文章目录
C++编译链接
在我还是个孩子的时候,我只会用IDE内置的编译器对源程序进行编译运行。或者是DEV-C++的F11,或者是VSCode的Ctrl+Alt+N,抑或是Visial Studio的Ctrl+Shift+B,只要轻轻一点,我们就能得到由源文件编译链接生成的可执行文件。而我,也从来没有想过这之间到底发生了什么,怎么就能得到可执行目标文件了。
而在我最近做编译原理实验时,遇到了瓶颈。编译原理第一次实验要求做一个词法分析器,我是按照书上的思路用C++(其实是C)实现的,而书上的程序将此分析器的实现拆分成了三个模块,第一个是scanner.h头文件,主要用于存储记号的数据结构、记号的种类、记号表以及对实现功能相关函数的声明(声明和定义的区别稍后会介绍),第二个是scannner.cpp,用于实现一些功能函数(即scanner.h中声明的那些函数)例如:初始化词法分析器、关闭词法分析器、识别记号、读取文件的一个字符等等,第三个是scannermain.cpp,用于实现main函数,调用scanner.cpp中实现的函数对词法分析器的功能进行测试。
好,上述的源代码都已经敲好了,我直接一个Run Code,然后就undefined reference to ××× ,报找不到函数的错误,再看
64-w64-mingw32/bin/ld.exe
是谁报的错,是链接器(GNU的链接器称为ld)。
为什么会报错,用脚丫子想一想,结果是显而易见的。我们进行的操作时Run Code是针对scannermain.cpp这个文件的,即整个编译链接过程只针对此文件,而此文件中所调用的函数在本文件中并没有定义,所以链接器找不到。
如何解决这个问题,那就是在编译scannermain.cpp的同时,也要编译scanner.cpp,这样链接器一连接就能找到对应的函数了,这些都离不开C++的分离式编译。
阅读须知:直到通过gcc/g++命令来看完整的编译链接过程最后一个模块开始时,文中提到的编译/编译链接都是统称,即经过一系列操作后生成可执行目标文件的整个过程称作编译/编译链接。而到最后一个部分,编译链接这个过程又被细分。
C++编译模式
分离式编译是个啥?
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件连接起来形成单一的可执行文件的过程
这个解释其实就是我上述所描述情况的解决办法。具体来说:
一个完整程序可以分成不同的模块放在不同的.cpp文件里。各.cpp文件里的东西相对独立,在其编译时不关心其他文件,只需要在编译成目标文件后再与其他的目标文件做一次链接就行了。比如,在文件test.cpp中定义了两个全局函数double sum(double, double);double divi(double, double),而在文件testmain.cpp中需要调用这两个函数。运用上述的概念,文件test.cpp和文件testmain.cpp并不需要知道对方的存在,而是可以分别地对它们进行编译,编译成目标文件之后再链接,就可以生成可执行目标文件了。
怎么实现上述过程?
在文件testmain.cpp中调用double sum(double, double);double divi(double, double)函数之前,声明一下两个函数即可。这是因为编译器在编译testmain.cpp的时候会生成一个符号表(symbol table),就像这两个函数一样的看不到定义的变量、函数会被存放在这个表中。再进行链接的时候,链接器就会在别的目标文件中去寻找这个变量或者函数的定义。一旦找到了,可执行目标文件就可以顺利地生成。
定义与声明
上述提到了两个概念“声明”与“定义”。
我之前从未意识到定义与声明的作用和意义,现在我意识到了。
C++ Primer上是这么说的:
为了允许把程序拆分成多个逻辑部分来编写,C++语言支持分离式编译(separatecompilation)机制,该机制允许将程序分割为若干个文件,每个文件可被独立编译。
如果将程序分为多个文件,则需要有在文件间共享代码的方法。例如,一个文件的代码可能需要使用另一个文件中定义的变量。一个实际的例子是std: :cout和std::cin,它们定义于标准库,却能被我们写的程序使用。
为了支持分离式编译,C++语言将声明和定义区分开来。声明(declaration)使得名字为程序所知,一个文件如果想使用别处定义的名字则必须包含对那个名字的声明。而定义(definition)负责创建与名字关联的实体。
变量声明规定了变量的类型和名字,在这一点上定义与之相同。但是除此之外,定义还申请存储空间,也可能会为变量赋一个初始值。
如果想声明一个变量而非定义它,就在变量名前添加关键字extern,而且不要显式地初始化变量:
extern int i; //声明i而非定义 int j; //声明并定义j任何包含了显式初始化的声明即成为定义。我们能给由extern关键字标记的变量赋一个初始值,但是这么做也就抵消了extern的作用。extern语句如果包含初始值就不再是声明,而变成定义了:
extern double pi = 3.1416; //定义在函数体内部,如果试图初始化一个由extern关键字标记的变量,将引发错误。
简单地说,“定义”就是把一个符号完完整整地描述出来:它是变量还是函数,返回什么类型,需要什么参数等等。而“声明”则只是声明这个符号的存在,即告诉编译器,这个符号是在其他文件中定义的,我这里先用着,你链接的时候再到别的地方去找找看它到底是什么吧。定义的时候要按C++语法完整地定义一个符号(变量或者函数),而声明的时候就只需要写出这个符号的原型了。
一个变量或者函数,在整个程序中可以被声明多次,但能且仅能被定义一次。反过来想,如果一个符号出现了两种不同的定义,编译器该听谁的?全都乱套了。
引出新的问题
现在有这么一个很常用的函数void f() {},在一个完整程序中的许多.cpp文件中都会被调用。运用上面的机制,我们只需要在一个文件中定义这个函数,而在其他的文件中声明这个函数。可是现在就这一个函数,一句声明就能解决,如果是在工程文件中呢?那么多使用率高的函数,需要我们一个个去声明吗?
聪明的人类当然会为自己的懒惰开脱,于是便有了头文件。
头文件有关
头文件用来干啥?
所谓头文件,其内容跟.cpp文件中的内容是一样的,都是C++的源代码。但头文件不用被编译。我们不再一条一条的去声明变量和函数,而是把声明全部放进一个头文件中,当某一个.cpp源文件需要这些声明时,就可以通过一个宏命令#include将头文件包含进这个.cpp文件中。
include
通过上述的例子来具体说明吧。
现在我们有一个test.h文件,是对两个函数double sum(double, double);double divi(double, double)的声明。
/*test.h*/
extern double sum(double, double);
extern double divi(double, double);
然后test.cpp是对这两个函数的实现:
/*scanner.cpp*/
#include "test.h" //可加可不加
double sum(double a ,double b){
double c = a + b;
return c;
}
double divi(double a, double b){
double c = a / b;
return c;
}
而testmain.cpp是对这两个函数的调用:
/*testmain.cpp*/
#include "test.h" //自己定义的头文件用引号
#include <stdio.h>
#include <stdlib.h>
int main(){
double a = sum(114, 514); //int->double的隐式转换
double b = divi(1919, 810);
printf("a = %f, b = %f",a,b);
system("pause");
}
程序目录结构如下:
├── testmain.cpp
├── test.h
└── test.c
include 是一个来自C语言的宏命令,它在编译器进行编译之前,即在预编译的时候起作用。#include的作用是把它后面所写文件的内容,完全copy到到当前的文件中来,是非常单纯的文本替换。因此,testmain.cpp文件中的第一句#include "test.h" ,在编译之前就会被替换成test.h文件的内容。即在编译过程将要开始的时候,testmain.cpp的内容已经发生了改变:
/*testmain.cpp*/
#include <stdio.h>
#include <stdlib.h>
extern double sum(double, double);
extern double divi(double, double);
int main(){
double a = sum(114, 514); //int->double的隐式转换
double b = divi(1919, 810);
printf("a = %f, b = %f",a,b);
system("pause");
}
如果除了testmain.cpp以外,还有其他的很多.cpp文件也用到了这两个函数,那么也通通只需要在使用这两个函数前写上一句#include "test.h" 就行了。
头文件中应该写什么?
通过上述可知,头文件的作用就是被其他.cpp文件包含进去的,它们本身并不参与编译。但实际上由于它们的内容被包含在在多个.cpp文件中,所以在编译.cpp文件时头文件中的内容实际上也得到了编译。通过“定义只能有一次”的规则,可以知道头文件中应该只放变量和函数的声明,而不能放它们的定义。无数的.cpp都会包含头文件,就意味着头文件内容都会被编译,如果放了定义,那么也就相当于在无数个文件中出现了对于变量或函数的定义,编译器就会报错redefinition。
雪崩时没有一片雪花是无辜的 --------《伏尔泰语录》
但是,凡事总有例外。头文件中可以写下述三种符号的定义。
-
头文件中可以写
const对象的定义。全局的const对象默认是没有extern的声明的,所以它只在当前文件中有效。把这样的对象写进头文件中,即使它被包含到其他多个.cpp文件中,这个对象也都只在包含它的那个文件中有效,对其他文件来说是不可见的,所以不会导致多重定义。所以,举一反三一下,对于C,static对象的定义和C++的private对象是不是也可以放在头文件中呢? -
头文件中可以写内联函数(inline)的定义。
插播一条广告,什么是内联函数?(当初在看C++ Primer的时候没有理解,书上也是一笔带过,现在又看了一遍)
将函数指定为内联函数,通常就是将它在每个调用点上“内联地”展开
其实就把它想象成跟include头文件一样的copy作用就好,就是在执行内联函数的地方把它替换为函数体。
这牵扯到一个函数调用机制。inline函数需要编译器在遇到它的地方根据它的定义把它内联展开的,而并非是普通函数那样可以先声明再链接的(内联函数不会链接),所以编译器就需要在编译时看到内联函数的完整定义才行。如果内联函数像普通函数一样只能定义一次的话,那内联函数根本没有意义,我不可能那么多文件只使用一次内联函数。因此C++规定,内联函数可以在程序中定义多次,只要内联函数在一个
.cpp文件中只出现一次,并且在所有的.cpp文件中,这个内联函数的定义是一样的,就是合法的。 -
头文件中可以写类(class)的定义。在程序中创建一个类的对象时,编译器只有在这个类的定义完全可见的情况下,才能知道这个类的对象应该如何布局。把类的定义放进头文件,在使用到这个类的.
cpp文件中去包含这个头文件,是很好的做法。类的定义中包含着数据成员和函数成员。数据成员是要等到具体的对象被创建时才会被定义(分配空间),但函数成员却是需要在一开始就被定义的,这也就是通常所说的类的实现。一般的做法是,把类的定义放在头文件中,而把函数成员的实现代码放在一个.cpp文件中(事实上我也是这么做的,在用C++编写游戏的过程中,都是一个类头文件对应一个.cpp文件,至于为什么用VS进行编译时没有产生与分离式编译有关的问题,这个文章最后提及)。除此之外还有另一种办法。就是直接把函数成员的实现代码也写进类定义里面。在C++的类中,如果函数成员在类的定义体中被定义,那么编译器会视这个函数为内联的。因此,把函数成员的定义写进类定义体,一起放进头文件中,也是合法。注意一下,如果把函数成员的定义写在类定义的头文件中并且写在了类外, 这是不合法的,因为这个函数成员此时就不是内联的了。一旦头文件被两个或两个以上的.cpp文件包含,这个函数成员就被重定义了。
#ifndef
紧接上文,如果头文件中只包含声明语句的话,它被同一个.cpp文件包含一伯次都没问题,因为可以声明多次。然而上面讨论到的头文件中的三个例外也是头文件很常见用处。因为其是定义,所以不能被多个.cpp文件包含,如何避免呢?
这就要用到#ifndef。#ifndef的作用:防止多个源文件同时包含同一个头文件时产生的定义冲突。
一般格式:
#ifndef <标识>
#define <标识>
...
...
#endif
<标识>在理论上来说可以是自由命名的,但每个头文件的这个<标识>都应该是唯一的。标识的命名规则一般是头文件名全大写,前后加下划线,并把文件名中的“.”也变成下划线,如例子中的test.h:
#ifndef _TEST_H_
#define _TEST_H_
extern double sum(double, double);
extern double divi(double, double);
#endif
通过gcc/g++命令来看完整的编译链接过程
说了这么多,好像还是都在说C++的分离式编译,具体编译链接过程中具体发生了啥还没探究。而上述的概念对接下来的编译链接过程做了很好的铺垫。
为了更好的说明,用GCC下面的gcc和g++编译器对上面的例子进行演示。
GNU是操作系统。
GCC是GNU Compiler Collection即GNU下的编译器集合
gcc是c语言编译器
g++是c++编译器
目前的目录结构:
通过g++编译:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UpRhFtRW-1669212816501)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20221123211152946.png)]](https://img-blog.csdnimg.cn/48942fab09b84b7f918edf8988412b23.png)
可见生成了可执行目标文件a.exe(由于没有指定可执行文件的名字,默认为a)。看起来很容易,事实真的是这样吗?编译原理课本上描述的语言之间的翻译(高级语言转换成机器语言)需要经过三步:预处理、编译、汇编,这只是转换成了机器语言,距离可执行文件还差一步:链接。而上述g++命令其实就是依次执行了这四个步骤:预处理、编译、汇编、链接。
预处理(Preprocessing)
预处理用于将所有的#include头文件以及宏定义替换成其真正的内容,预处理之后得到的仍然是文本文件,但文件体积会大很多。g++的预处理是预处理器cpp来完成的,可以通过如下命令对testmain.cpp进行预处理:
g++ -E testmain.cpp -o testmain.i

上述命令中-E是让编译器在预处理之后就退出,不进行后续编译过程;-o指定输出文件名。
由上图也知经过预处理之后代码体积会大很多。
预处理之后的程序还是文本,可以用文本编辑器打开。
编译(Compilation)
这里的编译不是指程序从源文件到二进制程序的全部过程,而是指将经过预处理之后的程序转换成特定汇编代码(assembly code)的过程。编译的指定如下:
g++ -S testmain.i -o testmain.s
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FILbLWED-1669212816502)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20221123212942669.png)]](https://img-blog.csdnimg.cn/d551b27457624440a637ccbbdb673282.png)
上述命令中-S让编译器在编译之后停止,不进行后续过程。编译过程完成后,将生成程序的汇编代码命名为testmain.s,这也是文本文件,可见已经转换成了汇编代码。
汇编(Assemble)
汇编过程将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件,是二进制格式。g++汇编过程通过汇编器as命令完成:
g++ -c testmain.s -o testmain.o

这一步生成的文件时可重定位目标文件,后缀为.o或者.obj,每一个程序相关的源文件都要生成这么一个目标文件以用于接下来的链接操作。
同时由于此文件已经时二进制格式,不能再用文本编辑器打开。用010editor打开,已经看不懂了(废话,能看懂你就是机器了)
链接(Linking)
链接过程将多个目标文以及所需的库文件链接成最终的可执行文件(executable file)(linux系统下为ELF)。
命令如下:
g++ -o testmain.o test.o //将所有源程序的.o文件一同链接
链接的详细过程如下:
合并段
在ELF文件中字节对齐是以4字节对齐的,在可执行程序中是以页的方式对齐的,因此如果在链接时将各个.o文件各个段单独的加载到可执行文件中,将会非常浪费空间:
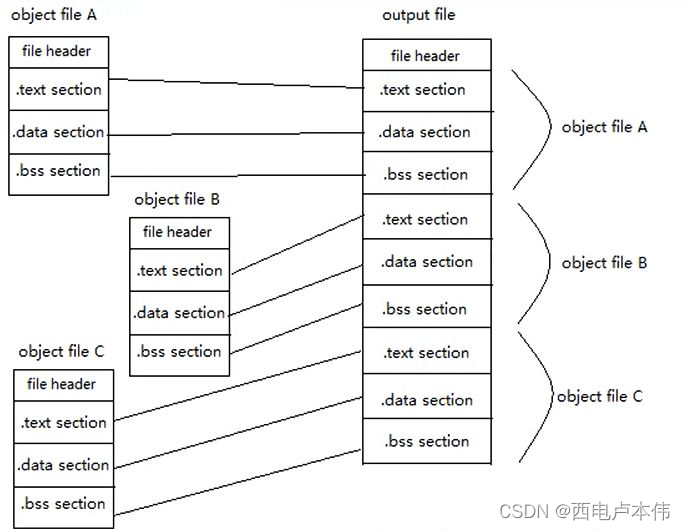
因此需要合并段,调整段偏移,把每个.o文件的.text段合并在一起,.data段合并在一起,这样在生成的可执行文件中,各个段都只有一个,由于在链接时只需要加载代码段(.text段)和数据段(.data段和.bss段)。因此合并段之后,在系统给我们分配内存时,只需要分配两个页面大小就可以,分别存放代码和数据。
汇总所有符号
每个.obj文件在编译时都会生成自己的符号表,我们要把这些符号都合并起来进行符号解析。即文章最开头说的,先把调用了而未定义的符号存到符号表中,在链接时候由链接器去找。这个过程实际就是链接器针对.o文件执行的。
完成符号的重定位
在进行合并段,调整段偏移时,输入文件的各个段在连接后的虚拟地址就已经确定了,这一步完成后,连接器开始计算各个符号的虚拟地址,因为各个符号在段内的相对位置是固定的,所以段内各个符号的地址也已经是确定的了,只不过连接器需要给每个符号加上一个偏移量,使他们能够调整到正确的虚拟地址,这就是符号的重定位过程。在ELF文件中,有一个叫重定位表的结构专门用来保存这些与从定位有关的信息,重定位表在ELF文件中往往是一个或多个段。由于笔者对此了解甚少,不做过多解释。
简单的方式呢
综上,一个完成程序的编译链接过程如下:
.cpp经过预处理成.i文件,经过编译成.s文件,经过汇编成.o文件,数个.o文件链接成可执行文件(.exe)
头文件在编译前就已经展开,故不用编译。与前面多次的阐明一致。
上述编译链接过程大可不必如此繁琐,分离式编译我们可以通过g++一步完成:
g++ test.cpp testmain.cpp
或者,通过makefile:
test:test.o testmain.o
g++ -o test test.o testmain.o
test.o:test.cpp
g++ -c test.cpp
testmain.o:testmain.cpp
gcc -c testmain.cpp
事实上就是将g++命令写道一个文件中,使用mingw32-make执行文件:

还有最后一个问题:我在编写游戏的过程中,有那么多的类头文件定义与源文件,而为什么我只需要按一下Ctrl+Shift+B就能编译,并成功运行呢?
事实是:Visual Studio包含了一个组件:VC/VC++,而在VC中,只需要将所有工程文件都包括在project中,VC会自动把makefile写好,用makefile实现分离式编译。
…突然就感觉一切都好神奇