安装程序,得我们手动来做。
经研究发现,GRUB 在启动时会加载一个 grub.cfg 的文本文件,根据其中的内容执行相应的操作,其中一部分内容就是启动项。
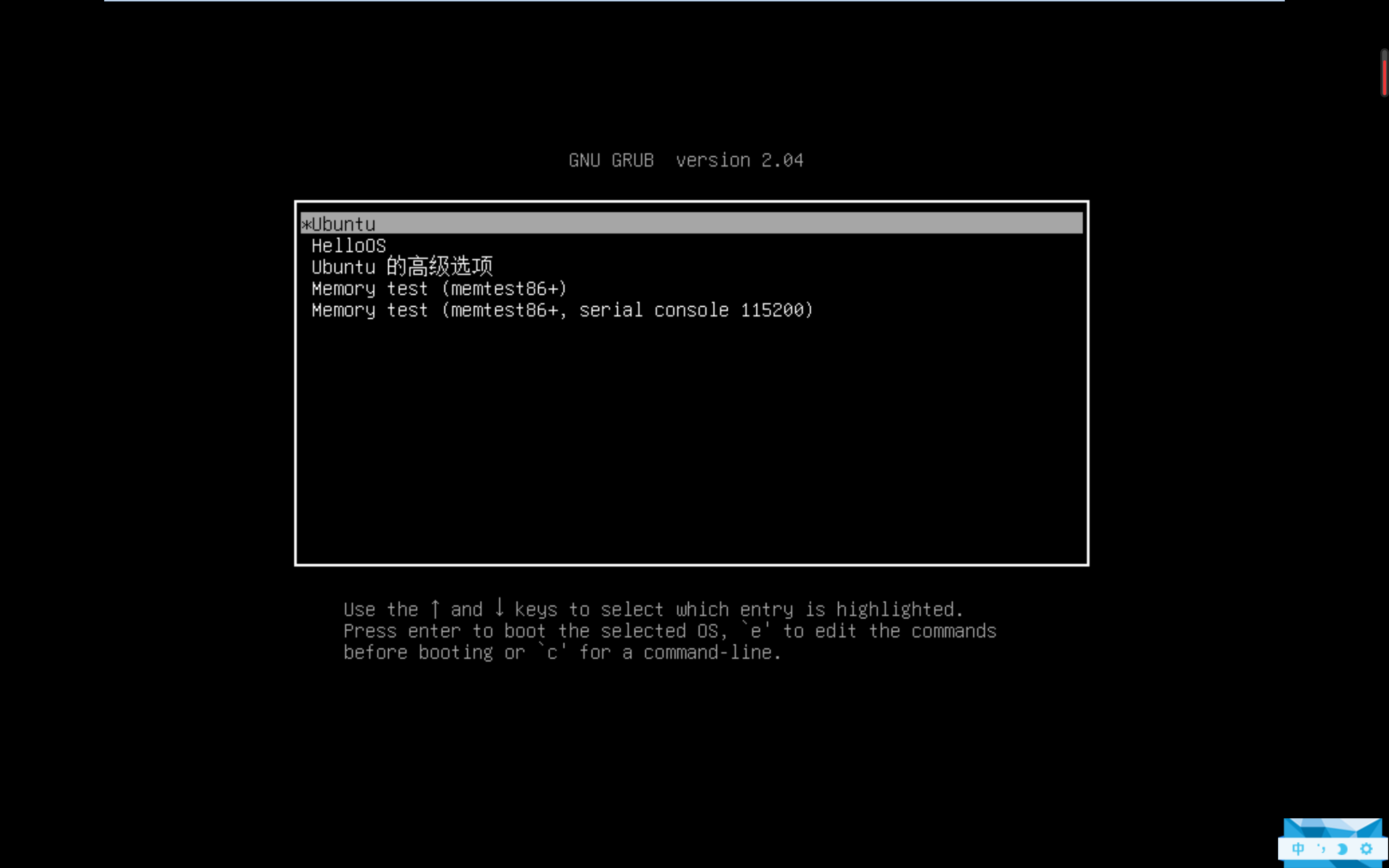
GRUB 首先会显示启动项到屏幕,然后让我们选择启动项,最后 GRUB 根据启动项对应的信息,加载 OS 文件到内存。
如果你不知道你的 boot 目录挂载的分区,可以在 Linux 系统的终端下输入命令:df /boot/,就会得到如下结果:

下面来看看我们 Hello OS 的启动项:
menuentry 'HelloOS' {
insmod part_msdos #GRUB加载分区模块识别分区
insmod ext2 #GRUB加载ext文件系统模块识别ext文件系统
set root='hd0,msdos5' #注意boot目录挂载的分区,这是我机器上的情况
multiboot2 /boot/HelloOS.bin #GRUB以multiboot2协议加载HelloOS.bin
boot #GRUB启动HelloOS.bin
}
把上面启动项的代码插入到你的 Linux 机器上的 /boot/grub/grub.cfg 文件中,然后把 Hello OS.bin 文件复制到 /boot/ 目录下,最后重启计算机,你就可以看到 Hello OS 的启动选项了。
但是 grub.cfg 是一个只读文件,因此我们需要更改一下这个文件的权限,再进行更改

还需要配置grub进入引导菜单
我们将HelloOS作为一个操作系统启动项供grub启动,因此需要能够在PC启动时进入grub引导菜单,并选择启动HelloOS
为了能够每次启动时进入grub引导菜单,需要进行如下设置
① 修改/etc/default/grub
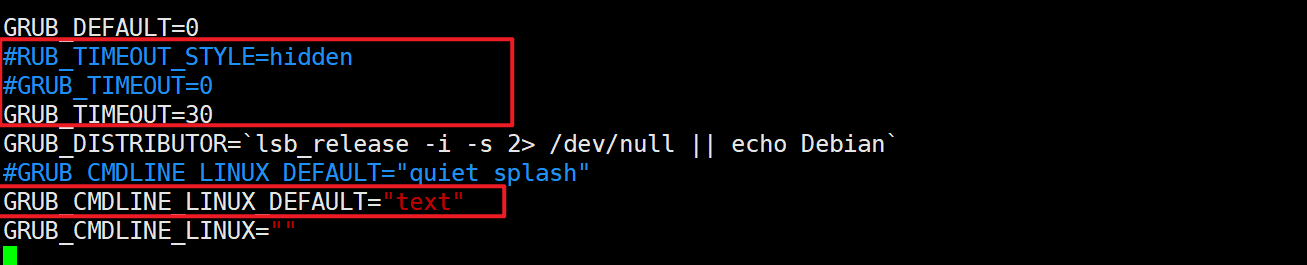
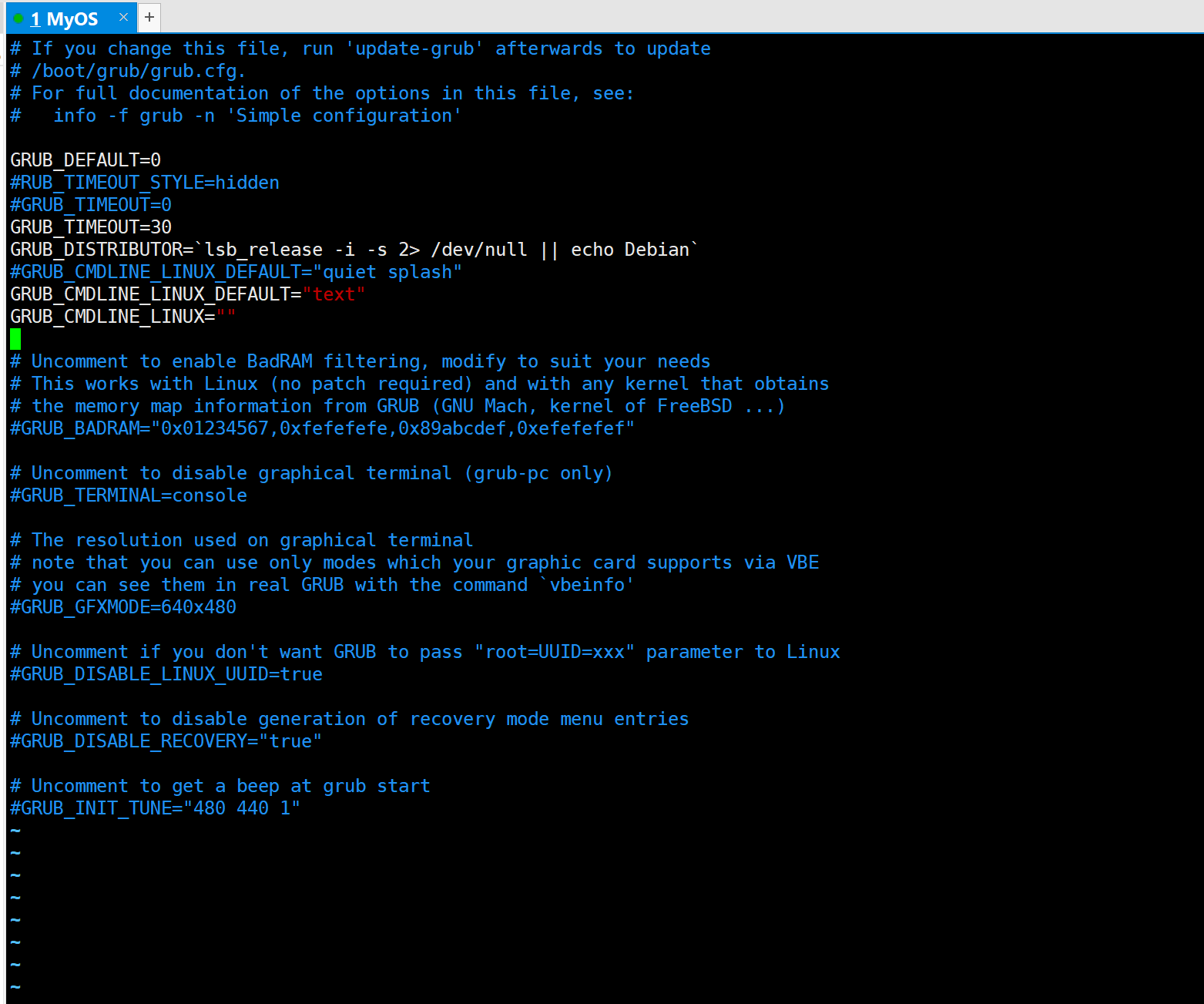
参考资料:https://blog.csdn.net/chenchengwudi/article/details/116707122
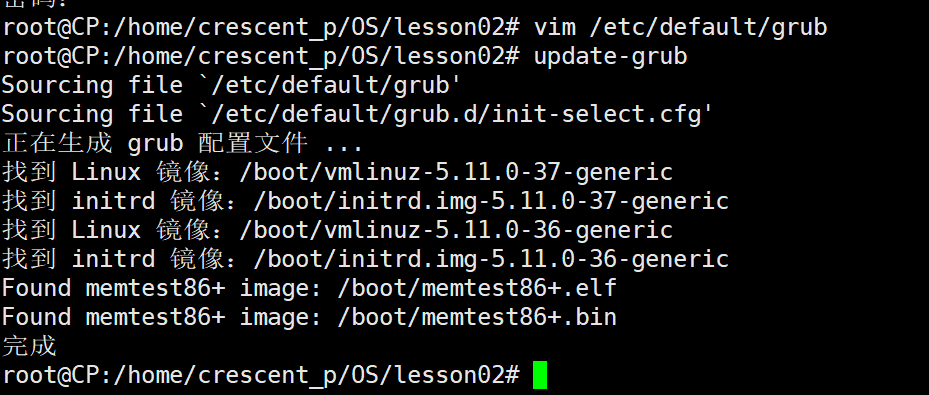
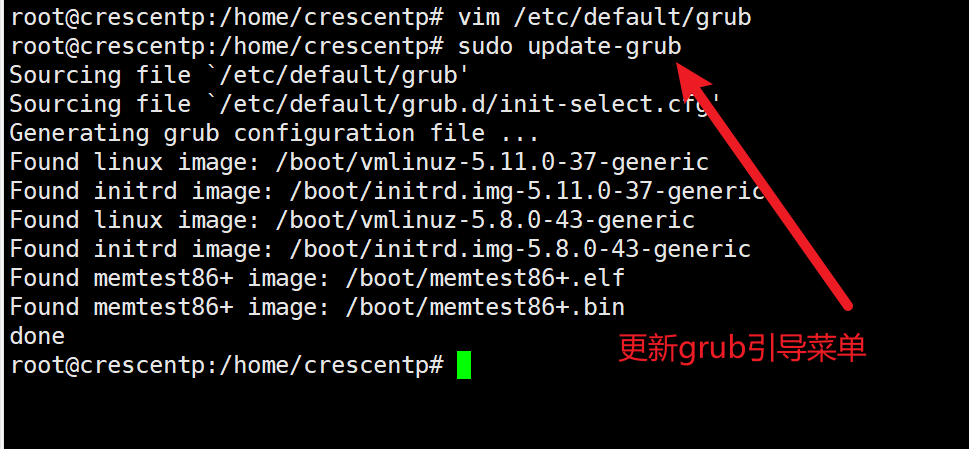
② 执行如下命令,更新grub配置
sudo update-grub
重启电脑的时候需要摁ESC键,结果是这样的
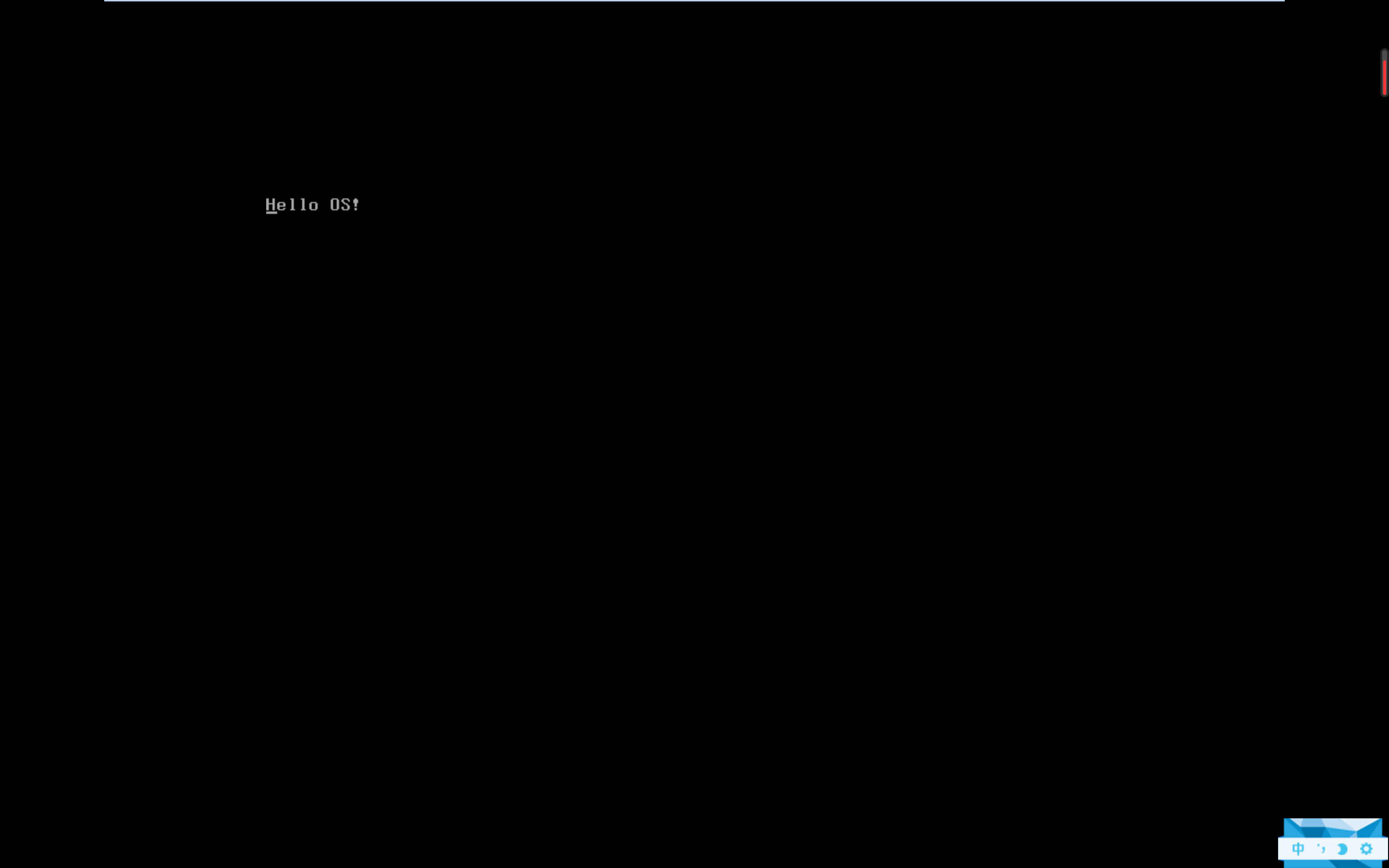
三. 黑盒之中有什么:内核结构与设计
在进行写我们自己的操作系统之前,我们要先对操作系统的内核有个大的架构思考。
1、内核中有什么
从抽象角度来看,内核就是计算机资源的管理者,当然管理资源是为了让应用使用资源。既然内核是资源的管理者,我们先来看看计算机中有哪些资源,然后通过资源的归纳,就能推导出内核这个大黑盒中应该有什么。
计算机资源可以分为两个部分:
- 硬件资源
- 总线
- CPU
- 内存
- 硬盘
- 网卡
- 显卡
- IO设备
- 软件资源
- 文件
- 软件
内核作为硬件资源和软件资源的管理者,其内部组成在逻辑上大致如下:
- 管理 CPU,由于 CPU 是执行程序的,而内核把运行时的程序抽象成进程,所以又称为进程管理。
- 管理内存,由于程序和数据都要占用内存,内存是非常宝贵的资源,所以内核要非常小心地分配、释放内存。
- 管理硬盘,而硬盘主要存放用户数据,而内核把用户数据抽象成文件,即管理文件,文件需要合理地组织,方便用户查找和读写,所以形成了文件系统。
- 管理显卡,负责显示信息,而现在操作系统都是支持 GUI(图形用户接口)的,管理显卡自然而然地就成了内核中的图形系统。
- 管理网卡,网卡主要完成网络通信,网络通信需要各种通信协议,最后在内核中就形成了网络协议栈,又称网络组件。
- 管理各种 I/O 设备,我们经常把键盘、鼠标、打印机、显示器等统称为 I/O(输入输出)设备,在内核中抽象成 I/O 管理器。
2、宏内核
宏内核就是把以上诸如管理进程的代码、管理内存的代码、管理各种 I/O 设备的代码、文件系统的代码、图形系统代码以及其它功能模块的代码,把这些所有的代码经过编译,最后链接在一起,形成一个大的可执行程序。
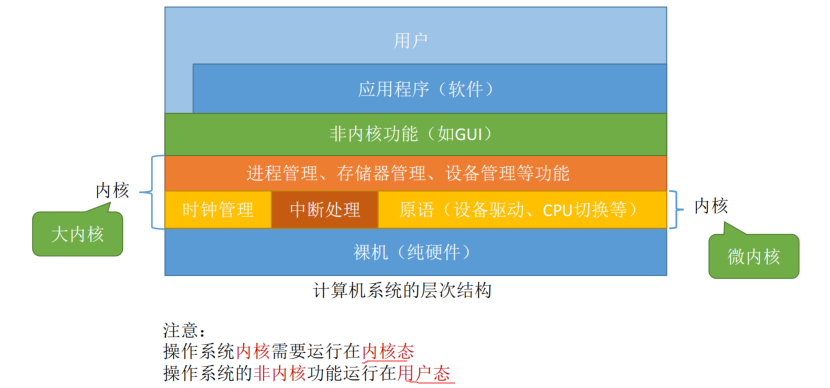


上图的宏内核结构有明显的缺点,因为它没有模块化,没有扩展性、没有移植性,高度耦合在一起,一旦其中一个组件有漏洞,内核中所有的组件可能都会出问题。
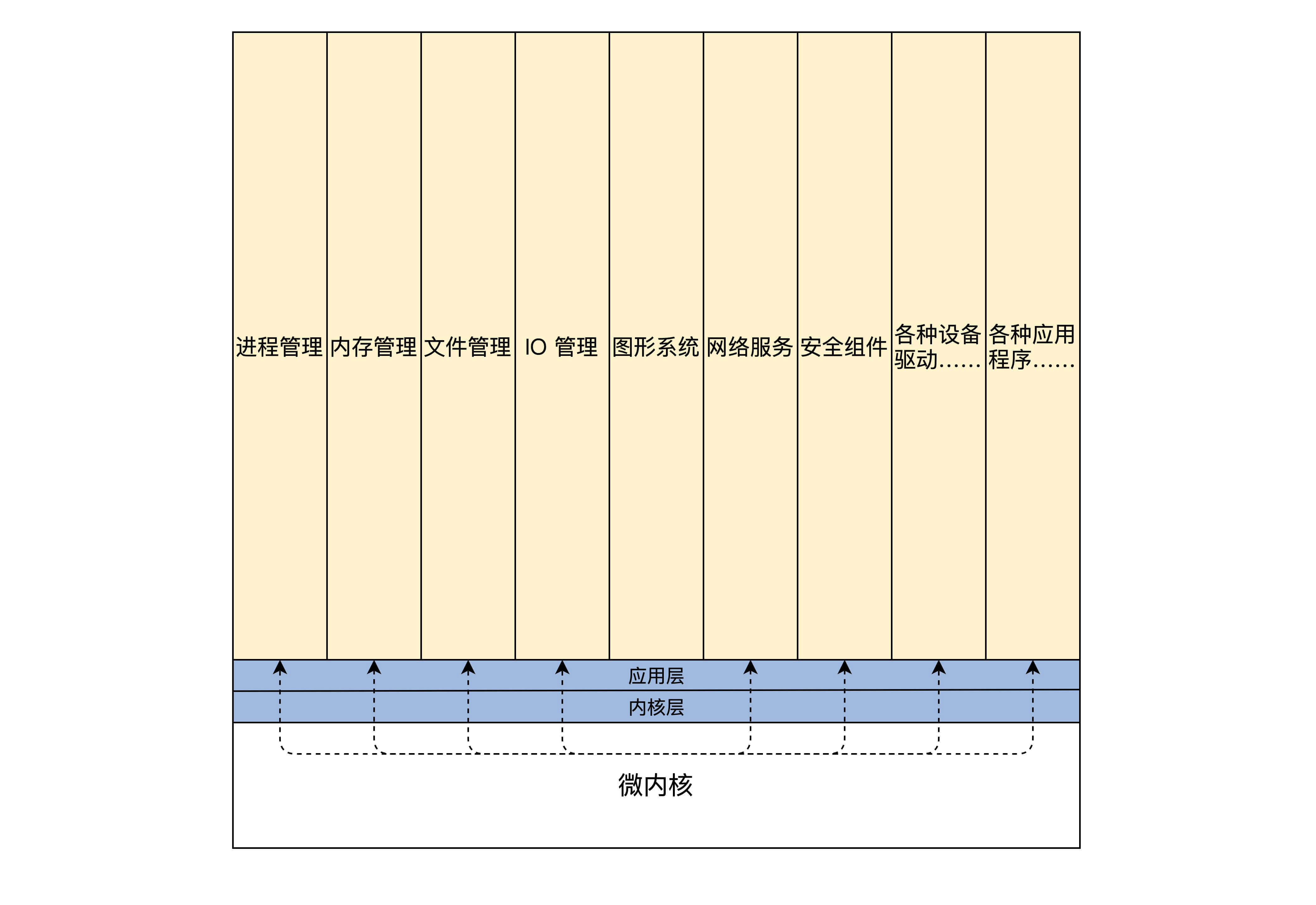
3、微内核
微内核架构正好与宏内核架构相反,它提倡内核功能尽可能少:仅仅只有进程调度、处理中断、内存空间映射、进程间通信等功能
这样的内核是不能完成什么实际功能的,开发者们把实际的进程管理、内存管理、设备管理、文件管理等服务功能,做成一个个服务进程。和用户应用进程一样,只是它们很特殊,宏内核提供的功能,在微内核架构里由这些服务进程专门负责完成。
微内核定义了一种良好的进程间通信的机制——消息。应用程序要请求相关服务,就向微内核发送一条与此服务对应的消息,微内核再把这条消息转发给相关的服务进程,接着服务进程会完成相关的服务。服务进程的编程模型就是循环处理来自其它进程的消息,完成相关的服务功能。其结构如下所示:

4、分离硬件的相关性
今天如此庞杂的计算机,其实也是一层一层地构建起来的,从硬件层到操作系统层再到应用软件层这样构建。分层的主要目的和好处在于屏蔽底层细节,使上层开发更加简单。计算机领域的一个基本方法是增加一个抽象层,从而使得抽象层的上下两层独立地发展,所以在内核内部再分若干层也不足为怪。
分离硬件的相关性,就是要把操作硬件和处理硬件功能差异的代码抽离出来,形成一个独立的软件抽象层,对外提供相应的接口,方便上层开发。
如果把所有硬件平台相关的代码,都抽离出来,放在一个独立硬件相关层中实现并且定义好相关的调用接口,再在这个层之上开发内核的其它功能代码,就会方便得多,结构也会清晰很多。操作系统的移植性也会大大增强,移植到不同的硬件平台时,就构造开发一个与之对应的硬件相关层。这就是分离硬件相关性的好处。
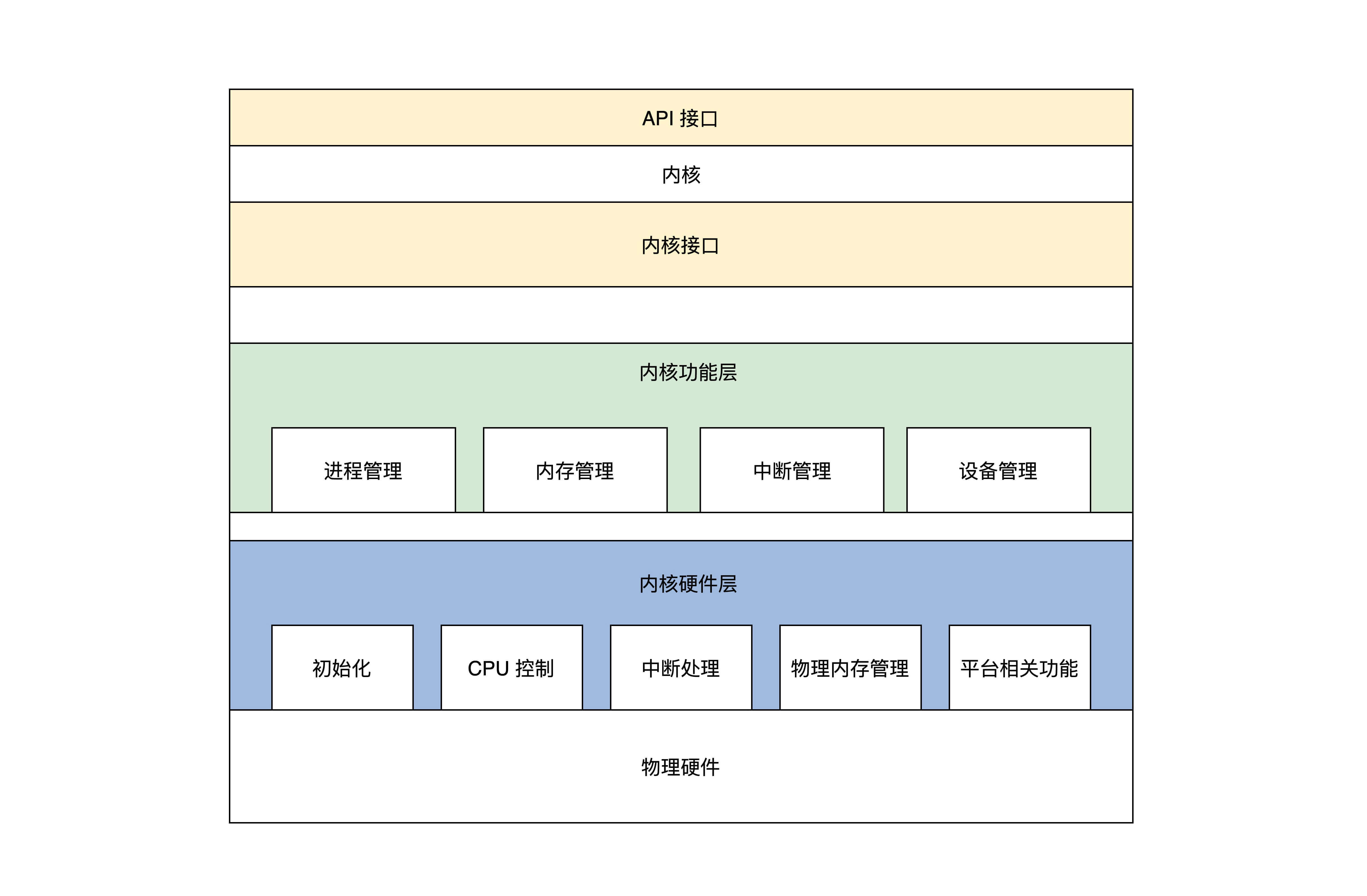
5、我们的选择
首先大致将我们的操作系统内核分为三个大层,分别是:
- 内核接口层。
- 内核功能层。
- 内核硬件层。




四、 震撼的Linux全景图:业界成熟的内核架构长什么样?
1、Linux 内核
Linux,全称 GNU/Linux,是一套免费使用和自由传播的操作系统,支持类 UNIX、POSIX 标准接口,也支持多用户、多进程、多线程,可以在多 CPU 的机器上运行。由于互联网的发展,Linux 吸引了来自全世界各地软件爱好者、科技公司的支持,它已经从大型机到服务器蔓延至个人电脑、嵌入式系统等领域。
Linux 的基本思想是一切都是文件:每个文件都有确定的用途,包括用户数据、命令、配置参数、硬件设备等对于操作系统内核而言,都被视为各种类型的文件。Linux 支持多用户,各个用户对于自己的文件有自己特殊的权利,保证了各用户之间互不影响。多任务则是现代操作系统最重要的一个特点,Linux 可以使多个程序同时并独立地运行。
Linux内部的全景图

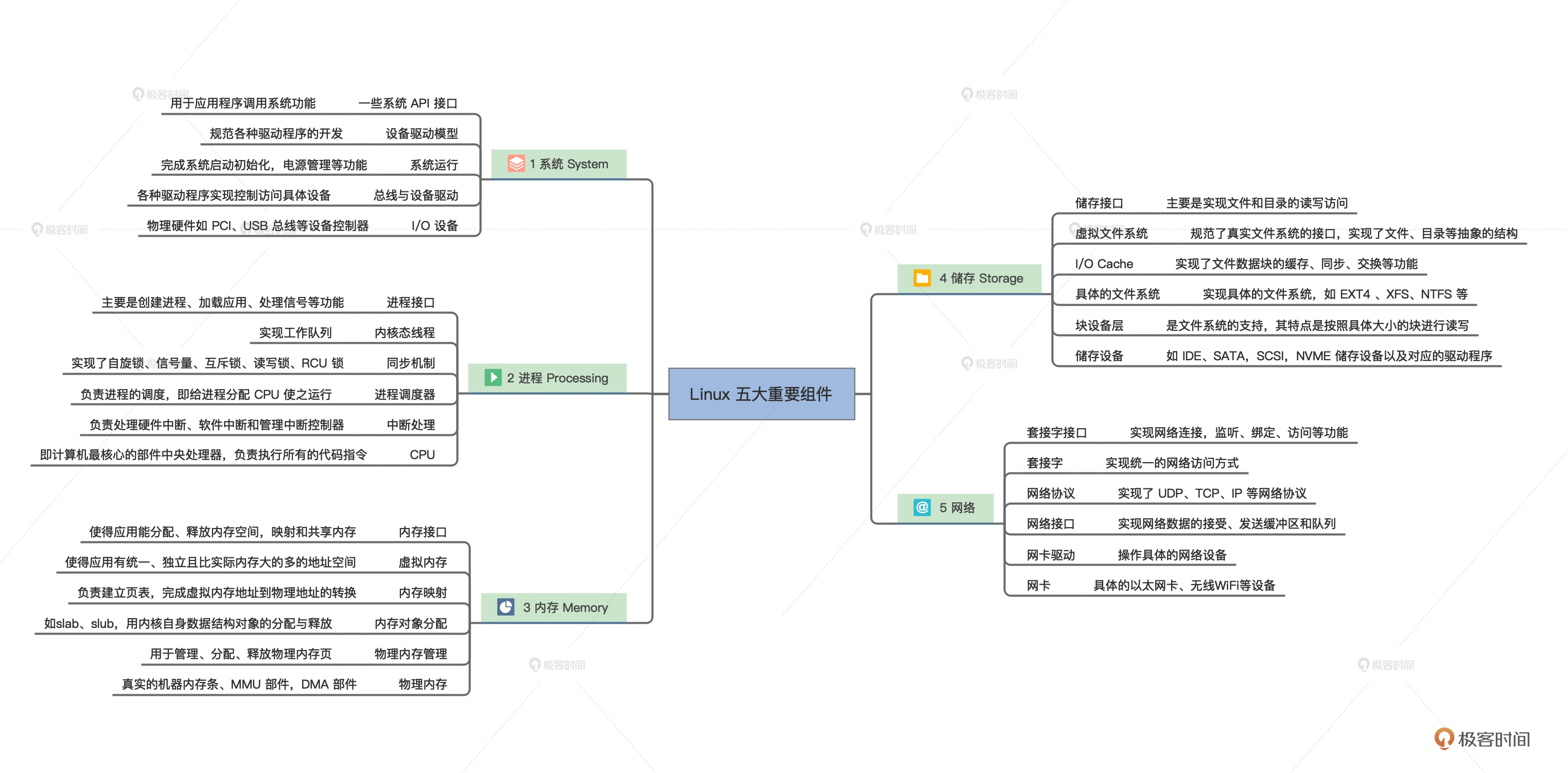
继续深入思考你就会发现,这些纵横交错的路径上有一个函数出现了问题,就麻烦大了,它会波及到全部组件,导致整个系统崩溃。当然调试解决这个问题,也是相当困难的。同样,模块之间没有隔离,安全隐患也是巨大的。
当然,这种结构不是一无是处,它的性能极高,而性能是衡量操作系统的一个重要指标。这种结构就是传统的内核结构,也称为宏内核架构。
2、Darwin-XNU 内核
Darwin 是由苹果公司在 2000 年开发的一个开放源代码的操作系统。
Darwin 作为 macOS 与 iOS 操作系统的核心,从技术实现角度说,它必然要支持 PowerPC、x86、ARM 架构的处理器。
Darwin 使用了一种微内核(Mach)和相应的固件来支持不同的处理器平台,并提供操作系统原始的基础服务,上层的功能性系统服务和工具则是整合了 BSD 系统所提供的。苹果公司还为其开发了大量的库、框架和服务,不过它们都工作在用户态且闭源。
Darwin架构图
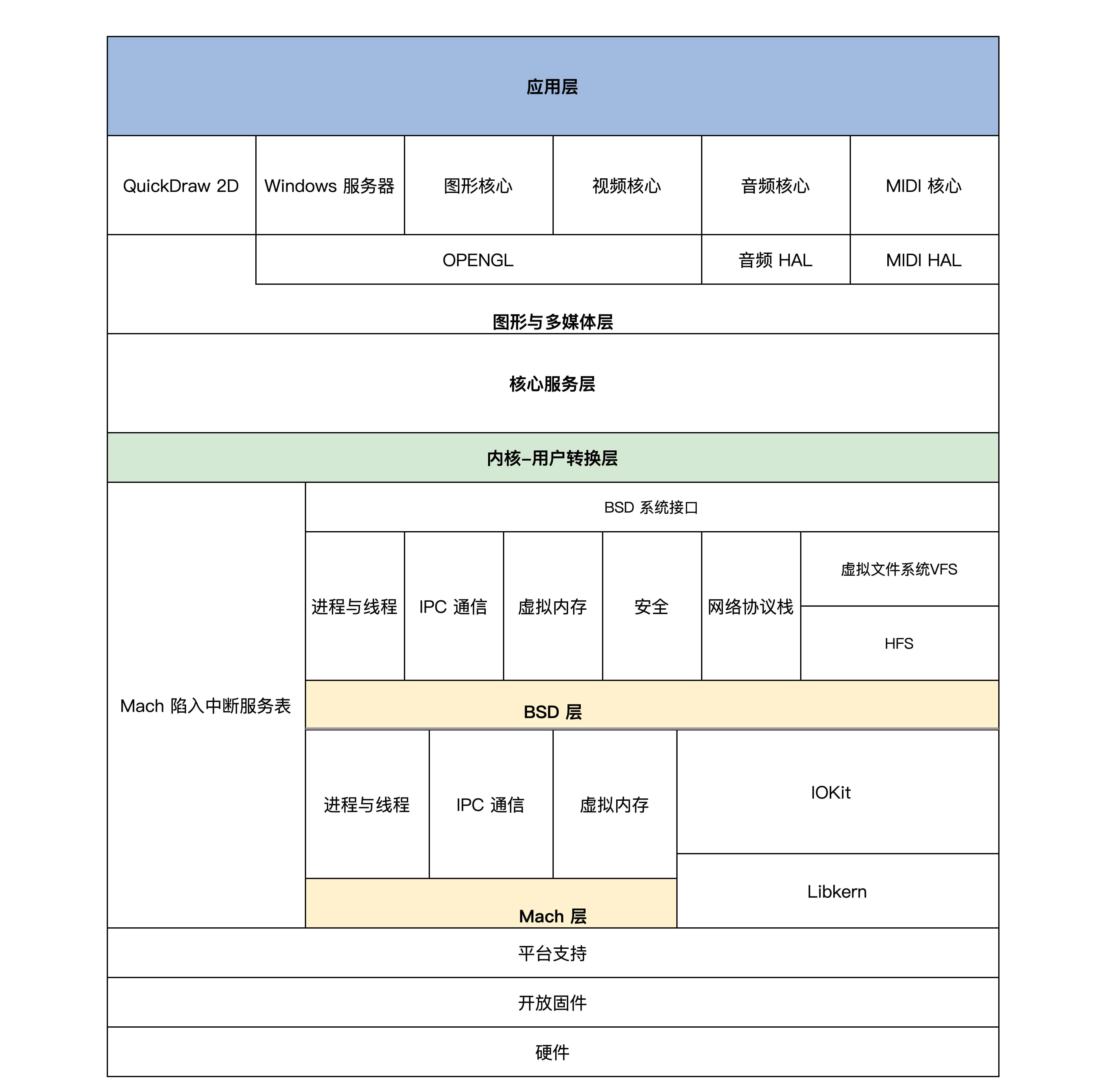
由于我们是研究 Darwin 内核,所以上图中我们只需要关注内核 - 用户转换层以下的部分即可。显然它有两个内核层——Mach层与 BSD层。
Mach 内核是卡耐基梅隆大学开发的经典微内核,意在提供最基本的操作系统服务,从而达到高性能、安全、可扩展的目的,而 BSD 则是伯克利大学开发的类 UNIX 操作系统,提供一整套操作系统服务。
那为什么两套内核会同时存在呢?
MAC OS X(2011 年之前的称呼)的发展经过了不同时期,随着时代的进步,产品功能需求增加,单纯的 Mach 之上实现出现了性能瓶颈,但是为了兼容之前为 Mach 开发的应用和设备驱动,就保留了 Mach 内核,同时加入了 BSD 内核.
Mach 内核仍然提供十分简单的进程、线程、IPC 通信、虚拟内存设备驱动相关的功能服务,BSD 则提供强大的安全特性,完善的网络服务,各种文件系统的支持,同时对 Mach 的进程、线程、IPC、虚拟内核组件进行细化、扩展延伸。。`
那么应用如何使用 Darwin 系统的服务呢?
应用会通过用户层的框架和库来请求 Darwin 系统的服务,即调用 Darwin 系统 API。
在调用 Darwin 系统 API 时,会传入一个 API 号码,用这个号码去索引 Mach 陷入中断服务表中的函数。此时,API 号码如果小于 0,则表明请求的是 Mach 内核的服务,API 号码如果大于 0,则表明请求的是 BSD 内核的服务,它提供一整套标准的 POSIX 接口。
3、Windows NT内核
现代 Windows 的内核就是 NT
Windows NT 是微软于 1993 年推出的面向工作站、网络服务器和大型计算机的网络操作系统,也可做 PC 操作系统。它是一款全新从零开始开发的新操作系统,并应用了现代硬件的所有特性,“NT”所指的便是“新技术”(New Technology)。
现在,NT 内核在设计上层次非常清晰明了,各组件之间界限耦合程度很低。
NT内核架构图:
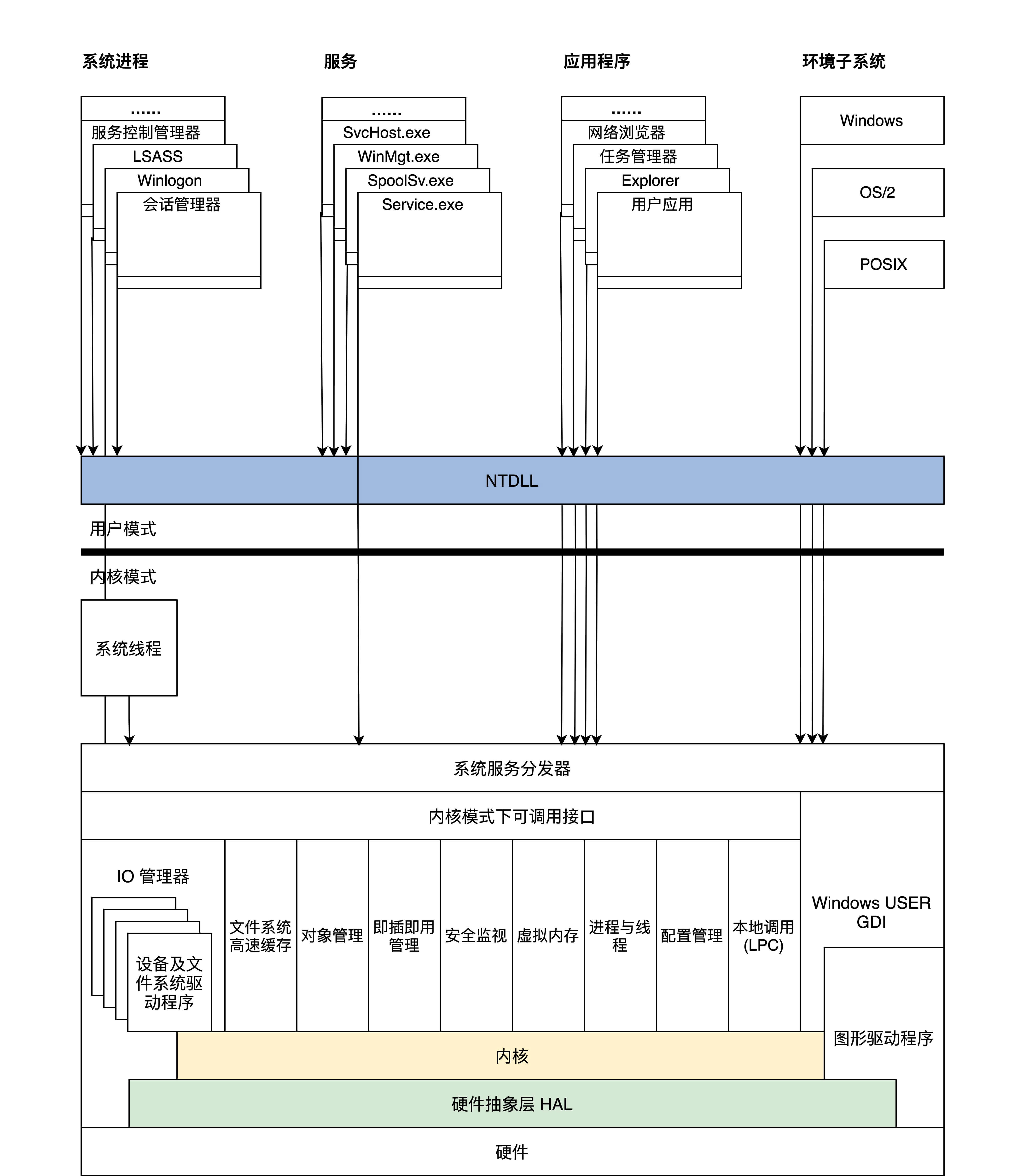
当然微软自己在 HAL 层上是定义了一个小内核,小内核之下是硬件抽象层 HAL,这个 HAL 存在的好处是:不同的硬件平台只要提供对应的 HAL 就可以移植系统了。小内核之上是各种内核组件,微软称之为内核执行体,它们完成进程、内存、配置、I/O 文件缓存、电源与即插即用、安全等相关的服务。
每个执行体互相独立,只对外提供相应的接口,其它执行体要通过内核模式可调用接口和其它执行体通信或者请求其完成相应的功能服务。所有的设备驱动和文件系统都由 I/O 管理器统一管理,驱动程序可以堆叠形成 I/O 驱动栈,功能请求被封装成 I/O 包,在栈中一层层流动处理。Windows 引以为傲的图形子系统也在内核中。
Linux 性能良好,结构异常复杂,不利于问题的排查和功能的扩展,而 Darwin-XNU 和 Windows 结构良好,层面分明,利于功能扩展,不容易产生问题且性能稳定。
五、CPU工作模式:执行程序的三种模式
操作系统是管理硬件的软件,硬件中重要的是CPU,现在对x86 CPU 做一定的了解。
CPU的工作模式分为:
- 实模式
- 保护模式
- 长模式
1、实模式
实模式又称实地址模式,实,即真实,这个真实分为两个方面,一个方面是运行真实的指令,对指令的动作不作区分,直接执行指令的真实功能,另一方面是发往内存的地址是真实的,对任何地址不加限制地发往内存。
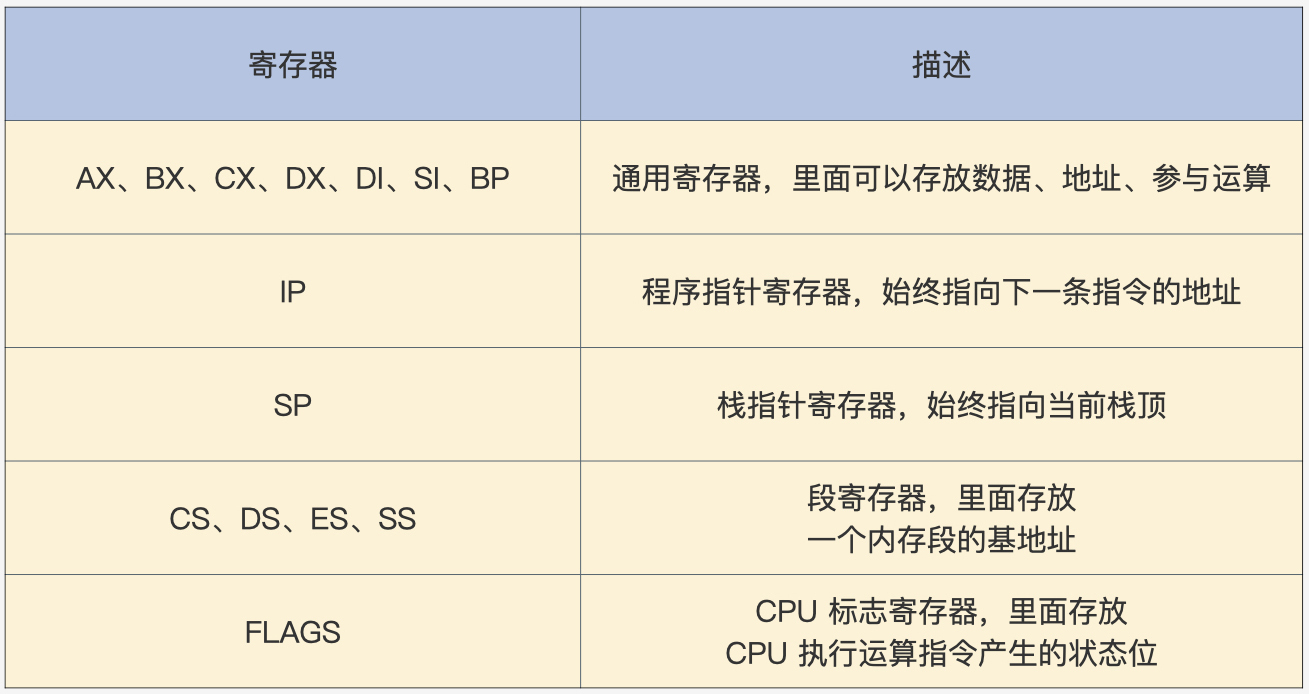
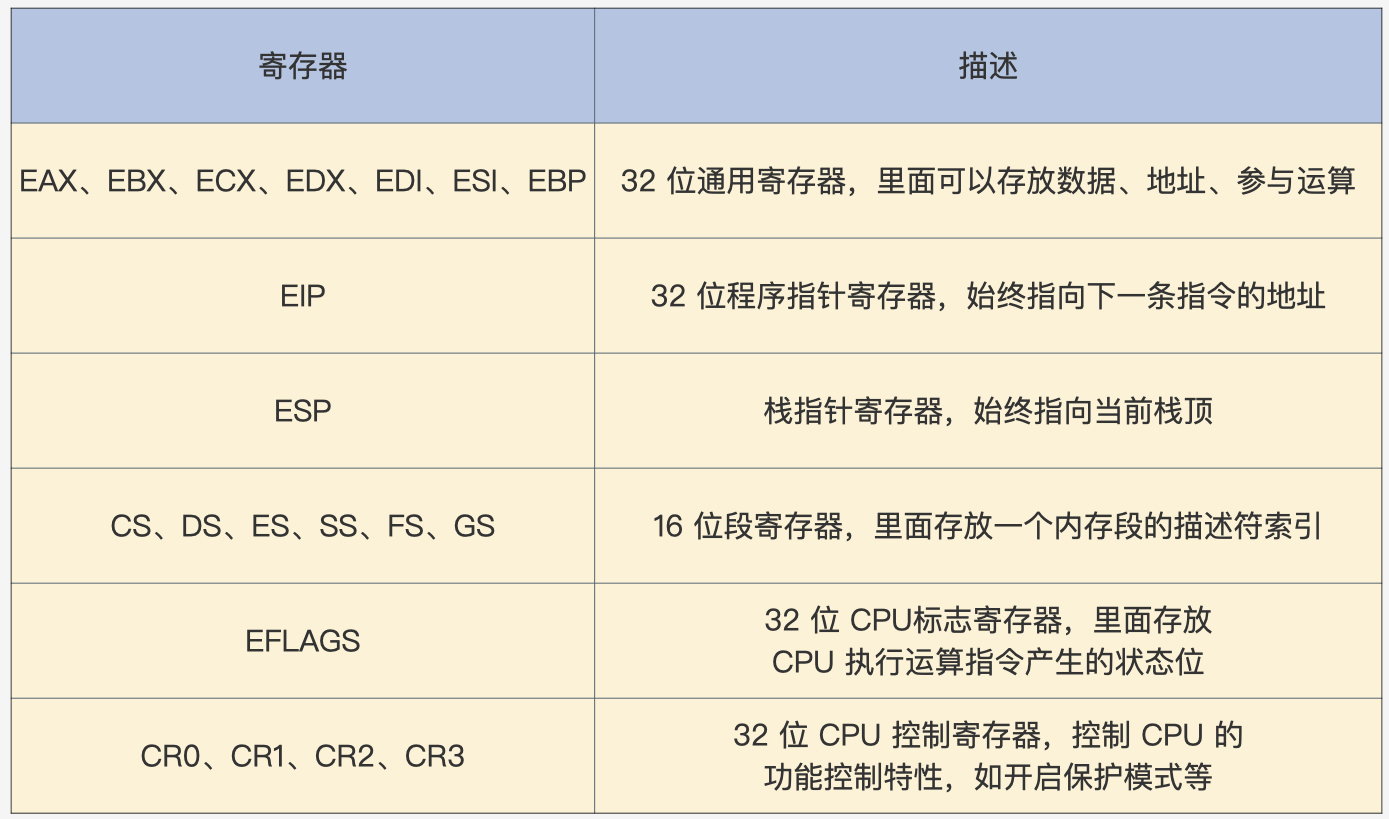
1.1 实模式寄存器
表中的寄存器都是16位的
1.2 实模式访问内存
虽然有了寄存器,但是数据和指令都是存放在内存中的。通常情况下,需要把数据装载进寄存器中才能操作,还要有获取指令的动作,这些都要访问内存才行,而我们知道访问内存靠的是地址值。
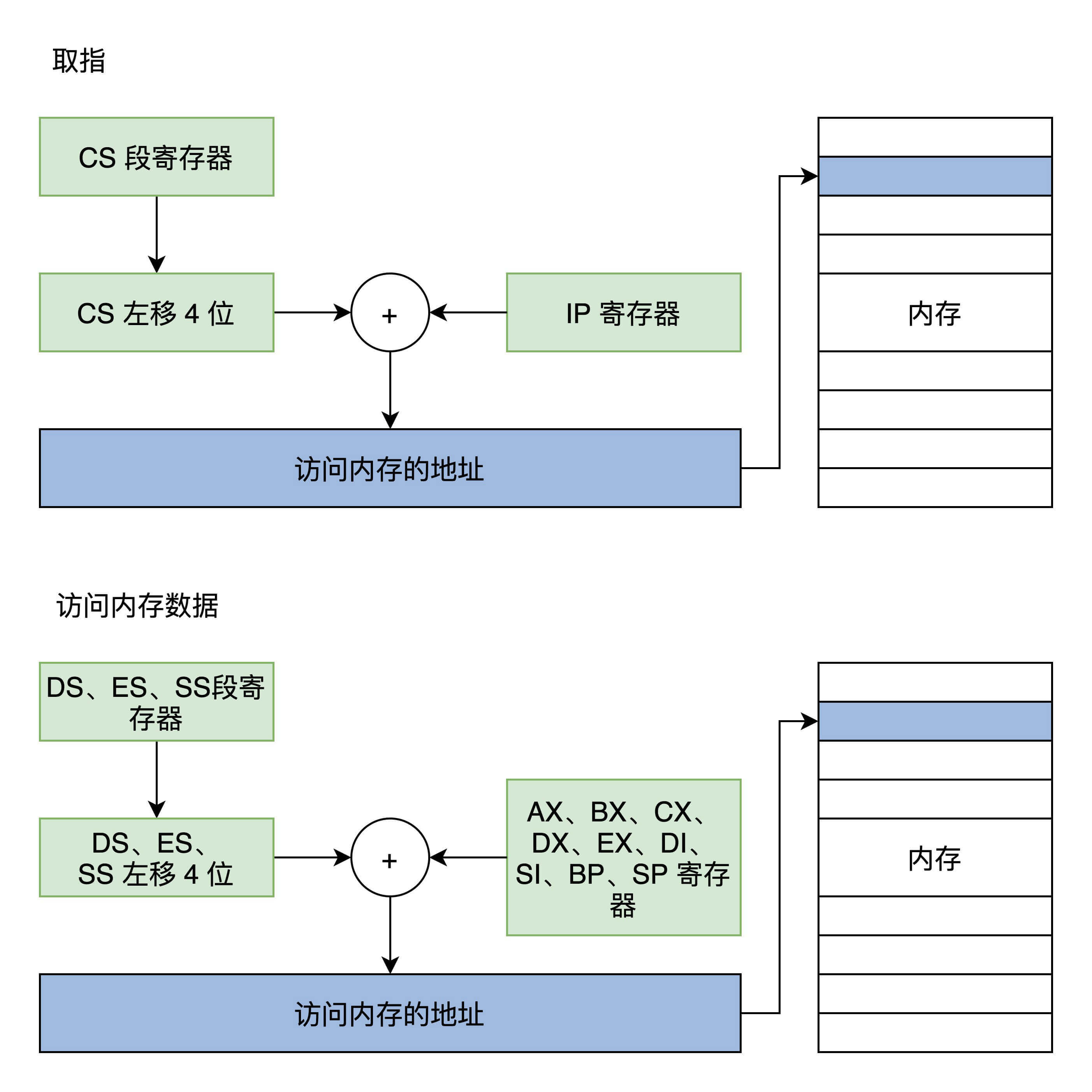
结合上图可以发现,所有的内存地址都是由段寄存器左移 4 位,再加上一个通用寄存器中的值或者常数形成地址,然后由这个地址去访问内存。这就是大名鼎鼎的分段内存管理模型。
就是王爽的汇编书里面的内容。
只不过这里要特别注意的是,代码段是由 CS 和 IP 确定的,而栈段是由 SS 和 SP 段确定的。
data SEGMENT ;定义一个数据段存放Hello World! hello DB 'Hello World!$' ;注意要以$结束data ENDScode SEGMENT ;定义一个代码段存放程序指令 ASSUME CS:CODE,DS:DATA ;告诉汇编程序,DS指向数据段,CS指向代码段start: MOV AX,data ;将data段首地址赋值给AX MOV DS,AX ;将AX赋值给DS,使DS指向data段 LEA DX,hello ;使DX指向hello首地址 MOV AH,09h ;给AH设置参数09H,AH是AX高8位,AL是AX低8位,其它类似 INT 21h ;执行DOS中断输出DS指向的DX指向的字符串hello MOV AX,4C00h ;给AX设置参数4C00h INT 21h ;调用4C00h号功能,结束程序code ENDSEND start
上述代码中的结构模型,也是符合 CPU 实模式下分段内存管理模式的,它们被汇编器转换成二进制数据后,也是以段的形式存在的。
代码中的注释已经很明确了,你应该很容易就能理解,大多数是操作寄存器,其中 LEA 是取地址指令,MOV 是数据传输指令。
1.3 实模式中断
中断即中止执行当前程序,转而跳转到另一个特定的地址上,去运行特定的代码。在实模式下它的实现过程是先保存 CS 和 IP 寄存器,然后装载新的 CS 和 IP 寄存器,那么中断是如何产生的呢?
- 第一种情况是,中断控制器给 CPU 发送了一个电子信号,CPU 会对这个信号作出应答。随后中断控制器会将中断号发送给 CPU,这是硬件中断。
- 第二种情况就是 CPU 执行了 INT 指令,这个指令后面会跟随一个常数,这个常数即是软中断号。这种情况是软件中断。
无论是硬件中断还是软件中断,都是 CPU 响应外部事件的一种方式。
为了实现中断,就需要在内存中放一个中断向量表,这个表的地址和长度由 CPU 的特定寄存器 IDTR指向。实模式下,表中的一个条目由代码段地址和段内偏移组成,如下图所示。
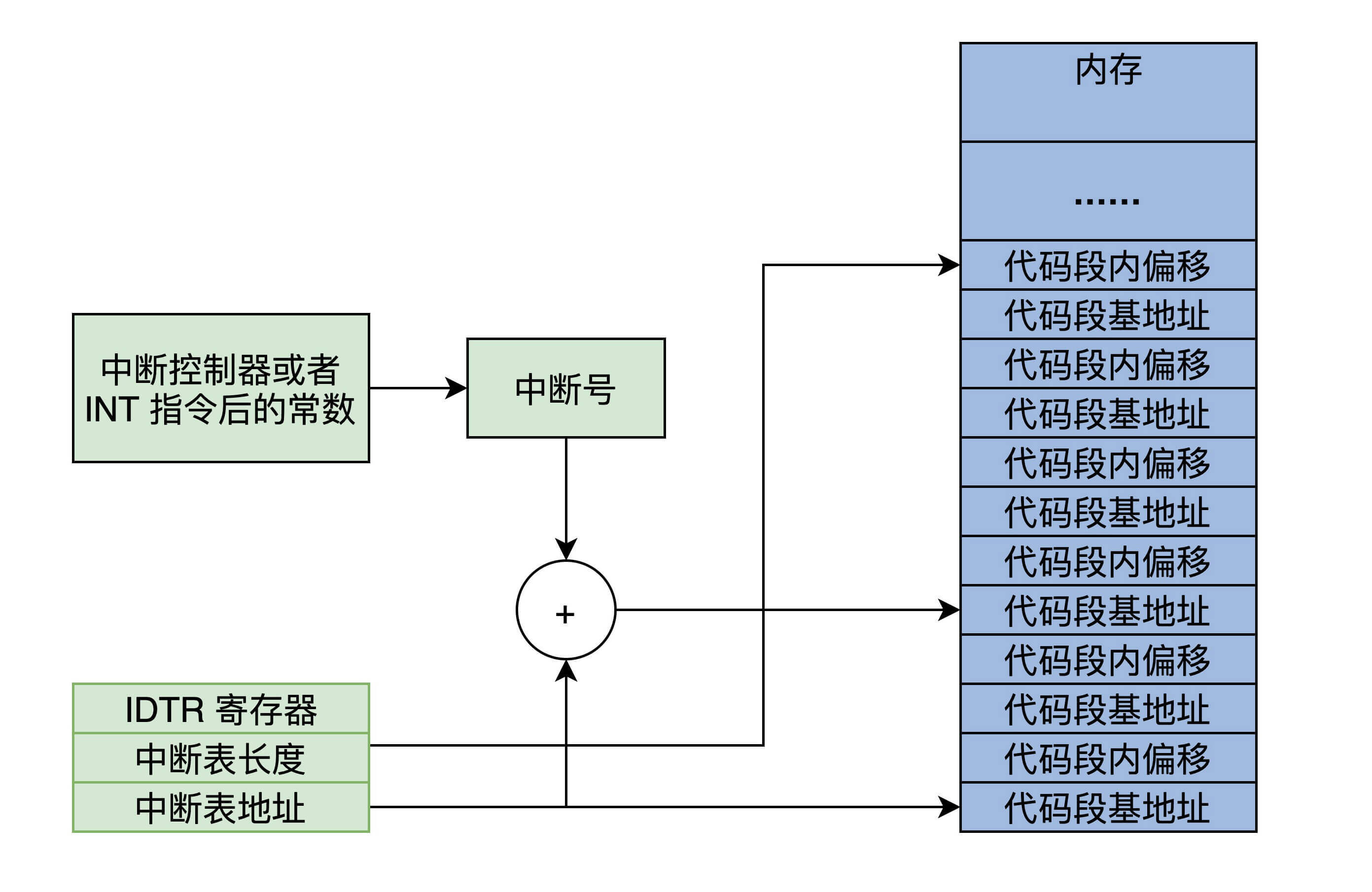
有了中断号以后,CPU 就能根据 IDTR 寄存器中的信息,计算出中断向量中的条目,进而装载 CS(装入代码段基地址)、IP(装入代码段内偏移)寄存器,最终响应中断。
2、保护模式
随着软件的规模不断增加,需要更高的计算量、更大的内存容量。
内存一大,首先要解决的问题是寻址问题,因为 16 位的寄存器最多只能表示 2^16 个地址,所以 CPU 的寄存器和运算单元都要扩展成 32 位的。
不过,虽然扩展 CPU 内部器件的位数解决了计算和寻址问题,但仍然没有解决前面那个实模式场景下的问题,导致前面场景出问题的原因有两点。
- 第一,CPU 对任何指令不加区分地执行;
- 第二,CPU 对访问内存的地址不加限制。
2. 1保护模式寄存器
保护模式相比于实模式,增加了一些控制寄存器和段寄存器,扩展通用寄存器的位宽,所有的通用寄存器都是 32 位的,还可以单独使用低 16 位,这个低 16 位又可以拆分成两个 8 位寄存器,如下表。
2.2 保护模式特权级
为了区分哪些指令(如 in、out、cli)和哪些资源(如寄存器、I/O 端口、内存地址)可以被访问,CPU 实现了特权级。
特权级分为 4 级,R0~R3,每个特权级执行指令的数量不同,R0 可以执行所有指令,R1、R2、R3 依次递减,它们只能执行上一级指令数量的子集。而内存的访问则是靠后面所说的段描述符和特权级相互配合去实现的。如下图.
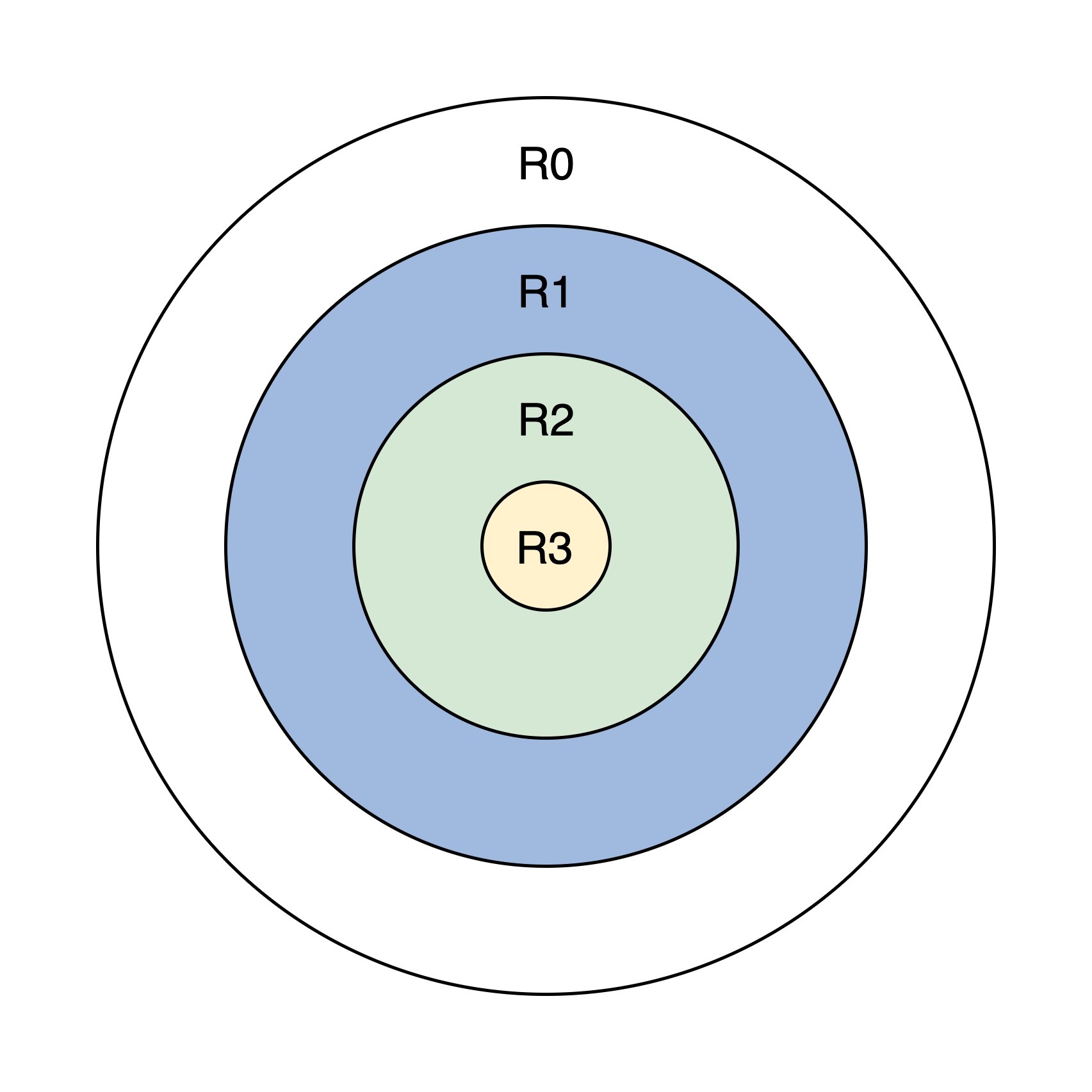
上面的圆环图,从外到内,既能体现权力的大小,又能体现各特权级对资源控制访问的多少,还能体现各特权级之间的包含关系。R0 拥有最大权力,可以访问低特权级的资源,反之则不行。
2.3 保护模式段描述符
目前为止,内存还是分段模型,要对内存进行保护,就可以转换成对段的保护。
由于 CPU 的扩展导致了 32 位的段基地址和段内偏移,还有一些其它信息,所以 16 位的段寄存器肯定放不下。放不下就要找内存借空间,然后把描述一个段的信息封装成特定格式的段描述符,放在内存中,其格式如下。
这个就是描述一个段的基本信息,可以使用这个段描述符找到我们所需要的内存段。保护模式段描述符.
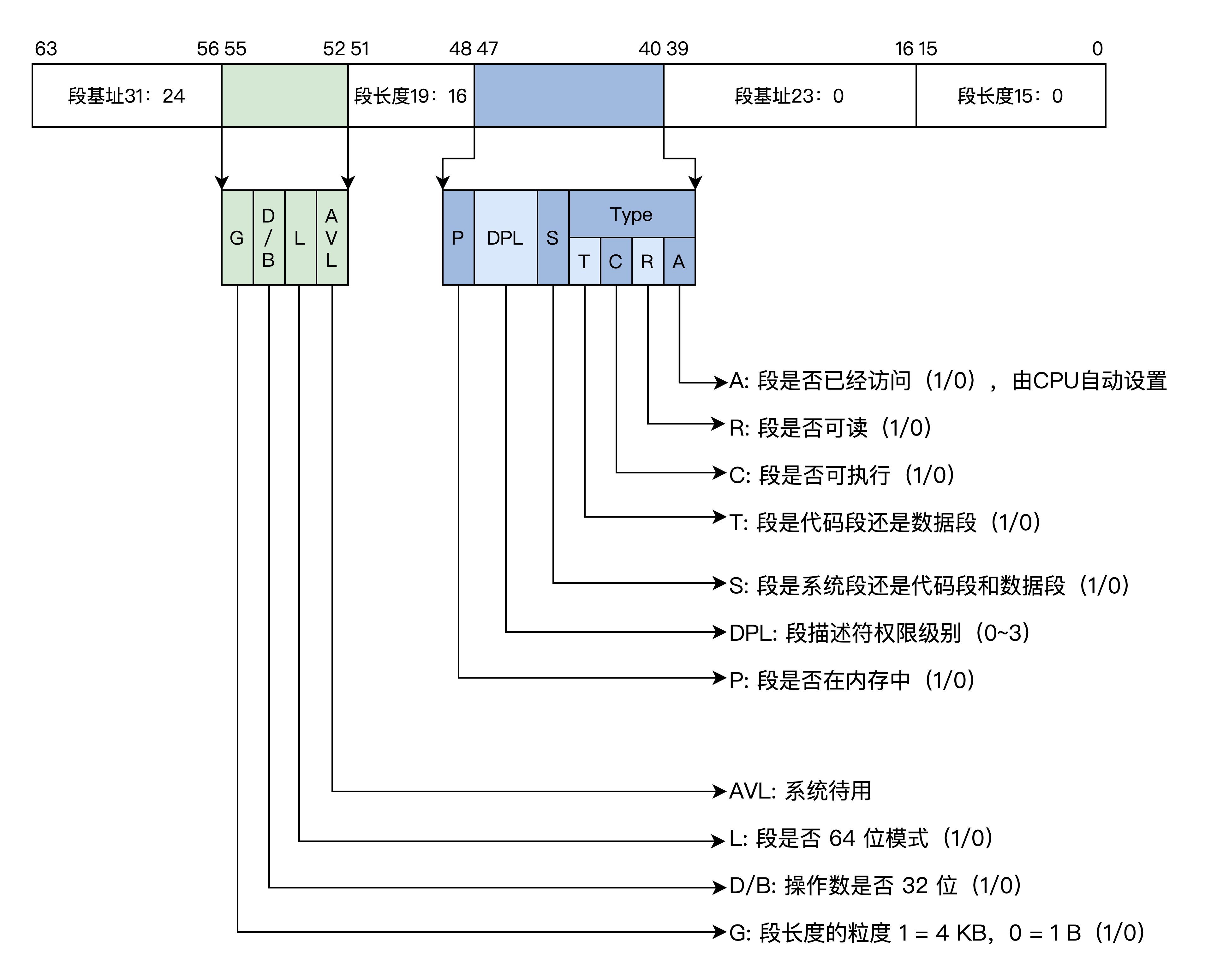
一个段描述符有 64 位 8 字节数据,里面包含了段基地址、段长度、段权限、段类型(可以是系统段、代码段、数据段)、段是否可读写,可执行等。虽然数据分布有点乱,这是由于历史原因造成的。
多个段描述符在内存中形成全局段描述符表(GDT),该表的基地址和长度由 CPU 和 GDTR 寄存器指示。如下图所示。
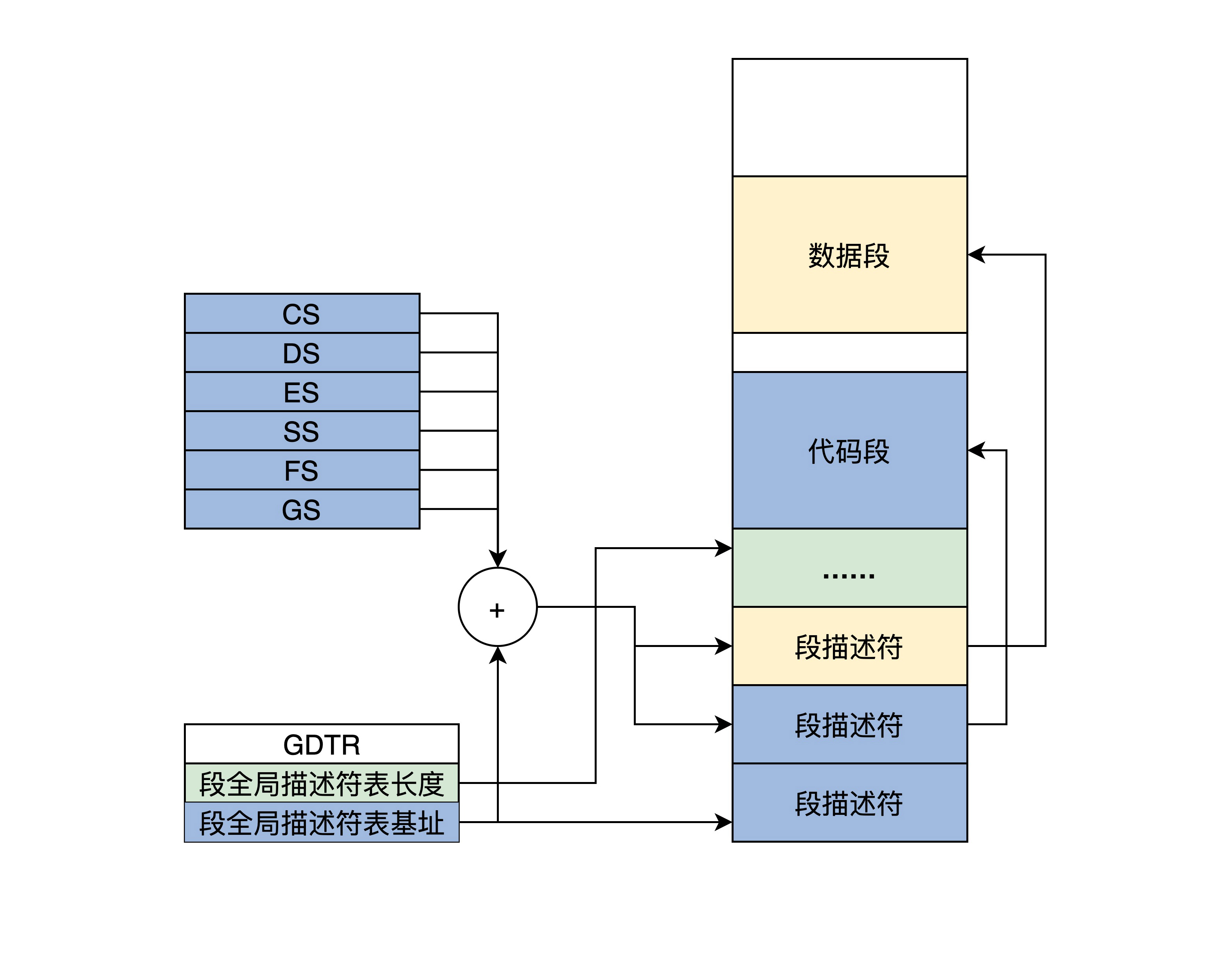
我们一眼就可以看出,段寄存器中不再存放段基地址,而是具体段描述符的索引,访问一个内存地址时,段寄存器中的索引首先会结合 GDTR 寄存器找到内存中的段描述符,再根据其中的段信息判断能不能访问成功。
2.4 保护模式段选择子
如果你认为 CS、DS、ES、SS、FS、GS 这些段寄存器,里面存放的就是一个内存段的描述符索引,那你可就草率了,其实它们是由影子寄存器、段描述符索引、描述符表索引、权限级别组成的。如下图所示。
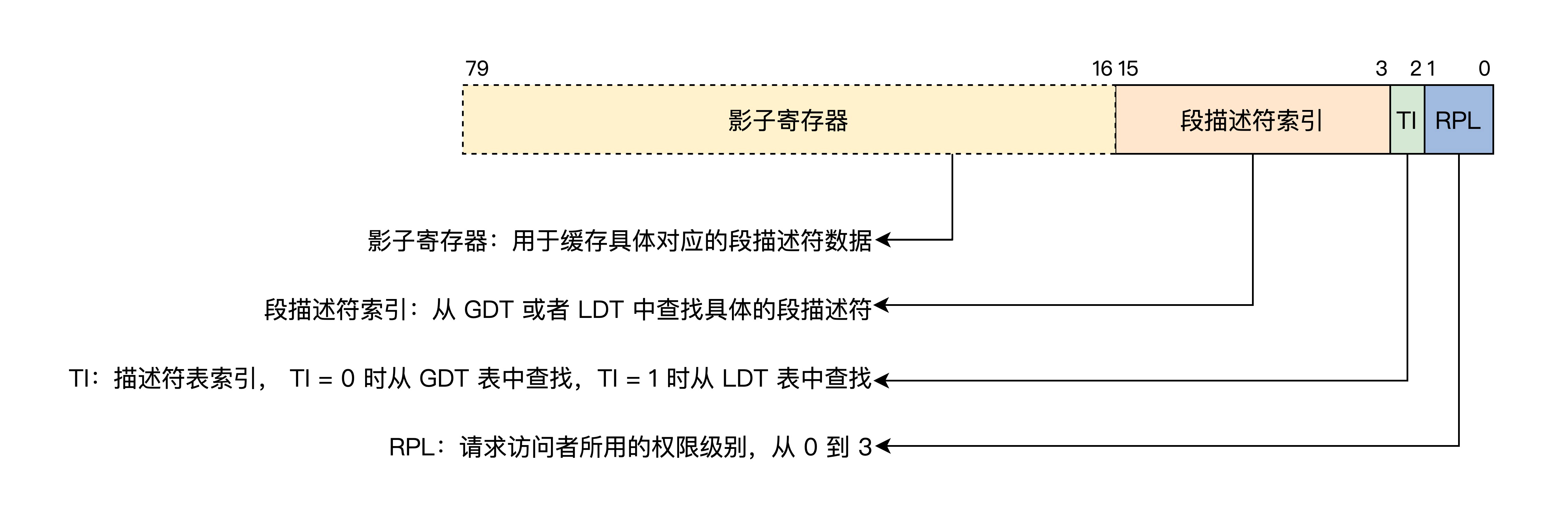
上图中影子寄存器是靠硬件来操作的,对系统程序员不可见,是硬件为了减少性能损耗而设计的一个段描述符的高速缓存,不然每次内存访问都要去内存中查表,那性能损失是巨大的,影子寄存器也正好是 64 位,里面存放了 8 字节段描述符数据。
低三位之所以能放 TI 和 RPL,是因为段描述符 8 字节对齐,每个索引低 3 位都为 0,我们不用关注 LDT,只需要使用 GDT 全局描述符表,所以 TI 永远设为 0。
通常情况下,CS 和 SS 中 RPL 就组成了 CPL(当前权限级别),所以常常是 RPL=CPL,进而 CPL 就表示发起访问者要以什么权限去访问目标段,当 CPL 大于目标段 DPL 时,则 CPU 禁止访问,只有 CPL 小于等于目标段 DPL 时才能访问。
2.5 保护模式平坦模型
x86 CPU 并不能直接使用分页模型,而是要在分段模型的前提下,根据需要决定是否要开启分页。因为这是硬件的规定,程序员是无法改变的。但是我们可以简化设计,来使分段成为一种“虚设”,这就是保护模式的平坦模型。
根据前面的描述,我们发现 CPU 32 位的寄存器最多只能产生 4GB 大小的地址,而一个段长度也只能是 4GB,所以我们把所有段的基地址设为 0,段的长度设为 0xFFFFF,段长度的粒度设为 4KB,这样所有的段都指向同一个(0~4GB-1)字节大小的地址空间。
下面我们还是看一看前面 Hello OS 中段描述符表,如下所示。
GDT_START:knull_dsc: dq 0;第一个段描述符CPU硬件规定必须为0kcode_dsc: dq 0x00cf9e000000ffff;段基地址=0,段长度=0xfffff;G=1,D/B=1,L=0,AVL=0 ;P=1,DPL=0,S=1;T=1,C=1,R=1,A=0kdata_dsc: dq 0x00cf92000000ffff;段基地址=0,段长度=0xfffff;G=1,D/B=1,L=0,AVL=0 ;P=1,DPL=0,S=1;T=0,C=0,R=1,A=0GDT_END:GDT_PTR:GDTLEN dw GDT_END-GDT_START-1GDTBASE dd GDT_START
上面代码中注释已经很明白了,段长度需要和 G 位配合,若 G 位为 1 则段长度等于 0xfffff 个 4KB。上面段描述符的 DPL=0,这说明需要最高权限即 CPL=0 才能访问。
这个得对照着上面的保护模式段描述符来对照
2.6 保护模式中断
因为实模式下 CPU 不需要做权限检查,所以它可以直接通过中断向量表中的值装载 CS:IP 寄存器就好了。
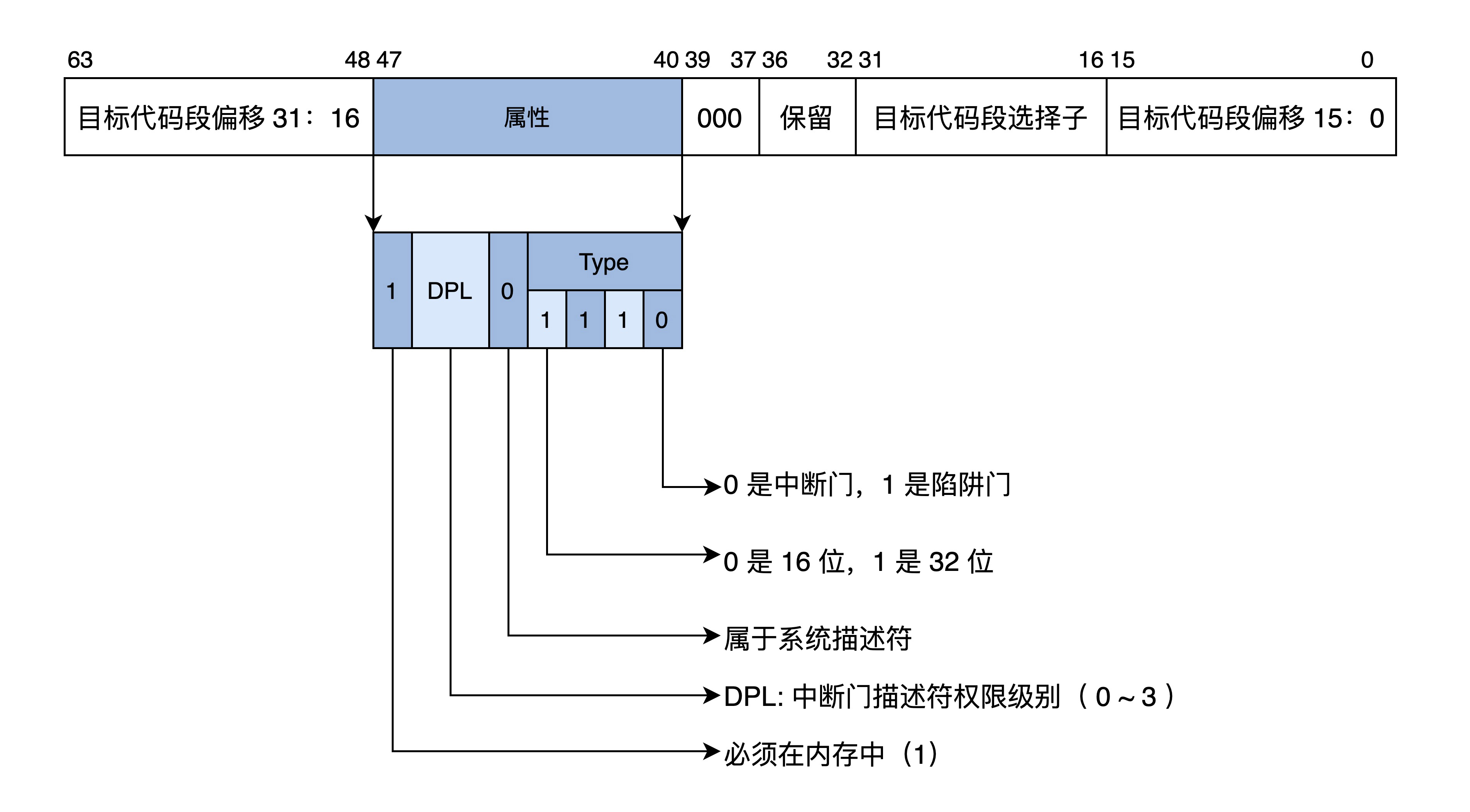
而保护模式下的中断要权限检查,还有特权级的切换,所以就需要扩展中断向量表的信息,即每个中断用一个中断门描述符来表示,也可以简称为中断门,中断门描述符依然有自己的格式,如下图所示。
保护模式中断门描述符:
同样的,保护模式要实现中断,也必须在内存中有一个中断向量表,同样是由 IDTR 寄存器指向,只不过中断向量表中的条目变成了中断门描述符,如下图所示。
通过算出中断号,找到中断门描述符,然后找到中断的代码。
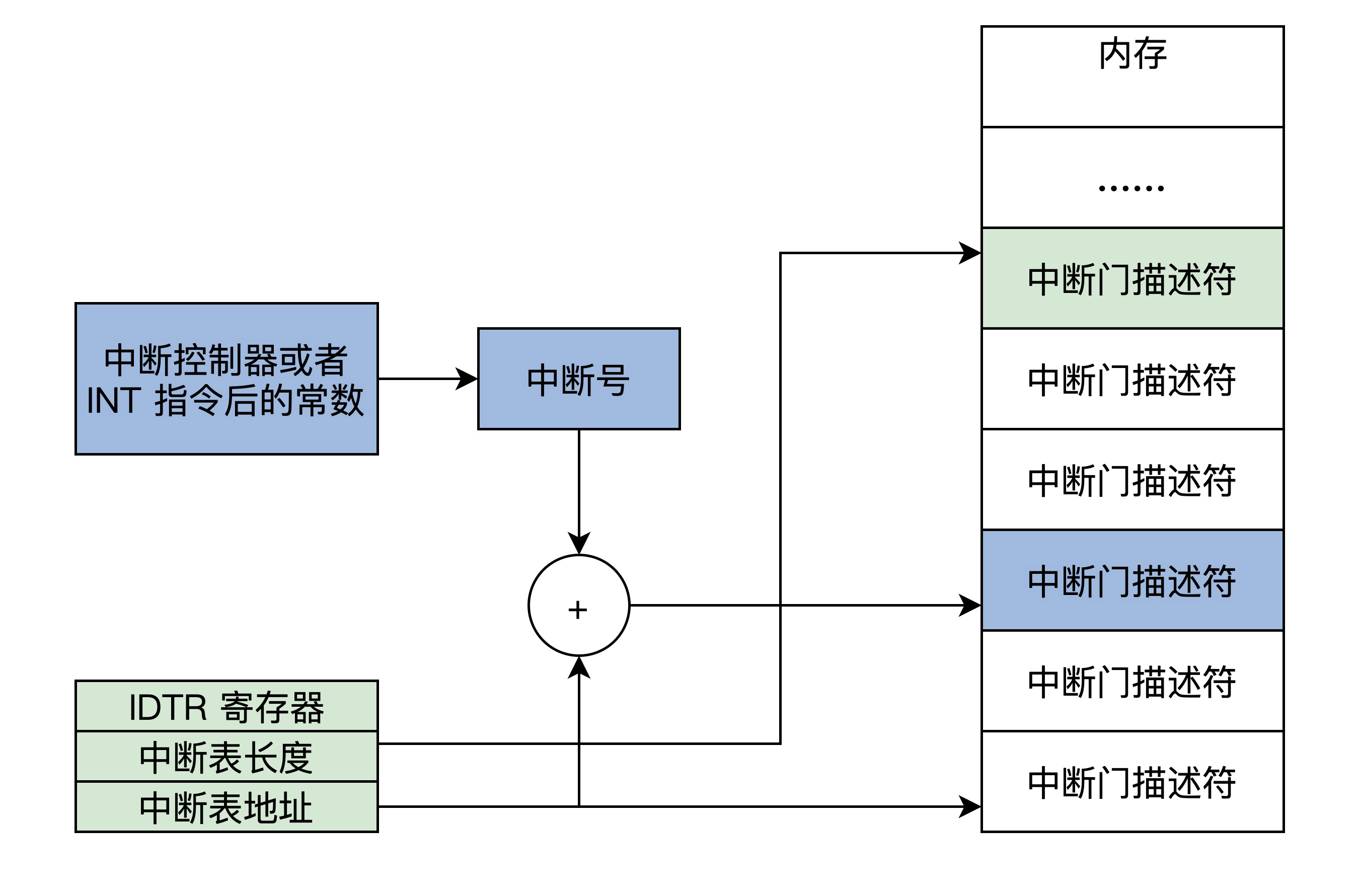
- 产生中断后,CPU 首先会检查中断号是否大于最后一个中断门描述符,x86 CPU 最大支持 256 个中断源(即中断号:0~255),然后检查描述符类型(是否是中断门或者陷阱门)、是否为系统描述符,是不是存在于内存中。
- 接着,检查中断门描述符中的段选择子指向的段描述符。
- 最后做权限检查,
如果 CPL 小于等于中断门的 DPL并且CPL 大于等于中断门中的段选择子,就指向段描述符的 DPL。
- 门打开是当前特权级低,门打开后就执行中断代码了,此时的特权级应该高
- 进一步的,CPL 等于中断门中的段选择子指向段描述符的 DPL,则为同级权限不进行栈切换,否则进行栈切换。如果进行栈切换,还需要从 TSS 中加载具体权限的 SS、ESP,当然也要对 SS 中段选择子指向的段描述符进行检查。
- 做完这一系列检查之后,CPU 才会加载中断门描述符中目标代码段选择子到 CS 寄存器中,把目标代码段偏移加载到 EIP 寄存器中。
2.7 切换到保护模式
x86 CPU 在第一次加电和每次 reset 后,都会自动进入实模式,要想进入保护模式,就需要程序员写代码实现从实模式切换到保护模式。切换到保护模式的步骤如下。
-
准备全局段描述符表(GDT),代码如下。
GDT_START:knull_dsc: dq 0kcode_dsc: dq 0x00cf9e000000ffffkdata_dsc: dq 0x00cf92000000ffffGDT_END:GDT_PTR:GDTLEN dw GDT_END-GDT_START-1GDTBASE dd GDT_START -
加载设置 GDTR 寄存器,使之指向全局段描述符表。lgdt
lgdt [GDT_PTR] -
设置 CR0 寄存器,开启保护模式。
;开启 PEmov eax, cr0bts eax, 0 ; CR0.PE =1mov cr0, eax -
进行长跳转,加载 CS 段寄存器,即段选择子。
jmp dword 0x8 :_32bits_mode ;_32bits_mode为32位代码标号即段偏移因为我们无法直接或间接 mov 一个数据到 CS 寄存器中,因为刚刚开启保护模式时,CS 的影子寄存器还是实模式下的值,所以需要告诉 CPU 加载新的段信息。
接下来,CPU 发现了 CRO 寄存器第 0 位的值是 1,就会按 GDTR 的指示找到全局描述符表,然后根据索引值 8,把新的段描述符信息加载到 CS 影子寄存器,当然这里的前提是进行一系列合法的检查。
到此为止,CPU 真正进入了保护模式,CPU 也有了 32 位的处理能力。
3、长模式
长模式又名 AMD64,因为这个标准是 AMD 公司最早定义的,它使 CPU 在现有的基础上有了 64 位的处理能力,既能完成 64 位的数据运算,也能寻址 64 位的地址空间。这在大型计算机上犹为重要,因为它们的物理内存通常有几百 GB。
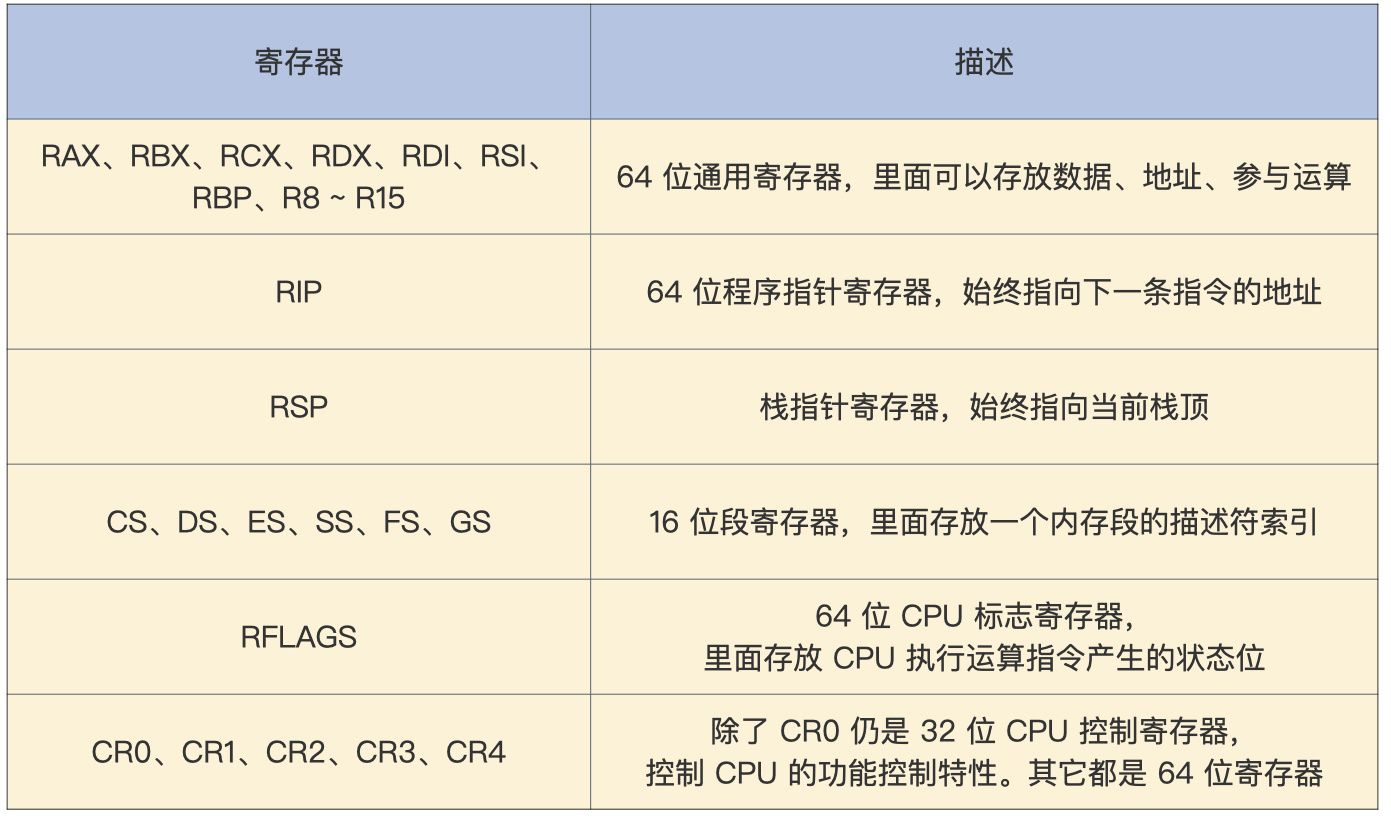
3.1 长模式寄存器
长模式相比于保护模式,增加了一些通用寄存器,并扩展通用寄存器的位宽,所有的通用寄存器都是 64 位,还可以单独使用低 32 位。
这个低 32 位可以拆分成一个低 16 位寄存器,低 16 位又可以拆分成两个 8 位寄存器,如下表。
长模式下的寄存器:
3.2 长模式段描述符
长模式依然具备保护模式绝大多数特性,如特权级和权限检查。相同的部分就不再重述了,这里只会说明长模式和保护模式下的差异。
下面我们来看看长模式下段描述的格式,如下图所示。
长模式段描述符:
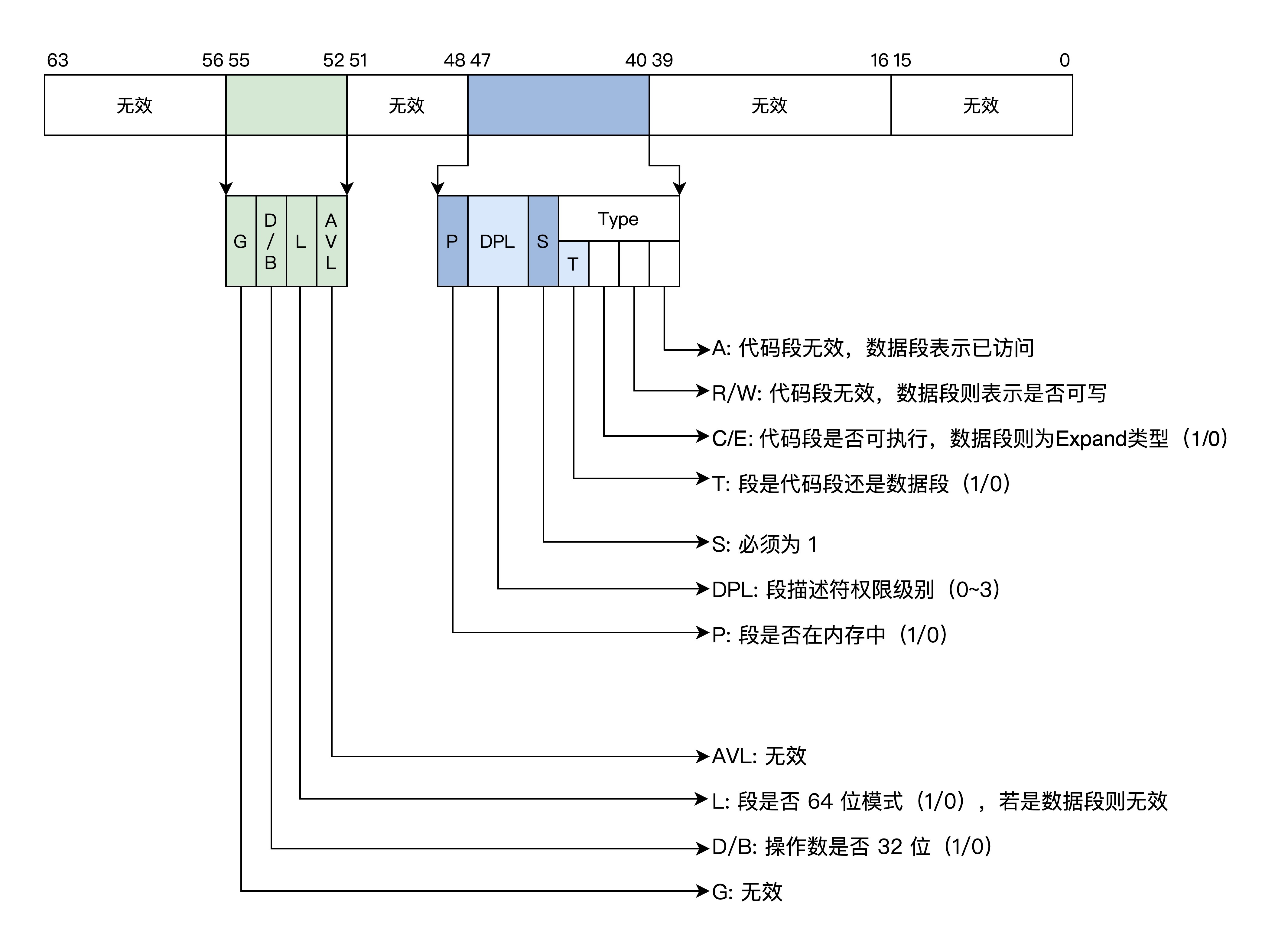
在长模式下,CPU 不再对段基址和段长度进行检查,只对 DPL 进行相关的检查,这个检查流程和保护模式下一样。
当描述符中的 L=1,D/B=0 时,就是 64 位代码段,DPL 还是 0~3 的特权级。然后有多个段描述在内存中形成一个全局段描述符表,同样由 CPU 的 GDTR 寄存器指向。
长模式下的段描述符表:
ex64_GDT:null_dsc: dq 0;第一个段描述符CPU硬件规定必须为0c64_dsc:dq 0x0020980000000000 ;64位代码段;无效位填0;D/B=0,L=1,AVL=0 ;P=1,DPL=0,S=1;T=1,C=0,R=0,A=0d64_dsc:dq 0x0000920000000000 ;64位数据段;无效位填0;P=1,DPL=0,S=1;T=0,C/E=0,R/W=1,A=0eGdtLen equ $ - null_dsc ;GDT长度eGdtPtr:dw eGdtLen - 1 ;GDT界限 dq ex64_GDT
上面代码中注释已经很清楚了,段长度和段基址都是无效的填充为 0,CPU 不做检查。但是上面段描述符的 DPL=0,这说明需要最高权限即 CPL=0 才能访问。若是数据段的话,G、D/B、L 位都是无效的。
3.3 长模式中断
保护模式下为了实现对中断进行权限检查,实现了中断门描述符,在中断门描述符中存放了对应的段选择子和其段内偏移,还有 DPL 权限,如果权限检查通过,则用对应的段选择子和其段内偏移装载 CS:EIP 寄存器。
其中的段内偏移只有 32 位,但是长模式支持 64 位内存寻址,所以要对中断门描述符进行修改和扩展,下面我们就来看看长模式下的中断门描述符的格式,如下图所示。
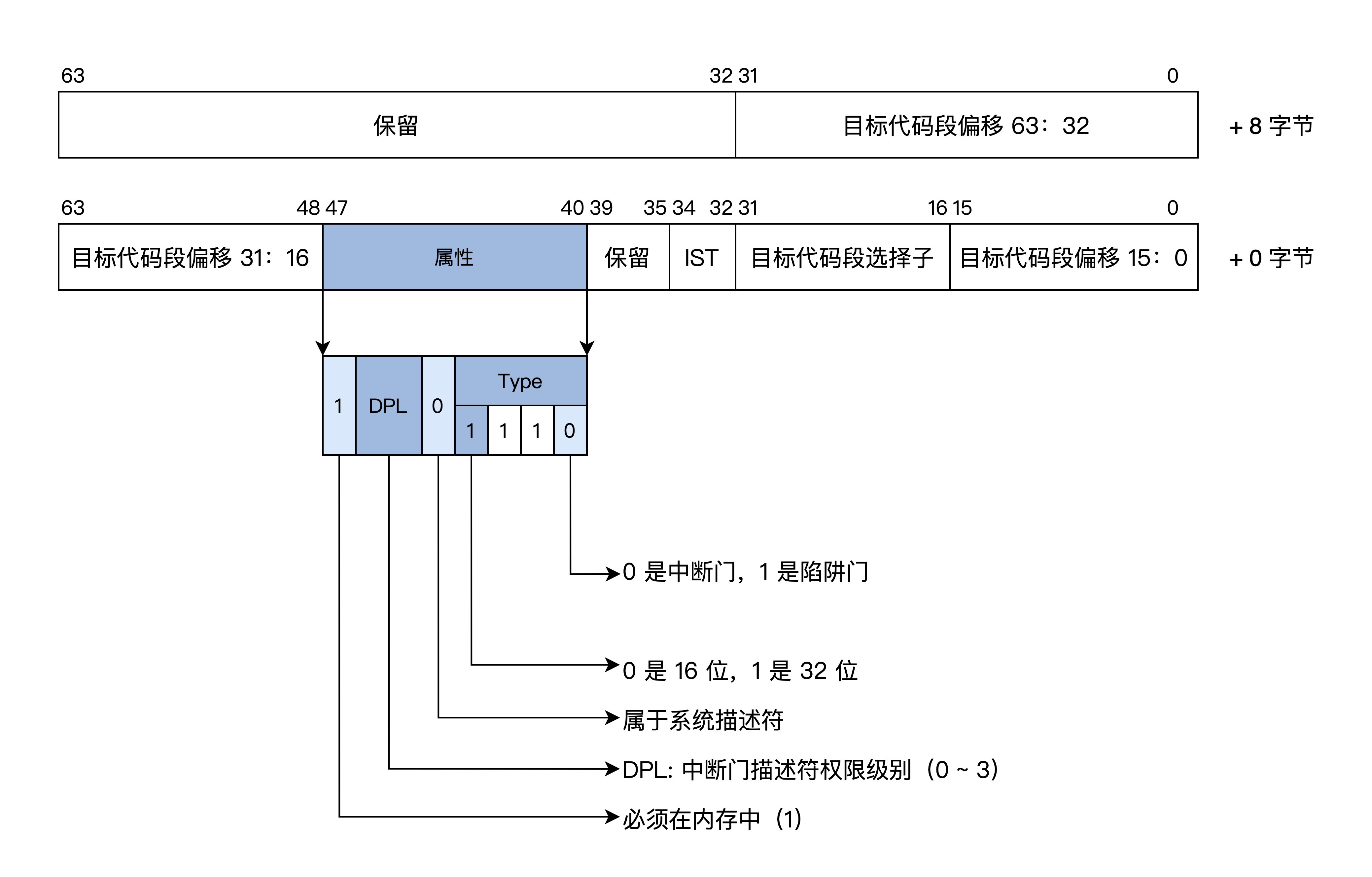
首先为了支持 64 位寻址中断门描述符在原有基础上增加 8 字节,用于存放目标段偏移的高 32 位值。其次,目标代码段选择子对应的代码段描述符必须是 64 位的代码段。最后其中的 IST 是 64 位 TSS 中的 IST 指针,因为我们不使用这个特性,所以不作详细介绍。
长模式也同样在内存中有一个中断门描述符表,只不过表中的条目(如上图所示)是 16 字节大小,最多支持 256 个中断源,对中断的响应和相关权限的检查和保护模式一样,这里不再赘述。
3.4 切换到长模式
我们既可以从实模式直接切换到长模式,也可以从保护模式切换长模式。切换到长模式的步骤如下。
-
准备长模式全局段描述符表。
ex64_GDT:null_dsc: dq 0;第一个段描述符CPU硬件规定必须为0c64_dsc:dq 0x0020980000000000 ;64位代码段d64_dsc:dq 0x0000920000000000 ;64位数据段eGdtLen equ $ - null_dsc ;GDT长度eGdtPtr:dw eGdtLen - 1 ;GDT界限 dq ex64_GDT -
准备长模式下的 MMU 页表,这个是为了开启分页模式,切换到长模式必须要开启分页,想想看,长模式下已经不对段基址和段长度进行检查了,那么内存地址空间就得不到保护了。而长模式下内存地址空间的保护交给了 MMU,MMU 依赖页表对地址进行转换,页表有特定的格式存放在内存中,其地址由 CPU 的 CR3 寄存器指向。
mov eax, cr4bts eax, 5 ;CR4.PAE = 1mov cr4, eax ;开启 PAEmov eax, PAGE_TLB_BADR ;页表物理地址mov cr3, eax -
加载 GDTR 寄存器,使之指向全局段描述表
lgdt [eGdtPtr] -
开启长模式,要同时开启保护模式和分页模式,在实现长模式时定义了 MSR 寄存器,需要用专用的指令 rdmsr、wrmsr 进行读写,IA32_EFER 寄存器的地址为 0xC0000080,它的第 8 位决定了是否开启长模式。
;开启 64位长模式mov ecx, IA32_EFERrdmsrbts eax, 8 ;IA32_EFER.LME =1wrmsr;开启 保护模式和分页模式mov eax, cr0bts eax, 0 ;CR0.PE =1bts eax, 31mov cr0, eax -
进行跳转,加载 CS 段寄存器,刷新其影子寄存器。
jmp 08:entry64 ;entry64为程序标号即64位偏移地址
4、总结
- 实模式,早期 CPU 是为了支持单道程序运行而实现的,单道程序能掌控计算机所有的资源,早期的软件规模不大,内存资源也很少,所以实模式极其简单,仅支持 16 位地址空间,分段的内存模型,对指令不加限制地运行,对内存没有保护隔离作用。
- 保护模式,随着多道程序的出现,就需要操作系统了。内存需求量不断增加,所以 CPU 实现了保护模式以支持这些需求。保护模式包含特权级,对指令及其访问的资源进行控制,对内存段与段之间的访问进行严格检查,没有权限的绝不放行,对中断的响应也要进行严格的权限检查,扩展了 CPU 寄存器位宽,使之能够寻址 32 位的内存地址空间和处理 32 位的数据,从而 CPU 的性能大大提高。
- 长模式,又名 AMD64 模式,最早由 AMD 公司制定。由于软件对 CPU 性能需求永无止境,所以长模式在保护模式的基础上,把寄存器扩展到 64 位同时增加了一些寄存器,使 CPU 具有了能处理 64 位数据和寻址 64 位的内存地址空间的能力。长模式弱化段模式管理,只保留了权限级别的检查,忽略了段基址和段长度,而地址的检查则交给了 MMU。
六、虚幻与真实:程序中的地址如何转换?
1、虚拟地址
正如其名,这个地址是虚拟的,自然而然地和具体环境进行了解耦,这个环境包括系统软件环境和硬件环境。
虚拟地址是逻辑上存在的一个数据值,比如 0~100 就有 101 个整数值,这个 0~100 的区间就可以说是一个虚拟地址空间,该虚拟地址空间有 101 个地址。
我们再来看看最开始 Hello World 的例子,我们用 objdump 工具反汇编一下 Hello World 二进制文件,就会得到如下的代码片段:
objdump -d hello
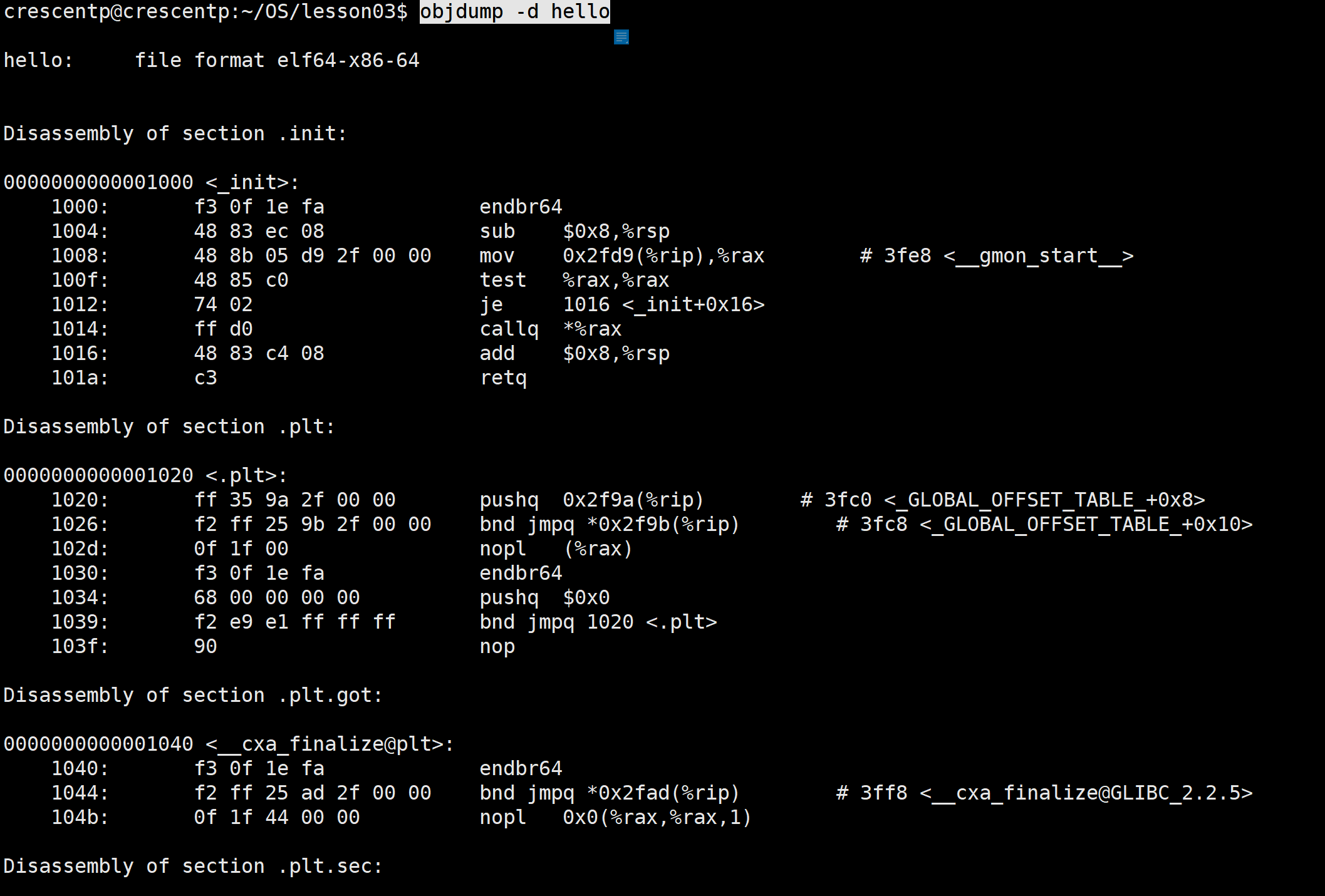
0000000000001000 <_init>: 1000: f3 0f 1e fa endbr64 1004: 48 83 ec 08 sub $0x8,%rsp 1008: 48 8b 05 d9 2f 00 00 mov 0x2fd9(%rip),%rax # 3fe8 <__gmon_start__> 100f: 48 85 c0 test %rax,%rax 1012: 74 02 je 1016 <_init+0x16> 1014: ff d0 callq *%rax 1016: 48 83 c4 08 add $0x8,%rsp 101a: c3 retq
上述代码中,左边第一列数据就是虚拟地址,第三列中是程序指令,如:“mov 0x2fd9(%rip),%rax”指令中的数据都是虚拟地址。
事实上,所有的应用程序开始的部分都是这样的。这正是因为每个应用程序的虚拟地址空间都是相同且独立的。
那么这个地址是由谁产生的呢?
答案是链接器,其实我们开发软件经过编译步骤后,就需要链接成可执行文件才可以运行,而链接器的主要工作就是把多个代码模块组装在一起,并解决模块之间的引用,即处理程序代码间的地址引用,形成程序运行的静态内存空间视图。
只不过这个地址是虚拟而统一的,而根据操作系统的不同,这个虚拟地址空间的定义也许不同,应用软件开发人员无需关心,由开发工具链给自动处理了。由于这虚拟地址是独立且统一的,所以各个公司开发的各个应用完全不用担心自己的内存空间被占用和改写。
2、物理地址
程序装进内存中想要执行,就需要和内存打交道,从内存中取得指令和数据。而内存只认一种地址,那就是物理地址。
什么是物理地址呢?物理地址在逻辑上也是一个数据,只不过这个数据会被地址译码器等电子器件变成电子信号,放在地址总线上,地址总线电子信号的各种组合就可以选择到内存的储存单元了。
但是地址总线上的信号(即物理地址),也可以选择到别的设备中的储存单元,如显卡中的显存、I/O 设备中的寄存器、网卡上的网络帧缓存器。不过如果不做特别说明,我们说的物理地址就是指选择内存单元的地址。
3、虚拟地址到物理地址的转换
明白了虚拟地址和物理地址之后,我们发现虚拟地址必须转换成物理地址,这样程序才能正常执行。要转换就必须要转换机构,它相当于一个函数:p=f(v),输入虚拟地址 v,输出物理地址 p。
用软件方式实现太低效,用硬件实现没有灵活性,最终就用了软硬件结合的方式实现,它就是 MMU(内存管理单元)。MMU 可以接受软件给出的地址对应关系数据,进行地址转换。
我们先来看看逻辑上的 MMU 工作原理框架图。如下图所示:
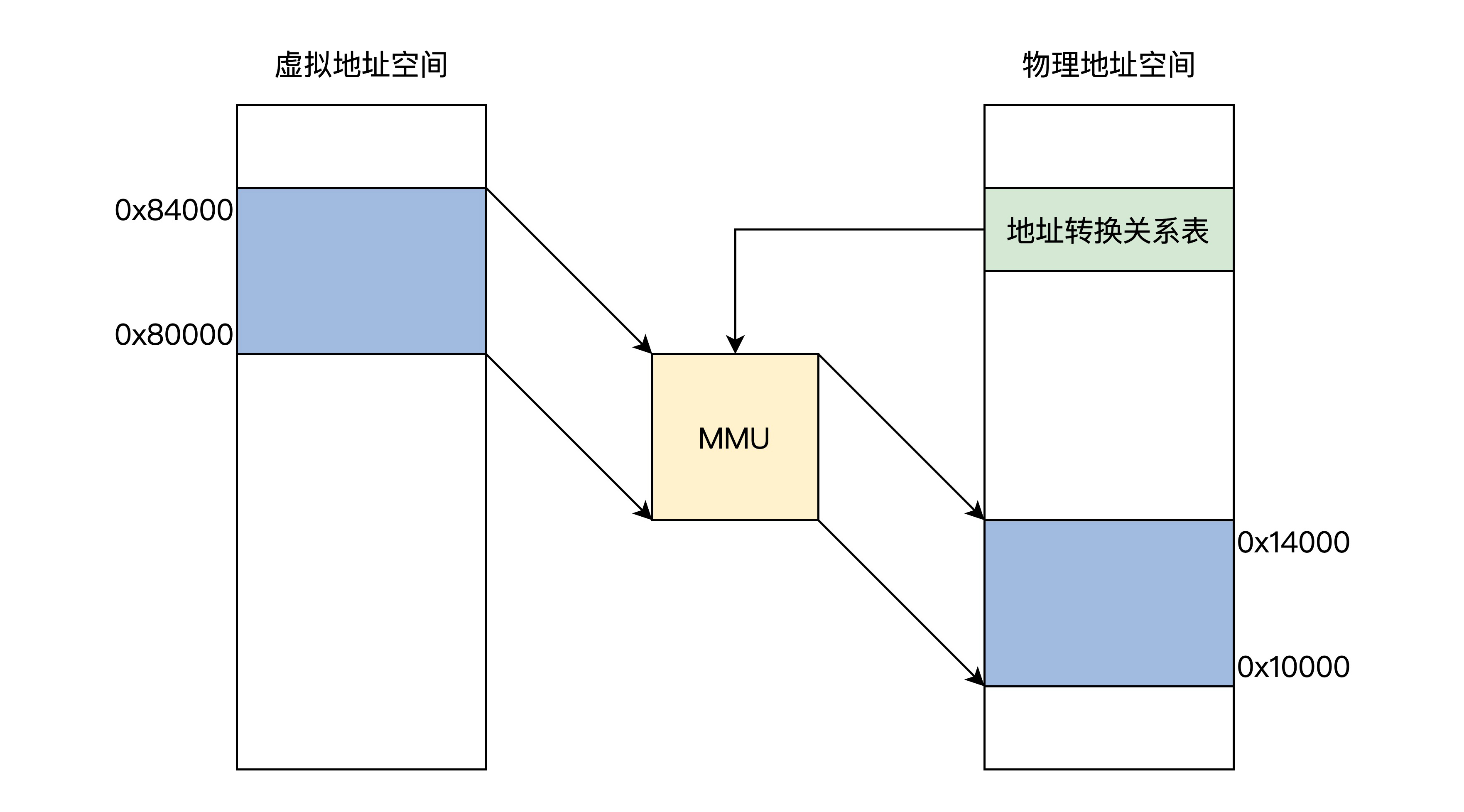
上图中展示了 MMU 通过地址关系转换表,将 0x80000~0x84000 的虚拟地址空间转换成 0x10000~0x14000 的物理地址空间,而地址关系转换表本身则是放物理内存中的。
如果在地址关系转换表中,这样来存放:一个虚拟地址对应一个物理地址。
那么问题来了,32 位地址空间下,4GB 虚拟地址的地址关系转换表就会把整个 32 位物理地址空间用完,这显然不行。
要是结合前面的保护模式下分段方式呢,地址关系转换表中存放:一个虚拟段基址对应一个物理段基址,这样看似可以,但是因为段长度各不相同,所以依然不可取。
综合刚才的分析,系统设计者最后采用一个折中的方案,即把虚拟地址空间和物理地址空间都分成同等大小的块,也称为页,按照虚拟页和物理页进行转换。根据软件配置不同,这个页的大小可以设置为 4KB、2MB、4MB、1GB,这样就进入了现代内存管理模式——分页模型。
下面来看看分页模型框架,如下图所示:
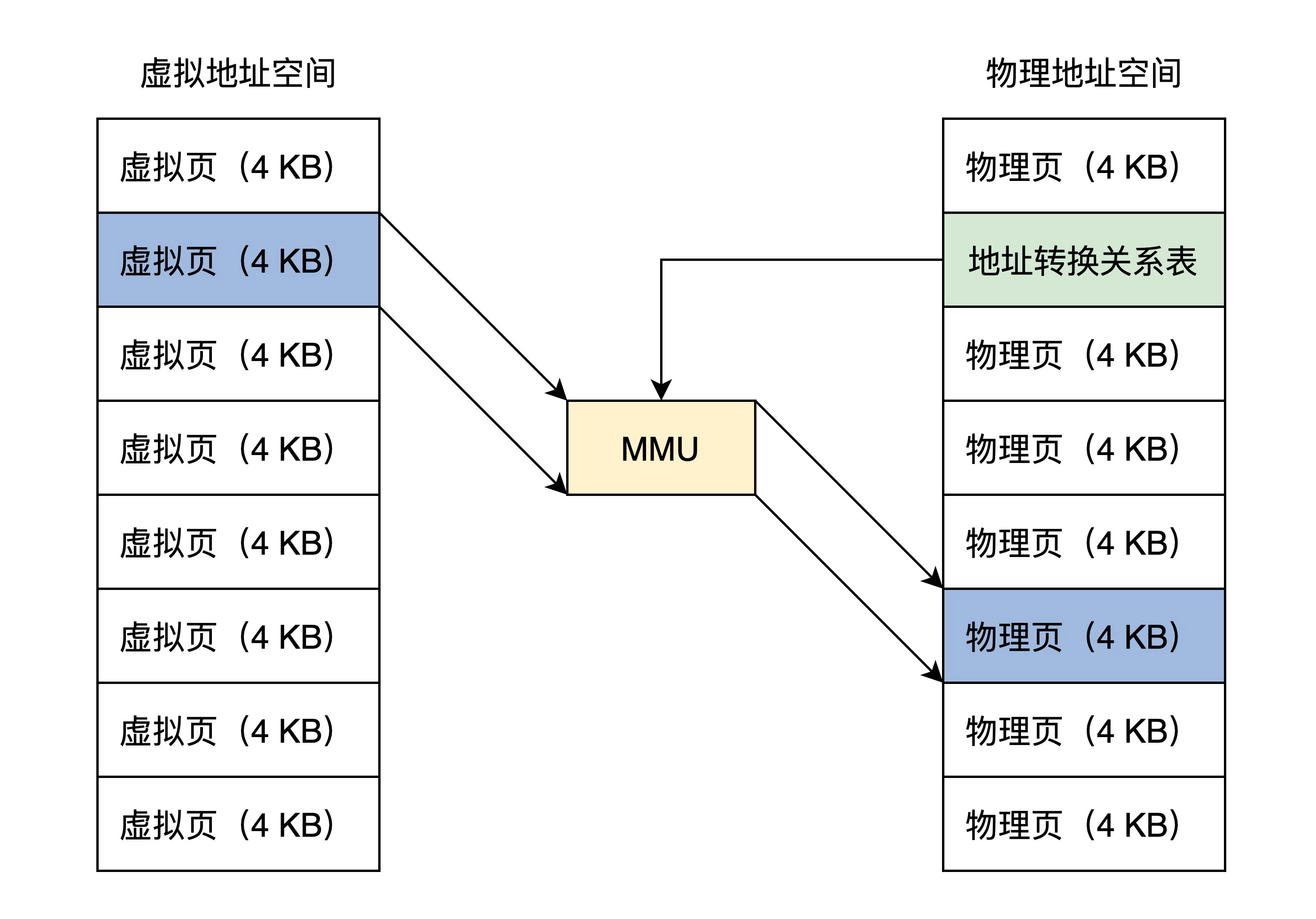
结合图片可以看出,一个虚拟页可以对应到一个物理页,由于页大小一经配置就是固定的,所以在地址关系转换表中,只要存放虚拟页地址对应的物理页地址就行了。
4、MMU
MMU 即内存管理单元,是用硬件电路逻辑实现的一个地址转换器件,它负责接受虚拟地址和地址关系转换表,以及输出物理地址。
根据实现方式的不同,MMU 可以是独立的芯片,也可以是集成在其它芯片内部的,比如集成在 CPU 内部,x86、ARM 系列的 CPU 就是将 MMU 集成在 CPU 核心中的。
SUN 公司的 CPU 是将独立的 MMU 芯片卡在总线上的,有一夫当关的架势。下面我们只研究 x86 CPU 中的 MMU。x86 CPU 要想开启 MMU,就必须先开启保护模式或者长模式,实模式下是不能开启 MMU 的。
由于保护模式的内存模型是分段模型,它并不适合于 MMU 的分页模型,所以我们要使用保护模式的平坦模式,这样就绕过了分段模型。这个平坦模型和长模式下忽略段基址和段长度是异曲同工的。地址产生的过程如下所示。
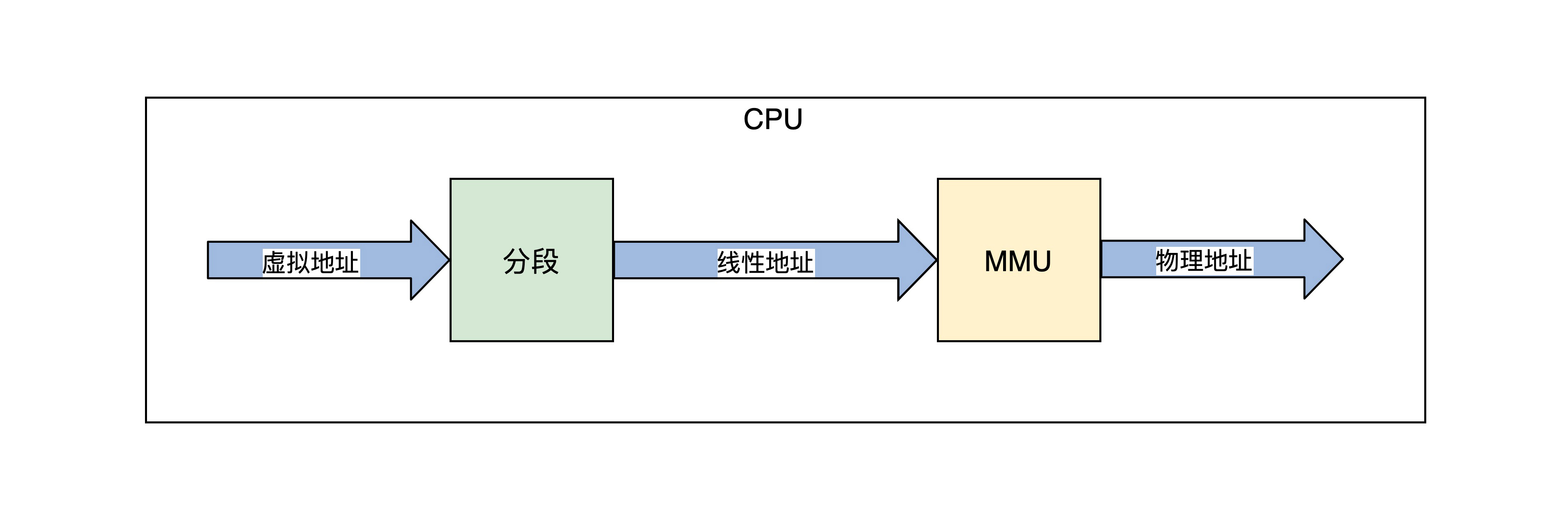
上图中,程序代码中的虚拟地址,经过 CPU 的分段机制产生了线性地址(每个段的地址都是从0开始),平坦模式和长模式下线性地址和虚拟地址是相等的。
如果不开启 MMU,在保护模式下可以关闭 MMU,这个线性地址就是物理地址。因为长模式下的分段弱化了地址空间的隔离,所以开启 MMU 是必须要做的,开启 MMU 才能访问内存地址空间。
5、MMU 页表
现在我们开始研究地址关系转换表,其实它有个更加专业的名字——页表。它描述了虚拟地址到物理地址的转换关系,也可以说是虚拟页到物理页的映射关系,所以称为页表。
为了增加灵活性和节约物理内存空间(因为页表是放在物理内存中的),所以页表中并不存放虚拟地址和物理地址的对应关系,只存放物理页面的地址,MMU 以虚拟地址为索引去查表返回物理页面地址,而且页表是分级的,总体分为三个部分:一个顶级页目录,多个中级页目录,最后才是页表,逻辑结构图如下.
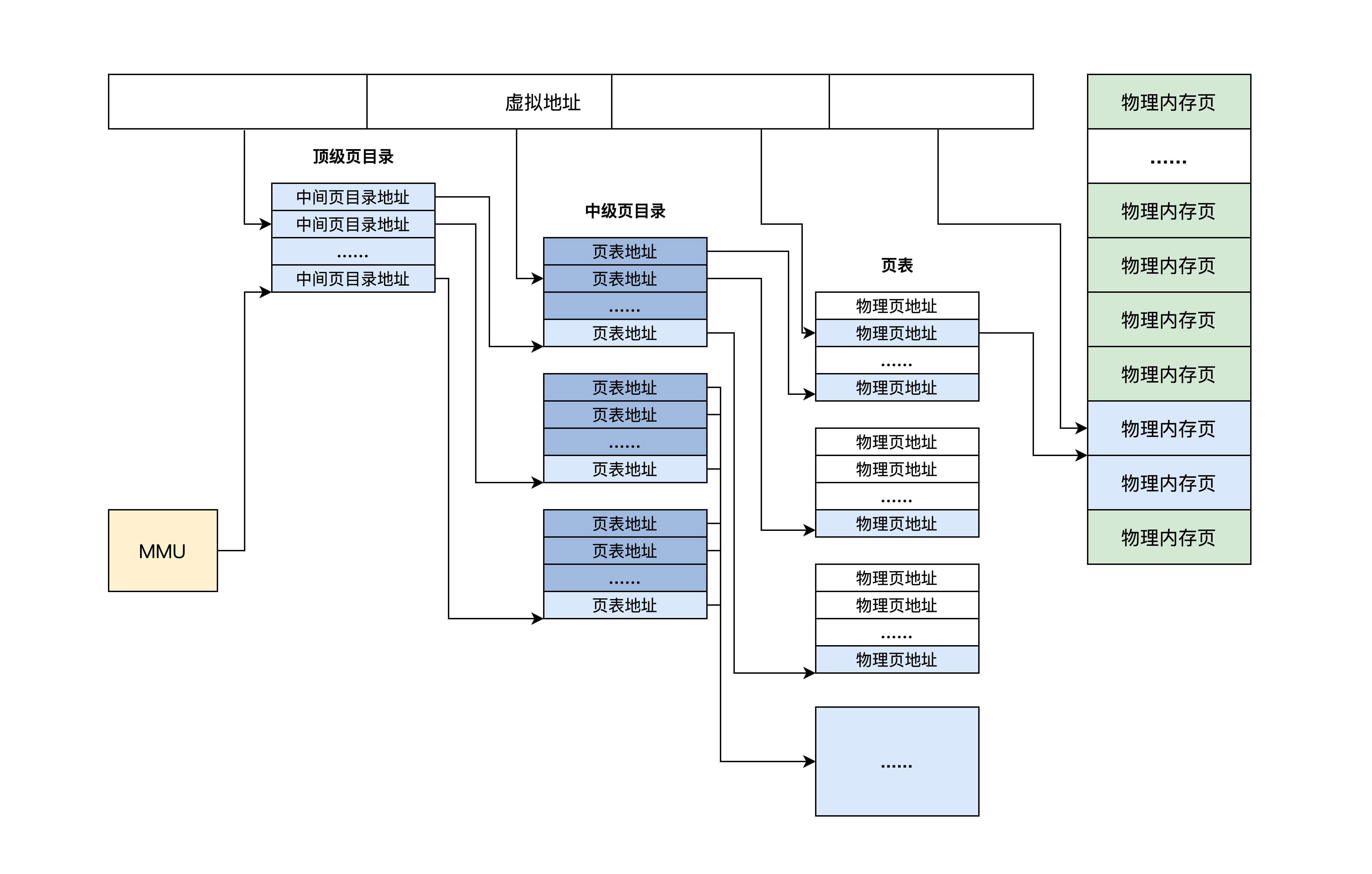
从上面可以看出,一个虚拟地址被分成从左至右四个位段。
第一个位段索引顶级页目录中一个项,该项指向一个中级页目录,然后用第二个位段去索引中级页目录中的一个项,该项指向一个页目录,再用第三个位段去索引页目录中的项,该项指向一个物理页地址,最后用第四个位段作该物理页内的偏移去访问物理内存。这就是 MMU 的工作流程。
6、保护模式下的分页
前面的内容都是理论上帮助我们了解分页模式原理的,分页模式的灵活性、通用性、安全性,是现代操作系统内存管理的基石,更是事实上的标准内存管理模型,现代商用操作系统都必须以此为基础实现虚拟内存功能模块。
因为我们的主要任务是开发操作系统,而开发操作系统就落实到真实的硬件平台上去的,下面我们就来研究 x86 CPU 上的分页模式。
首先来看看保护模式下的分页,保护模式下只有 32 位地址空间,最多 4GB-1 大小的空间。
根据前面得知 32 位虚拟地址经过分段机制之后得到线性地址,又因为通常使用平坦模式,所以线性地址和虚拟地址是相同的。
保护模式下的分页大小通常有两种,一种是 4KB 大小的页,一种是 4MB 大小的页。分页大小的不同,会导致虚拟地址位段的分隔和页目录的层级不同,但虚拟页和物理页的大小始终是等同的。
保护模式下的分页——4KB 页
该分页方式下,32 位虚拟地址被分为三个位段:页目录索引、页表索引、页内偏移,只有一级页目录,其中包含 1024 个条目 ,每个条目指向一个页表,每个页表中有 1024 个条目。其中一个条目就指向一个物理页,每个物理页 4KB。这正好是 4GB 地址空间。如下图所示。
保护模式下的4KB分页
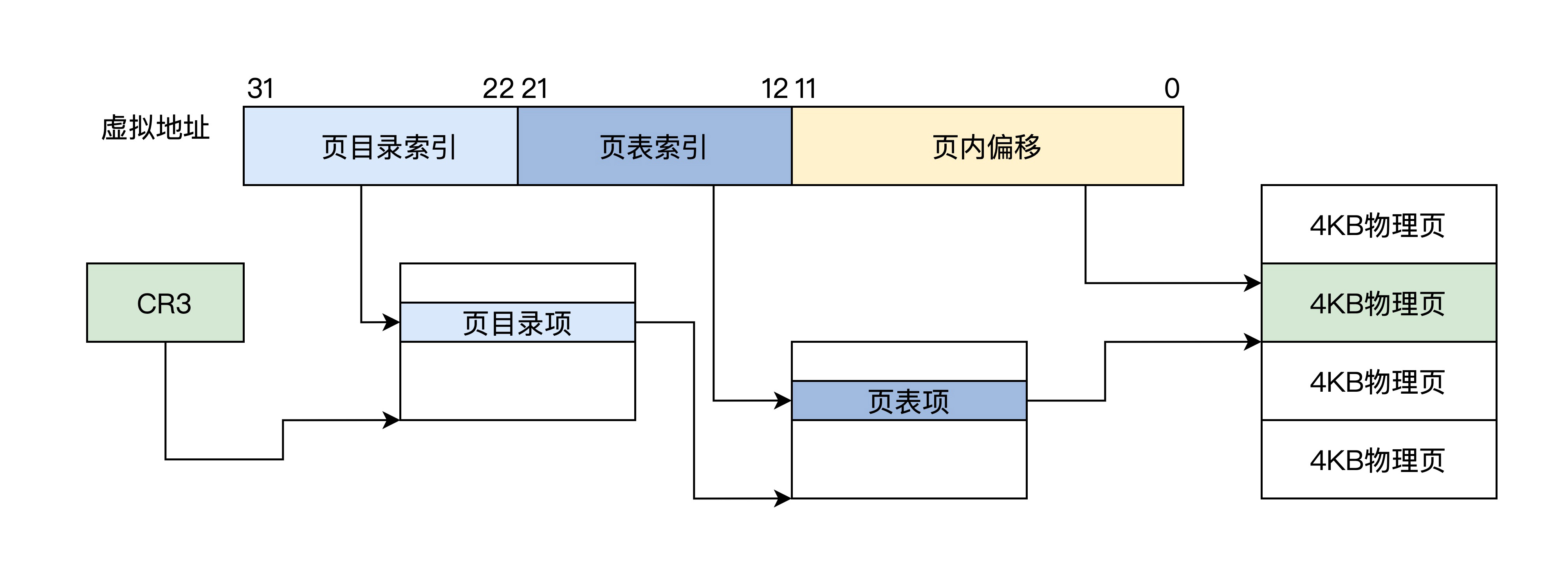
上图中 CR3 就是 CPU 的一个 32 位的寄存器,MMU 就是根据这个寄存器找到页目录的。下面,我们看看当前分页模式下的 CR3、页目录项、页表项的格式。
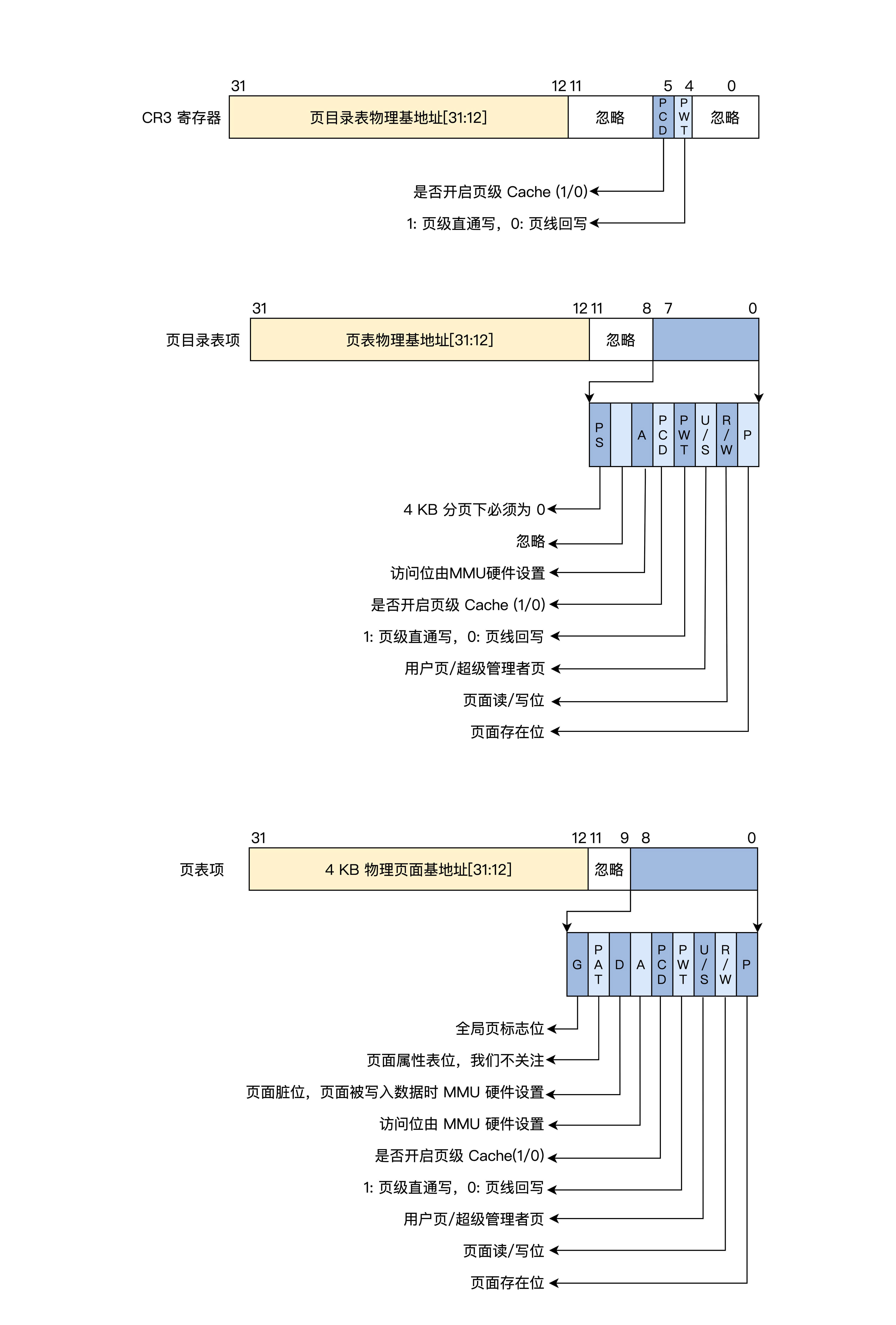
可以看到,页目录项、页表项都是 4 字节 32 位,1024 个项正好是 4KB(一个页),因此它们的地址始终是 4KB 对齐的,所以低 12 位才可以另作它用,形成了页面的相关属性,如是否存在、是否可读可写、是用户页还是内核页、是否已写入、是否已访问等。
十、 设置工作模式与环境(上):建立计算机
从内核映像格式说起