深度学习-图像分类算法
小卷积核应用-VGGNet
利用小卷积核代替大卷积核,感受野不变减少网络的卷积参数量
网络结构
VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
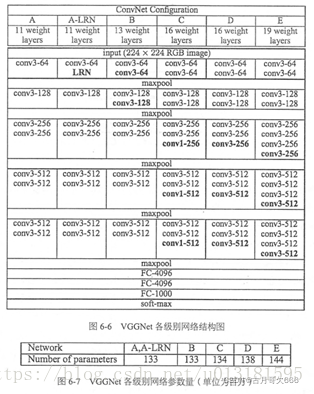
原文链接https://blog.csdn.net/u013181595/article/details/80974210
最优局部稀疏结构-Inception
以往网络结构通过级联进行堆叠,随着深度的加深容易产生梯度消失,Szegedy提出加深网络的宽度,用1×1、3×3、5×5与最大池化并行方式进行组织,形成一个局部稀疏结构。
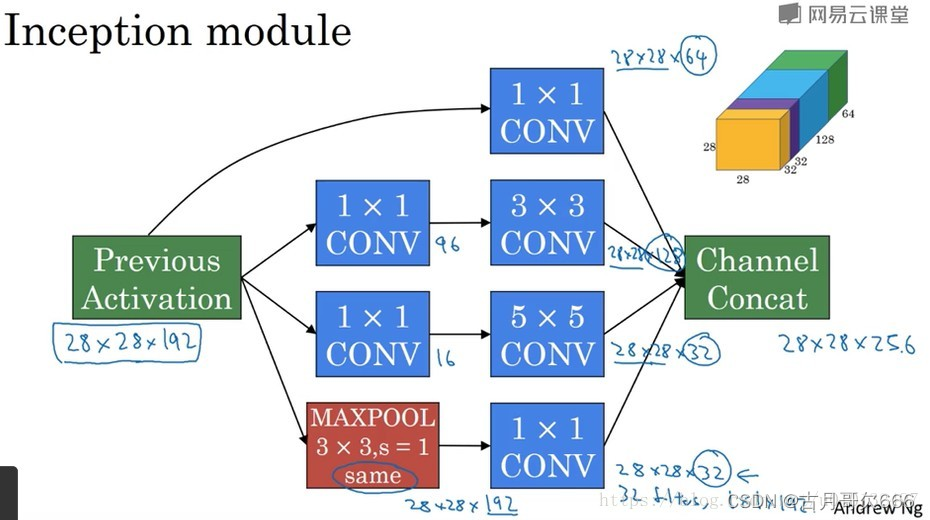
inception网络或inception层的作用就是代替人工来确定卷积层中的过滤器类型或者确定是否需要卷积层或者池化层。一个inception模块会将所有的可能叠加起来,这就是inception模块的核心内容。
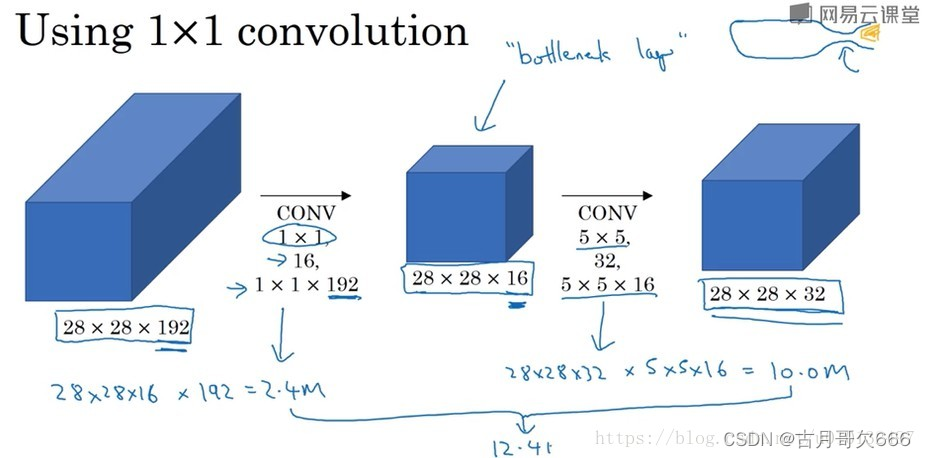
通常称中间的层为瓶颈层,也就是最小网络层。我们先缩小网络,然后在扩大 它。通过两张图的对比可以明显看到,采用了1*1的层的计算成本下降了10倍。那么仅仅大幅缩小表示层规模会不会影响神经网络的性能?事实证明,只要合理构建瓶颈层,那么既可以缩小规模,又不会降低性能,从而大量节省了运算。
原文链接https://blog.csdn.net/u010132497/article/details/80060303
Inception V1-V4总结:
Inception V1:
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,
一方面增加了网络的width,

另一方面增加了网络对尺度的适应性;
Inception V2:
一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯;
另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
Inception V3:
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),
这样的好处,
既可以加速计算(多余的计算能力可以用来加深网络),
又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,
还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
Inception V4:
v4研究了Inception模块结合Residual Connection能不能有改进?
发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,
同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能
原文链接:https://blog.csdn.net/sunflower_sara/article/details/80686658
恒等映射残差单元-ResNet
ResNet 是在 2015年 由何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
残差单元原理
H(x)= F(x)+x
当网络某一层已经能够提取最佳特征时,后续层试图改变特征x会使得网络的损失变大,为了减少损失使F(x)自动趋于0,此时H(x)= x
网络结构
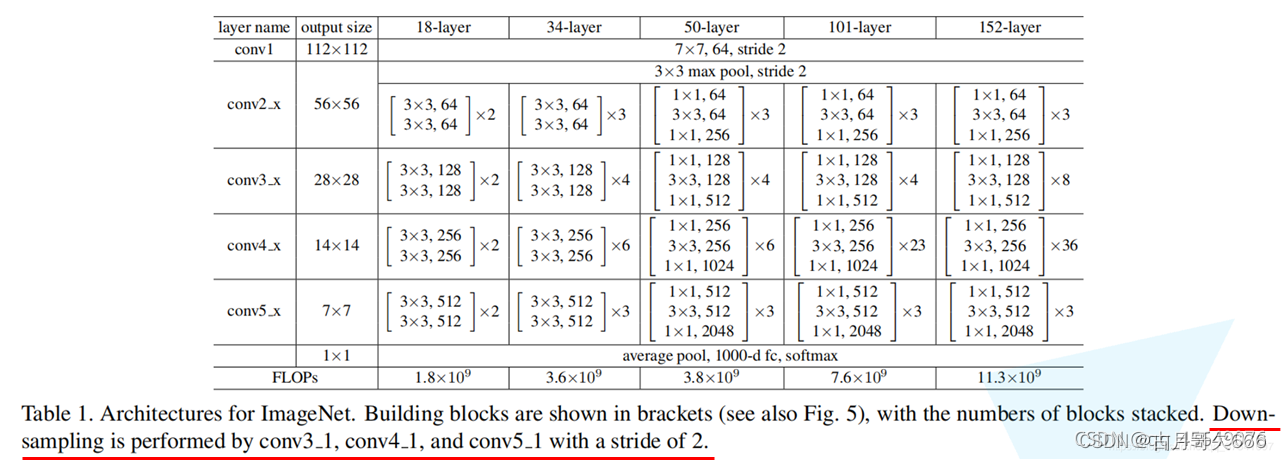
亮点
1.超深的网络结构(超过1000层)。
2.提出residual(残差结构)模块。
3.使用Batch Normalization 加速训练(丢弃dropout)。
1.采用残差结构的原因
1.梯度消失和梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
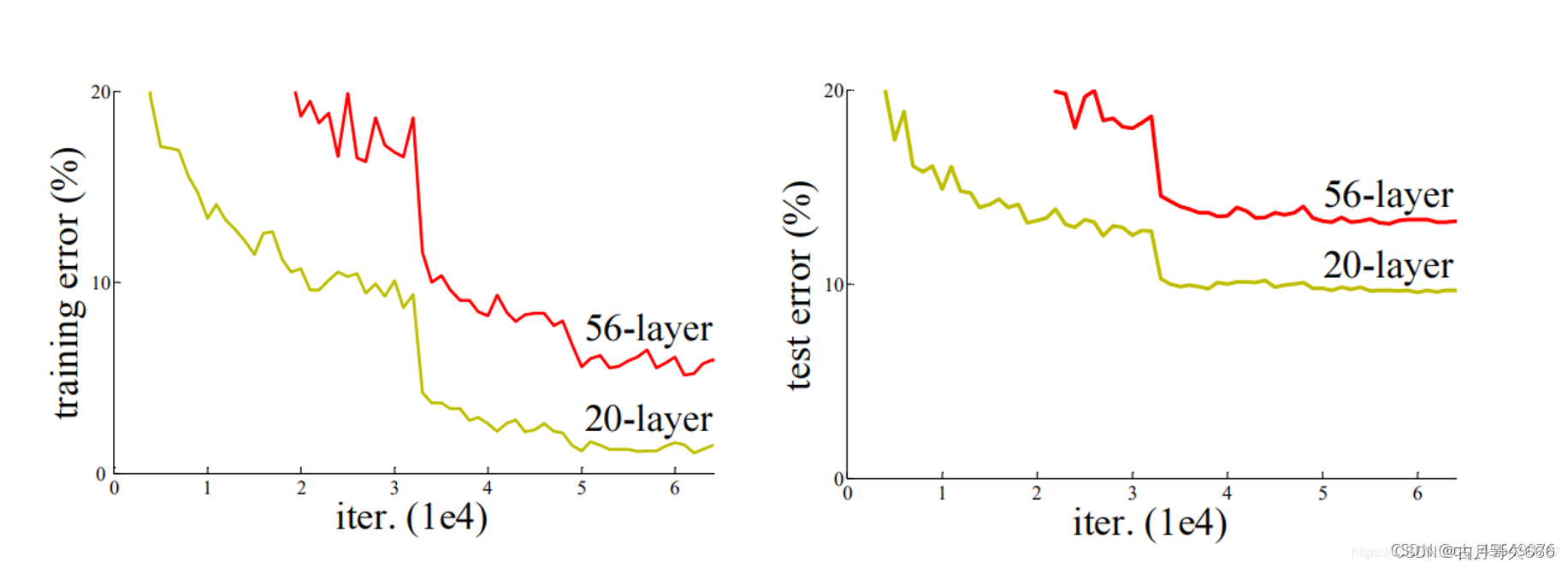
2.退化问题
随着层数的增加,预测效果反而越来越差。如下图所示
多层密集连接-DenseNet
huang等2017年受ResNet启发提出一种更加密集的前馈式跳跃连接,从特征角度出发,通过增加网络信息流的隐性深层监督和特征复用缓解了梯度消失的问题,同时提升模型的性能。
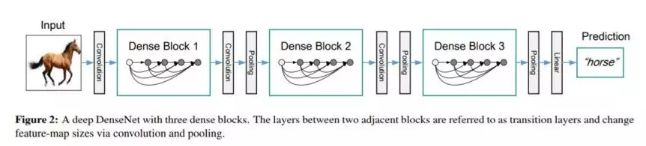
在同一个Denseblock中要求feature size保持相同大小,在不同Denseblock之间设置transition layers实现Down sampling, 在作者的实验中transition layer由BN + Conv(1×1) +2×2 average-pooling组成
网络结构

DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:
(1) 相比ResNet拥有更少的参数数量.
(2) 旁路加强了特征的重用.
(3) 网络更易于训练,并具有一定的正则效果.
(4) 缓解了gradient vanishing和model degradation的问题.
论文链接:https://arxiv.org/pdf/1608.06993.pdf
代码的github链接:https://github.com/liuzhuang13/DenseNet
MXNet版本代码(有ImageNet预训练模型):https: //github.com/miraclewkf/DenseNet
| 原文链接 | https://zhuanlan.zhihu.com/p/43057737 |
|---|---|
| 原文链接 | https://www.jianshu.com/p/8a117f639eef |
特征通道重标定-SENet
SENet是ImageNet 2017(ImageNet收官赛)的冠军模型,和ResNet的出现类似,都在很大程度上减小了之前模型的错误率,并且复杂度低,新增参数和计算量小。
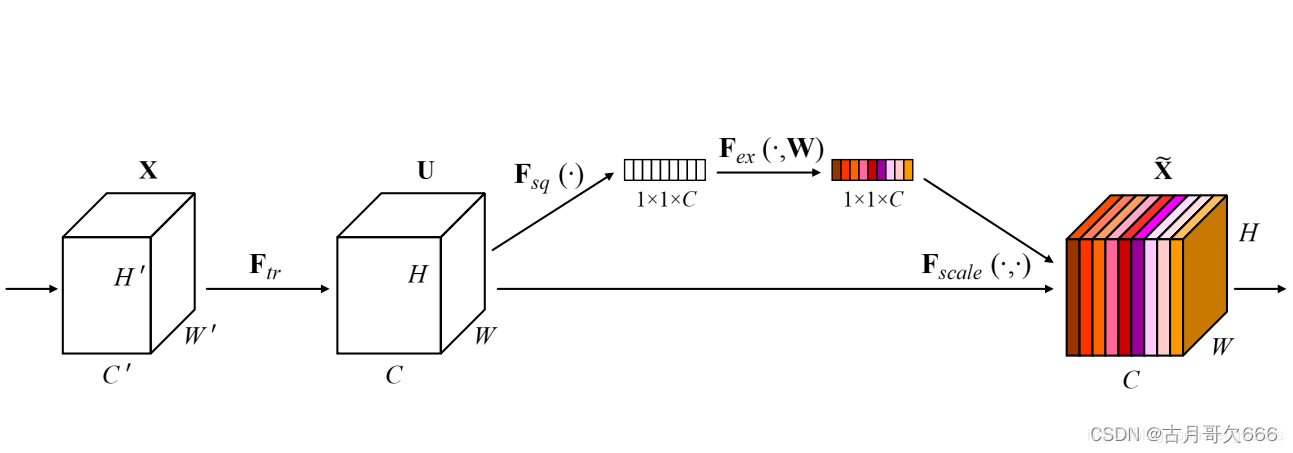
一个可以嵌入到主干网络的子模块,包括压缩、激励、和乘积,可以学习特征通道之间的关系,将每个特征通道对目标任务的重要性转化为可以学习的参数,根据学习到的参数增强有用的特征通道抑制贡献小的特征通道。
-
Squeeze部分。即为压缩部分,采用一个全局平均池化操作将输入特征图沿着通道维进行压缩,原始feature map的维度为HWC,其中H是高度(Height),W是宽度(width),C是通道数(channel)。Squeeze做的事情是把HWC压缩为11C,相当于把HW压缩成一维了,实际中一般是用global average pooling实现的。HW压缩成一维后,相当于这一维参数获得了之前H*W全局的视野,感受区域更广。
-
Excitation部分。得到Squeeze的11C的表示后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。
-
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
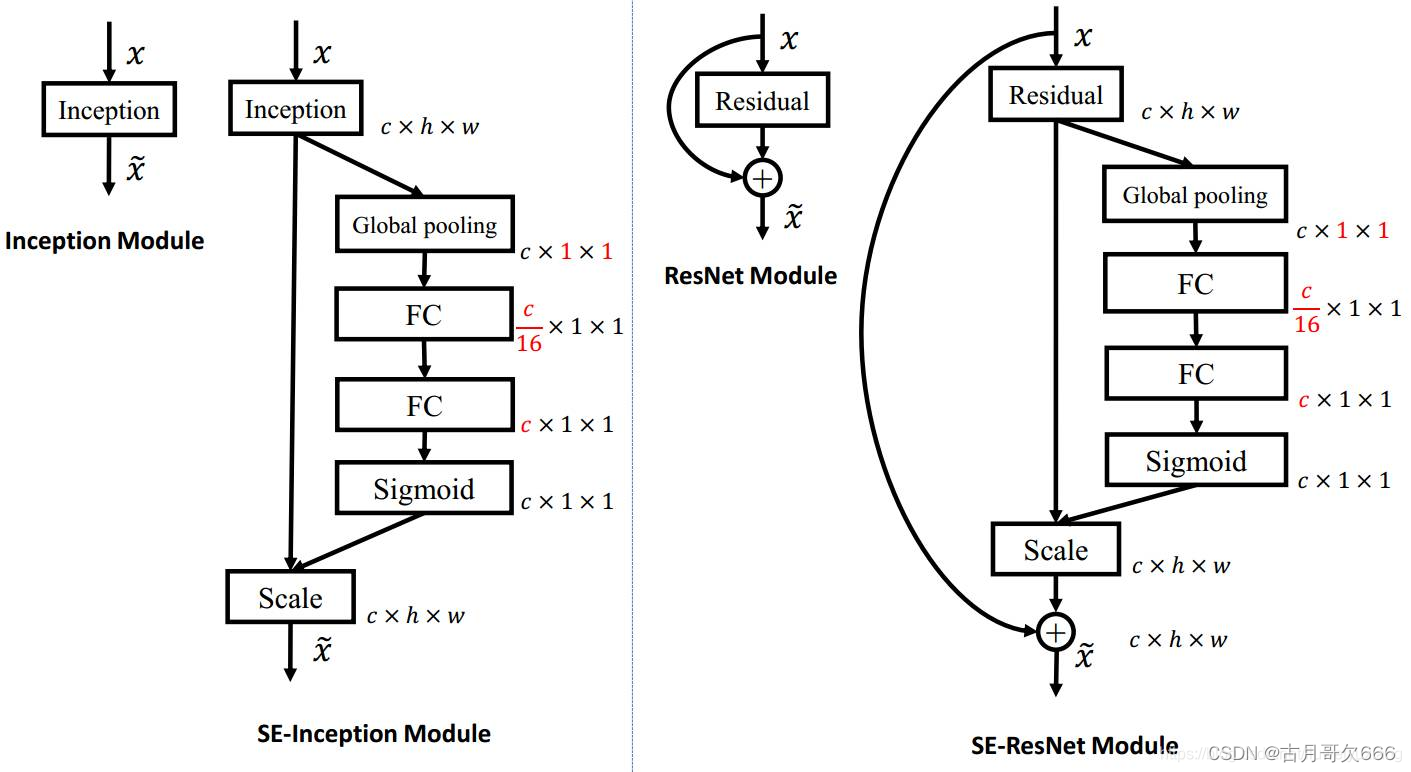
SENet可以应用到残差结构和密集连接结构中
ImageNet分类Top5错误率:
2014 GoogLeNet 6.67%
2015 ResNet 3.57%
2016 ~~~ 2.99%
2017 SENet 2.25%
| SENet官方Caffe实现: | https://github.com/hujie-frank/SENet |
|---|---|
| PyTorch实现: | https://github.com/moskomule/senet.pytorch |
| TensorFlow实现: | https://github.com/taki0112/SENet-Tensorflow |
原文链接:https://blog.csdn.net/guanxs/article/details/98544872
https://blog.csdn.net/liuweiyuxiang/article/details/84075343
总结:
SE模块将注意力机制引入到深度学习中,且SE本身模块不会对本身结构造成影响,只是多出一条分支,仅增加少量参数,降低了模型的错误率。
通道压缩与扩展-SqueezeNet
伯克利和斯坦福2016年提出的轻量级卷积神经网络,代表模型轻量化的开端
主要包括压缩与扩张
压缩
利用1×1卷积降维,减少特征图数目,降低模型的参数量
扩张
利用1×1与3×3卷积进行扩张,还原特征图数量
深度可分离卷积-MobileNet
定位优势:移动设备或者嵌入式设备的轻量级网络,相对同样轻量级的SqueezeNet网络,参数两量近似,性能更好。
主要分为两部分:深度通道卷积与逐点卷积
深度通道卷积
对于来自上一层的多通道特征图,首先将其全部拆分为单个通道的特征图,分别对他们进行单通道卷积,它只对来自上一层的特征图做了尺寸的调整,而通道数没有发生变化
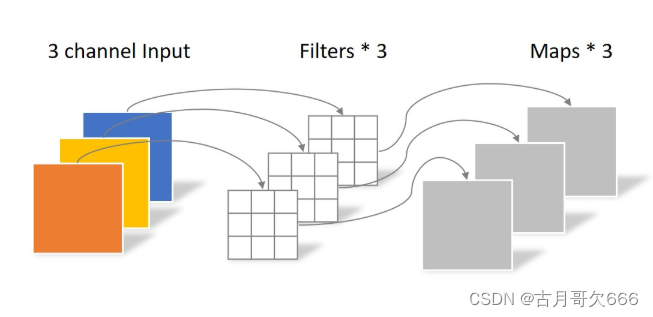
逐点卷积
因为深度卷积没有融合通道间信息,所以需要配合逐点卷积使用。
采取卷积核1×1大小,滤波器包含了与上一层通道数(即深度卷积通道个数)一样数量的卷积核。相对于通道而言,对每个通道进行整合卷积(之间是每个通道单独卷积,这里将不同通道利用1×1逐点卷积并进行合并得到特征图),这又被称之为逐点卷积(Pointwise Convolution)。
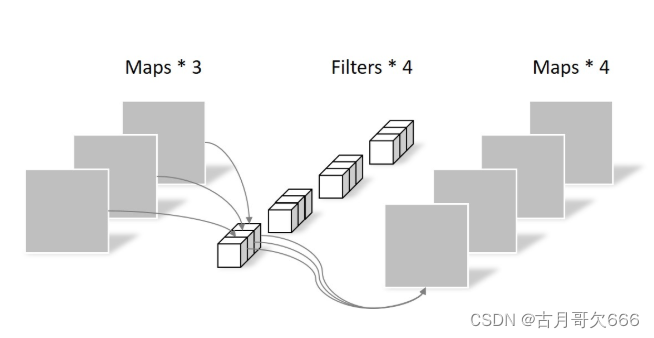
常规卷积
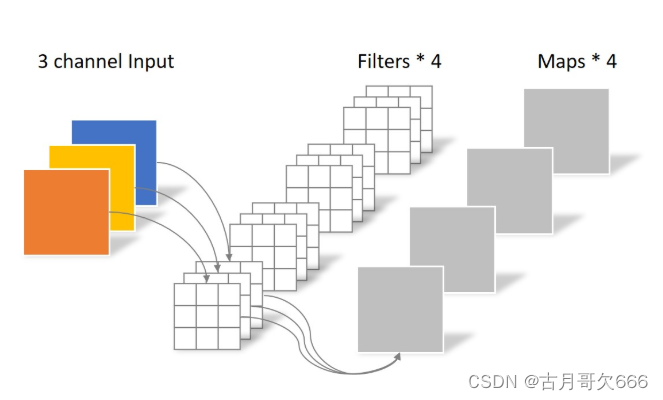
总结:
常规卷积与深度可分离卷积不同其实在于深度可分离卷积将卷积过程进行了拆分,把特征图通道与卷积核通道卷积拆分出来。
具有更少的参数量(参数量对比)、计算代价
参数量计算方式:
P=M1* M2* D* D
注:M1,M2输入输出特征图数量,D卷积核大小