文章目录
方案一,使用typora
第一步,编写python脚本
# -*- coding: utf-8 -*-
import os
import base64
# import markdown
import sys
from bs4 import BeautifulSoup
# 读取传入的当前文件夹目录,windows使用传参案例: python D:\xxxxx\223333.py %cd%
current_dir = sys.argv[1]
print("要转换的html所在目录path=" + current_dir)
directory = current_dir
# 循环浏览目录中的每个文件
for filename in os.listdir(directory):
if filename.endswith(".html"):
html_file_name = filename
with open(html_file_name, 'r', encoding='utf-8') as file:
html_content = file.read()
# 获取Markdown文件所在的文件夹路径
markdown_folder = os.path.dirname(os.path.abspath(html_file_name))
# 调整HTML中的图片路径,相对路径变成绝对路径
html_with_adjusted_image_paths = html_content.replace('src="', 'src="' + markdown_folder + '/')
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html_with_adjusted_image_paths, 'html.parser')
# 获取所有<img>标签
img_tags = soup.find_all('img')
# 遍历<img>标签
for img_tag in img_tags:
# 获取图片路径
image_path = img_tag['src']
# 读取图片文件并进行Base64编码
with open(image_path, 'rb') as file:
image_data = file.read()
base64_data = base64.b64encode(image_data).decode('utf-8')
# 替换<img>标签的src属性为Base64编码数据
img_tag['src'] = f'data:image/jpeg;base64,{
base64_data}'
# 获取修改后的HTML内容
modified_html = str(soup)
# 将调整后的HTML内容写入文件
# print(html_file_name)
html_file_name = current_dir + "/" + filename
# print(html_file_name)
with open(html_file_name, 'w', encoding='utf-8') as file:
file.write(modified_html)
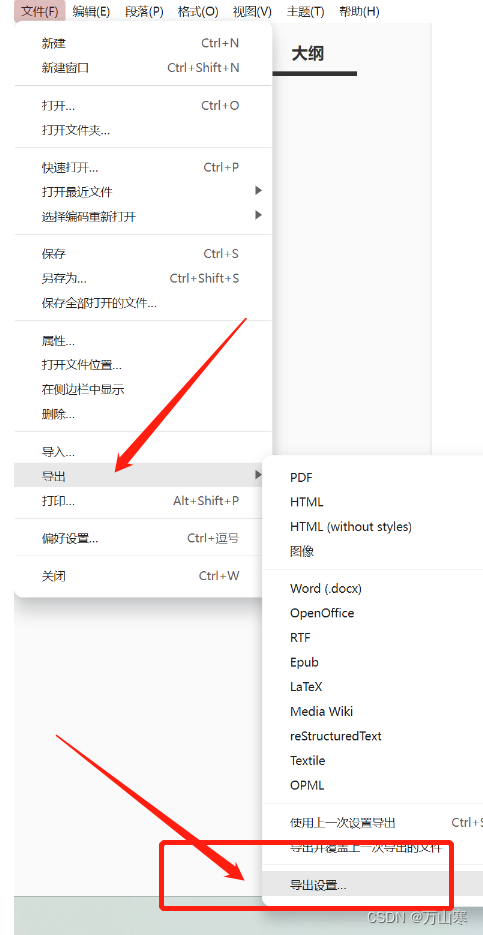
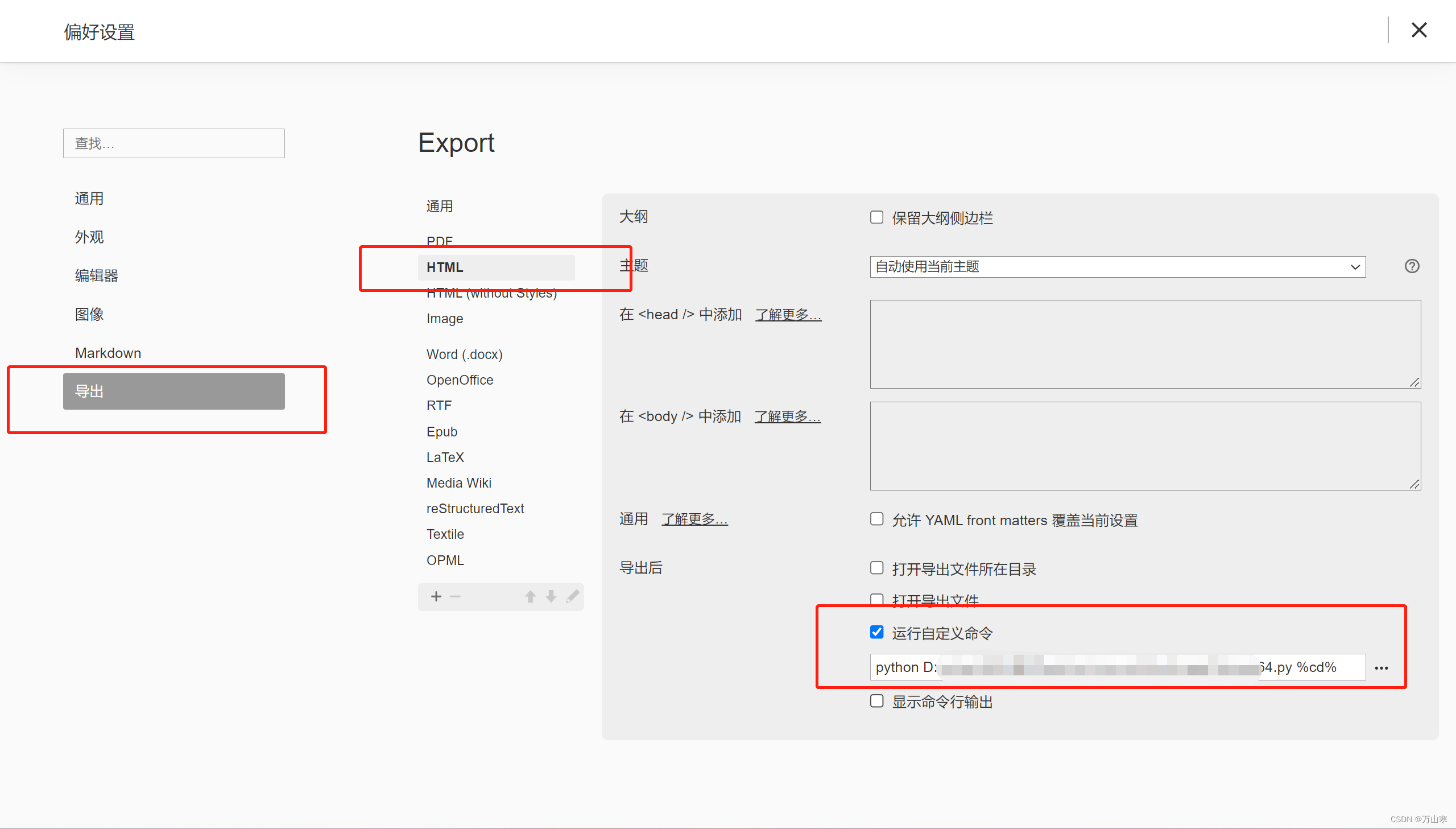
第二步,设置导出后运行py脚本,设置如下
方式二,使用vscode插件:Markdown Preview Enhanced
使用方法
在markdown头部添加
---
html:
# 这个值设置是否将image转换成base64字符串
embed_local_images: true
embed_svg: true
offline: false
# 这个值设置侧边栏
toc: true
print_background: false
---
预览界面右键,选择导出
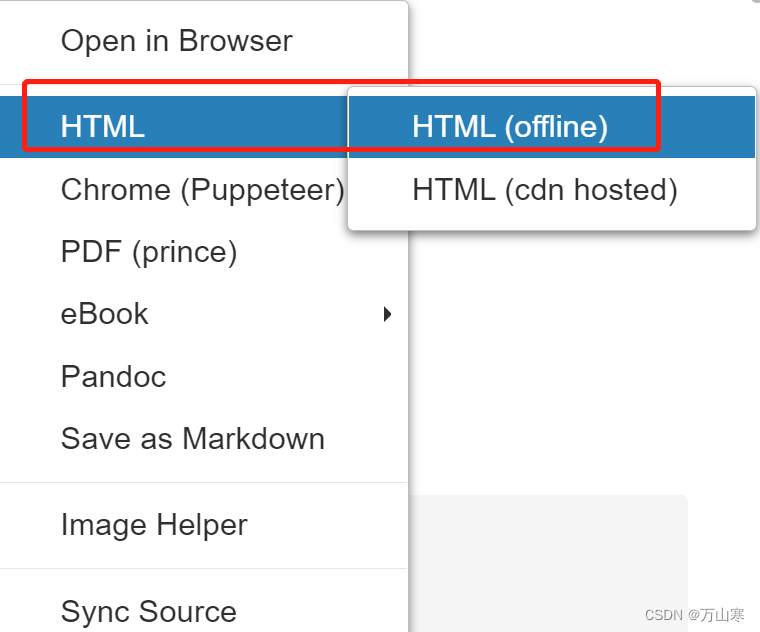
Markdown Preview Enhanced插件导出word
文档头部添加
---
title: "标题"
author: 作者
date: 时间
# 模型,word文档
output: word_document
#output:
# word_document:
# 输出路径
# path: /Exports/Habits.docx
---
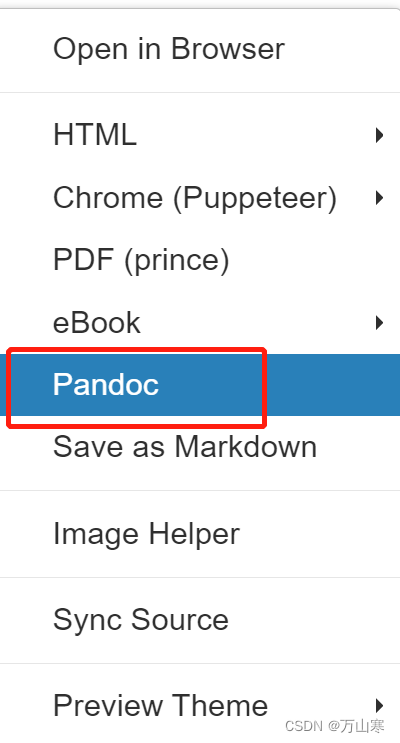
选择pandoc导出word