「前言」文章是关于网络编程的socket套接字方面的,下面开始讲解!
「归属专栏」网络编程
「笔者」枫叶先生(fy)
「座右铭」前行路上修真我
「枫叶先生有点文青病」
「每篇一句」
春风得意马蹄疾,一日看尽长安花。
——孟郊《登科后》

目录
一、预备知识
1.1 源IP和目的IP
理解源IP地址和目的IP地址
- 在IP数据包头部中(在网络层), 有两个IP地址, 分别叫做源IP地址, 和目的IP地址
- IP地址通常在广域网中使用,准确来说,IP地址既可以在局域网中使用也可以在广域网中使用
- 每台主机必须要有IP地址,否则就不能上网
- IP地址标识唯一的主机
什么是源IP和目的IP?
还是张三从北京到云南骑自行车旅游的例子,张三每去到下一站都会说:我从北京来,要去云南旅游。这里的北京就是源IP,云南就是目的IP,旅途中张三会经过很多的站口,但是张三依旧是从北京来,去往云南旅游。其中从北京去往云南这个大目标是不会改变的,虽然旅途中会经过很多个小站。
源IP和目的IP的作用是:为未来的每一个阶段,提供方向目标,方便路径选择
如果在北京主机A向云南主机B发消息,那么主机A的IP地址就是源IP地址,主机B的IP地址就是目的IP
1.2 源MAC地址和目的MAC地址
理解源MAC地址和目的MAC地址
- 源MAC地址和目的MAC地址是包含在链路层的报头当中的
- 而MAC地址实际只在当前局域网内有效
什么是源MAC地址和目的MAC地址?
依旧是张三从北京到云南骑自行车旅游的例子:
- 张三从北京出发
- 张三去到石家庄说:我上一站从北京来,下一站去往郑州;
- 张三去到郑州后说:我上一站从石家庄来,下一站去往西安;
- 张三去到西安后说:我上一站从郑州来,下一站去往成都;
- 张三去到成都后说:我上一站西安来,下一站去往云南;
- 张三到达云南
其中我们发现,张三口中的地址一直在变化,这些变化的地址就是MAC地址,比如:北京去石家庄,北京是源MAC地址,石家庄是目的MAC地址;石家庄去郑州:石家庄就变成了源MAC地址,郑州就变成了目的MAC地址...
同理当数据跨网络到达另一个局域网时,其源MAC地址和目的MAC地址就需要发生变化,因此当数据达到路由器时,路由器会将该数据当中链路层的报头去掉,然后再重新封装一个报头,此时该数据的源MAC地址和目的MAC地址就发生了变化
源MAC地址和目的MAC地址提供了网络通信的可行性
1.2 认识端口号
端口号(port)是传输层协议的内容:(在OS内)
- 端口号是一个2字节16位的整数;
- 端口号用来标识一个进程, 告诉操作系统, 当前的这个数据要交给哪一个进程来处理;
- IP地址 + 端口号能够标识网络上的某一台主机的某一个进程,标识进程在全网的唯一性
- 一个端口号只能被一个进程占用
注:(这里的IP是公网IP),IP到后面再详细解释
1.3 理解 "端口号" 和 "进程PID" 的关系
我们把数据从主机A发送到主机B,目的是让这两台主机进行通信吗?答案肯不是,把数据从主机A发送到主机B是手段不是目的,真正进行通信的其实是主机上的软件(或人),比如小A和小B在各自的主机上下了QQ,小A和小B使用QQ进行聊天,通信的是QQ软件(或人)。
A主机上,可能会同时存在多个正在进行跨网络通信的进程,发送数据是由该QQ软件对应的进程进行发送,发送的数据也不是直接发给B主机,而是先发给客户端软件的服务端进程上,再由服务端进程转发数据给B主机。
此时,B主机上也可能会同时存在多个正在进行跨网络通信的进程,如何识别哪个进程是对应该QQ软件的进程???
- 此时,就需要用到端口号了,端口号的作用是:用来标识一个进程, 告诉操作系统, 当前的这个数据要交给哪一个进程来处理
- IP地址(标识主机在全网的唯一性)+ 该主机上的端口号port(标识主机上进程的唯一性)
- 所以,IP地址 + 端口号port(可以标识该主机上对应的进程,在全网中唯一性)
- 所以,主机A对应进程:IP+port,主机B对应进程:IP + port,这样就可以标识这两个进程在全网都是唯一的
- 所以网络通信的本质是:其实就是进程间通信
- 而进程间通信的前提是:双方进程看到同一份公共资源,而这份公共资源在这里就是网络
通信其实就是在 I/O,所以我们的上网行为无外乎就两种:
- 我把我的数据发出去
- 我要收到别人给我发的数据
进程PID就已经标识了同一台主机上进程的唯一性,为什么不使用PID进行标识?为什么要使用端口号port??
- 进程IPID是用来标识同一台主机上进程的唯一性,它是属于系统级的概念;
- 而端口号(port)也是用来标识同一台主机上进程的唯一性,它是属于网络的概念
- 事实上,用进程的PID标识同一台主机上进程的唯一性,从技术上这也是可以的,但是并没有这么做
- 是因为,系统是系统,网络是网络,系统已经够复杂了,网络再来掺和一脚系统会变得更加复杂
- 单独设置端口号是为了与系统进行解耦
- 标识进程在全网的唯一性,两台主机的的PID可能会相同
- 不是所有的进程都需要提供网络服务或请求(即port),但是所有的进程都需要PID
软件都是用户主动打开的,所以几乎大部分情况都是用户端先向服务端发起请求,那如何保证客户端每次都能找到服务端进程??
- 要保证客户端每次都能找到服务端的进程,就必须要保证服务端的 IP + port 的唯一性,服务端的进程的端口号不能随意改变
底层OS如何根据port找到指定的进程??
- 实际底层采用哈希的方式建立了端口号和进程PID或PCB之间的映射关系,当底层拿到端口号时就可以匹配对应的哈希表,然后就能够找到该端口号对应的进程
注意:一个进程可以绑定多个端口号; 但是一个端口号不能被多个进程绑定
事实上,一台主机发送数据给另一台主机,发送方除了要发送数据外还要把自己的 IP + 端口号port 发送给服务端,服务端进程再转发数据给另一台主机。通信是双方的
所以在未来发送数据的时候一定会多发一部分数据,多发的这部分数据以协议的形式呈现
1.4 源端口号和目的端口号
传输层协议(TCP和UDP)的数据段中有两个端口号, 分别叫做源端口号和目的端口号.,就是在描述 "数据是谁发的, 要发给谁"
这个与源IP与,目的IP类似,就不举张三的例子了,比如主机A给主机B发数据,主机A就是源端口,数据要去下一个局域网的路由器,下一个局域网的路由器就是目的端口,以此类推,直到一直跳跃到主机B
1.5 认识TCP协议
此处我们先对TCP(Transmission Control Protocol 传输控制协议)有一个直观的认识,后面我们再详细讨论TCP的一些细节问题
TCP概述:
- 传输层协议
- 有连接
- 可靠传输
- 面向字节流
TCP协议是面向连接的,如果两台主机之间想要进行数据传输,那么必须要先建立连接,当连接建立成功后才能进行数据传输。
其次,TCP协议是保证可靠的协议,数据在传输过程中如果出现了丢包、乱序等情况,TCP协议都有对应的解决方法
1.6 认识UDP协议
此处我们也是对UDP(User Datagram Protocol 用户数据报协议)有一个直观的认识,后面再详细讨论.
UDP概述:
- 传输层协议
- 无连接
- 不可靠传输
- 面向数据报
使用UDP协议进行通信时无需建立连接,如果两台主机之间想要进行数据传输,那么直接将数据发送给对端主机就行了
但是UDP协议是不可靠的,数据在传输过程中如果出现了丢包、乱序等情况,UDP协议本身是不知道的,也无法处理
注:面向字节流和面向数据报暂时不谈
UDP是不可靠传输,为什么还要有UDP,TCP是可靠传输难道不好吗??
- 这里的 可靠 VS 不可靠 是中性词,没有任何的褒贬义,不是说可靠就是好,不可靠就是不好,这里的可靠和不可靠描述的是一种现象
- 可靠是伴随着成本的提高的,实现是更复杂的,维护和编码成本更高
- 不可靠的实现成本低,实现比较简单,维护和使用成本低
- UDP和TCP都是有适合自己的场景的,比如TCP就比较适合银行的交易系统等,UDP就比较适合直播或者投递广告,两者一般都是一起结合使用的:网络流畅时就使用UDP协议进行数据传输,而当网速不好时就使用TCP协议进行数据传输
1.7 网络字节序
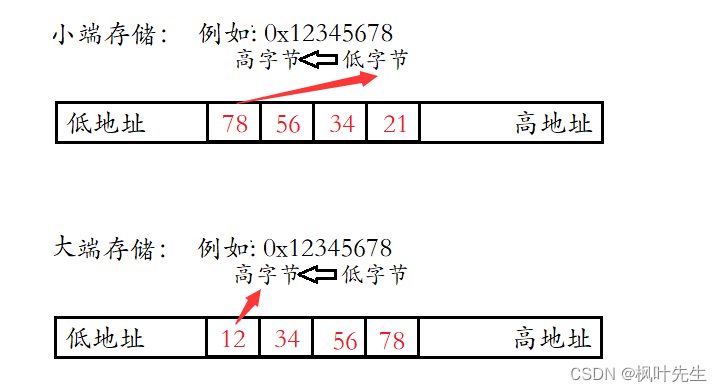
计算机的存储是分大小端的,在C语言已经学习过了
- 大端模式: 数据的高字节内容保存在内存的低地址处,数据的低字节内容保存在内存的高地址处。
- 小端模式: 数据的高字节内容保存在内存的高地址处,数据的低字节内容保存在内存的低地址处。
内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分, 网络数据流同样有大端小端之分
如果只在一台主机上,那么是不需要考虑大小端问题的,因为同一台机器上的数据采用的存储方式都是一样的,要么采用的都是大端存储模式,要么采用的都是小端存储模式。
但如果涉及跨主机网络通信,那就必须考虑大小端的问题,否则其他主机识别出来的数据可能与发送端想要发送的数据是不一致的
比如,两台主机之间在进行网络通信,其中发送端是小端机,而接收端是大端机。发送端将发送缓冲区中的数据按内存地址从低到高的顺序发出后,接收端从网络中获取数据依次保存在接收缓冲区时,也是按内存地址从低到高的顺序保存的
- 但由于发送端和接收端采用的分别是小端存储和大端存储
- 发送端按小端的方式发送数据,比如:0x12345678,发送的顺序是:78 56 34 12,小端识别数据是正常的:0x12345678
- 而接收端是大端存储,接受数据的顺序是 78 56 34 12,最后识别的数据是:0x78563412
- 此时接收端识别到的数据与发送端原本想要发送的数据就不一样了,这就是由于大小端的偏差导致数据识别出现了错误
解决方法
- 解决方法简单粗暴:规定网络中的数据都是大端
- 即发送端是小端,需要先将数据转成大端,然后再发送到网络当中
- 发送端是大端,则可以直接进行发送
- 接收端是小端,需要先将接收的网络数据转成小端后再进行数据识别
- 接收端是大端,则可以直接进行数据识别
以上综述:
- 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出;
- 接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存;
- 因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址.
- TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节.
- 不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据;
- 如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可
网络字节序与主机字节序之间的转换
为使网络程序具有可移植性,使同样的代码在大端和小端计算机上编译后都能正常运行,可以调用以下库函数做网络字节序和主机字节序的转换
注:转换工作不需要我们自己做。直接调用库函数即可完成
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
- 函数名当中的h表示 host,n表示 network,l表示 long,32位长整数,s表示 short,16位短整数
- htonl 的意思就是:把32位的主机字节序转换成(to)32位网络字节序
- 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回
- 如果主机是大端字节序,这些 函数不做转换,将参数原封不动地返回
二、socket编程接口
socket的中文意思是插座,在计算机叫套接字
在进行网络通信时,客户端就相当于插头,服务端就相当于一个插座,但服务端上可能会有多个不同的服务进程(多个插孔),因此当我们在访问服务时需要指明服务进程的端口号(对应规格的插孔),才能享受对应服务进程的服务
套接字的种类大致分三种:
- 网络套接字编程:应用于跨主机网络通信,也支持本地通信
- unix域间套接字:只能进行本地通信
- 原始套接字:可以从应用层直接绕开传输层,直接去访问底层协议,通常用于各种抓bao软件、网络侦测工具
注:后面只讲第一种套接字,即网络编程套接字,网络编程套接字懂了,unix域间套接字也可以看懂(接口相同)
由于有三种套接字,为了使用方便,接口设计者就只设计了一套接口,可以通过传不同的参数,解决所有网络或者其他场景下的网络通信
2.1 socket常见的API接口
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,
socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);注:参数用到再解释
2.2 sockaddr结构
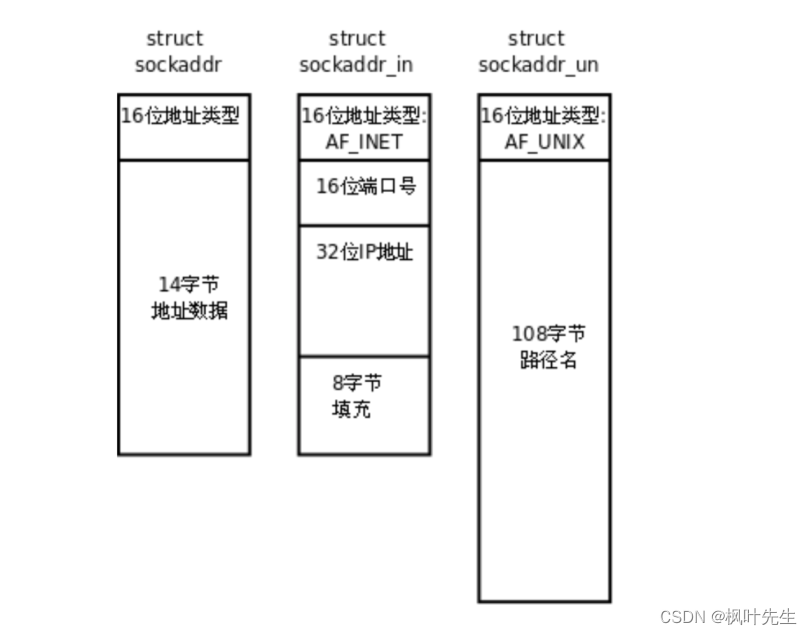
前面说到设计者只设计了一套接口,这套接口里面最重要的就是 sockaddr结构体,除此之外还有两个结构体:sockaddr_in 和 sockaddr_un
- sockaddr_in 结构体是用于跨网络通信,其中 sockaddr_in 的 in 是 inet,"inet" 是Internet Protocol(IP)的简写
- sockaddr_un 结构体是用于本地通信,其中 sockaddr_un 的 un 是 unix
但是我们使用函数时,传的参数是 sockaddr结构体,并不是 sockaddr_in 和 sockaddr_un
- sockaddr_in 和 sockaddr_un结构体头部的16个比特位(2字节)都是一样的,这16位地址类型代表的是使用网络通信还是本地通信
- 而 sockaddr结构体设计前两个字节的内容也与 sockaddr_in 和 sockaddr_un结构体一样,sockaddr结构体其他字段不重要,重要的是前两个字节
- 我们需要做的就是对 sockaddr_in 或 sockaddr_un结构体进行填充,然后传参给 sockaddr,这个过程必须要强制类型转换
- 在socket函数的内部,对于传进来的参数 sockaddr 直接去前两个字节,进行判断是网络通信还是本地通信,知道这个结果后再强制类型转换回 sockaddr_in 和 sockaddr_un结构体
用这样的设计方式,就可以设计出同一套接口套接字接口了,这就是面向对象语言的多态
为什么不用 void* 代替 struct sockaddr* ??
因为当时设计这些 socket 接口时,C语言的语法还不支持 void*。并且在C语言支持了 void* 之后也没有将它改回来,因为这些接口是系统接口,直接内嵌在OS里面的,系统接口是所有上层软件接口的基石,系统接口是不能轻易更改的,否则会带来某些严重的后果
文章暂时到这里,下一篇开始编写代码
--------------------- END ----------------------
「 作者 」 枫叶先生
「 更新 」 2023.6.15
「 声明 」 余之才疏学浅,故所撰文疏漏难免,
或有谬误或不准确之处,敬请读者批评指正。