官方文档:Flux data scripting language | InfluxDB Enterprise 1.9 Documentation
目录
4.2.2、Pipe-forward operator(管道转发运算符)
4.8.2、group():对InfluxDB中的数据进行分组
4.8.3、sort() & limit():使用Flux对数据进行排序和限制
4.8.8、movingAverage() & timedMovingAverage() :移动平均值
4.8.16、first() & last():查询第1个和最后一个值
Flux 是一种功能性数据脚本语言,设计用于查询、分析和处理时间序列数据。它利用了 InfluxQL 的强大功能和 TICKscript 的功能,并将它们组合成一个统一的语法。Flux v0.65 已准备好生产并包含在 InfluxDB v1.8 中。 Flux 的 InfluxDB v1.8 实现是只读的,不支持将数据写回 InfluxDB。
Flux 是 InfluxQL 和其他类似 SQL 的查询语言的替代品,用于查询和分析数据。 Flux 使用函数式语言模式,使其非常强大、灵活,并且能够克服 InfluxQL 的许多限制。本文概述了使用 Flux 而不是 InfluxQL 可能执行的许多任务,并提供有关 Flux 和 InfluxQL 奇偶校验的信息。可以使用 Flux InfluxQL 和 Flux parity 可以使用 Flux Joins 跨测量的数学 按标签排序 按任何列分组 按日历月和年的窗口 使用多个数据源 DatePart-like 查询 透视直方图 协方差 将布尔值转换为整数 字符串操作和数据整形 使用地理时态数据连接 InfluxQL 从来不支持连接。
1、Flux设计原则
Flux 被设计成可用、可读、灵活、可组合、可测试、可贡献和可共享。它的语法很大程度上受到 2018 年最流行的脚本语言 Javascript 的启发,并采用函数式方法进行数据探索和处理。
以下示例说明了从存储桶(类似于 InfluxQL 数据库)中提取过去 5 分钟的数据,通过 cpu 测量值和 cpu=cpu-total 标签过滤该数据,以 1 分钟间隔对数据进行窗口化,并计算平均值每个窗口的:
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r.cpu == "cpu-total")
|> aggregateWindow(every: 1m, fn: mean)
2、启用Flux
Flux 与 InfluxDB v1.8+ 打包在一起,不需要任何额外的安装,但是默认情况下它是禁用的,需要启用。
通过在 influxdb.conf 的 [http] 部分下将 Flux-enabled 选项设置为 true 来启用 Flux:
influxdb.conf:
# ...
[http]
# ...
flux-enabled = true
# ...当 InfluxDB 启动时,Flux 守护进程也会启动,并且可以使用 Flux 查询数据。
3、执行Flux查询
有多种方法可以使用 InfluxDB Enterprise 和 Chronograf v1.8+ 执行 Flux 查询。
3.1、Chronograf的数据浏览器
Chronograf v1.8+ 在其 Data Explorer 中支持 Flux。 Flux 查询可以在 Chronograf 用户界面中构建、执行和可视化。
3.2、Influx CLI
要使用 InfluxDB Enterprise 1.9+ influx CLI 启动交互式 Flux read-eval-print-loop (REPL),请使用以下标志运行 influx 命令:
-type=flux
-path-prefix=/api/v2/query
如果在您的 InfluxDB 实例上启用了身份验证,请使用 -username 标志来提供您的 InfluxDB 用户名和
-password 标志来提供您的密码。
- 无授权:
influx -type=flux -path-prefix=/api/v2/query
- 启用身份验证:
influx -type=flux \
-path-prefix=/api/v2/query \
-username myuser \
-password PasSw0rd任何 Flux 查询都可以在 REPL 中执行。
3.2.1、通过参数提交Flux查询
Flux 查询也可以使用 influx CLI 的 -type=flux 选项和 -execute 参数作为参数传递给 Flux REPL。随附的字符串作为 Flux 查询执行,结果在终端中输出。
- 无授权
influx -type=flux \
-path-prefix=/api/v2/query \
-execute '<flux query>'
- 启用身份验证
influx -type=flux \
-path-prefix=/api/v2/query \
-username myuser \
-password PasSw0rd \
-execute '<flux query>'
3.2.2、通过STDIN提交Flux查询
Flux 查询通过 STDIN 输入到 influx CLI 中。查询结果在您的终端中输出。
- 无授权
echo '<flux query>' | influx -type=flux -path-prefix=/api/v2/query
- 启用身份验证
echo '<flux query>' | influx -type=flux \
-path-prefix=/api/v2/query \
-username myuser \
-password PasSw0rd3.3、Flux数据库API
Flux 可用于通过 InfluxDB 的 /api/v2/query 端点查询 InfluxDB。查询的数据以带注释的 CSV 格式返回。
在您的请求中,设置以下内容:
Accept header to application/csv
Content-type header to application/vnd.flux
如果在您的 InfluxDB 实例上启用了身份验证,则 授权头为 Token <username>:<password>这允许您以纯文本形式发布 Flux 查询并接收带注释的 CSV 响应。
下面是一个使用 Flux 查询 InfluxDB 的 curl 命令示例:
curl -XPOST localhost:8086/api/v2/query -sS \
-H 'Accept:application/csv' \
-H 'Content-type:application/vnd.flux' \
-d 'from(bucket:"telegraf")
|> range(start:-5m)
|> filter(fn:(r) => r._measurement == "cpu")'
4、开始使用Flux
Flux 是 InfluxData 的新功能数据脚本语言,专为查询、分析和处理数据而设计。这个多部分的入门指南介绍了与 Flux 相关的重要概念。它涵盖了使用 Flux 从 InfluxDB 查询时间序列数据,并介绍了 Flux 语法和函数。
4.1、你需要什么
- InfluxDB v1.8:Flux v0.65 内置于 InfluxDB v1.8 中,可用于查询存储在 InfluxDB 中的数据。
- Chronograf v1.8+:不是必需的,但强烈推荐。 Chronograf v1.8 的 Data Explorer 提供了用于编写 Flux 脚本和可视化结果的用户界面 (UI)。 Chronograf v1.8+ 中的仪表板也支持 Flux 查询。
4.2、关键概念
Flux 引入了重要的新概念,您在开始时应该理解。
4.2.1、Buckets(桶)
Flux 引入了“buckets”,这是 InfluxDB 的一种新的数据存储概念。存储桶是具有保留策略的存储数据的命名位置。它类似于 InfluxDB v1.x “数据库”,但它是数据库和保留策略的组合。使用多个保留策略时,每个保留策略都被视为其自己的存储桶。
Flux 的 from() 函数,它定义了一个 InfluxDB 数据源,需要一个桶参数。将 Flux 与 InfluxDB v1.x 一起使用时,请使用以下存储桶命名约定,它将数据库名称和保留策略组合成一个存储桶名称:
InfluxDB v1.x存储桶命名约定:
// Pattern
from(bucket:"<database>/<retention-policy>")
// Example
from(bucket:"telegraf/autogen")
4.2.2、Pipe-forward operator(管道转发运算符)
Flux 广泛使用管道转发运算符 (|>) 将操作链接在一起。在每个函数或操作之后,Flux 返回一个包含数据的表或表集合。管道转发操作符将这些表通过管道传送到下一个函数或操作中,在这些函数或操作中进一步处理或操作它们。
4.2.3、Tables(表)
Flux 构造表中的所有数据。当数据从数据源流式传输时,Flux 将其格式化为带注释的逗号分隔值 (CSV),表示表格。然后函数操作或处理它们并输出新表。这使得将函数链接在一起以构建复杂的查询变得容易。
Group keys(组键):每个表都有一个描述表内容的组键。它是一个列列表,表中的每一行都将具有相同的值。每行中具有唯一值的列不属于组键。随着函数处理和转换数据,每个函数都会修改输出表的组键。了解函数如何修改表和组键是正确调整数据以获得所需输出的关键。
- 实例组键:
[_start, _stop, _field, _measurement, host]
请注意,_time 和 _value 被排除在示例组键之外,因为它们对于每一行都是唯一的。
4.3、使用Flux的工具
您有多种选择来编写和运行 Flux 查询,但在您开始时,我们建议使用以下方法:Chronograf的数据浏览器。Chronograf 的数据资源管理器可以轻松编写您的第一个 Flux 脚本并可视化结果。要使用 Chronograf 的 Flux UI,请打开数据资源管理器并在图表占位符上方的源下拉列表右侧,选择 Flux 作为源类型。这将提供模式、脚本和函数窗格。 Schema 窗格允许您浏览数据。脚本窗格是您编写 Flux 脚本的地方。 Functions 窗格提供了 Flux 查询中可用的函数列表。
4.4、使用Flux查询InfluxDB
本指南介绍了使用 Flux 从 InfluxDB 查询数据的基础知识。如果您还没有,请确保安装 InfluxDB v1.8+,启用 Flux,并选择用于编写 Flux 查询的工具。可以使用执行Flux查询中描述的任何方法执行以下查询。请务必为每种方法提供您的 InfluxDB Enterprise 授权凭证。
每个 Flux 查询都需要以下内容:① 数据源;② 一个时间范围;③ 数据过滤器。
4.4.1、定义你的数据源
Flux 的 from() 函数定义了一个 InfluxDB 数据源。它需要一个桶参数。对于此示例,使用 telegraf/autogen,这是 TICK 堆栈提供的默认数据库和保留策略的组合。
4.4.2、指定时间范围
Flux 在查询时间序列数据时需要时间范围。 “无界”查询非常耗费资源,作为一种保护措施,Flux 不会查询没有指定范围的数据库。使用管道转发运算符 (|>) 将数据从数据源通过管道传输到 range() 函数,该函数指定查询的时间范围。它接受两个属性:开始和停止。范围可以是使用负持续时间的相对范围或使用时间戳的绝对范围。相对范围是相对于“现在”的。
- 示例:相对时间范围
// Relative time range with start only. Stop defaults to now.
from(bucket:"telegraf/autogen")
|> range(start: -1h)
// Relative time range with start and stop
from(bucket:"telegraf/autogen")
|> range(start: -1h, stop: -10m)
- 示例:绝对时间范围
from(bucket:"telegraf/autogen")
|> range(start: 2018-11-05T23:30:00Z, stop: 2018-11-06T00:00:00Z)
对于本指南,使用相对时间范围 -15m 将查询结果限制为最近 15 分钟的数据:
from(bucket:"telegraf/autogen")
|> range(start: -15m)
4.4.3、过滤您的数据
将您的范围数据传递给 filter() 函数,以根据数据属性或列缩小结果范围。 filter() 函数有一个参数 fn,它需要一个匿名函数,该函数具有基于列或属性过滤数据的逻辑。Flux 的匿名函数语法与 Javascript 非常相似。记录或行作为记录 (r) 传递给 filter() 函数。匿名函数获取记录并评估它以查看它是否与定义的过滤器匹配。使用 AND 关系运算符链接多个过滤器。
// Pattern
(r) => (r.recordProperty comparisonOperator comparisonExpression)
// Example with single filter
(r) => (r._measurement == "cpu")
// Example with multiple filters
(r) => (r._measurement == "cpu") and (r._field != "usage_system" )
对于此示例,按 cpu 测量值、usage_system 字段和 cpu-total 标记值进行过滤:
from(bucket: "telegraf/autogen")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
4.4.4、输出您的查询数据
使用 Flux 的 yield() 函数将过滤后的表作为查询结果输出。
from(bucket: "telegraf/autogen")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> yield()
Chronograf 和 influx CLI 在每个脚本的末尾自动假设一个 yield() 函数,以便输出和可视化数据。最佳实践是包含一个 yield() 函数,但这并不总是必要的。
4.5、使用Flux转换数据
从 InfluxDB 查询数据时,您通常需要以某种方式转换该数据。常见的示例是将数据聚合为平均值、对数据进行下采样等。本指南演示了如何使用 Flux 函数来转换您的数据。它逐步创建了一个 Flux 脚本,该脚本将数据划分为时间窗口,平均每个窗口中的 _values,并将平均值作为新表输出。了解数据的“形状”如何通过这些操作发生变化非常重要。
4.5.1、查询数据
使用之前 InfluxDB 指南中的 Query data 中内置的查询,但更新范围以从最后一小时提取数据:
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
4.5.2、Flux函数
Flux 提供了许多执行特定操作、转换和任务的函数。您还可以在 Flux 查询中创建自定义函数。 Flux 标准库文档中详细介绍了函数。转换从 InfluxDB 查询的数据时使用的一种常见函数类型是聚合函数。聚合函数采用表中的一组 _values,聚合它们,并将它们转换为新值。
此示例使用 mean() 函数对时间窗口内的值进行平均。
4.5.3、窗口化您的数据
Flux 的 window() 函数根据时间值对记录进行分区。使用 every 参数定义每个窗口的持续时间。every 支持所有有效的持续时间单位,包括日历月 (1mo) 和年 (1y)。
对于此示例,以五分钟为间隔 (5m) 的窗口数据。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> window(every: 5m)
随着数据被收集到时间窗口中,每个窗口都作为自己的表格输出。可视化时,每个表都分配有唯一的颜色。
4.5.4、聚合窗口数据
Flux 聚合函数获取每个表中的 _values 并以某种方式聚合它们。使用 mean() 函数对每个表的 _values 进行平均。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> window(every: 5m)
|> mean()
由于每个窗口中的行都被聚合,它们的输出表只包含一个具有聚合值的行。窗口化表格仍然是独立的,并且在可视化时将显示为单个未连接的点。
4.5.5、将时间添加到您的聚合中
当值被聚合时,结果表没有 _time 列,因为用于聚合的记录都有不同的时间戳。聚合函数不会推断应该将什么时间用于聚合值。因此 _time 列被删除。在下一个操作中需要一个 _time 列。要添加一个,请使用 duplicate() 函数将 _stop 列复制为每个窗口表的 _time 列。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
4.5.6、展开聚合表
使用带有 every: inf 参数的 window() 函数将所有点聚集到一个单一的无限窗口中。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
一旦取消分组并组合成一个表,聚合数据点将在您的可视化中显示为连接。
4.5.7、辅助函数
这似乎只是为了构建一个聚合数据的查询而进行的大量编码,但是通过该过程有助于了解数据在通过每个函数时如何改变“形状”。Flux 提供(并允许您创建)抽象许多这些步骤的“帮助”函数。本指南中执行的相同操作可以使用 aggregateWindow() 函数完成。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
|> aggregateWindow(every: 5m, fn: mean)
4.6、Flux语法基础
Flux的核心是一种专门为处理数据而设计的脚本语言。本指南介绍了一些简单的表达式以及如何在 Flux 中处理它们。
4.6.1、简单的表达式
> 1 + 1
2
4.6.2、变量
> s = "this is a string"
> i = 1 // an integer
> f = 2.0 // a floating point number
键入变量的名称以打印其值:
> s
this is a string
> i
1
> f
2
4.6.3、记录
Flux 还支持记录。记录中的每个值都可以是不同的数据类型。
> o = {name:"Jim", age: 42, "favorite color": "red"}
使用点表示法访问记录的属性:
> o.name
Jim
> o.age
42
或括号表示法:
> o["name"]
Jim
> o["age"]
42
> o["favorite color"]
red
使用括号表示法来引用属性键中具有特殊或空白字符的记录属性。
4.6.4、列表
Flux 支持列表。列表值必须是同一类型。
> n = 4
> l = [1,2,3,n]
> l
[1, 2, 3, 4]
4.6.5、函数
Flux 使用函数来完成大部分繁重的工作。下面是一个对数字 n 求平方的简单函数。
> square = (n) => n * n
> square(n:3)
9
Flux 不支持位置参数或参数。调用函数时必须始终命名参数。
4.6.6、管道转发运算符
Flux 广泛使用管道转发运算符 (|>) 将操作链接在一起。在每个函数或操作之后,Flux 返回一个包含数据的表或表集合。 pipe-forward 操作符将这些表通过管道传送到下一个函数中,在该函数中进一步处理或操作它们。
data |> someFunction() |> anotherFunction()
4.7、基本语法的实际应用
如果您已经阅读过其他入门指南,这可能看起来很熟悉。 Flux 的语法受到 Javascript 和其他函数式脚本语言的启发。当您开始将这些基本原则应用于实际用例(例如创建数据流变量、自定义函数等)时,Flux 的强大功能及其查询和处理数据的能力将变得显而易见。
下面的示例提供了每个输入命令的多行和单行版本。 Flux 中的回车不是必需的,但有助于提高可读性。单行和多行命令都可以复制并粘贴到以 Flux 模式运行的 influx CLI 中。
4.7.1、多行输入
定义数据流变量:Flux 中变量赋值的一个常见用例是为一个或多个输入数据流创建变量。
timeRange = -1h
cpuUsageUser = from(bucket: "telegraf/autogen")
|> range(start: timeRange)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_user" and r.cpu == "cpu-total")
memUsagePercent = from(bucket: "telegraf/autogen")
|> range(start: timeRange)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
这些变量可以在其他函数中使用,例如 join(),同时保持语法最小和灵活。
定义自定义函数:创建一个函数,该函数返回输入流中具有最高 _value 的 N 行。为此,请将输入流(表)和要返回的结果数 (n) 传递给自定义函数。然后使用 Flux 的 sort() 和 limit() 函数在数据集中查找前 n 个结果。
topN = (tables=<-, n) => tables
|> sort(desc: true)
|> limit(n: n)
使用这个新的自定义函数 topN 和上面定义的 cpuUsageUser 数据流变量,找到前五个数据点并产生结果。
cpuUsageUser
|> topN(n: 5)
|> yield()
此查询将返回过去一小时内用户 CPU 使用率最高的五个数据点。
4.7.2、单行输入
定义数据流变量:Flux 中变量赋值的一个常见用例是为多个过滤的输入数据流创建变量。
timeRange = -1h
cpuUsageUser = from(bucket: "telegraf/autogen")
|> range(start: timeRange)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_user" and r.cpu == "cpu-total")
memUsagePercent = from(bucket: "telegraf/autogen")
|> range(start: timeRange)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
这些变量可以在其他函数中使用,例如 join(),同时保持语法最小和灵活。
定义自定义函数:让我们创建一个函数,它返回输入数据流中具有最高 _value 的 N 行。为此,请将输入流(表)和要返回的结果数 (n) 传递给自定义函数。然后使用 Flux 的 sort() 和 limit() 函数在数据集中查找前 n 个结果。
topN = (tables=<-, n) => tables |> sort(desc: true) |> limit(n: n)
使用上面定义的 cpuUsageUser 数据流变量,使用自定义 topN 函数找到前五个数据点并产生结果。此查询将返回过去一小时内用户 CPU 使用率最高的五个数据点。
4.8、使用Flux查询数据
以下指南中提供的许多示例都使用数据变量,它表示按度量和字段过滤数据的基本查询。数据定义为:
data = from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement" and r._field == "example-field")
4.8.1、查询字段和标签
使用 filter() 函数根据字段、标签或任何其他列值查询数据。 filter() 执行类似于 InfluxQL 和其他类似 SQL 的查询语言中的 SELECT 语句和 WHERE 子句的操作。
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "example-measurement" and
r._field == "example-field" and
r.tag == "example-tag"
)
filter()函数:filter() 有一个 fn 参数,它需要一个判定函数,一个由一个或多个判定表达式组成的匿名函数。判定函数评估每个输入行。评估结果为 true 的行包含在输出数据中。评估结果为 false 的行将从输出数据中排除。
// ...
|> filter(fn: (r) => r._measurement == "example-measurement" )
fn 判定函数需要一个 r 参数,它将每一行表示为 filter() 迭代输入数据。行记录中的键值对表示列及其值。使用点表示法或方括号表示法来引用判定函数中的特定列值。使用逻辑运算符将多个判定表达式链接在一起。
// Row record
r = {foo: "bar", baz: "quz"}
// Example predicate function
(r) => r.foo == "bar" and r["baz"] == "quz"
// Evaluation results
(r) => true and true
按字段和标签过滤:from()、range() 和 filter() 的组合代表了最基本的 Flux 查询:
- 使用 from() 定义您的存储桶。
- 使用 range() 按时间限制查询结果。
- 使用 filter() 来确定要输出的数据行。
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement" and r.tag == "example-tag")
|> filter(fn: (r) => r._field == "example-field")
4.8.2、group():对InfluxDB中的数据进行分组
使用 Flux,您可以按查询数据集中的任何列对数据进行分组。 “分组”将数据分区到表中,其中每一行为指定的列共享一个公共值。本指南介绍了 Flux 中的数据分组,并提供了数据在流程中如何形成的示例。
group keys(组键):每个表都有一个组键——一个列列表,表中的每一行都具有相同的值。
示例组键:
[_start, _stop, _field, _measurement, host]
Flux 中对数据进行分组,本质上就是定义输出表的组键。了解修改组键如何塑造输出数据是成功将数据分组和转换为所需输出的关键。
group()函数:Flux 的 group() 函数定义了输出表的组键。使用 group() 函数对特定列中具有共同值的数据进行分组。group()函数具有以下参数:
- columns:在分组操作中包含或排除的列列表(取决于模式)。
- mode:用于定义组和结果组键的方法。可能的值包括 by 和 except。
data
|> group(columns: ["cpu", "host"], mode: "by")
产生的组键:
[cpu, host]
输入:
| _time | host | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | host1 | 1.0 |
| 2020-01-01T00:01:00Z | host2 | 2.0 |
| 2020-01-01T00:02:00Z | host1 | 1.0 |
| 2020-01-01T00:02:00Z | host2 | 3.0 |
输出:
| _time | host | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | host1 | 1.0 |
| 2020-01-01T00:02:00Z | host1 | 1.0 |
| _time | host | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | host2 | 2.0 |
| 2020-01-01T00:02:00Z | host2 | 3.0 |
为了说明分组的工作原理,定义一个从 db/rp 存储桶查询系统 CPU 使用率的 dataSet 变量。过滤 cpu 标记,使其仅返回每个编号的 CPU 内核的结果。
系统操作为所有编号的 CPU 内核使用的 CPU。它使用正则表达式来过滤仅编号的核心。
dataSet = from(bucket: "db/rp")
|> range(start: -2m)
|> filter(fn: (r) => r._field == "usage_system" and r.cpu =~ /cpu[0-9*]/)
|> drop(columns: ["host"])
此示例从返回的数据中删除主机列,因为仅跟踪单个主机的 CPU 数据,并且它简化了输出表。如果监控多个主机,请不要删除主机列。请注意,每个表都会输出组键:表:键:<group-key>。
Table: keys: [_start, _stop, _field, _measurement, cpu]
_start:time _stop:time _field:string _measurement:string cpu:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:00.000000000Z 7.892107892107892
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:10.000000000Z 7.2
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:20.000000000Z 7.4
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:30.000000000Z 5.5
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:40.000000000Z 7.4
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:34:50.000000000Z 7.5
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:00.000000000Z 10.3
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:10.000000000Z 9.2
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:20.000000000Z 8.4
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:30.000000000Z 8.5
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:40.000000000Z 8.6
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:35:50.000000000Z 10.2
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu0 2018-11-05T21:36:00.000000000Z 10.6
Table: keys: [_start, _stop, _field, _measurement, cpu]
_start:time _stop:time _field:string _measurement:string cpu:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:00.000000000Z 0.7992007992007992
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:10.000000000Z 0.7
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:20.000000000Z 0.7
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:30.000000000Z 0.4
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:40.000000000Z 0.7
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:34:50.000000000Z 0.7
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:00.000000000Z 1.4
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:10.000000000Z 1.2
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:20.000000000Z 0.8
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:30.000000000Z 0.8991008991008991
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:40.000000000Z 0.8008008008008008
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:35:50.000000000Z 0.999000999000999
2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z usage_system cpu cpu1 2018-11-05T21:36:00.000000000Z 1.1022044088176353按 cpu 列对数据集流进行分组:
dataSet
|> group(columns: ["cpu"])
这实际上不会改变数据的结构,因为它已经在组键中有 cpu,因此按 cpu 分组。但是,请注意它确实更改了组键:
Table: keys: [cpu]
cpu:string _stop:time _time:time _value:float _field:string _measurement:string _start:time
---------------------- ------------------------------ ------------------------------ ---------------------------- ---------------------- ---------------------- ------------------------------
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:00.000000000Z 7.892107892107892 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:10.000000000Z 7.2 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:20.000000000Z 7.4 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:30.000000000Z 5.5 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:40.000000000Z 7.4 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:50.000000000Z 7.5 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:00.000000000Z 10.3 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:10.000000000Z 9.2 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:20.000000000Z 8.4 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:30.000000000Z 8.5 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:40.000000000Z 8.6 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:50.000000000Z 10.2 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu0 2018-11-05T21:36:00.000000000Z 2018-11-05T21:36:00.000000000Z 10.6 usage_system cpu 2018-11-05T21:34:00.000000000Z
Table: keys: [cpu]
cpu:string _stop:time _time:time _value:float _field:string _measurement:string _start:time
---------------------- ------------------------------ ------------------------------ ---------------------------- ---------------------- ---------------------- ------------------------------
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:00.000000000Z 0.7992007992007992 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:10.000000000Z 0.7 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:20.000000000Z 0.7 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:30.000000000Z 0.4 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:40.000000000Z 0.7 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:34:50.000000000Z 0.7 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:00.000000000Z 1.4 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:10.000000000Z 1.2 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:20.000000000Z 0.8 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:30.000000000Z 0.8991008991008991 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:40.000000000Z 0.8008008008008008 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:35:50.000000000Z 0.999000999000999 usage_system cpu 2018-11-05T21:34:00.000000000Z
cpu1 2018-11-05T21:36:00.000000000Z 2018-11-05T21:36:00.000000000Z 1.1022044088176353 usage_system cpu 2018-11-05T21:34:00.000000000Z可视化保持不变。
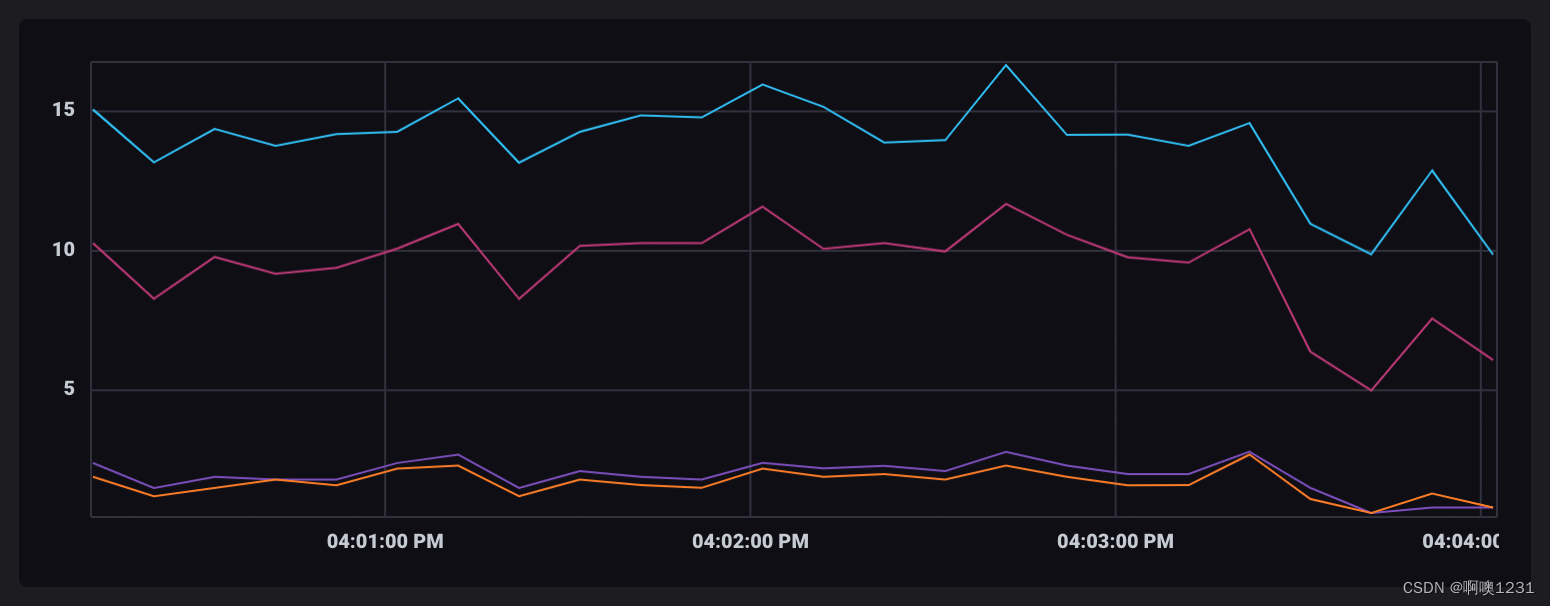
按 _time 列对数据进行分组很好地说明了分组如何更改数据的结构:
dataSet
|> group(columns: ["_time"])
当按 _time 分组时,共享一个公共 _time 值的所有记录将被分组到单独的表中。所以每个输出表代表一个时间点。
Table: keys: [_time]
_time:time _start:time _stop:time _value:float _field:string _measurement:string cpu:string
------------------------------ ------------------------------ ------------------------------ ---------------------------- ---------------------- ---------------------- ----------------------
2018-11-05T21:34:00.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 7.892107892107892 usage_system cpu cpu0
2018-11-05T21:34:00.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 0.7992007992007992 usage_system cpu cpu1
2018-11-05T21:34:00.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 4.1 usage_system cpu cpu2
2018-11-05T21:34:00.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 0.5005005005005005 usage_system cpu cpu3
Table: keys: [_time]
_time:time _start:time _stop:time _value:float _field:string _measurement:string cpu:string
------------------------------ ------------------------------ ------------------------------ ---------------------------- ---------------------- ---------------------- ----------------------
2018-11-05T21:34:10.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 7.2 usage_system cpu cpu0
2018-11-05T21:34:10.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 0.7 usage_system cpu cpu1
2018-11-05T21:34:10.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 3.6 usage_system cpu cpu2
2018-11-05T21:34:10.000000000Z 2018-11-05T21:34:00.000000000Z 2018-11-05T21:36:00.000000000Z 0.5 usage_system cpu cpu3因为每个时间戳都被构造为一个单独的表,所以在可视化时,共享相同时间戳的所有点看起来都是连接的。

通过一些进一步的处理,您可以计算每个时间点所有 CPU 的平均 CPU 使用率,并将它们分组到一个表中,但我们不会在此示例中涉及。如果您有兴趣自己运行和可视化它,查询将如下所示:
dataSet
|> group(columns: ["_time"])
|> mean()
|> group(columns: ["_value", "_time"], mode: "except")
按 cpu 和 _time 列分组:
dataSet
|> group(columns: ["cpu", "_time"])
这会为每个唯一的 cpu 和 _time 组合输出一个表:
Table: keys: [_time, cpu]
_time:time cpu:string _stop:time _value:float _field:string _measurement:string _start:time
------------------------------ ---------------------- ------------------------------ ---------------------------- ---------------------- ---------------------- ------------------------------
2018-11-05T21:34:00.000000000Z cpu0 2018-11-05T21:36:00.000000000Z 7.892107892107892 usage_system cpu 2018-11-05T21:34:00.000000000Z
Table: keys: [_time, cpu]
_time:time cpu:string _stop:time _value:float _field:string _measurement:string _start:time
------------------------------ ---------------------- ------------------------------ ---------------------------- ---------------------- ---------------------- ------------------------------
2018-11-05T21:34:00.000000000Z cpu1 2018-11-05T21:36:00.000000000Z 0.7992007992007992 usage_system cpu 2018-11-05T21:34:00.000000000Z可视化时,表格显示为单独的、未连接的点。
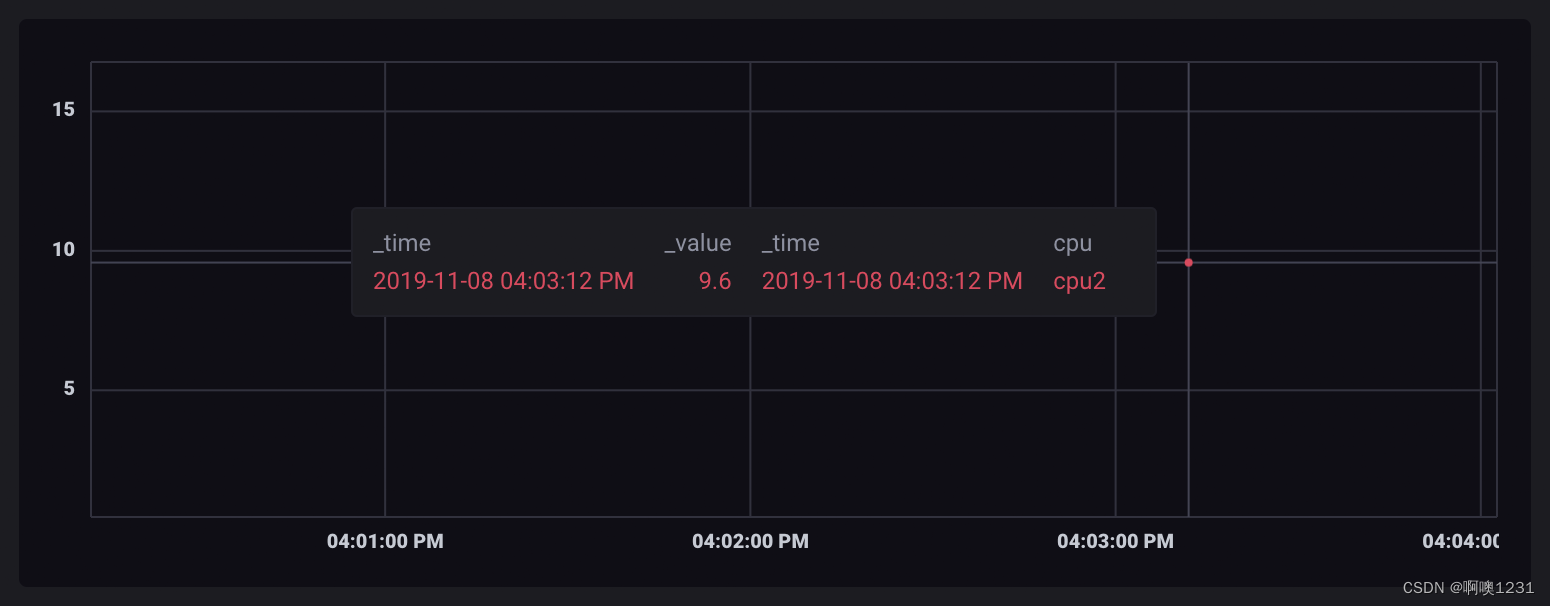
按 cpu 和 _time 分组很好地说明了分组的工作原理。
4.8.3、sort() & limit():使用Flux对数据进行排序和限制
使用 sort() 函数按特定列对每个表中的记录进行排序,使用 limit() 函数将输出表中的记录数限制为固定数 n。
data
|> sort(columns: ["host", "_value"])
|> limit(n: 4)
输入:
| _time | host | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | A | 1.0 |
| 2020-01-01T00:02:00Z | B | 1.2 |
| 2020-01-01T00:03:00Z | A | 1.8 |
| 2020-01-01T00:04:00Z | B | 0.9 |
| 2020-01-01T00:05:00Z | B | 1.4 |
| 2020-01-01T00:06:00Z | B | 2.0 |
输出:
| _time | host | _value |
|---|---|---|
| 2020-01-01T00:03:00Z | A | 1.8 |
| 2020-01-01T00:01:00Z | A | 1.0 |
| 2020-01-01T00:06:00Z | B | 2.0 |
| 2020-01-01T00:05:00Z | B | 1.4 |
以下示例首先按区域排序系统正常运行时间region,然后是主机host,然后是值_value。
from(bucket: "db/rp")
|> range(start: -12h)
|> filter(fn: (r) => r._measurement == "system" and r._field == "uptime")
|> sort(columns: ["region", "host", "_value"])
limit() 函数将输出表中的记录数限制为固定数 n。以下示例最多显示过去一小时的 10 条记录。
from(bucket:"db/rp")
|> range(start:-1h)
|> limit(n:10)
您可以同时使用 sort() 和 limit() 来显示前 N 条记录。下面的示例返回首先按区域排序的 10 个最高系统正常运行时间值,然后是主机,然后是值。
from(bucket: "db/rp")
|> range(start: -12h)
|> filter(fn: (r) => r._measurement == "system" and r._field == "uptime")
|> sort(columns: ["region", "host", "_value"])
|> limit(n: 10)
您现在已经创建了一个对数据进行排序和限制的 Flux 查询。 Flux 还提供了 top() 和 bottom() 函数来同时执行这两个函数。
4.8.4、Window & aggregate
使用时间序列数据执行的常见操作是将数据分组到时间窗口或“窗口化”数据,然后将窗口化值聚合成新值。本指南介绍了使用 Flux 对数据进行窗口化和聚合,并演示了数据在该过程中是如何形成的。
以下示例深入介绍了窗口化和聚合数据所需的步骤。 aggregateWindow() 函数为您执行这些操作,但了解数据在此过程中的形成方式有助于成功创建所需的输出。
data
|> aggregateWindow(every: 20m, fn: mean)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z |
250 |
| 2020-01-01T00:04:00Z |
160 |
| 2020-01-01T00:12:00Z |
150 |
| 2020-01-01T00:19:00Z |
220 |
| 2020-01-01T00:32:00Z |
200 |
| 2020-01-01T00:51:00Z |
290 |
| 2020-01-01T01:00:00Z |
340 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:20:00Z | 195 |
| 2020-01-01T00:40:00Z | 200 |
| 2020-01-01T01:00:00Z | 290 |
| 2020-01-01T01:20:00Z | 340 |
为本指南的目的,定义一个代表您的基础数据集的变量。以下示例查询主机的内存使用情况。
dataSet = from(bucket: "db/rp")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> drop(columns: ["host"])
此示例从返回的数据中删除主机列,因为仅跟踪单个主机的内存数据并且它简化了输出表。删除主机列是可选的,如果监视多个主机上的内存,则不建议这样做。dataSet 现在可用于表示您的基础数据,类似于以下内容:
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199使用 window() 函数根据时间范围对数据进行分组。与 window() 一起传递的最常见的参数是 every ,它定义了窗口之间的持续时间。every 参数支持所有有效的持续时间单位,包括日历月 (1mo) 和年 (1y)。其他参数可用,但对于此示例,将基础数据集窗口化为一分钟窗口。
dataSet
|> window(every: 1m)
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:40.000000000Z 68.65062713623047
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:50.000000000Z 67.20139980316162在 InfluxDB UI 中可视化时,每个窗口表都以不同的颜色显示。

聚合函数获取表中所有行的值并使用它们来执行聚合操作,结果在单行表中作为新值输出。由于窗口化数据被拆分为单独的表,聚合操作分别针对每个表运行并输出仅包含聚合值的新表。
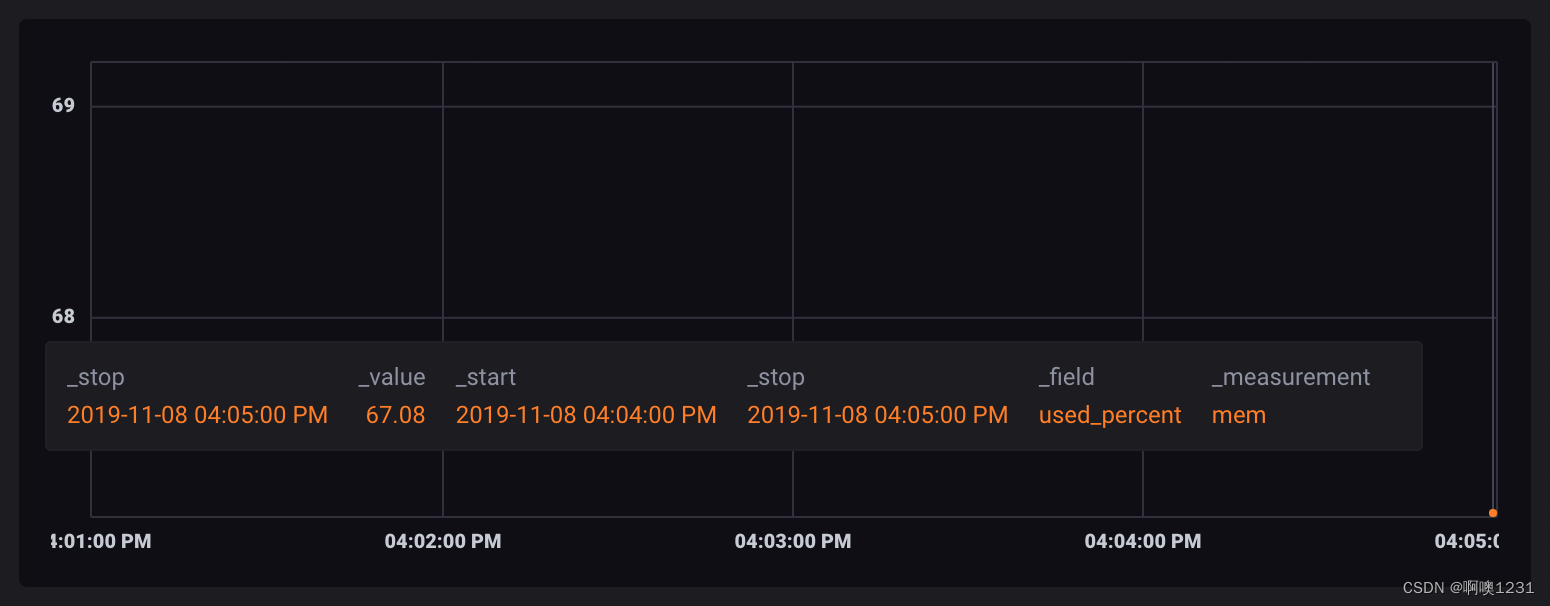
对于此示例,使用 mean() 函数输出每个窗口的平均值:
dataSet
|> window(every: 1m)
|> mean()
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 65.50651391347249
因为每个数据点都包含在自己的表中,所以在可视化时,它们会显示为单个未连接的点。
请注意 _time 列不在聚合输出表中。因为每个表中的记录都聚合在一起,它们的时间戳不再适用,并且该列从组键和表中删除。另请注意 _start 和 _stop 列仍然存在。这些代表时间窗口的下限和上限。许多 Flux 函数依赖于 _time 列。要在聚合函数之后进一步处理您的数据,您需要重新添加 _time。使用 duplicate() 函数将 _start 或 _stop 列复制为新的 _time 列。
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
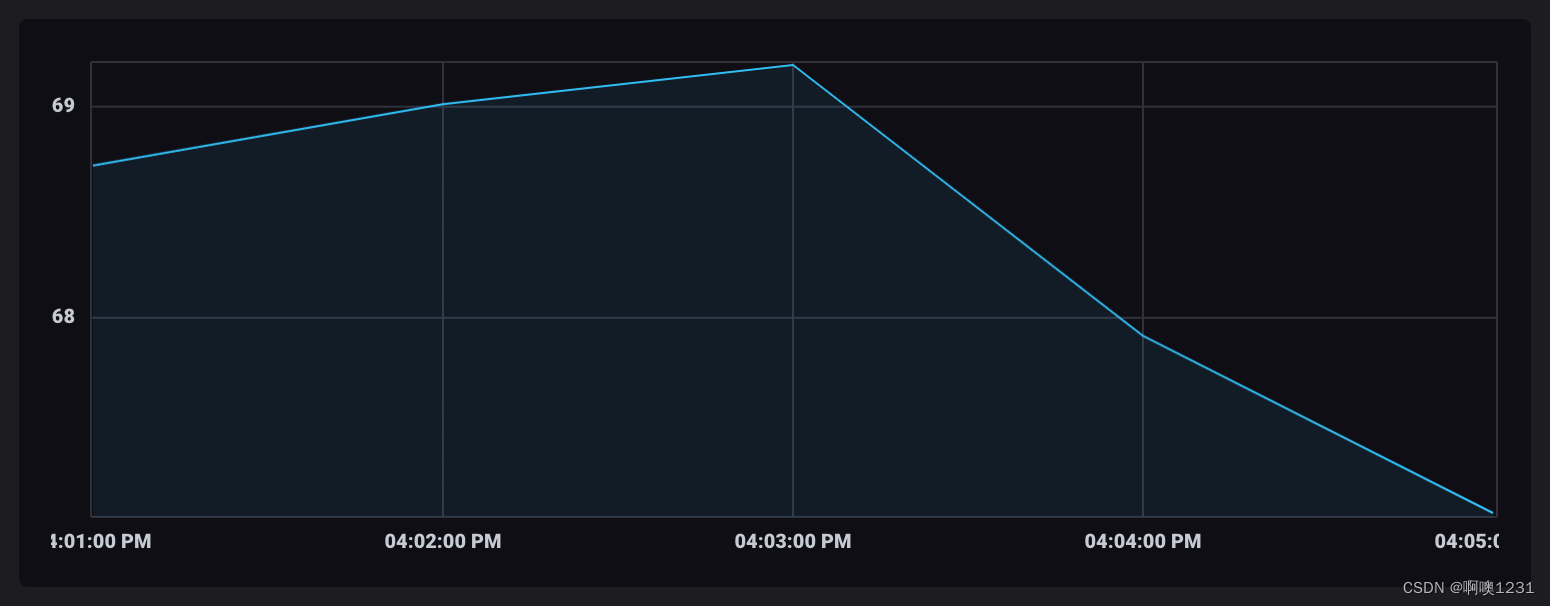
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249将汇总值保存在单独的表中通常不是您想要的数据格式。使用 window() 函数将数据“展开”到单个无限 (inf) 窗口中。
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
窗口化需要一个 _time 列,这就是为什么需要在聚合后重新创建 _time 列的原因。
未加窗的输出列表:
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 65.30719598134358
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.39330975214641
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49386278788249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229通过单个表中的聚合值,可视化中的数据点被连接起来。
您现在已经创建了一个窗口和聚合数据的 Flux 查询。本指南中概述的数据转换过程应用于所有聚合操作。Flux 还提供了 aggregateWindow() 函数,它为您执行所有这些单独的函数。以下 Flux 查询将返回相同的结果:
dataSet
|> aggregateWindow(every: 1m, fn: mean)
4.8.5、用数学运算转换数据
Flux 支持数据转换中的数学表达式。本文介绍如何使用 Flux 算术运算符“映射”数据并使用数学运算转换值。
基本数学运算:Flux 数学运算中的操作数必须是相同的数据类型。例如,整数不能用于浮点运算。否则,您将收到类似于以下内容的错误:
Error: type error: float != int要将操作数转换为相同类型,请使用类型转换函数或手动格式化操作数。操作数数据类型确定输出数据类型。例如:
100 // Parsed as an integer
100.0 // Parsed as a float
// Example evaluations
> 20 / 8
2
> 20.0 / 8.0
2.5
使用 map() 函数重新映射列值并应用数学运算。
data
|> map(fn: (r) => ({ r with _value: r._value * r._value }))
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 2 |
| 2020-01-01T00:02:00Z | 4 |
| 2020-01-01T00:03:00Z | 3 |
| 2020-01-01T00:04:00Z | 5 |
输出:
Flux 允许您创建使用数学运算的自定义函数。查看以下示例。
- 自定义乘法函数:
multiply = (x, y) => x * y
multiply(x: 10, y: 12)
// Returns 120
- 自定义百分比函数
percent = (sample, total) => (sample / total) * 100.0
percent(sample: 20.0, total: 80.0)
// Returns 25.0要转换输入流中的多个值,您的函数需要:
- 处理管道转发数据。
- 计算所需的每个操作数都存在于每一行中(参见下面的 Pivot vs join)。
- 使用 map() 函数遍历每一行。
下面的示例 multiplyByX() 函数包括:
- 表示输入数据流 (<-) 的表参数。
- 一个 x 参数,它是 _value 列中的值相乘的数字。
- 遍历输入流中每一行的 map() 函数。它使用 with 运算符来保留每行中的现有列。它还将 _value 列乘以 x。
multiplyByX = (x, tables=<-) => tables
|> map(fn: (r) => ({r with _value: r._value * x}))
data
|> multiplyByX(x: 10)
例:将Byte转换为GB。要将活动内存从字节转换为千兆字节 (GB),请将内存测量中的活动字段除以 1,073,741,824。map() 函数遍历管道转发数据中的每一行,并通过将原始 _value 除以 1073741824 来定义新的 _value。
from(bucket: "db/rp")
|> range(start: -10m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "active")
|> map(fn: (r) => ({r with _value: r._value / 1073741824}))
您可以将相同的计算转换为函数:
bytesToGB = (tables=<-) => tables
|> map(fn: (r) => ({r with _value: r._value / 1073741824}))
data
|> bytesToGB()
因为原始度量(字节)是整数,所以操作的输出是整数并且不包括部分 GB。要计算部分 GB,请使用 float() 函数将 _value 列及其值转换为浮点数,并将除法运算中的分母格式化为浮点数。
bytesToGB = (tables=<-) => tables
|> map(fn: (r) => ({r with _value: float(v: r._value) / 1073741824.0}))
要计算百分比,请使用简单除法,然后将结果乘以 100。
> 1.0 / 4.0 * 100.0
25.0
pivot() & join():要在 Flux 中查询和使用数学运算中的值,操作数值必须存在于单行中。 pivot() 和 join() 都会这样做,但两者之间有重要区别:
- pivot性能更高:pivot() 读取和操作单个数据流。 join() 需要两个数据流,读取和组合两个数据流的开销可能很大,尤其是对于较大的数据集。
- 对多个数据源使用join():查询来自不同存储桶或数据源的数据时使用 join()。
将字段透视到列中以进行数学运算:
data
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({r with _value: (r.field1 + r.field2) / r.field3 * 100.0}))
加入多个数据源进行数学运算:
import "sql"
import "influxdata/influxdb/secrets"
pgUser = secrets.get(key: "POSTGRES_USER")
pgPass = secrets.get(key: "POSTGRES_PASSWORD")
pgHost = secrets.get(key: "POSTGRES_HOST")
t1 = sql.from(
driverName: "postgres",
dataSourceName: "postgresql://${pgUser}:${pgPass}@${pgHost}",
query: "SELECT id, name, available FROM exampleTable",
)
t2 = from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement" and r._field == "example-field")
join(tables: {t1: t1, t2: t2}, on: ["id"])
|> map(fn: (r) => ({r with _value: r._value_t2 / r.available_t1 * 100.0}))
4.8.6、计算百分比
从查询数据计算百分比是时间序列数据的常见用例。要计算Flux中的百分比,操作数必须在每一行中。使用 map() 重新映射行中的值并计算百分比。
计算百分比:
- 使用 from()、range() 和 filter() 来查询操作数。
- 使用 pivot() 或 join() 将操作数值对齐到行中。
- 使用 map() 将分子操作数值除以分母操作数值并乘以 100。
以下示例使用 pivot() 将操作数对齐到行中,因为 pivot() 在大多数情况下都有效,并且比 join() 性能更高。
data
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(
fn: (r) => ({
_time: r._time,
_field: "used_percent",
_value: float(v: r.used) / float(v: r.total) * 100.0,
}),
)
输入:
| _time_时间 | _field_场地 | _value_价值 |
|---|---|---|
| 2020-01-01T00:00:00Z2020-01-01T00:00:00Z | used用过的 | 2.5 |
| 2020-01-01T00:00:10Z2020-01-01T00:00:10Z | used用过的 | 3.1 |
| 2020-01-01T00:00:20Z2020-01-01T00:00:20Z | used用过的 | 4.2 |
| _time_时间 | _field_场地 | _value_价值 |
|---|---|---|
| 2020-01-01T00:00:00Z2020-01-01T00:00:00Z | total全部的 | 8.0 |
| 2020-01-01T00:00:10Z2020-01-01T00:00:10Z | total全部的 | 8.0 |
| 2020-01-01T00:00:20Z2020-01-01T00:00:20Z | total全部的 | 8.0 |
输出:
| _time_时间 | _field_场地 | _value_价值 |
|---|---|---|
| 2020-01-01T00:00:00Z2020-01-01T00:00:00Z | used_percentused_percent | 31.25 |
| 2020-01-01T00:00:10Z2020-01-01T00:00:10Z | used_percentused_percent | 38.75 |
| 2020-01-01T00:00:20Z2020-01-01T00:00:20Z | used_percentused_percent | 52.50 |
示例1:以下示例从 gpu-monitor 存储桶中查询数据并计算一段时间内使用的 GPU 内存百分比。数据包括以下内容:
- gpu 测量;
- mem_used 字段:使用的 GPU 内存(以字节为单位)
- mem_total 字段:以字节为单位的总 GPU 内存
查询mem_used和mem_total字段:
from(bucket: "gpu-monitor")
|> range(start: 2020-01-01T00:00:00Z)
|> filter(fn: (r) => r._measurement == "gpu" and r._field =~ /mem_/)
返回以下两个表流:
| _time | _measurement | _field | _value |
|---|---|---|---|
| 2020-01-01T00:00:00Z | gpu | mem_used | 2517924577 |
| 2020-01-01T00:00:10Z | gpu | mem_used | 2695091978 |
| 2020-01-01T00:00:20Z | gpu | mem_used | 2576980377 |
| 2020-01-01T00:00:30Z | gpu | mem_used | 3006477107 |
| 2020-01-01T00:00:40Z | gpu | mem_used | 3543348019 |
| 2020-01-01T00:00:50Z | gpu | mem_used | 4402341478 |
| _time | _measurement | _field | _value |
|---|---|---|---|
| 2020-01-01T00:00:00Z | gpu | mem_total | 8589934592 |
| 2020-01-01T00:00:10Z | gpu | mem_total | 8589934592 |
| 2020-01-01T00:00:20Z | gpu | mem_total | 8589934592 |
| 2020-01-01T00:00:30Z | gpu | mem_total | 8589934592 |
| 2020-01-01T00:00:40Z | gpu | mem_total | 8589934592 |
| 2020-01-01T00:00:50Z | gpu | mem_total | 8589934592 |
使用 pivot() 将 mem_used 和 mem_total 字段转换为列。输出包括 mem_used 和 mem_total 列,其中包含每个对应 _time 的值。
// ...
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
| _time | _measurement | mem_used | mem_total |
|---|---|---|---|
| 2020-01-01T00:00:00Z | gpu | 2517924577 | 8589934592 |
| 2020-01-01T00:00:10Z | gpu | 2695091978 | 8589934592 |
| 2020-01-01T00:00:20Z | gpu | 2576980377 | 8589934592 |
| 2020-01-01T00:00:30Z | gpu | 3006477107 | 8589934592 |
| 2020-01-01T00:00:40Z | gpu | 3543348019 | 8589934592 |
| 2020-01-01T00:00:50Z | gpu | 4402341478 | 8589934592 |
现在每一行都包含计算百分比所需的值。使用 map() 重新映射每行中的值。将 mem_used 除以 mem_total 并乘以 100 以返回百分比。(要返回包含小数点的精确浮点百分比值,下面的示例将整数字段值转换为浮点数并乘以浮点值 (100.0)。)
// ...
|> map(
fn: (r) => ({
_time: r._time,
_measurement: r._measurement,
_field: "mem_used_percent",
_value: float(v: r.mem_used) / float(v: r.mem_total) * 100.0
})
)
查询结果:
| _time | _measurement | _field | _value |
|---|---|---|---|
| 2020-01-01T00:00:00Z | gpu | mem_used_percent | 29.31 |
| 2020-01-01T00:00:10Z | gpu | mem_used_percent | 31.37 |
| 2020-01-01T00:00:20Z | gpu | mem_used_percent | 30.00 |
| 2020-01-01T00:00:30Z | gpu | mem_used_percent | 35.00 |
| 2020-01-01T00:00:40Z | gpu | mem_used_percent | 41.25 |
| 2020-01-01T00:00:50Z | gpu | mem_used_percent | 51.25 |
完整查询:
from(bucket: "gpu-monitor")
|> range(start: 2020-01-01T00:00:00Z)
|> filter(fn: (r) => r._measurement == "gpu" and r._field =~ /mem_/ )
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(
fn: (r) => ({
_time: r._time,
_measurement: r._measurement,
_field: "mem_used_percent",
_value: float(v: r.mem_used) / float(v: r.mem_total) * 100.0
})
)
示例2:使用多个字段计算百分比。
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> filter(fn: (r) => r._field == "used_system" or r._field == "used_user" or r._field == "total")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({r with _value: float(v: r.used_system + r.used_user) / float(v: r.total) * 100.0}))
示例3:使用多个测量计算百分比:
- 确保测量值在同一个桶中。
- 使用 filter() 包含来自两个测量的数据。
- 使用 group() 取消分组数据并返回单个表。
- 使用 pivot() 将字段旋转到列中。
- 使用 map() 重新映射行并执行百分比计算。
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => (r._measurement == "m1" or r._measurement == "m2") and (r._field == "field1" or r._field == "field2"))
|> group()
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({r with _value: r.field1 / r.field2 * 100.0}))
示例4:使用多个数据源计算百分比。
import "sql"
import "influxdata/influxdb/secrets"
pgUser = secrets.get(key: "POSTGRES_USER")
pgPass = secrets.get(key: "POSTGRES_PASSWORD")
pgHost = secrets.get(key: "POSTGRES_HOST")
t1 = sql.from(
driverName: "postgres",
dataSourceName: "postgresql://${pgUser}:${pgPass}@${pgHost}",
query: "SELECT id, name, available FROM exampleTable",
)
t2 = from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement" and r._field == "example-field")
join(tables: {t1: t1, t2: t2}, on: ["id"])
|> map(fn: (r) => ({r with _value: r._value_t2 / r.available_t1 * 100.0}))
4.8.7、increase():跟踪表中多个列的增加
当跟踪随时间推移或定期重置的计数器值的变化时,此功能特别有用。increase() 返回表中行之间非负差异的累积总和。
data
|> increase()
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1 |
| 2020-01-01T00:02:00Z | 2 |
| 2020-01-01T00:03:00Z | 8 |
| 2020-01-01T00:04:00Z | 10 |
| 2020-01-01T00:05:00Z | 0 |
| 2020-01-01T00:06:00Z | 4 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:02:00Z | 1 |
| 2020-01-01T00:03:00Z | 7 |
| 2020-01-01T00:04:00Z | 9 |
| 2020-01-01T00:05:00Z | 9 |
| 2020-01-01T00:06:00Z | 13 |
4.8.8、movingAverage() & timedMovingAverage() :移动平均值
使用movingAverage() 或timedMovingAverage() 函数返回数据的移动平均值:
- movingAverage():对于表中的每一行,movingAverage() 返回当前值和先前值的平均值,其中 n 是用于计算平均值的值的总数。
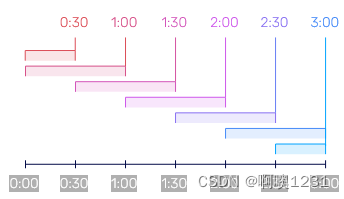
- timedMovingAverage():返回当前值和上一周期(持续时间)中所有行值的平均值。它以每个参数定义的频率返回移动平均值。下图中的每种颜色代表用于计算平均值的时间段以及返回表示平均值的点的时间。如果every = 30m 且period = 1h:
data
|> movingAverage(n: 3)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1.0 |
| 2020-01-01T00:02:00Z | 1.2 |
| 2020-01-01T00:03:00Z | 1.8 |
| 2020-01-01T00:04:00Z | 0.9 |
| 2020-01-01T00:05:00Z | 1.4 |
| 2020-01-01T00:06:00Z | 2.0 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:03:00Z | 1.33 |
| 2020-01-01T00:04:00Z | 1.30 |
| 2020-01-01T00:05:00Z | 1.36 |
| 2020-01-01T00:06:00Z | 1.43 |
data
|> timedMovingAverage(every: 2m, period: 4m)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1.0 |
| 2020-01-01T00:02:00Z | 1.2 |
| 2020-01-01T00:03:00Z | 1.8 |
| 2020-01-01T00:04:00Z | 0.9 |
| 2020-01-01T00:05:00Z | 1.4 |
| 2020-01-01T00:06:00Z | 2.0 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:02:00Z | 1.000 |
| 2020-01-01T00:04:00Z | 1.333 |
| 2020-01-01T00:06:00Z | 1.325 |
| 2020-01-01T00:06:00Z | 1.150 |
4.8.9、计算变化率
使用 derivative() 函数计算后续值之间的变化率,或使用 aggregate.rate() 函数计算每个时间窗口的平均变化率。如果点之间的时间发生变化,这些函数会将点标准化为一个共同的时间间隔,从而使值易于比较。
derivative():计算后续非空值之间每单位时间的变化率。默认情况下,derivative() 仅返回正导数值,并将负值替换为 null。计算值作为浮点数返回。
data
|> derivative(unit: 1m, nonNegative: true)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 250 |
| 2020-01-01T00:04:00Z | 160 |
| 2020-01-01T00:12:00Z | 150 |
| 2020-01-01T00:19:00Z | 220 |
| 2020-01-01T00:32:00Z | 200 |
| 2020-01-01T00:51:00Z | 290 |
| 2020-01-01T01:00:00Z | 340 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:04:00Z | |
| 2020-01-01T00:12:00Z | |
| 2020-01-01T00:19:00Z | 10.0 |
| 2020-01-01T00:32:00Z | |
| 2020-01-01T00:51:00Z | 4.74 |
| 2020-01-01T01:00:00Z | 5.56 |
要返回负导数值,请将 nonNegative 参数设置为 false。
|> derivative(unit: 1m, nonNegative: false)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 250 |
| 2020-01-01T00:04:00Z | 160 |
| 2020-01-01T00:12:00Z | 150 |
| 2020-01-01T00:19:00Z | 220 |
| 2020-01-01T00:32:00Z | 200 |
| 2020-01-01T00:51:00Z | 290 |
| 2020-01-01T01:00:00Z | 340 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:04:00Z | -22.5 |
| 2020-01-01T00:12:00Z | -1.25 |
| 2020-01-01T00:19:00Z | 10.0 |
| 2020-01-01T00:32:00Z | -1.54 |
| 2020-01-01T00:51:00Z | 4.74 |
| 2020-01-01T01:00:00Z | 5.56 |
使用 aggregate.rate() 函数计算每个时间窗口的平均变化率。aggregate.rate() 返回由 every 定义的时间间隔的每单位平均变化率(作为浮点数)。负值替换为 null。aggregate.rate() 不支持 nonNegative: false。
import "experimental/aggregate"
data
|> aggregate.rate(every: 20m, unit: 1m)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 250 |
| 2020-01-01T00:04:00Z | 160 |
| 2020-01-01T00:12:00Z | 150 |
| 2020-01-01T00:19:00Z | 220 |
| 2020-01-01T00:32:00Z | 200 |
| 2020-01-01T00:51:00Z | 290 |
| 2020-01-01T01:00:00Z | 340 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:20:00Z | |
| 2020-01-01T00:40:00Z | 10.0 |
| 2020-01-01T01:00:00Z | 4.74 |
| 2020-01-01T01:20:00Z | 5.56 |
4.8.10、使用Flux创建直方图
直方图为您的数据分布提供了宝贵的洞察力。本指南介绍如何使用 Flux 的 histogram() 函数将数据转换为累积直方图。
histogram()函数:通过计算“bins”列表的数据频率来近似数据集的累积分布。 bin 只是数据点所在的范围。所有小于或等于边界的数据点都计入 bin。在直方图输出中,添加了一列 (le),表示每个 bin 的上限。 Bin 计数是累积的。
Flux 提供了两个辅助函数来生成直方图 的bins。每个都生成并输出一个浮点数组,设计用于 histogram() 函数的 bins 参数。
- linearBins():生成线性分隔的浮点数列表。
linearBins(start: 0.0, width: 10.0, count: 10) // Generated list: [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, +Inf] - logarithmicBins():生成一个以指数方式分隔的浮点数列表。
logarithmicBins(start: 1.0, factor: 2.0, count: 10, infinty: true) // Generated list: [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, +Inf]
示例1:
data
|> histogram(
column: "_value",
upperBoundColumn: "le",
countColumn: "_value",
bins: [100.0, 200.0, 300.0, 400.0],
)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 250.0 |
| 2020-01-01T00:01:00Z | 160.0 |
| 2020-01-01T00:02:00Z | 150.0 |
| 2020-01-01T00:03:00Z | 220.0 |
| 2020-01-01T00:04:00Z | 200.0 |
| 2020-01-01T00:05:00Z | 290.0 |
| 2020-01-01T01:00:00Z | 340.0 |
输出:
| le | _value |
|---|---|
| 100.0 | 0.0 |
| 200.0 | 3.0 |
| 300.0 | 6.0 |
| 400.0 | 7.0 |
示例2:使用线性bin生成直方图。
from(bucket: "telegraf/autogen")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> histogram(bins: linearBins(start: 65.5, width: 0.5, count: 20, infinity: false))
输出表:
Table: keys: [_start, _stop, _field, _measurement, host]
_start:time _stop:time _field:string _measurement:string host:string le:float _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------ ---------------------------- ----------------------------
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 65.5 5
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 66 6
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 66.5 8
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 67 9
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 67.5 9
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 68 10
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 68.5 12
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 69 12
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 69.5 15
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 70 23
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 70.5 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 71 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 71.5 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 72 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 72.5 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 73 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 73.5 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 74 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 74.5 30
2018-11-07T22:19:58.423658000Z 2018-11-07T22:24:58.423658000Z used_percent mem Scotts-MacBook-Pro.local 75 30示例3:使用对数bin生成直方图。
from(bucket: "telegraf/autogen")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> histogram(bins: logarithmicBins(start: 0.5, factor: 2.0, count: 10, infinity: false))
输出表:
Table: keys: [_start, _stop, _field, _measurement, host]
_start:time _stop:time _field:string _measurement:string host:string le:float _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------ ---------------------------- ----------------------------
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 0.5 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 1 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 2 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 4 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 8 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 16 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 32 0
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 64 2
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 128 30
2018-11-07T22:23:36.860664000Z 2018-11-07T22:28:36.860664000Z used_percent mem Scotts-MacBook-Pro.local 256 304.8.11、填充
使用 fill() 函数将空值替换为:
- 前一个非空值:要使用前一个非空值填充空值,请将 usePrevious 参数设置为 true。
data |> fill(usePrevious: true) - 一个指定的值。
data |> fill(value: 0.0)
fill() 函数不会填充空的时间窗口。它只替换现有数据中的空值。填充空的时间窗口需要时间插值(参见 influxdata/flux#2428)。
data
|> fill(usePrevious: true)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | null |
| 2020-01-01T00:02:00Z | 0.8 |
| 2020-01-01T00:03:00Z | null |
| 2020-01-01T00:04:00Z | null |
| 2020-01-01T00:05:00Z | 1.4 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | null |
| 2020-01-01T00:02:00Z | 0.8 |
| 2020-01-01T00:03:00Z | 0.8 |
| 2020-01-01T00:04:00Z | 0.8 |
| 2020-01-01T00:05:00Z | 1.4 |
data
|> fill(value: 0.0)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | null |
| 2020-01-01T00:02:00Z | 0.8 |
| 2020-01-01T00:03:00Z | null |
| 2020-01-01T00:04:00Z | null |
| 2020-01-01T00:05:00Z | 1.4 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 0.0 |
| 2020-01-01T00:02:00Z | 0.8 |
| 2020-01-01T00:03:00Z | 0.0 |
| 2020-01-01T00:04:00Z | 0.0 |
| 2020-01-01T00:05:00Z | 1.4 |
4.8.12、查找中值
使用 median() 函数返回一个表示输入数据的 0.5 分位数(第 50 个百分位数)或中位数的值。
选择以下方法之一来计算中位数:
- estimate_tdigest(估计):(默认)一种聚合方法,它使用 t-digest 数据结构来计算大型数据源的准确 0.5 分位数估计。输出表由包含计算中位数的单行组成。使用默认方法“estimate_tdigest”返回表中包含表中第 50 个百分位数据的值的所有行。
data |> median()_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _value 1.5 - exact_mean(精确平均):一种聚合方法,取最接近 0.5 分位数的两个点的平均值。输出表由包含计算中位数的单行组成。使用exact_mean 方法返回每个输入表的单行,其中包含最接近表中数据的数学中位数的两个值的平均值。
data |> median(method: "exact_mean")_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _value 1.5 - exact_selector(精确选择器):一种选择器方法,它返回至少 50% 的点小于的数据点。输出表由包含计算中位数的单行组成。
data |> median(method: "exact_selector")_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _time _value 2020-01-01T00:02:00Z 1.0
将median() 和 aggregateWindow() 一起使用:aggregateWindow() 将数据分割成时间窗口,将每个窗口中的数据聚合成一个点,然后去除基于时间的分割。它主要用于对数据进行下采样。要在 aggregateWindow() 中指定中值计算方法,请使用完整的函数语法:
data
|> aggregateWindow(every: 5m, fn: (tables=<-, column) => tables |> median(method: "exact_selector"))
4.8.13、查找百分位数和分位数
使用 quantile() 函数返回输入数据的 q 分位数或百分位数内的所有值。百分位数和分位数非常相似,只是用于计算返回值的数字不同。百分位数使用 0 到 100 之间的数字计算。分位数使用 0.0 和 1.0 之间的数字计算。例如,0.5 分位数与第 50 个百分位数相同。
选择以下方法之一来计算分位数:
- estimate_tdigest(估计):(默认)一种聚合方法,它使用 t-digest 数据结构来计算大型数据源的分位数估计。输出表由包含计算的分位数的单行组成。如果计算 0.5 分位数或第 50 个百分位数:
_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _value 1.5 - exact_mean(精确平均):一种聚合方法,取最接近分位数的两个点的平均值。输出表由包含计算的分位数的单行组成。如果计算 0.5 分位数或第 50 个百分位数:
_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _value 1.5 - exact_selector(精确选择器):一个选择器方法,它返回至少 q 个点小于的数据点。输出表由包含计算的分位数的单行组成。如果计算 0.5 分位数或第 50 个百分位数:
_time _value 2020-01-01T00:01:00Z 1.0 2020-01-01T00:02:00Z 1.0 2020-01-01T00:03:00Z 2.0 2020-01-01T00:04:00Z 3.0 _time _value 2020-01-01T00:02:00Z 1.0
使用默认方法“estimate_tdigest”返回表中包含表中第 99 个百分位数据的值的所有行:
data
|> quantile(q: 0.99)
使用exact_mean 方法返回每个输入表的单行,其中包含最接近表中数据的数学分位数的两个值的平均值。例如,要计算 0.99 分位数:
data
|> quantile(q: 0.99, method: "exact_mean")
使用exact_selector 方法为每个输入表返回一行,其中包含表中q * 100% 的值小于的值。例如,要计算 0.99 分位数:
data
|> quantile(q: 0.99, method: "exact_selector")
使用 quantile() 和 aggregateWindow():aggregateWindow() 将数据分割成时间窗口,将每个窗口中的数据聚合成一个点,然后去除基于时间的分割。它主要用于对数据进行下采样。要在 aggregateWindow() 中指定分位数计算方法,请使用完整的函数语法:
data
|> aggregateWindow(
every: 5m,
fn: (tables=<-, column) => tables
|> quantile(q: 0.99, method: "exact_selector"),
)
4.8.14、Join(加入):使用Flux连接数据
join() 函数将两个或多个输入流(其值在一组公共列上相等)合并为单个输出流。 Flux 允许您连接两个数据流之间共有的任何列,并为交叉测量连接和跨测量数学等操作打开了大门。为了说明连接操作,使用 Telegraf 捕获并存储在 InfluxDB 中的数据 - 内存使用和进程。在本指南中,我们将连接两个数据流,一个代表内存使用量,另一个代表正在运行的进程总数,然后计算每个正在运行的进程的平均内存使用量。
为了执行连接,您必须有两个数据流。为每个数据流分配一个变量。
- 定义一个 memUsed 变量,用于过滤 mem 度量和 used 字段。这将返回使用的内存量(以字节为单位)。
memUsed = from(bucket: "db/rp") |> range(start: -5m) |> filter(fn: (r) => r._measurement == "mem" and r._field == "used")Table: keys: [_start, _stop, _field, _measurement, host] _start:time _stop:time _field:string _measurement:string host:string _time:time _value:int ------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------ ------------------------------ -------------------------- 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:00.000000000Z 10956333056 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:10.000000000Z 11014008832 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:20.000000000Z 11373428736 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:30.000000000Z 11001421824 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:40.000000000Z 10985852928 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:50:50.000000000Z 10992279552 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:00.000000000Z 11053568000 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:10.000000000Z 11092242432 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:20.000000000Z 11612774400 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:30.000000000Z 11131961344 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:40.000000000Z 11124805632 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:51:50.000000000Z 11332464640 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:52:00.000000000Z 11176923136 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:52:10.000000000Z 11181068288 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z used mem host1.local 2018-11-06T05:52:20.000000000Z 11182579712 - 定义一个 procTotal 变量,用于过滤流程测量和总计字段。这将返回正在运行的进程数。
procTotal = from(bucket: "db/rp") |> range(start: -5m) |> filter(fn: (r) => r._measurement == "processes" and r._field == "total")Table: keys: [_start, _stop, _field, _measurement, host] _start:time _stop:time _field:string _measurement:string host:string _time:time _value:int ------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------ ------------------------------ -------------------------- 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:00.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:10.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:20.000000000Z 471 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:30.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:40.000000000Z 469 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:50:50.000000000Z 471 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:51:00.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:51:10.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:51:20.000000000Z 470 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z total processes host1.local 2018-11-06T05:51:30.000000000Z 470
加入两个数据流:定义了两个数据流后,使用 join() 函数将它们连接在一起。 join() 需要两个参数:
- tables(表):一个表的映射,用于连接它们将被别名的键。在下面的示例中,mem 是 memUsed 的别名,proc 是 procTotal 的别名。
- on:一个字符串数组,定义表将在其上连接的列。两个表都必须具有此列表中指定的所有列。
join(tables: {mem: memUsed, proc: procTotal}, on: ["_time", "_stop", "_start", "host"])
Table: keys: [_field_mem, _field_proc, _measurement_mem, _measurement_proc, _start, _stop, host]
_field_mem:string _field_proc:string _measurement_mem:string _measurement_proc:string _start:time _stop:time host:string _time:time _value_mem:int _value_proc:int
---------------------- ---------------------- ----------------------- ------------------------ ------------------------------ ------------------------------ ------------------------ ------------------------------ -------------------------- --------------------------
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:00.000000000Z 10956333056 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:10.000000000Z 11014008832 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:20.000000000Z 11373428736 471
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:30.000000000Z 11001421824 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:40.000000000Z 10985852928 469
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:50.000000000Z 10992279552 471
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:00.000000000Z 11053568000 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:10.000000000Z 11092242432 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:20.000000000Z 11612774400 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:30.000000000Z 11131961344 470
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:40.000000000Z 11124805632 469
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:50.000000000Z 11332464640 471
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:52:00.000000000Z 请注意,输出表包括以下列,这些列为具有两个输入表唯一值的列。
- _field_mem:
- _field_proc:
- _measurement_mem:
- _measurement_proc:
- _value_mem:
- _value_proc:
计算并创建一个新表:将两个数据流连接到一个表中,使用 map() 函数通过将现有的 _time 列映射到新的 _time 列并将 _value_mem 除以 _value_proc 并将其映射到新的 _value 列来构建新表。
join(tables: {mem: memUsed, proc: procTotal}, on: ["_time", "_stop", "_start", "host"])
|> map(fn: (r) => ({_time: r._time, _value: r._value_mem / r._value_proc}))
Table: keys: [_field_mem, _field_proc, _measurement_mem, _measurement_proc, _start, _stop, host]
_field_mem:string _field_proc:string _measurement_mem:string _measurement_proc:string _start:time _stop:time host:string _time:time _value:int
---------------------- ---------------------- ----------------------- ------------------------ ------------------------------ ------------------------------ ------------------------ ------------------------------ --------------------------
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:00.000000000Z 23311346
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:10.000000000Z 23434061
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:20.000000000Z 24147407
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:30.000000000Z 23407280
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:40.000000000Z 23423993
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:50:50.000000000Z 23338173
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:00.000000000Z 23518229
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:10.000000000Z 23600515
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:20.000000000Z 24708030
used total mem processes 2018-11-06T05:50:00.000000000Z 2018-11-06T05:55:00.000000000Z Scotts-MacBook-Pro.local 2018-11-06T05:51:30.000000000Z 此表表示每个正在运行的进程的平均内存量(以字节为单位)。
现实世界的例子:以下函数通过连接来自 httpd 的字段和写入测量值来计算写入 InfluxDB 集群的批量大小,以便比较 pointReq 和 writeReq。结果按集群 ID 分组,因此您可以跨集群进行比较。
batchSize = (cluster_id, start=-1m, interval=10s) => {
httpd = from(bucket: "telegraf")
|> range(start: start)
|> filter(fn: (r) => r._measurement == "influxdb_httpd" and r._field == "writeReq" and r.cluster_id == cluster_id)
|> aggregateWindow(every: interval, fn: mean)
|> derivative(nonNegative: true, unit: 60s)
write = from(bucket: "telegraf")
|> range(start: start)
|> filter(fn: (r) => r._measurement == "influxdb_write" and r._field == "pointReq" and r.cluster_id == cluster_id)
|> aggregateWindow(every: interval, fn: max)
|> derivative(nonNegative: true, unit: 60s)
return join(tables: {httpd: httpd, write: write}, on: ["_time", "_stop", "_start", "host"])
|> map(fn: (r) => ({_time: r._time, _value: r._value_httpd / r._value_write}))
|> group(columns: cluster_id)
}
batchSize(cluster_id: "enter cluster id here")
4.8.15、查询累计总和
使用cumulativeSum() 函数计算值的运行总计。 cumulativeSum 对后续记录的值求和,并返回使用总和更新的每一行。
data
|> cumulativeSum()
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1 |
| 2020-01-01T00:02:00Z | 2 |
| 2020-01-01T00:03:00Z | 1 |
| 2020-01-01T00:04:00Z | 3 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1 |
| 2020-01-01T00:02:00Z | 3 |
| 2020-01-01T00:03:00Z | 4 |
| 2020-01-01T00:04:00Z | 7 |
将 cumulativeSum() 与 aggregateWindow()一起使用:aggregateWindow() 将数据分段为时间窗口,将每个窗口中的数据聚合为一个点,然后删除基于时间的分段。它主要用于对数据进行下采样。aggregateWindow() 需要一个聚合函数,它为每个时间窗口返回一行。要将cumulativeSum() 与aggregateWindow 一起使用,请在aggregateWindow() 中使用sum,然后使用cumulativeSum() 计算聚合值的总和。
data
|> aggregateWindow(every: 5m, fn: sum)
|> cumulativeSum()
4.8.16、first() & last():查询第1个和最后一个值
使用 first() 或 last() 函数返回输入表中的第一个或最后一条记录。
data
|> first()
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1.0 |
| 2020-01-01T00:02:00Z | 1.0 |
| 2020-01-01T00:03:00Z | 2.0 |
| 2020-01-01T00:04:00Z | 3.0 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1.0 |
data
|> last()
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:01:00Z | 1.0 |
| 2020-01-01T00:02:00Z | 1.0 |
| 2020-01-01T00:03:00Z | 2.0 |
| 2020-01-01T00:04:00Z | 3.0 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:04:00Z | 3.0 |
将 first() 或 last() 与 aggregateWindow()一起使用:使用 first() 和 last() 与 aggregateWindow() 选择基于时间的组中的第一条或最后一条记录。 aggregateWindow() 将数据分割成时间窗口,使用聚合或选择器函数将每个窗口中的数据聚合成一个点,然后删除基于时间的分割。
|> aggregateWindow(
every: 1h,
fn: first,
)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 10 |
| 2020-01-01T00:00:15Z | 12 |
| 2020-01-01T00:00:45Z | 9 |
| 2020-01-01T00:01:05Z | 9 |
| 2020-01-01T00:01:10Z | 15 |
| 2020-01-01T00:02:30Z | 11 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:00:59Z | 10 |
| 2020-01-01T00:01:59Z | 9 |
| 2020-01-01T00:02:59Z | 11 |
4.8.17、exists 运算符
使用 Flux exists 运算符检查记录是否包含键或该键的值是否为空。
p = {firstName: "John", lastName: "Doe", age: 42}
exists p.firstName
// Returns true
exists p.height
// Returns false将exists与行函数(filter()、map()、reduce())一起使用来检查行是否包含列或该列的值是否为空。
1、过滤空值:
from(bucket: "db/rp")
|> range(start: -5m)
|> filter(fn: (r) => exists r._value)2、基于存在映射值:
from(bucket: "default")
|> range(start: -30s)
|> map(
fn: (r) => ({r with
human_readable: if exists r._value then
"${r._field} is ${string(v: r._value)}."
else
"${r._field} has no value.",
}),
)
3、忽略自定义聚合函数中的值
customSumProduct = (tables=<-) => tables
|> reduce(
identity: {sum: 0.0, product: 1.0},
fn: (r, accumulator) => ({r with
sum: if exists r._value then
r._value + accumulator.sum
else
accumulator.sum,
product: if exists r._value then
r.value * accumulator.product
else
accumulator.product,
}),
)
4.8.18、用Flux提取标量值
使用 Flux 流和表函数从 Flux 查询输出中提取标量值。例如,这使您可以使用查询结果动态设置变量。
从输出中提取标量值:
- 提取表。
- 从表中提取一列或从表中提取一行。
目前的限制:
- InfluxDB 用户界面 (UI) 当前不支持原始标量输出。使用 map() 将标量值添加到输出数据。
- Flux REPL 目前不支持 Flux 流和表函数(也称为“动态查询”)。请参阅#15321。
1、tableFind():提取表
Flux 将查询结果格式化为表流。要从表流中提取标量值,您必须首先提取单个表。如果查询结果只包含一个表,它仍然被格式化为表流。您仍然必须从流中提取该表。使用 tableFind() 提取组键值与 fn 判别函数匹配的第一个表。判别函数需要一个key记录,它表示每个表的组键。
sampleData
|> tableFind(fn: (key) => key._field == "temp" and key.location == "sfo")
上面的示例返回一个表:
| _time | location | _field | _value |
|---|---|---|---|
| 2019-11-01T12:00:00Z | sfo | temp | 65.1 |
| 2019-11-01T13:00:00Z | sfo | temp | 66.2 |
| 2019-11-01T14:00:00Z | sfo | temp | 66.3 |
| 2019-11-01T15:00:00Z | sfo | temp | 66.8 |
提取正确的表:Flux 函数不保证表顺序,并且 tableFind() 仅返回与 fn 判别匹配的第一个表。要提取包含您实际需要的数据的表,请在您的判别函数中非常具体,或者过滤和转换您的数据以最小化通过管道转发到 tableFind() 的表的数量。
2、getColumn():从表中提取一列
使用 getColumn() 函数从提取的表中的特定列输出值数组。
sampleData
|> tableFind(fn: (key) => key._field == "temp" and key.location == "sfo")
|> getColumn(column: "_value")
// Returns [65.1, 66.2, 66.3, 66.8]使用提取的列值:使用变量来存储值数组。在下面的示例中,SFOTemps 表示值数组。引用数组中的特定索引(从 0 开始的整数)以返回该索引处的值。
SFOTemps = sampleData
|> tableFind(fn: (key) => key._field == "temp" and key.location == "sfo")
|> getColumn(column: "_value")
SFOTemps
// Returns [65.1, 66.2, 66.3, 66.8]
SFOTemps[0]
// Returns 65.1
SFOTemps[2]
// Returns 66.33、getRecord():从表中提取一行
使用 getRecord() 函数从提取的表中的单行输出数据。使用 idx 参数指定要输出的行的索引。该函数为每列输出一个包含键值对的记录
sampleData
|> tableFind(fn: (key) => key._field == "temp" and key.location == "sfo")
|> getRecord(idx: 0)
// Returns {
// _time:2019-11-11T12:00:00Z,
// _field:"temp",
// location:"sfo",
// _value: 65.1
// }使用提取的行记录:使用变量来存储提取的行记录。在下面的示例中, tempInfo 表示提取的行。使用点表示法来引用记录中的键。
tempInfo = sampleData
|> tableFind(fn: (key) => key._field == "temp" and key.location == "sfo")
|> getRecord(idx: 0)
tempInfo
// Returns {
// _time:2019-11-11T12:00:00Z,
// _field:"temp",
// location:"sfo",
// _value: 65.1
// }
tempInfo._time
// Returns 2019-11-11T12:00:00Z
tempInfo.location
// Returns sfo4、辅助函数示例
创建自定义辅助函数以从查询输出中提取标量值。
提取标量字段值:
// Define a helper function to extract field values
getFieldValue = (tables=<-, field) => {
extract = tables
|> tableFind(fn: (key) => key._field == field)
|> getColumn(column: "_value")
return extract[0]
}
// Use the helper function to define a variable
lastJFKTemp = sampleData
|> filter(fn: (r) => r.location == "kjfk")
|> last()
|> getFieldValue(field: "temp")
lastJFKTemp
// Returns 71.2提取标量行数据:
// Define a helper function to extract a row as a record
getRow = (tables=<-, field, idx=0) => {
extract = tables
|> tableFind(fn: (key) => true)
|> getRecord(idx: idx)
return extract
}
// Use the helper function to define a variable
lastReported = sampleData
|> last()
|> getRow(field: "temp")
"The last location to report was ${lastReported.location}.
The temperature was ${string(v: lastReported._value)}°F."
// Returns:
// The last location to report was kord.
// The temperature was 38.9°F.5、样本数据
以下示例数据集代表从三个位置收集的虚构温度指标。它采用带注释的 CSV 格式,并使用 csv.from() 函数导入到 Flux 查询中。将以下内容放在查询的开头以使用示例数据:
import "csv"
sampleData = csv.from(csv: "
#datatype,string,long,dateTime:RFC3339,string,string,double
#group,false,true,false,true,true,false
#default,,,,,,
,result,table,_time,location,_field,_value
,,0,2019-11-01T12:00:00Z,sfo,temp,65.1
,,0,2019-11-01T13:00:00Z,sfo,temp,66.2
,,0,2019-11-01T14:00:00Z,sfo,temp,66.3
,,0,2019-11-01T15:00:00Z,sfo,temp,66.8
,,1,2019-11-01T12:00:00Z,kjfk,temp,69.4
,,1,2019-11-01T13:00:00Z,kjfk,temp,69.9
,,1,2019-11-01T14:00:00Z,kjfk,temp,71.0
,,1,2019-11-01T15:00:00Z,kjfk,temp,71.2
,,2,2019-11-01T12:00:00Z,kord,temp,46.4
,,2,2019-11-01T13:00:00Z,kord,temp,46.3
,,2,2019-11-01T14:00:00Z,kord,temp,42.7
,,2,2019-11-01T15:00:00Z,kord,temp,38.9
")
4.8.19、操作时间戳
存储在 InfluxDB 中的每个点都有一个关联的时间戳。使用 Flux 处理和操作时间戳以满足您的需求。
1、转换时间戳格式
- Unix纳秒转换为RFC3339:使用 time() 函数将 Unix 纳秒时间戳转换为 RFC3339 时间戳。
time(v: 1568808000000000000) // Returns 2019-09-18T12:00:00.000000000Z - RFC3339转换为Unix纳秒:
uint(v: 2019-09-18T12:00:00.000000000Z) // Returns 1568808000000000000
2、计算2个时间戳之间的持续时间
Flux 不支持使用时间类型值的数学运算。要计算两个时间戳之间的持续时间:
- 使用 uint() 函数将每个时间戳转换为 Unix 纳秒时间戳。
- 该 Unix 纳秒时间戳减去另一个。
- 使用 duration() 函数将结果转换为持续时间。
time1 = uint(v: 2019-09-17T21:12:05Z)
time2 = uint(v: 2019-09-18T22:16:35Z)
duration(v: time2 - time1)
// Returns 25h4m30sFlux 不支持持续时间列类型。要将持续时间存储在列中,请使用 string() 函数将持续时间转换为字符串。
3、检索当前时间
- 当前UTC时间:使用 now() 函数以 RFC3339 格式返回当前 UTC 时间。now() 在运行时被缓存,因此 Flux 脚本中的所有 now() 实例都返回相同的值。
now() - 当前系统时间:导入system包,使用system.time()函数以RFC3339格式返回宿主机当前系统时间。system.time() 返回执行的时间,因此 Flux 脚本中的每个 system.time() 实例都返回一个唯一值。
import "system" system.time()
4、标准化不规则时间戳
要标准化不规则时间戳,请使用 truncateTimeColumn() 函数将所有 _time 值截断为指定单位。这在点应按时间对齐的 join() 和 pivot() 操作中很有用,但时间戳略有不同。
data
|> truncateTimeColumn(unit: 1m)
输入:
| _time | _value |
|---|---|
| 2020-01-01T00:00:49Z | 2.0 |
| 2020-01-01T00:01:01Z | 1.9 |
| 2020-01-01T00:03:22Z | 1.8 |
| 2020-01-01T00:04:04Z | 1.9 |
| 2020-01-01T00:05:38Z | 2.1 |
输出:
| _time | _value |
|---|---|
| 2020-01-01T00:00:00Z | 2.0 |
| 2020-01-01T00:01:00Z | 1.9 |
| 2020-01-01T00:03:00Z | 1.8 |
| 2020-01-01T00:04:00Z | 1.9 |
| 2020-01-01T00:05:00Z | 2.1 |
5、一起使用时间戳(timestamp)和持续时间(duration)
- 为时间戳添加持续时间:Experimental.addDuration() 函数将持续时间添加到指定时间并返回结果时间。通过使用experimental.addDuration(),您接受实验功能的风险。
import "experimental" experimental.addDuration(d: 6h, to: 2019-09-16T12:00:00Z) // Returns 2019-09-16T18:00:00.000000000Z - 从时间戳中减去持续时间:Experimental.subDuration() 函数从指定时间中减去一个持续时间并返回结果时间。通过使用 experimental.subDuration(),您接受实验功能的风险。
import "experimental" experimental.subDuration(d: 6h, from: 2019-09-16T12:00:00Z) // Returns 2019-09-16T06:00:00.000000000Z
4.8.20、监控状态
Flux 可帮助您监控指标和事件中的状态:
- 找出一个状态持续多久;
- 计算连续状态的数量;
- 检测状态变化。
1、找出一个状态持续多久
使用 stateDuration() 函数计算列值保持相同值(或状态)的时间。包括以下信息:
- 要搜索的列:任何标签键、标签值、字段键、字段值或度量。
- 值:要在指定列中搜索的值(或状态)。
- 状态持续时间列:用于存储状态持续时间的新列——指定值持续的时间长度。
- Unit:用于增加状态持续时间的时间单位(1s(默认)、1m、1h)。
data
|> stateDuration(
fn: (r) => r._column_to_search == "value_to_search_for",
column: "state_duration",
unit: 1s,
)
使用 stateDuration() 搜索每个点的指定值:
- 对于评估为 true 的第一个点,状态持续时间设置为 0。对于评估为 true 的每个连续点,状态持续时间增加每个连续点之间的时间间隔(以指定单位)。
- 如果状态为假,则状态持续时间重置为 -1。
使用stateDuration()的示例查询:以下查询在过去 5 分钟内搜索门存储桶以查找门已关闭的秒数:
from(bucket: "doors")
|> range(start: -5m)
|> stateDuration(
fn: (r) => r._value == "closed",
column: "door_closed",
unit: 1s,
)
在此示例中,door_closed 是状态持续时间列。如果您每分钟将数据写入门存储桶,则状态持续时间会在 _value 关闭的每个连续点增加 60 秒。如果 _value 未关闭,则状态持续时间重置为 0。
上面示例查询的结果可能如下所示(为简单起见,我们省略了测量、标签和字段列):
_time _value door_closed
2019-10-26T17:39:16Z closed 0
2019-10-26T17:40:16Z closed 60
2019-10-26T17:41:16Z closed 120
2019-10-26T17:42:16Z open -1
2019-10-26T17:43:16Z closed 0
2019-10-26T17:44:27Z closed 60
2、计算连续状态的数量
使用 stateCount() 函数并包含以下信息:
- 要搜索的列:任何标签键、标签值、字段键、字段值或度量。
- 值:在指定列中搜索。
- 状态计数列:用于存储状态计数的新列─指定值存在的连续记录数。
data
|> stateCount(
fn: (r) => r._column_to_search == "value_to_search_for",
column: "state_count"
)
使用stateCount()在每个点中搜索指定值:
- 对于评估为 true 的第一个点,状态计数设置为 1。对于评估为 true 的每个连续点,状态计数增加 1。
- 如果状态为假,则状态计数重置为 -1。
使用stateCount()的示例查询:以下查询在过去 5 分钟内搜索门存储桶,并计算已关闭的点数作为它们的 _value:
from(bucket: "doors")
|> range(start: -5m)
|> stateCount(fn: (r) => r._value == "closed", column: "door_closed")
此示例将状态计数存储在 door_closed 列中。如果您每分钟将数据写入门存储桶,则状态计数会在 _value 关闭的每个连续点增加 1。如果 _value 未关闭,则状态计数重置为 -1。
上面示例查询的结果可能如下所示(为简单起见,我们省略了测量、标签和字段列):
_time _value door_closed
2019-10-26T17:39:16Z closed 1
2019-10-26T17:40:16Z closed 2
2019-10-26T17:41:16Z closed 3
2019-10-26T17:42:16Z open -1
2019-10-26T17:43:16Z closed 1
2019-10-26T17:44:27Z closed 2
机器状态计数的示例查询:以下查询每分钟检查一次机器状态(空闲、已分配或忙碌)。 InfluxDB 在过去一小时内搜索服务器存储桶并计算机器状态为空闲、已分配或忙碌的记录。
from(bucket: "servers")
|> range(start: -1h)
|> filter(fn: (r) => r.machine_state == "idle" or r.machine_state == "assigned" or r.machine_state == "busy")
|> stateCount(fn: (r) => r.machine_state == "busy", column: "_count")
|> stateCount(fn: (r) => r.machine_state == "assigned", column: "_count")
|> stateCount(fn: (r) => r.machine_state == "idle", column: "_count")
4.8.21、查询SQL数据源
Flux sql 包提供了处理 SQL 数据源的函数。 sql.from() 让您可以查询 PostgreSQL、MySQL 和 SQLite 等 SQL 数据源,并将结果用于 InfluxDB 仪表板、任务和其他操作。
1、查询SQL数据源
查询 SQL 数据源:
- 在 Flux 查询中导入 sql 包
- 使用 sql.from() 函数指定用于从 SQL 数据源查询数据的驱动程序、数据源名称 (DSN) 和查询:
import "sql" sql.from( driverName: "mysql", dataSourceName: "user:password@tcp(localhost:3306)/db", query: "SELECT * FROM example_table", )
2、将SQL数据与InfluxDB中的数据连接起来
从 InfluxDB 查询 SQL 数据源的主要好处之一是能够使用存储在 InfluxDB 之外的数据来丰富查询结果。使用下面的空气传感器示例数据,以下查询将存储在 InfluxDB 中的空气传感器指标与存储在 PostgreSQL 中的传感器信息连接起来。连接的数据允许您根据未存储在 InfluxDB 中的传感器信息查询和过滤结果。
// Import the "sql" package
import "sql"
// Query data from PostgreSQL
sensorInfo = sql.from(
driverName: "postgres",
dataSourceName: "postgresql://localhost?sslmode=disable",
query: "SELECT * FROM sensors",
)
// Query data from InfluxDB
sensorMetrics = from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "airSensors")
// Join InfluxDB query results with PostgreSQL query results
join(tables: {metric: sensorMetrics, info: sensorInfo}, on: ["sensor_id"])
3、样本传感器数据
样本数据生成器和样本传感器信息模拟一组传感器,用于测量整个建筑物房间内的温度、湿度和一氧化碳。每个收集的数据点都存储在 InfluxDB 中,带有一个 sensor_id 标签,用于标识它来自的特定传感器。示例传感器信息存储在 PostgreSQL 中。
样本数据包括:
- 从每个传感器收集的模拟数据并存储在 InfluxDB 中的 airSensors 测量中:① temperature;② humidity;③ co。
- 有关存储在 PostgreSQL 中的传感器表中的每个传感器的信息:① sensor_id;② location;③ model_number;④ last_inspected。
》导入并生成示例传感器数据:
1)下载并运行示例数据生成器
- air-sensor-data.rb 是一个生成空气传感器数据并将数据存储在 InfluxDB 中的脚本。要使用 air-sensor-data.rb:
- 创建一个数据库来存储数据。
- 下载示例数据生成器。此工具需要 Ruby。
- 赋予 air-sensor-data.rb 可执行权限:
chmod +x air-sensor-data.rb - 启动启动器。指定您的数据库。
生成器开始向 InfluxDB 写入数据,并将一直持续到停止。使用 ctrl-c 停止生成器。注意:使用 --help 标志查看其他配置选项。./air-sensor-data.rb -d database-name - 查询您的目标数据库以确保生成的数据写入成功。生成器不会从写入请求中捕获错误,因此即使数据没有成功写入 InfluxDB,它也会继续运行。
from(bucket: "database-name/autogen") |> range(start: -1m) |> filter(fn: (r) => r._measurement == "airSensors")
2)导入样本传感器信息
- 下载并安装 PostgreSQL。
- 下载示例传感器信息 CSV。
- 使用 PostgreSQL 客户端(psql 或 GUI)创建传感器表:
CREATE TABLE sensors ( sensor_id character varying(50), location character varying(50), model_number character varying(50), last_inspected date ); - 导入下载的 CSV 样本数据。将 FROM 文件路径更新为下载的 CSV 样本数据的路径。
COPY sensors(sensor_id,location,model_number,last_inspected) FROM '/path/to/sample-sensor-info.csv' DELIMITER ',' CSV HEADER; - 查询表以确保数据正确导入:
SELECT * FROM sensors;
4.8.22、条件逻辑
Flux 提供了 if、then 和 else 条件表达式,允许强大而灵活的 Flux 查询。本指南介绍如何使用 Flux 条件表达式来查询和转换数据。 Flux 从左到右评估语句,一旦条件匹配就停止评估。
条件表达式语法:
// Pattern
if <condition> then <action> else <alternative-action>
// Example
if color == "green" then "008000" else "ffffff"
条件表达式在以下情况下最有用:
- 定义变量时。
- 使用一次对单行操作的函数时(filter()、map()、reduce())。
1、评估条件表达式
Flux 按顺序评估语句,并在条件匹配时停止评估。例如,给定以下语句:
if r._value > 95.0000001 and r._value <= 100.0 then
"critical"
else if r._value > 85.0000001 and r._value <= 95.0 then
"warning"
else if r._value > 70.0000001 and r._value <= 85.0 then
"high"
else
"normal"
当 r._value 为 96 时,输出为“critical”并且不评估剩余条件。
2、例子
1)有条件地设置变量的值:下面的示例根据 dueDate 变量与 now() 的关系设置过期变量:
dueDate = 2019-05-01T00:00:00Z
overdue = if dueDate < now() then true else false
2)创建条件过滤器:以下示例使用示例度量变量来更改查询过滤数据的方式。 metric 有三个可能的值:Memeory、CPU、Disk。
metric = "Memory"
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(
fn: (r) => if v.metric == "Memory" then
r._measurement == "mem" and r._field == "used_percent"
else if v.metric == "CPU" then
r._measurement == "cpu" and r._field == "usage_user"
else if v.metric == "Disk" then
r._measurement == "disk" and r._field == "used_percent"
else
r._measurement != "",
)
3)使用map()有条件地转换列值:以下示例使用 map() 函数有条件地转换列值。它将级别列设置为基于 _value 列的特定字符串。
from(bucket: "telegraf/autogen")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> map(
fn: (r) => ({
// Retain all existing columns in the mapped row
r with
// Set the level column value based on the _value column
level: if r._value >= 95.0000001 and r._value <= 100.0 then
"critical"
else if r._value >= 85.0000001 and r._value <= 95.0 then
"warning"
else if r._value >= 70.0000001 and r._value <= 85.0 then
"high"
else
"normal",
}),
)
4、使用reduce()有条件地增加一个计数:以下示例使用 aggregateWindow() 和 reduce() 函数计算每五分钟窗口中超过定义阈值的记录数。
threshold = 65.0
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
// Aggregate data into 5 minute windows using a custom reduce() function
|> aggregateWindow(
every: 5m,
// Use a custom function in the fn parameter.
// The aggregateWindow fn parameter requires 'column' and 'tables' parameters.
fn: (column, tables=<-) => tables
|> reduce(
identity: {above_threshold_count: 0.0},
fn: (r, accumulator) => ({
// Conditionally increment above_threshold_count if
// r.value exceeds the threshold
above_threshold_count: if r._value >= threshold then
accumulator.above_threshold_count + 1.0
else
accumulator.above_threshold_count + 0.0,
}),
),
)
4.8.23、正则表达式
在匹配大量数据集合中的模式时,正则表达式(正则表达式)非常强大。使用 Flux,正则表达式主要用于判别函数中的评估逻辑,例如过滤行、删除和保留列、状态检测等。本指南展示了如何在 Flux 脚本中使用正则表达式。
1、Go 正则表达式语法
Flux 使用 Go 的 regexp 包进行正则表达式搜索。
2、正则表达式运算符
Flux 提供了两个用于正则表达式的比较运算符。
- =~:当左边的表达式匹配右边的正则表达式时,它的计算结果为真。
- !~:当左边的表达式与右边的正则表达式不匹配时,它的计算结果为真。
3、Flux中的正则表达式
在 Flux 脚本中使用正则表达式匹配时,用 / 将正则表达式括起来。以下是基本的正则表达式比较语法:
expression =~ /regex/
expression !~ /regex/
4、例子
1)使用正则表达式按标签值过滤:以下示例按 cpu 标签过滤记录。它只保留 cpu 为 cpu0、cpu1 或 cpu2 的记录。
from(bucket: "db/rp")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_user" and r.cpu =~ /cpu[0-2]/)
2)使用正则表达式按字段键过滤:以下示例排除了字段键中没有 _percent 的记录。
from(bucket: "db/rp")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "mem" and r._field =~ /_percent/)
3)删除与正则表达式匹配的列:以下示例删除名称不带 _ 的列。
from(bucket: "db/rp")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "mem")
|> drop(fn: (column) => column !~ /_.*/)
例子:
data
|> filter(fn: (r) => r.tag =~ /^foo[1-3]/)
输入:
| _time | tag | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | foo1 | 1.0 |
| 2020-01-01T00:02:00Z | foo5 | 1.2 |
| 2020-01-01T00:03:00Z | bar3 | 1.8 |
| 2020-01-01T00:04:00Z | foo3 | 0.9 |
| 2020-01-01T00:05:00Z | foo2 | 1.4 |
| 2020-01-01T00:06:00Z | bar1 | 2.0 |
输出:
| _time | tag | _value |
|---|---|---|
| 2020-01-01T00:01:00Z | foo1 | 1.0 |
| 2020-01-01T00:04:00Z | foo3 | 0.9 |
| 2020-01-01T00:05:00Z | foo2 | 1.4 |
4.8.24、地理时态数据
使用 Flux Geo 包过滤地理时态数据并按地理位置或轨迹分组。Geo 软件包是实验性的,可能随时更改。使用它,即表示您同意实验功能的风险。
要使用地理时态数据:
- 导入experimental/geo包。
import "experimental/geo" - 加载地时数据。有关示例地时数据,请参见下文。
- 执行以下一项或多项操作:① 形状数据与Geo包一起使用;② 按区域过滤数据(使用严格或非严格过滤器);③ 按区域或按轨道对数据进行分组。
1、形状数据与Geo包一起使用:Flux Geo 包中的函数需要 lat 和 lon 字段以及 s2_cell_id 标签。重命名纬度和经度字段并生成 S2 小区 ID 令牌。
import "experimental/geo"
sampleGeoData
|> geo.shapeData(latField: "latitude", lonField: "longitude", level: 10)
2、按区域过滤时空数据:使用 geo.filterRows 函数按箱形、圆形或多边形地理区域过滤地理时态数据。
import "experimental/geo"
sampleGeoData
|> geo.filterRows(
region: {lat: 30.04, lon: 31.23, radius: 200.0},
strict: true
)
3、分组地时数据:使用 geo.groupByArea() 按区域对地理时态数据进行分组,使用 geo.asTracks() 将数据分组为轨迹或路线。
import "experimental/geo"
sampleGeoData
|> geo.groupByArea(newColumn: "geoArea", level: 5)
|> geo.asTracks(groupBy: ["id"],orderBy: ["_time"])
》样本数据:本节中的许多示例都使用了一个 sampleGeoData 变量,该变量表示地理时态数据的样本集。 GitHub 上的 Bird Migration Sample Data 提供了满足 Flux Geo 包要求的示例地理时态数据。
1)加载带注释的CSV样本数据:使用实验性 csv.from() 函数从 GitHub 加载样本鸟迁徙注释 CSV 数据:
import `experimental/csv`
sampleGeoData = csv.from(
url: "https://github.com/influxdata/influxdb2-sample-data/blob/master/bird-migration-data/bird-migration.csv"
)
csv.from(url: ...) 每次执行查询时都会下载示例数据 (~1.3 MB)。如果带宽是一个问题,使用 to() 函数将数据写入存储桶,然后使用 from() 查询存储桶。
2)使用线路协议将样本数据写入InfluxDB:使用 curl 和 influx write 命令将鸟类迁徙线路协议写入 InfluxDB。将 db/rp 替换为您的目标存储桶:
curl https://raw.githubusercontent.com/influxdata/influxdb2-sample-data/master/bird-migration-data/bird-migration.line --output ./tmp-data
influx write -b db/rp @./tmp-data
rm -f ./tmp-data使用 Flux 查询鸟类迁徙数据并将其分配给 sampleGeoData 变量:
sampleGeoData = from(bucket: "db/rp")
|> range(start: 2019-01-01T00:00:00Z, stop: 2019-12-31T23:59:59Z)
|> filter(fn: (r) => r._measurement == "migration")
5、优化Flux查询
5.1、使用pushdowns启动查询
pushdowns是将数据操作推送到底层数据源而不是对内存中的数据进行操作的函数或函数组合。使用pushdowns启动查询以提高查询性能。一旦非pushdowns函数运行,Flux 会将数据拉入内存并在那里运行所有后续操作。
5.1.1、下推功能和功能组合
InfluxDB Enterprise 1.9+ 支持以下下推。
| Functions | Supported |
|---|---|
| count() | √ |
| drop() | √ |
| duplicate() | √ |
| filter() * | √ |
| fill() | √ |
| first() | √ |
| group() | √ |
| keep() | √ |
| last() | √ |
| max() | √ |
| mean() | √ |
| min() | √ |
| range() | √ |
| rename() | √ |
| sum() | √ |
| window() | √ |
| Function combinations | |
| window() |> count() | √ |
| window() |> first() | √ |
| window() |> last() | √ |
| window() |> max() | √ |
| window() |> min() | √ |
| window() |> sum() | √ |
* filter() 仅在所有参数值为静态时下推。请参阅避免内联处理过滤器。
在查询开始时使用下推函数和函数组合。一旦非下推函数运行,Flux 会将数据拉入内存并在那里运行所有后续操作。
下推使用中的函数:
from(bucket: "db/rp")
|> range(start: -1h) //
|> filter(fn: (r) => r.sensor == "abc123") //
|> group(columns: ["_field", "host"]) // Pushed to the data source
|> aggregateWindow(every: 5m, fn: max) //
|> filter(fn: (r) => r._value >= 90.0) //
|> top(n: 10) // Run in memory5.2、避免内联过滤处理器
避免使用数学运算或内联字符串操作来定义数据过滤器。内联处理过滤器值可防止 filter() 将其操作下推到底层数据源,因此前一个函数返回的数据会加载到内存中。这通常会导致严重的性能损失。
例如,以下查询使用 Chronograf 仪表板模板变量和字符串连接来定义要过滤的区域。因为 filter() 使用内联字符串连接,所以它无法将其操作推送到底层数据源并将从 range() 返回的所有数据加载到内存中。
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r.region == v.provider + v.region)
要动态设置过滤器并保持 filter() 函数的下推能力,请使用变量在 filter() 之外定义过滤器值:
region = v.provider + v.region
from(bucket: "db/rp")
|> range(start: -1h)
|> filter(fn: (r) => r.region == region)
5.3、避免短窗口持续时间
开窗(根据时间间隔对数据进行分组)通常用于聚合和下采样数据。通过避免较短的窗口持续时间来提高性能。更多的窗口需要更多的计算能力来评估每行应该分配到哪个窗口。合理的窗口时长取决于查询的总时间范围。
5.4、谨慎使用“繁重”的函数
以下函数比其他函数使用更多的内存或 CPU。在使用它们之前,请考虑它们在您的数据处理中的必要性:
- map();
- reduce();
- join();
- union();
- pivot();
5.5、尽可能使用set()而不是map()
set()、experimental.set() 和 map 都可以设置数据中的列值,但是 set 函数比 map() 具有性能优势。使用以下准则来确定使用哪个:
- 如果将列值设置为预定义的静态值,请使用 set() 或 experimental.set()。
- 如果使用现有行数据动态设置列值,请使用 map()。
1、将列值设置为静态值:以下查询在功能上相同,但使用 set() 比使用 map() 更高效。
data
|> map(fn: (r) => ({ r with foo: "bar" }))
// Recommended
data
|> set(key: "foo", value: "bar")
2、使用现有行数据动态设置列值
data
|> map(fn: (r) => ({ r with foo: r.bar }))
5.6、平衡时间范围和数据精度
为确保查询是高性能的,请平衡数据的时间范围和精度。例如,如果您查询每秒存储的数据并请求六个月的数据,则每个系列的结果将包括约 1550 万个点。根据 filter()(cardinality) 之后返回的序列数,这很快就会变成数十亿个点。 Flux 必须将这些点存储在内存中以生成响应。使用下推优化内存中存储的点数。
5.7、使用Flux分析器测量查询性能
使用 Flux Profiler 包测量查询性能并将性能指标附加到查询输出中。以下Flux分析器可用:
- query:提供有关整个 Flux 脚本执行的统计信息。
- operator:提供有关查询中每个操作的统计信息。
导入分析器包并使用 profile.enabledProfilers 选项启用分析器。
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
// Query to profile6、Flux vs InfluxQL
Flux 是 InfluxQL 和其他类似 SQL 的查询语言的替代品,用于查询和分析数据。 Flux 使用函数式语言模式,使其非常强大、灵活,并且能够克服 InfluxQL 的许多限制。本文概述了使用 Flux 而不是 InfluxQL 可能执行的许多任务,并提供有关 Flux 和 InfluxQL 奇偶校验的信息。
6.1、可以使用Flux的情形
6.1.1、Joins(连接)
InfluxQL 从不支持连接。它们可以使用 TICKscript 来完成,但即使是 TICKscript 的连接能力也是有限的。 Flux 的 join() 函数允许您连接来自任何存储桶、任何度量和任何列的数据,只要每个数据集都包含要连接它们的列。这为真正强大和有用的操作打开了大门。
dataStream1 = from(bucket: "bucket1")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "network" and r._field == "bytes-transferred")
dataStream2 = from(bucket: "bucket1")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "httpd" and r._field == "requests-per-sec")
join(tables: {d1: dataStream1, d2: dataStream2}, on: ["_time", "_stop", "_start", "host"])
6.1.2、跨测量数学
能够执行交叉测量连接还允许您使用来自单独测量的数据运行计算——这是 InfluxData 社区高度要求的功能。下面的示例从单独的测量、mem和processes中获取两个数据流,将它们连接起来,然后计算每个正在运行的进程使用的平均内存量:
// Memory used (in bytes)
memUsed = from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used")
// Total processes running
procTotal = from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "processes" and r._field == "total")
// Join memory used with total processes and calculate
// the average memory (in MB) used for running processes.
join(tables: {mem: memUsed, proc: procTotal}, on: ["_time", "_stop", "_start", "host"])
|> map(fn: (r) => ({_time: r._time, _value: r._value_mem / r._value_proc / 1000000}))
6.1.3、按标签排序
InfluxQL 的排序功能非常有限,只允许您使用 ORDER BY 时间子句控制时间的排序顺序。 Flux 的 sort() 函数根据列列表对记录进行排序。根据列类型,记录按字典顺序、数字顺序或时间顺序排序。
from(bucket: "telegraf/autogen")
|> range(start: -12h)
|> filter(fn: (r) => r._measurement == "system" and r._field == "uptime")
|> sort(columns: ["region", "host", "_value"])
6.1.4、按任意列分组
InfluxQL 允许您按标签或按时间间隔分组,但仅此而已。 Flux 允许您按数据集中的任何列进行分组,包括 _value。使用 Flux group() 函数定义对数据进行分组的列。
from(bucket:"telegraf/autogen")
|> range(start:-12h)
|> filter(fn: (r) => r._measurement == "system" and r._field == "uptime" )
|> group(columns:["host", "_value"])
6.1.5、按日历月和年的窗口
InfluxQL 不支持按日历月和年的窗口数据,因为它们的长度不同。 Flux 支持日历月和年的持续时间单位(1mo、1y),并允许您按日历月和年窗口和聚合数据。
from(bucket:"telegraf/autogen")
|> range(start:-1y)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent" )
|> aggregateWindow(every: 1mo, fn: mean)
6.1.6、使用多个数据源
InfluxQL 只能查询存储在 InfluxDB 中的数据。 Flux 可以从 CSV、PostgreSQL、MySQL、Google BigTable 等其他数据源查询数据。将该数据与 InfluxDB 中的数据相结合,以丰富查询结果。
import "csv"
import "sql"
csvData = csv.from(csv: rawCSV)
sqlData = sql.from(
driverName: "postgres",
dataSourceName: "postgresql://user:password@localhost",
query: "SELECT * FROM example_table",
)
data = from(bucket: "telegraf/autogen")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "sensor")
auxData = join(tables: {csv: csvData, sql: sqlData}, on: ["sensor_id"])
enrichedData = join(tables: {data: data, aux: auxData}, on: ["sensor_id"])
enrichedData
|> yield(name: "enriched_data")
6.1.7、类DatePart查询
InfluxQL 不支持仅在一天中的指定时间返回结果的类似 DatePart 的查询。 Flux hourSelection 函数仅返回时间值在指定小时范围内的数据。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r.cpu == "cpu-total")
|> hourSelection(start: 9, stop: 17)
6.1.8、Pivot
InfluxQL 从未支持透视数据表。 Flux pivot() 函数提供了通过指定 rowKey、columnKey 和 valueColumn 参数来透视数据表的能力。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "cpu" and r.cpu == "cpu-total")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
6.1.9、直方图
生成直方图的能力一直是 InfluxQL 非常需要的功能,但从未得到支持。 Flux 的 histogram() 函数使用输入数据生成累积直方图,并支持未来的其他直方图类型。
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> histogram(buckets: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100,])
6.1.10、协方差
Flux 提供了简单的协方差计算函数。 covariance() 函数计算两列之间的协方差,cov() 函数计算两个数据流之间的协方差。
1、两列之间的协方差
from(bucket: "telegraf/autogen")
|> range(start: -5m)
|> covariance(columns: ["x", "y"])
2、两个数据流之间的协方差
table1 = from(bucket: "telegraf/autogen")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "measurement_1")
table2 = from(bucket: "telegraf/autogen")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "measurement_2")
cov(x: table1, y: table2, on: ["_time", "_field"])
6.1.11、将布尔值转换为整数
InfluxQL 支持类型转换,但仅适用于数字数据类型(浮点数到整数,反之亦然)。 Flux 类型转换函数为类型转换提供了更广泛的支持,并允许您执行一些长期请求的操作,例如将布尔值转换为整数。
1、将布尔字段值转换为整数
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "m" and r._field == "bool_field")
|> toInt()
6.1.12、字符串操作和数据整形
InfluxQL 在查询数据时不支持字符串操作。 Flux Strings 包是对字符串数据进行操作的函数集合。当与 map() 函数结合使用时,字符串包中的函数允许进行字符串清理和规范化等操作。
import "strings"
from(bucket: "telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "weather" and r._field == "temp")
|> map(
fn: (r) => ({
r with
location: strings.toTitle(v: r.location),
sensor: strings.replaceAll(v: r.sensor, t: " ", u: "-"),
status: strings.substring(v: r.status, start: 0, end: 8),
})
)
6.1.13、使用地时数据
import "experimental/geo"
from(bucket: "geo/autogen")
|> range(start: -1w)
|> filter(fn: (r) => r._measurement == "taxi")
|> geo.shapeData(latField: "latitude", lonField: "longitude", level: 20)
|> geo.filterRows(region: {lat: 40.69335938, lon: -73.30078125, radius: 20.0}, strict: true)
|> geo.asTracks(groupBy: ["fare-id"])
6.2、使用 InfluxQL 和 Flux parity
Flux 正在努力实现与 InfluxQL 的完全平等,并为此添加了新功能。下表显示了 InfluxQL 语句、子句和函数及其等效的 Flux 函数。
*to()函数只写入InfluxDB 2.0