
Title: YONA: You Only Need One Adjacent Reference-frame for Accurate and Fast Video Polyp Detection
Paper: https://arxiv.org/pdf/2306.03686.pdf
导读
结肠镜视频对于辅助临床直肠癌诊断非常重要,因为相比静态图像,结肠镜视频包含更丰富的信息。然而,与常见的固定摄像头视频不同,结肠镜视频中的摄像头移动会引起快速的画面抖动,导致现有的视频检测模型训练不稳定。
为了解决这个问题,本文提出了一种名为YONA, You Only Need one Adjacent Reference-frame的方法,这是一个高效的端到端训练框架,用于视频息肉检测。YONA 利用前一帧与当前帧的信息,不需要多帧协作就能对当前帧进行息肉检测。具体而言,对于前景部分,YONA 根据前景的相似性,自适应地将当前帧的通道激活模式与相邻参考帧进行对齐。对于背景部分,YONA 则通过帧间差异进行背景动态对齐,消除由于剧烈空间抖动产生的无效特征。此外,在训练过程中,YONA 应用了跨帧对比学习,并利用真实边界框信息来改进模型对息肉和背景的感知能力。
最终,研究人员在三个公开的具有挑战性的基准数据集上进行了定量和定性实验证明,所提方法在准确性和速度上都大大优于之前的最先进竞争方法。
背景
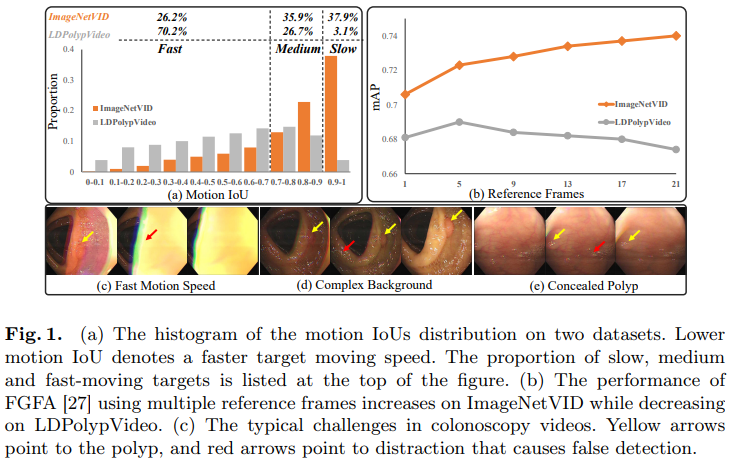
结合上图,我们简单分析下视频息肉分割的三大难点与挑战。
Fast motion speed
论文指出,在结肠镜视频中,目标的运动速度通常很快,相比自然视频数据集(如ImageNetVID),结肠镜视频数据集(如LDPolypVideo)中的大多数目标都处于高速运动状态。这导致了相邻前景特征的巨大差异,例如运动模糊或遮挡,如图1©所示。因此,作者推测,在息肉视频检测中过多地协作多帧将增加相邻帧之间的错位,导致检测性能较差。图1(b)展示了 FGFA 方法在增加参考帧数的情况下在两个数据集上的性能。两条曲线的不同趋势证实了这个假设。
Complex background
结肠镜视频与常见的固定摄像头视频不同,摄像头的移动会在相邻帧之间引入大的干扰(如镜面反射、气泡、水等),如图1(d)所示。这些异常情况破坏了背景结构的完整性,从而影响了多帧融合的效果。
Concealed polyps
如图1(e)所示,可以注意到在结肠镜视频中,有些息肉可能被视为隐藏的对象,因为这些息肉与肠壁具有非常相似的外观。模型在推理过程中会被这些帧所困惑,导致高假阳性或假阴性的预测结果。
方法
为了应对上述问题,论文提出了 YONA 框架,该框架充分利用了参考帧信息,并且仅需要一个相邻参考帧就能准确地进行视频息肉检测。具体而言,本文首先提出了前景时序对齐(FTA)模块,根据前景的相似性明确地对齐相邻特征之间的前景通道激活模式。此外,在 FTA 之后,论文设计了背景动态对齐(BDA)模块,进一步学习帧间背景的空间动态,以更好地消除运动速度的影响并增加训练的稳健性。最后,论文引入了跨帧辅助对比学习(CBCL),与 FTA 和 BDA 并行,充分利用边界框注释来扩大在嵌入空间中对息肉和背景的区分能力。


Foreground Temporal Alignment
如上所述,在结肠镜视频中,由于摄像头的高速移动,帧间的变化对前景和背景目标来说都非常剧烈。因此,多帧(参考帧数大于3)的融合可能会将更多的噪声特征引入到聚合特征中。另一方面,被遮挡或扭曲的前景上下文也会影响聚合结果的质量。因此,本文提出了利用仅一个相邻参考帧的前景上下文进行帧间时序对齐。

FTA 旨在将锚定特征的特定通道激活模式与其前面的参考特征进行对齐。首先,给定中间特征 Fa、Fr 和参考二值图 Mr,通过在空间维度上使用二值图对 Fr 进行池化操作,将其转化为一维通道模式 fr,并将其归一化到[0, 1]范围内。然后,利用通道注意机制计算注意力图,并通过加权点积将注意力图与原始锚定特征相结合,通过残差连接保持梯度流,从而获得增强的锚定特征。
需要注意的是,在训练阶段,使用参考帧的真实边界框生成二值图 Mr。在推理阶段,仅当参考帧的验证边界框存在时,才进行前景时序对齐。通过这种前景时序对齐的方式,有效的缓解快速运动对前景目标检测的影响,通过对锚定特征和前一个参考帧的对齐,从而提高了前景目标的检测性能。
简单理解,这里其实就是结合上一帧的信息对当前帧通过注意力机制的方式进行纠正。不过最上面那个 Pooling 会不会有点多余?毕竟又引入多一个超参出来。
由于视频抖动,相邻帧在时间上可能会快速变化,直接融合参考特征会引入噪声信息并误导训练。因此,论文设计了一种自适应重新加权的方法,通过衡量特征的相似性来确定参考特征对锚定特征的重要性。具体而言,如果参考帧的前景特征与锚定特征接近,那么在所有通道上将为其分配较大的权重。否则,将分配较小的权重。为了提高效率,作者直接采用余弦相似度度量来衡量相似性。

哦,原来是来判断“需要参考多少信息”。简单来说,alpha 参数用于根据参考特征和锚定特征之间的相似性动态地调整它们之间的权重,以更好地对齐特征并提高前景目标检测的准确性。大白话就是两帧图像越相似,就将这个 feature map 的权重调高,也说得过去,我们继续往下走。
Background Dynamic Alignment
传统的基于卷积的目标检测器在背景稳定的情况下能够良好地检测对象。然而,一旦接收到明显的干扰,如光照或阴影,背景的变化可能导致空间相关性的降低,并引发许多误报预测。受帧间差异方法的启发,该模块首先提取相邻背景内容的动态场,并借鉴可变形卷积的思想,根据动态场的强度学习内在的几何变换。(有点意思?)

在实践中,给定经过前景时序对齐模块得到的增强锚定特征 F˜ 和参考特征 Fr,我们先计算它们之间的帧间差异,即通过逐元素相减得到差异特征(这样直接相减稳妥吗?)。然后,对差异特征进行 1×1 卷积,生成动态场,它编码了相邻帧之间的所有空间动态变化(把光流的概念也引入进来了吗,哈哈哈)。最后,通过 3×3 的可变形卷积将动态场 D 嵌入到锚定特征中,得到最终的对齐锚定特征 F*。
最后,如图所示,在训练阶段,作者将增强的锚定特征输入到三个检测头,由3×3卷积和1×1卷积组成,产生用于检测损失的中心、尺寸和偏移特征。检测损失由中心损失、尺寸损失和偏移损失组成,并使用 focal loss和 L1 loss 进行加权。这块没什么好讲的,我们就不展开了。
总的来说,通过这个背景动态对齐的模块,作者试图提高在背景干扰下的目标检测性能,通过学习背景动态变化的几何变换,增强了锚定特征的表示能力。
Cross-frame Box-assisted Contrastive Learning
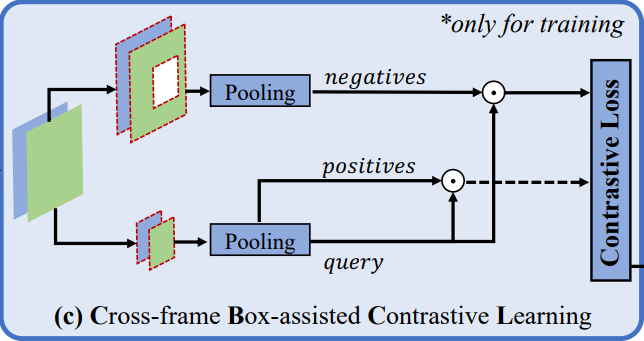
前面我们讲到,在结肠镜视频中,存在一些与肠壁非常相似的隐匿性息肉,因此我们需要一种高级的训练策略来区分这种同质性。跨帧框辅助对比学习模块,旨在通过对比学习来区分隐匿性息肉和肠壁的相似性,以提高模型的判别能力。这种辅助训练策略能够通过比较不同帧之间的特征相似性和差异性来促进模型的学习和泛化能力。
具体而言,受监督对比学习的最新研究启发,该模块选择两个帧上的前景和背景区域,并通过 GT 进行引导,以进行对比学习。在实践中,给定一批中间特征图 Fa、Fr 和相应的二进制图 Ma、Mr,我们首先在批处理级别上将锚定特征和参考特征进行级联(就是 concat 啦~),得到 F̂ 和 M̂。然后,根据 M̂ 中的 M̂ (x, y) = 1 和 M̂ (x, y) = 0,提取交叉帧特征 F̂ 的前景和背景通道模式(就是用一个阈值提取二值图像),并使用公式(1)进行计算。

然后,对于每个前景通道模式作为"query",随机选择另一个不同的前景特征作为"positive",而同一批次中的所有背景特征都被视为"negatives"。最后,通过 InfoNCE 算法计算一步对比损失,该损失用于衡量 “query” 和 “positive” 之间的相似性,以及 “query” 和 “negatives” 之间的差异。最后将所有步骤的损失求和得到最终的对比损失。
InfoNCE
InfoNCE, Normalized Cross Entropy 是一种用于对比学习的损失函数,它被广泛应用于自监督学习和无监督学习任务中。它的目标是通过最大化正样本与负样本之间的相似性,来鼓励模型学习到有意义的特征表示。
在对比学习中,InfoNCE 的计算过程如下:对于给定的一个查询样本(query),我们希望模型能够识别出与之相似的正样本(positive),并将其与其他不相似的负样本(negatives)区分开来。
具体而言,对于每个查询样本,我们计算其与正样本之间的相似性得分,并对所有负样本进行归一化指数函数运算,然后将得分进行归一化。最后,使用交叉熵损失函数,将正样本的得分与负样本的得分进行比较,以最大化正样本与负样本之间的差异。
InfoNCE 的数学公式如下:

其中,涉及到一个温度参数,用于控制相似性的平滑程度。最终,通过最小化 InfoNCE 损失,模型可以学习到更具区分性的特征表示,从而提高对比学习任务的性能。
实验
数据集
本文在三个主流公开的视频息肉检测基准数据集上评估了所提出的方法,分别是SUN Colonoscopy Video Database、LDPolypVideo和CVC-VideoClinicDB。这些数据集分别包含了大量的训练集和测试集帧数,用于测试算法的性能。
参数设置
本文骨干网络选取ResNet-50,并选择了CenterNet作为基础检测器。与 CenterNet 相同的设置中,作者设定了 λ s z i e = 0.1 \lambda_{szie} = 0.1 λszie=0.1 和 λ s z i e = 1 \lambda_{szie} = 1 λszie=1,用于控制目标尺寸和偏移的损失权重。对训练集图像进行随机裁剪和调整大小为 512×512,并使用 ImageNet 的归一化设置进行预处理。数据增强方面,采用了随机旋转和翻转操作。批量大小设置为 32。
此外,模型使用 Adam 优化器进行训练,权重衰减率为 5 × 10^(-4),训练时长为 64 个 epochs。初始学习率设定为 10^(-4),并采用余弦退火策略逐渐减小到 10^(-5)。超参数 λ c o n t r a s t \lambda{contrast} λcontrast 通过消融实验设定为 0.3。
效果
:::block-1

与 CenterNet 基线相比,YONA 模型通过三个创新设计显著提高了 F1 分数,分别在三个基准数据集上提升了9.2%、8.3%和7.4%,证明了模型设计的有效性。此外,与所有其他基于图像的最先进方法相比,YONA 在准确性和速度之间取得了最佳的平衡,适用于所有数据集。其次,对于基于视频的 SOTA ,先前的多帧合作的视频目标检测器在具有挑战性的数据集上缺乏准确检测的能力。具体而言,YONA 在三个数据集上的F1分数分别超过了次优的STFT方法2.2%、3.0%和1.3%,并且FPS达到33.8。
:::
:::block-1

如图所示,由于采用了一邻近帧的框架,YONA 不仅可以避免部分遮挡导致的误报(第1和第2个片段),还能够在严重的图像质量下捕捉到有用的信息(第2个片段)。此外,YONA 在具有挑战性的场景中,如隐匿性息肉(第3个片段),展现出了稳健的性能。
:::
总结
本文提出了一种名为 YONA 的新框架,用于准确和快速检测结肠镜视频中的息肉。该框架通过引入前景和背景对齐模块来处理快速运动情况下的特征,同时引入跨帧对比学习模块来增强模型对息肉和肠壁的区分能力。实验证明,YONA 在三个大规模公开视频息肉检测数据集上取得了最先进的性能。