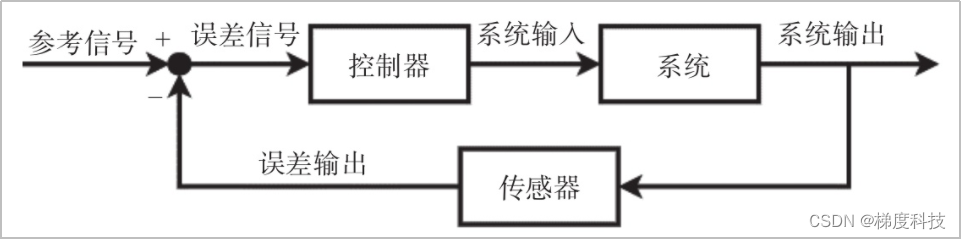
Kubernetes 的核心就是控制理论,Kubernetes控制器中实现的控制回路是一种闭环反馈控制系统,该类型的控制系统基于反馈回路将目标系统的当前状态与预定义的期望状态相比较,二者之间的差异作为误差信号产生一个控制输出作为控制器的输入,以减少或消除目标系统当前状态与期望状态的误差,如图1所示。这种控制循环在Kubernetes上也称为调谐循环。
对Kubernetes来说,无论控制器的具体实现有多么简单或多么复杂,它基本都是通过定期重复执行如下3个步骤来完成控制任务。
(1)从 API Server 读取资源对象的期望状态和当前状态。
(2)比较二者的差异,而后运行控制器中的必要代码操作现实中的资源对象,将资源对象的真实状态修正为Spec中定义的期望状态,例如创建或删除 Pod 对象,以及发起一个云服务 API 请求等。
(3)变动操作执行成功后,将结果状态存储在API Server上的目标资源对象的status字段中。
如图3 Kubernetes控制循环工作示意图。
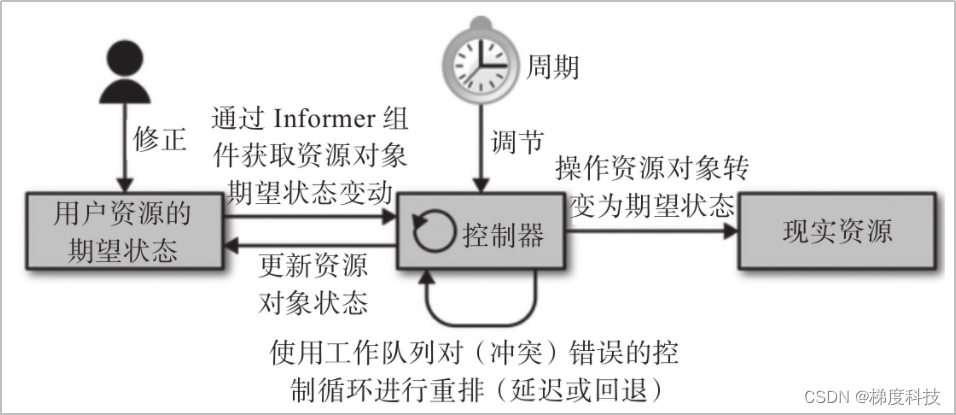
任务繁重的Kubernetes集群上同时运行着数量巨大的控制循环,每个循环都有一组特定的任务要处理,为了避免 API Server被请求淹没,需设定控制回路以较低的频率运行,默认每3分钟一次。同时,为了能及时触发由客户端提交的期望状态的更改,控制器向API Server注册监视受控资源对象,这些资源对象期望状态的任何变动都会由Informer 组件通知给控制器立即执行而无须等到下一轮的控制循环。控制器使用工作队列将需要运行的控制循环进行排队,从而确保在受控对象众多或资源对象变动频繁的场景中尽量少地错过控制任务。
出于简化管理的目的,Kubernetes 将数十种内置的控制器程序整合成了名为kube-controller-manager的单个应用程序,并运行为独立的单体守护进程,它是控制平面的重要组件,也是整个Kubernetes集群的控制中心。