思路介绍
我们在工作或者生活中有没有碰到这种情况,就是我们需要对内容进行翻译,平时的时候我们是一句一句的粘贴翻译后在粘贴回来,针对这种情况 ,我们可以试着可以用代码的方式帮我们进行执行。方便又快捷
首页,我们来设计软件的开发逻辑和思路,大致的思路是这样的
既然这样 ,那我们就按照我们前期的思路来写代码,分步骤来实现这些功能,
一,分行读取文本内容:
这里我将代码粘贴至下面,代码会做注释
nenr = input("输入txt文件所在位置:") #将这里设置为用户自动输入
a=[]
with open(r"{}".format(nenr), "r") as f:
for line in f.readlines(): #加入循环,分行读取文本内的全部内容
line = line.strip('\n') # 去掉列表中每一个元素的换行符,后续等内容翻译好后存入文本时需要再加上换行符,不然我们存入的数据会堆积在一起
a.append(line) #将翻译的内容存入一个空的列表a
print(a) #打印a的内容执行效果

ok这里我们看到,这几行代码已经讲数据给提取出来了,以一个列表的方式给取出来了,其中,文本里的每一行的内容就是列表里的一个元素,
二,将内容分行提取后进行翻译并整理好我们需要的格式
我们将内容翻译出来后,这时就得想着,如何将内容给翻译好?这里我找到了一个第三方的翻译api,api的信息我就不粘贴了,后续有想要的可以私信我。我们看下如何实现这一步骤,代码如下:

import requests
nenr = input("输入txt文件所在位置:") #将这里设置为用户自动输入
a=[]
with open(r"{}".format(nenr), "r") as f:
for line in f.readlines(): #加入循环,分行读取文本内的全部内容
line = line.strip('\n') # 去掉列表中每一个元素的换行符,后续等内容翻译好后存入文本时需要再加上换行符,不然我们存入的数据会堆积在一起
a.append(line) #将翻译的内容存入一个空的列表a
b=[] #定义一个空列表b,这个列表是方便我们后续存入翻译后的内容
for x in a: #这里我们使用循环,将存入数据的列表a给分步骤翻译
a_1 = requests.get(url="http://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i=""{}".format(x)) #通过循环将列表的数据逐个翻译
b.append(a_1.json()["translateResult"][0][0]["tgt"] + "\n") #这里将翻译后的数据给提取出来,然后将这个数据存入空列表b中,这里记得再存入的时候加上划行符“\n”
print(b) #查看我们翻译后的内容ok,我们来看下执行效果

我们看到,这里我们已经将内容给翻译好了,既然翻译好了的话,我们就可以把翻译的内容给替换掉文本里的内容了
三,将翻译后的数据替换掉之前的数据
既然翻译好了,这时候我们就应该把翻译后的数据替换掉之前的数据才行,不让我们这样翻译和直接手动逐条翻译有什么区别咧
import requests
nenr = input("输入txt文件所在位置:") #将这里设置为用户自动输入
a=[]
with open(r"{}".format(nenr), "r") as f:
for line in f.readlines(): #加入循环,分行读取文本内的全部内容
line = line.strip('\n') # 去掉列表中每一个元素的换行符,后续等内容翻译好后存入文本时需要再加上换行符,不然我们存入的数据会堆积在一起
a.append(line) #将翻译的内容存入一个空的列表a
b=[] #定义一个空列表b,这个列表是方便我们后续存入翻译后的内容
for x in a: #这里我们使用循环,将存入数据的列表a给分步骤翻译
a_1 = requests.get(url="http://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i=""{}".format(x)) #通过循环将列表的数据逐个翻译
b.append(a_1.json()["translateResult"][0][0]["tgt"] + "\n") #这里将翻译后的数据给提取出来,然后将这个数据存入空列表b中,这里记得再存入的时候加上划行符“\n”
print(b) #查看我们翻译后的内容
file_handle = open(r"{}".format(nenr), mode='w')
file_handle.writelines(b) #将集合b存入文本里
file_handle.close() #数据存入后关闭文本我们来看下执行后的效果

不错不错,既然翻译好了 我们何不再加上其他的一些优化加强咧,比如 判断是否选择的是txt文件,或者是当txt文件是否存在 或者 我们可以把代码给打包成其他的一些内容,既然有思路了,我们就开始吧,
四,判断用户输入的是否是txt文件
这里我们要想判断用户输入的是不是txt文件时,我们可以直接判断后缀,如果用户输入的内容的末尾没有带上 .txt 这时,我们是否就可以判断用户输入的不是txt文件。有思路就通过代码实现,代码如下:
import os
import requests
nenr = input("输入txt文件所在位置:") #将这里设置为用户自动输入
a=[]
accs = os.path.splitext(r"{}".format(nenr))[1] in ['.txt'] #这行代码是将判断用户输入的内容末尾是否是.txt 如果是,则返回true
if accs == True: #这里我们加入判断,如果是返回的是true,则执行正常的代码:
with open(r"{}".format(nenr), "r") as f:
for line in f.readlines(): #加入循环,分行读取文本内的全部内容
line = line.strip('\n') # 去掉列表中每一个元素的换行符,后续等内容翻译好后存入文本时需要再加上换行符,不然我们存入的数据会堆积在一起
a.append(line) #将翻译的内容存入一个空的列表a
b=[] #定义一个空列表b,这个列表是方便我们后续存入翻译后的内容
for x in a: #这里我们使用循环,将存入数据的列表a给分步骤翻译
a_1 = requests.get(url="http://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i=""{}".format(x)) #通过循环将列表的数据逐个翻译
b.append(a_1.json()["translateResult"][0][0]["tgt"] + "\n") #这里将翻译后的数据给提取出来,然后将这个数据存入空列表b中,这里记得再存入的时候加上划行符“\n”
print(b) #查看我们翻译后的内容
file_handle = open(r"{}".format(nenr), mode='w')
file_handle.writelines(b) #将集合b存入文本里
file_handle.close() #数据存入后关闭文本
else:
print("请输入正确的文件类型") #当用户输入的内容不是txt文件时,则给出用户提示我们来看下执行后的效果:
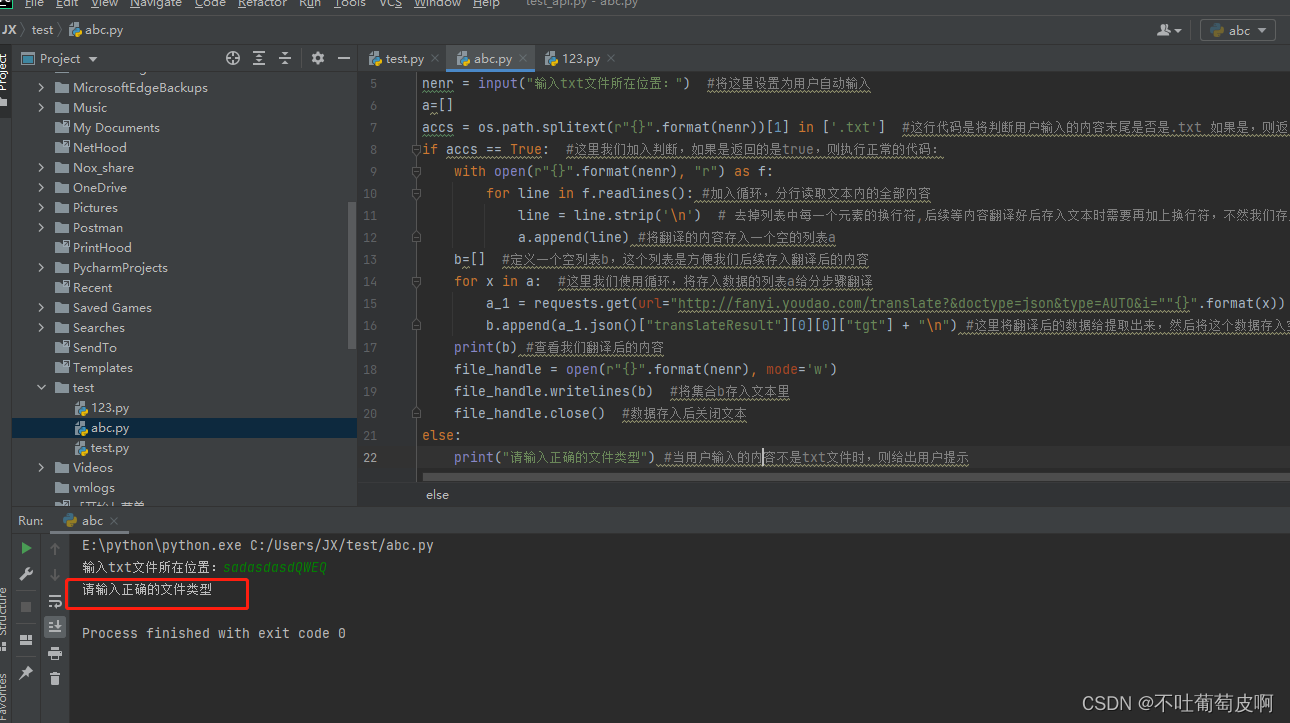
这里我们发现一个问题,当用户执行后,如果文件类型不正确就直接停止掉了,这样用户就需要重输入,对用户很不友好,咋办,我们加入循环,当用户执行成功后,代码翻译后,结束循环,如果文件类型不正确,那就重新循环,顺便,再给用户执行成功时加入一个提示
五,加入循环,提升用户体验
这里我们加入循环操作,提示用户体检,然后再给执行成功后加上提示,代码如下
import os
import requests
while True: #加入死循环,当翻译成功后结束循环,其他情况下一直循环
nenr = input("输入txt文件所在位置:") #将这里设置为用户自动输入
a=[]
b = [] #定义一个空列表b,这个列表是方便我们后续存入翻译后的内容
accs = os.path.splitext(r"{}".format(nenr))[1] in ['.txt'] #这行代码是将判断用户输入的内容末尾是否是.txt 如果是,则返回true
if accs == True: #这里我们加入判断,如果是返回的是true,则执行正常的代码:
with open(r"{}".format(nenr), "r") as f:
for line in f.readlines(): #加入循环,分行读取文本内的全部内容
line = line.strip('\n') # 去掉列表中每一个元素的换行符,后续等内容翻译好后存入文本时需要再加上换行符,不然我们存入的数据会堆积在一起
a.append(line) #将翻译的内容存入一个空的列表a
for x in a: #这里我们使用循环,将存入数据的列表a给分步骤翻译
a_1 = requests.get(url="http://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i=""{}".format(x)) #通过循环将列表的数据逐个翻译
b.append(a_1.json()["translateResult"][0][0]["tgt"] + "\n") #这里将翻译后的数据给提取出来,然后将这个数据存入空列表b中,这里记得再存入的时候加上划行符“\n”
print(b) #查看我们翻译后的内容
file_handle = open(r"{}".format(nenr), mode='w')
file_handle.writelines(b) #将集合b存入文本里
file_handle.close() #数据存入后关闭文本
print("翻译成功,请至文件夹内查看") #翻译成功后提示
break #翻译成功后结束循环
else:
print("请输入正确的文件类型") #当用户输入的内容不是txt文件时,则给出用户提示执行效果如下:

这里我们看到,执行效果不错,既然这样的话,我们何不给代码打过包,提升软件的实用性,让其他电脑上没装python的同事也能使用?
六,打包
这里我们使用的是python的打包模块pyinstaller,我太饿了,打包模块的使用方法我就不多说了,后续有啥问题或者其他情况可以私聊或者评论,我都会回复
打包代码:pyinstaller -F -i acc.ico abcc.py
打包后的效果

执行的效果:
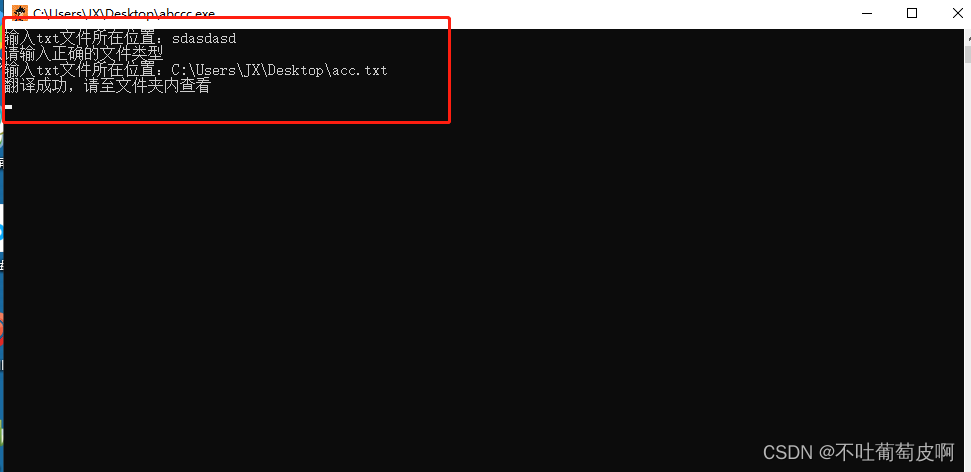

今天的趣味分享结束了,路过的点个关注哦 谢谢,后续如果碰到了有趣的软件会在次分享