全卷积网络FCN讲解
一、背景
FCN是由Jonathan Long等人在2015年发表的论文《Fully Convolutional Networks for Semantic Segmentation》中提出的,它是首个端对端针对像素级预测的全卷积网络。
论文地址:https://arxiv.org/pdf/1411.4038.pdf
二、FCN(全卷积网络)
1. CNN与FCN的区别
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
举例:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。

传统的基于CNN分割方法有几个缺点:
- 存储开销很大:
例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。 - 计算效率低下:
相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。 - 像素块大小的限制了感知区域的大小:
通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
而FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
网络结构示意图:
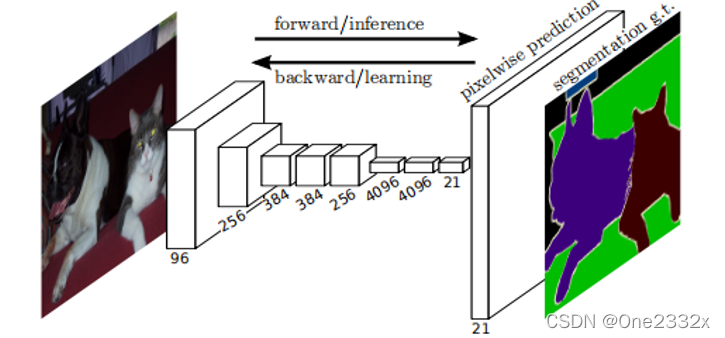
输入的图片可为任意尺寸彩色图片,且输出的和输入的尺寸相同,该网络才用的PACSAL VOC数据集,所以类别有20个+1个背景,总共有21个。
简而言之,FCN就是将传统网络的全连接层替换成卷积层,这样网络的输出不再是类别而是heatmap,并且输入图片的尺寸不受限制。
2. FCN采用的3大技术
全卷积神经网络主要使用了三种技术:
- 卷积化(Convolutionalization): 适应任意尺寸输入,输出低分辨率的分割图片。
- 反卷积 : 低分辨率的图像进行上采样,输出同分辨率的分割图片
- 跳跃结构(跳跃层、Skip Layer): 结合上采样和上层卷积池化后数据,填补丢失的细节数据, 修复还原图像
卷积化(Convolutionalization)
卷积化就是将普通分类网络,例如:VGG16、ResNet、AlexNet等网络中的全连接层,转换为卷积层,如下图所示。
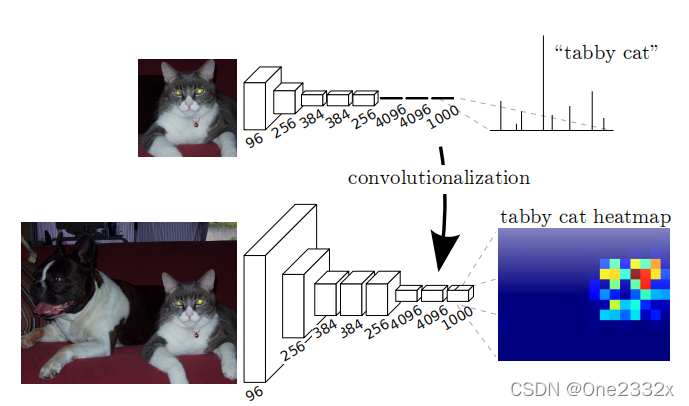
全连接层 --> 卷积层
全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
- 对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块,其余部分都是零。而在其中大部分块中,元素都是相等的。
- 相反,任何全连接层都可以被转化为卷积层。比如,一个全连接层转化为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。
假设一个卷积神经网络,
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,s=1, padding=3, 这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,s=1, 这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,s=1, 最终输出为[1x1x1000]。
实际操作中,每次这样的变换都需要把全连接层的权重W重塑成卷积层的滤波器。
反卷积(Deconvolution)
首先,先介绍一下上采样方法,上采样方法包含插值法(最邻近插值、双线性插值等)、转置卷积方法。
本博客主要介绍转置卷积方法,插值法请参考博客:https://blog.csdn.net/stf1065716904/article/details/78450997
反卷积(Deconvolution)也叫转置卷积(Transposed Convolution), 当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。
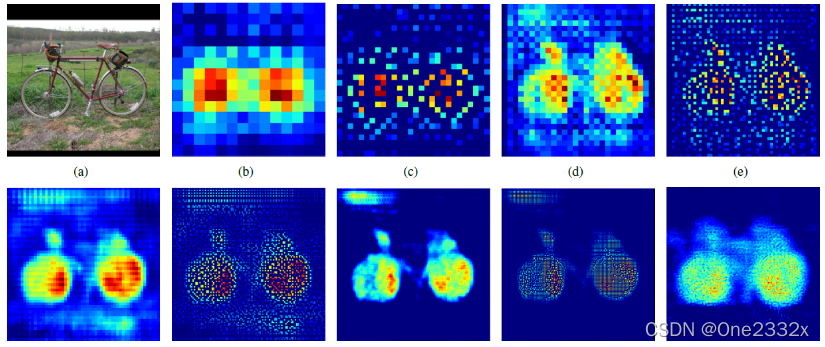
图像(图a)在经过卷积、池化等一系列处理后,得到的特征图(图b)分辨率远小于原图像。这样一来特征图中的像素无法与原图中一一对应,无法对每个像素进行预测。 而经过反卷积方法提升分辨率得到同时,还保证了特征所在区域的权重,最后将图片的分辨率提升原图一致后,权重高的区域则为目标所在区域。
传统的网络是下采样(subsampling),对应的输出尺寸会降低;上采样(upsampling)的意义在于将小尺寸的高维度特征图(feature map)恢复回去,以便做像素级的预测(pixelwise prediction),获得每个点的分类信息,如下图所示。
对于一般卷积,输入的是蓝色4x4矩阵,卷积核大小3x3。当设置卷积参数padding=0,stride=1时,卷积输出绿色2x2矩阵,如下图:

相应的卷积公式为: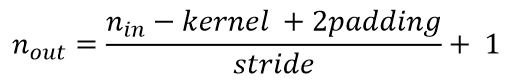
而对于反卷积,相当于把普通卷积反过来,输入蓝色2x2矩阵,卷积核大小还是3x3。当设置反卷积参数padding=0,stride=1时输出绿色4x4矩阵,如图,这相当于完全将上图倒过来。

而对于反卷积公式就是将输入和输出反过来:
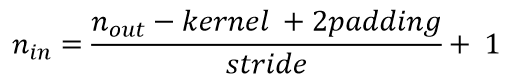
反卷积(转置卷积)详解参考博客:https://blog.csdn.net/LoseInVain/article/details/81098502
跳跃结构(跳跃层、Skip Layer)
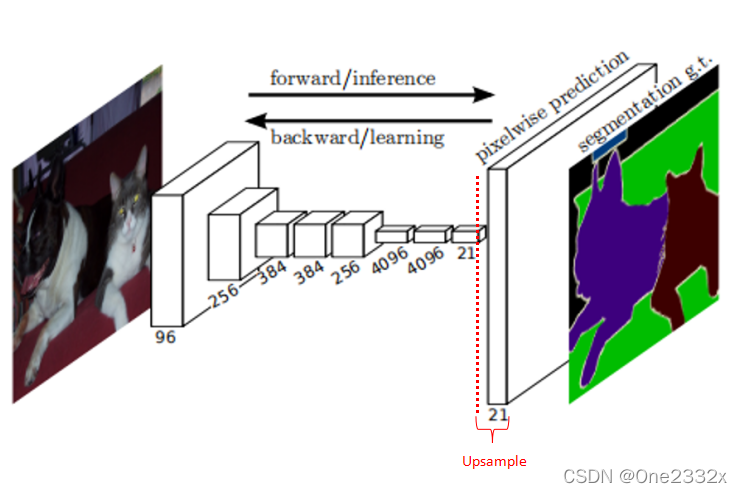
模型前期通过卷积、池化、非线性激活函数等作用输出了特征权重图像,由于最后一层的特征图(也叫热图, heatmap, 指卷积池化的最后特征图)太小,我们会损失很多细节。因此我们需要找到一种方式填补丢失的细节数据然后再反卷积,所以就有了跳跃结构(Skip Layer), 这是特征融合的一种方式。
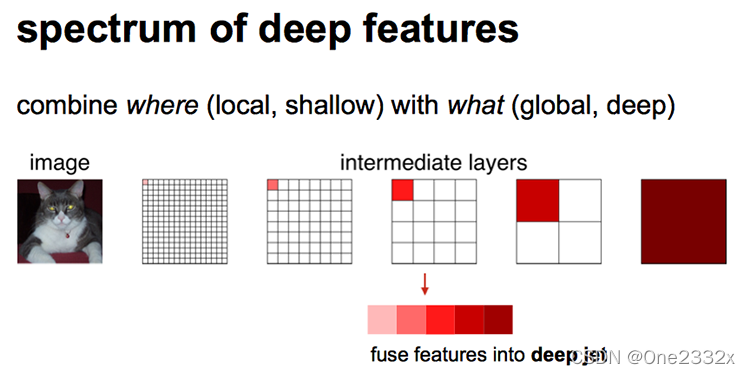
如上图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征。因此在这里向前迭代,把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
具体来说,就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,分为FCN-32s,FCN-16s,FCN-8s三种,如下图所示,黑色实线指向FCN-32s,黑色虚线指向FCN-16s,灰色虚线指向FCN-8s。
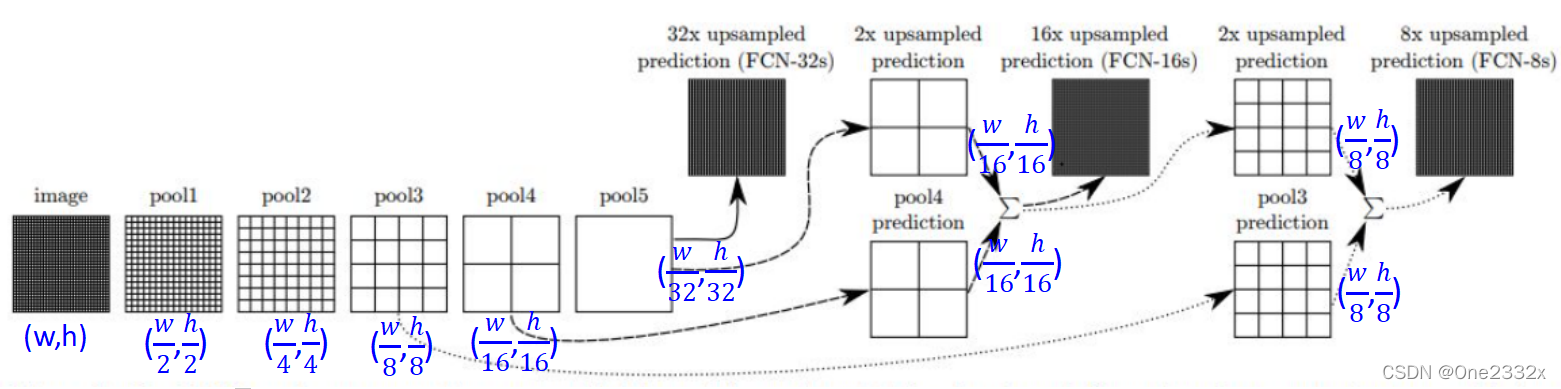
具体过程如下:
- FCN-32s:
(看上图黑色实线)对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,最后,通过32x upsample prediction(注意,这里上采样方法采用的是转置卷积)使其扩大32倍,恢复到原像片大小。 - FCN-16s:
(看上图黑色虚线)前面步骤不变,但不进行最后的32x upsample prediction操作,pool5之后通过2x upsample prediction,使其扩大两倍,变成原图像的1/16,然后与pool4 prediction相结合,最后在进行16x upsample prediction,使其扩大16倍,恢复到原图像大小。 - FCN-8s:
(看上图灰色虚线)前面步骤不变,但不进行最后的16x upsample prediction操作,FCN-16s种结合好的进行2x upsample prediction操作,使其扩大2倍,变成原图像的1/8倍,在与pool3 prediction相结合,最后进行8x upsample prediction,使其扩大8倍,恢复到原图像大小。
FCN-32s、FCN-16s、FCN-8s效果图如下所示,可以看出FCN-8s的分割效果更好,更为准确。

三、参考资料
目标分割(一)FCN讲解
语义分割–全卷积网络FCN详解
全卷积网络FCN详细讲解(超级详细哦)
[论文解读]FCN+与CNN的区别+三大技术+网络结构
全卷积网络FCN与卷积神经网络CNN的区别