一:基本概念
角色:
- Leader:提供读写
- follower:提供读操作,参与Leader选举和过半写成功策略。
- observer: 只提供读,通常情况下,通过client端连接zk集群性能都不错,但是如果client端量很大,增加集群节点(或者有节点挂掉),那么过半策略会因为server增加网络消耗等负担,集群性能会下降。。。Observer的使用,只提供读,那么就不会有差异了。 所以Observer的使用会增加集群性能
session会话:
指客户端启动时,与zk服务端建立的tcp连接。
通过这个连接,客户端能够⼼跳检测与服务器保持有效的会话, 也能够向Zookeeper服务器发送请求并接受响应,还能够通过该连接接受来⾃服务器的Watch事件通知
数据节点Znode:存储数据 ,据模型是⼀棵树 ,由斜杠(/)进⾏分割的路径,就是⼀个Znode,例如/app/path1。
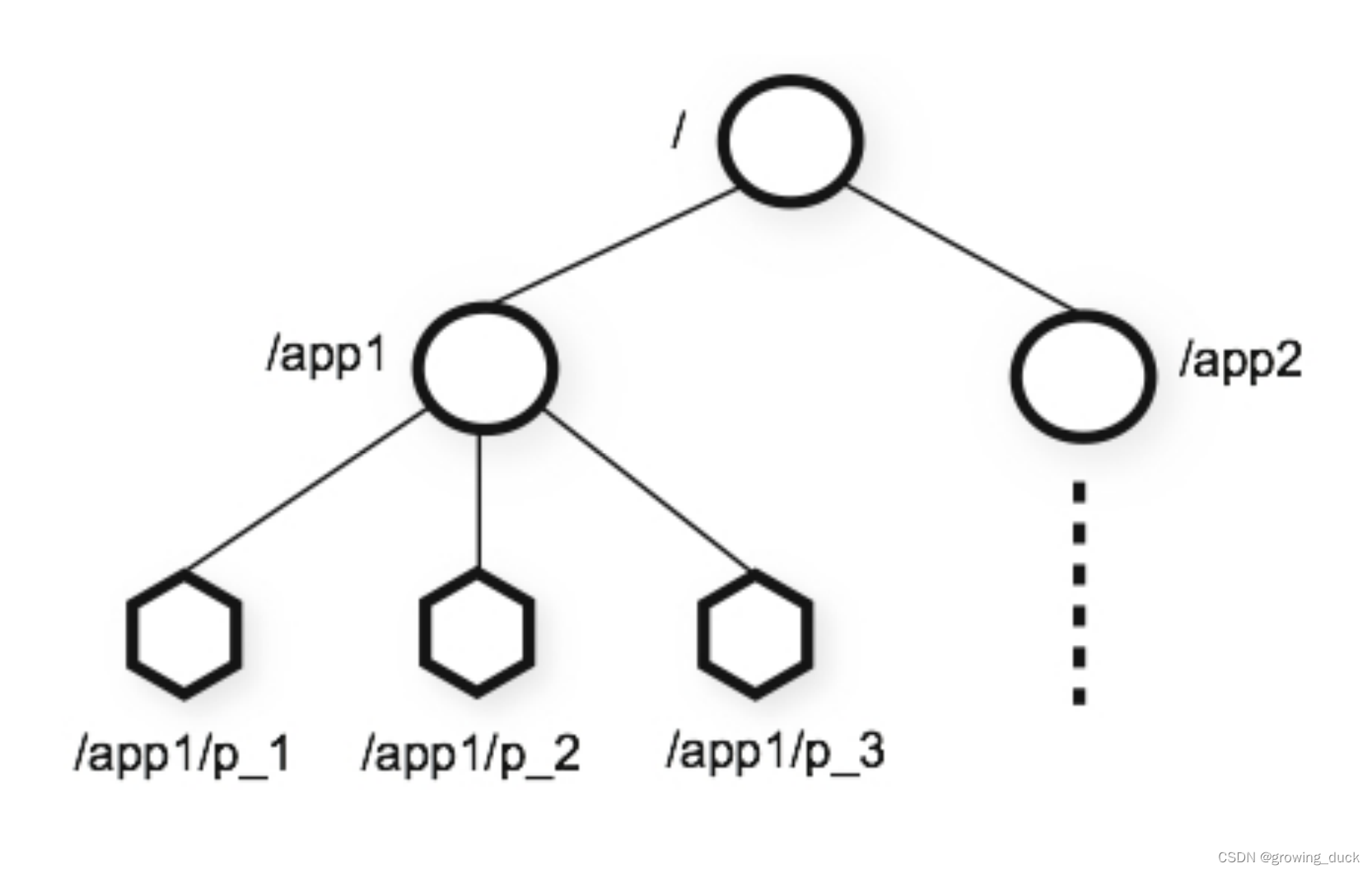
- 临时节点Ephemeral:客户端会话断开后消失
- 持久节点Persistent:需要主动删除,否则创建后一直存在
- 顺序节点Sequential:分持久顺序节点和临时顺序节点,在以上两种节点的最后生成一个数字表示顺序
版本:
在Znode节点数据中,有个Stat数据结构,记录了三个version
- version:当前节点版本
- avesion:当前节点ACL版本-权限控制机制
- cversion:子节点版本
watcher:
事件监听,注册在节点上。 节点变更时通知相关客户端
zxid-事务id:
zk的事务⼀般包括数据节点创建与删除、数据节点内容更新等操作。 在znode中有两部分是数据:业务数据和节点状态信息
- czxid:当前节点创建的事务id
- ctime:当前节点创建的时间
- mzxid:当前节点最后一次被修改的事务id
- mtime:当前节点最后一次被修改的时间
- 还有一些版本号,子节点的信息和数量等
授权模式ACL:
授权模式表示客户端操作某个znode节点应该有什么样的权限,可以分三方面理解:
- 权限模式-Scheme: 用哪一种类型的权限来进行限制
- IP模式:对ip进行控制的方式
- Digest模式:最常用的的验证方式,用户:密码
- World模式:最开放的一种模式,一种特殊的Digest,授权对象只有一个anyone,代表登录到服务器的所有客户端都能对该节点执行某种权限
- Auth模式:使用已经认证过的用户进行认证,那前提肯定是需要有这么一个用户存在。
- 授权对象-ID: 具体授权的目标
- 比如IP模式下,对象就是ip; Digest模式下,就是 用户名:密码; World模式下,就是固定的 anyone; Auth模式下,就是一个已经认证过的用户。
- 权限-Permission:具体的权限,增删改查等
CREATE(C):数据节点的创建权限,允许授权对象在该数据节点下创建⼦节点。
DELETE(D): ⼦节点的删除权限,允许授权对象删除该数据节点的⼦节点。
READ(R):数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或⼦节点列表等。
WRITE(W):数据节点的更新权限,允许授权对象对该数据节点进⾏更新操作。 ·
ADMIN(A):数据节点的管理权限,允许授权对象对该数据节点进⾏ ACL 相关的设置操作。
具体设置节点的权限,就是设置Scheme:ID:Permission的形式。 具体示例参照:
Zookeeper 节点权限控制ACL详解_zk acl_渔夫数据库笔记的博客-CSDN博客
二:zk使用
下载安装这里就不说了,zk的操作主要就是操作节点Znode。
命令行操作
连接zk:
./zkcli.sh 连接本地的zookeeper服务器
./zkCli.sh -server ip:port 连接指定的服务器
创建节点:
create [-s][-e] path data acl
其中,-s或-e分别代表顺序或临时节点,若不指定,则创建持久节点;data是存储的数据;acl⽤来进⾏权限控制(可以不指定)。
如:create -s /zk-test 123
读取节点:
ls path 查看指定节点的所有下一级子节点
get path 查看指定节点的内容和属性
更新节点:
set path data [version] 更新指定节点的内容 。 version指基于哪个数据版本号更新,一般不传,更新后dataVersion自动+1。 如果指定,就必须指定为最新的版本号,否则更新失败。基于此特性可以做乐观锁。
删除节点:
delete path [version] 删除指定节点。 同上可以指定版本号删除,如果版本号与最新的不匹配则删除失败,防止删除时别人已更新过数据。
如果节点存在子节点,则删除失败,需要先删除子节点。 也可以使用递归删除命令 deleteall path
客户端操作
java中使用客户端,通常有三种:
zookeeper原生api:不好用,有很多问题;
ZkClient客户端: 基于原生api封装,比较好用;
Curator客户端: 也是基于原生api封装,功能比ZkClient更强,对很多应用场景的支持更完善(如分布式锁,分布式队列,leader选举,缓存机制等), 推荐使用。
Curator:
引入依赖包:
<!-- zookeeper --> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.10</version> </dependency> <!-- curator-framework --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.2.0</version> </dependency> <!-- curator-recipes --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.2.0</version> </dependency>
Curator创建客户端是通过CuratorFrameworkFactory⼯⼚类来实现的,它有两个方法:
public static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy); public static CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy);connectString: 服务器ip:端口(多个用逗号分隔)。
retryPolicy: 重试策略,是一个接口,默认提供了以下实现,分别是ExponentialBackoffRetry(基于backoff的重连策略)、RetryNTimes(重连N次策略)、RetryForever(永远重试策略)。当然,用户可以自己实现。
connectionTimeoutMs: 连接超时时间,默认15s(建立连接的最大时间,超过后连接建立失败)。
sessionTimeoutMs: 会话超时时间,默认60s(连接建立后会有心跳机制检查会话是否正常)
启动:
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",
5000,1000,retryPolicy);
client.start();创建节点:
private static void createNode(String nodePath, String data) throws Exception {
if (StringUtils.isEmpty(nodePath)) {
System.out.println("节点【" + nodePath + "】不能为空");
return;
}
//1、对节点是否存在进行判断,否则会报错:【NodeExistsException: KeeperErrorCode = NodeExists for /root】
Stat exists = client.checkExists().forPath(nodePath);
if (null != exists) {
System.out.println("节点【" + nodePath + "】已存在,不能新增");
return;
} else {
System.out.println(StringUtils.join("节点【", nodePath, "】不存在,可以新增节点!"));
}
//2、创建节点, curator客户端开发提供了Fluent风格的API,是一种流式编码方式,可以不断地点.点.调用api方法
//创建永久节点(默认就是持久化的)
client.create().forPath(nodePath);
//3、也可以手动指定节点的类型为持久化的
client.create()
.withMode(CreateMode.PERSISTENT)
.forPath(nodePath);
//4、如果父节点不存在,创建当前节点的父节点(可以一次性创建多级节点)
String node = client.create()
.creatingParentsIfNeeded()
.forPath(nodePath);
System.out.println(node);
//创建节点,并为当前节点赋值内容
if (StringUtils.isNotBlank(data)) {
//5、创建永久节点,并为当前节点赋值内容
client.create()
.forPath(nodePath, data.getBytes());
//6、创建永久有序节点
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(nodePath, data.getBytes());
//7、创建临时节点
client.create()
.withMode(CreateMode.EPHEMERAL)
.forPath(nodePath, data.getBytes());
}
//8、创建临时有序节点
client.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(nodePath, data.getBytes());
}更新节点:
private static void updateNode(String nodePath, String data) throws Exception {
//更新节点
Stat stat = client.setData().forPath(nodePath, data.getBytes());
//指定版本号,更新节点,更新的时候如果指定数据版本的话,那么需要和zookeeper中当前数据的版本要一致,-1表示匹配任何版本
//Stat stat = client.setData().withVersion(-1).forPath(nodePath, data.getBytes());
System.out.println(stat);
//异步设置某个节点数据
Stat stat1 = client.setData().inBackground().forPath(nodePath, data.getBytes());
System.out.println(stat1.toString());
}获取节点内容:
private static void getNode(String nodePath) throws Exception {
//获取某个节点数据
byte[] bytes = client.getData().forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes)));
//读取zookeeper的数据,并放到Stat中
Stat stat1 = new Stat();
byte[] bytes2 = client.getData().storingStatIn(stat1).forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes2)));
System.out.println(stat1);
}查询子节点信息:
private static void getNode(String nodePath) throws Exception {
//获取某个节点的所有子节点
List<String> stringList = client.getChildren().forPath(nodePath);
if (CollectionUtils.isEmpty(stringList)) {
return;
}
//遍历节点
stringList.forEach(System.out::println);
}删除节点:
private static void deleteNode(String nodePath) throws Exception {
//删除节点
//client.delete().forPath(nodePath);
//删除节点,即使出现网络故障,zookeeper也可以保证删除该节点
//client.delete().guaranteed().forPath(nodePath);
//级联删除节点(如果当前节点有子节点,子节点也可以一同删除)
client.delete().deletingChildrenIfNeeded().forPath(nodePath);
}三: 应用场景
发布订阅:
zk有push 和 pull两种模式,也就是推 拉。 推:客户端可以在zk某个节点注册监听,有变更时通过wacther事件通知; 拉: 客户端主动去获取节点上的信息。
通常也可以将这两种结合使用,比如把一些信息配置到zk上(如mysql配置信息),客户端启动时主动拉取一次。 当有变更时通过wacther通知,客户端再主动拉取一次。 另外,对于一些不是所有客户端都需要关注的信息,收到通知后,感兴趣的客户端才会去拉取。
命名服务:
在分布式系统中,被命名的实体可以是集群中的机器、提供的服务地址、远程对象等。 比如在dubbo中,就是将接口全路径作为名称注册到zk上,通过调用的接口名就能从zk上找到服务的具体ip地址等(因为有多台服务,通常是一个地址列表),最终通过Netty调用到服务上去。
所以,在分布式系统中,命名要求全局唯一,也就是一个分布式id的概念。可以使用自定义的业务类型+顺序节点的方式:
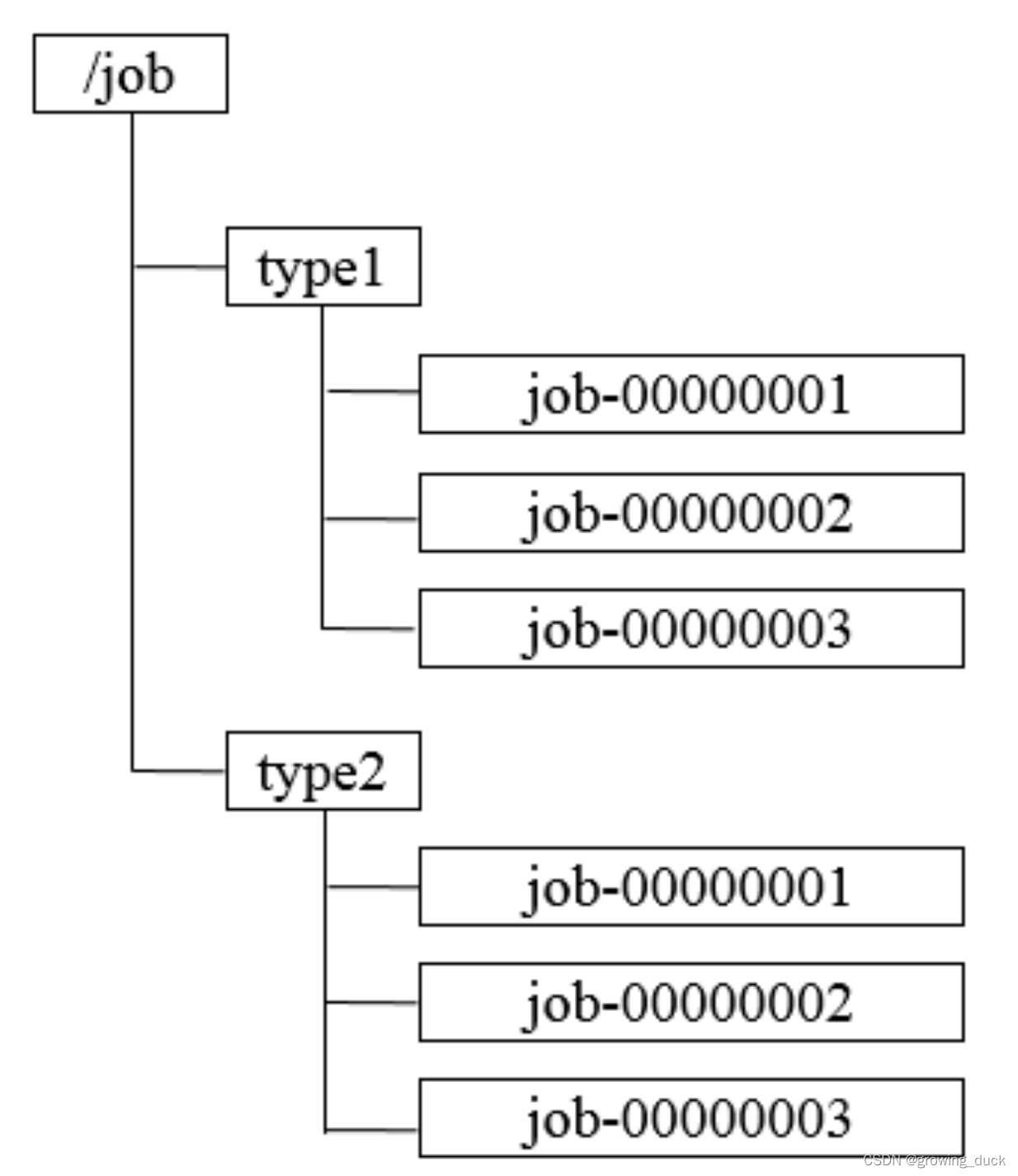
master选举:
master说白了,也就相当于要从集群中选出一个节点来做特别的事情。 一些办法是 集群所有节点都往数据库(或redis)插数据,类似分布式锁,成功的节点就作为master。 但是如果master宕机或是异常,集群没法收到通知重新选举。 zk有注册监听的功能,能主动通知状态; 也有分布式锁的功能(所有节点往zk创建同一个节点,只有一个能成功),更适合做此类场景。
分布式锁:
排他锁:
- 在指定节点/lock下创建临时节点,只有一个节点能成功。 其他客户端需要对/lock做监听等待锁释放。释放也就是客户端删除临时节点,并通过watcher通知。
共享锁:
共享锁又称读锁,A操作对某个对象上了锁后,其他读操作(B,C)可以执行,但写操作(E,F)必须等对象释放锁后才能执行。zk如何实现呢?
- 各个客户端执行操作时,在指定节点/lock下创建临时顺序节点,如R-00000001,R-00000002…代表读,W-00000001,W-00000002…代表写。读写交替,就如:R-00000001,W-00000002,R-00000003
- 创建成功后,当前客户端获取/lock下所有子节点,并对当前/lock节点做监听。
- 如果当前客户端是读操作,要求比自己小的子节点都是读操作,才算获取锁成功(证明在它之前没有数据变更); 如果是写操作,则自己必须为最小子节点, 否则进入等待。
- 当某个客户端的操作结束后删除对应的临时顺序节点,也就是释放锁(/lock下子节点发生变化),其他客户端会收到监听。 重复以上步骤获取所有子节点进行判断。
羊群效应: 每一次释放锁都会导致zk发送大量的消息给监听的客户端,而收到通知的客户端又会向zk请求所有的子节点列表来判断自己是否是最小,能否执行业务逻辑。 最终,可能只有最小的那个节点能执行,其他的节点又进入等待,如此反复……
羊群效应改善: 客户端不对/lock做监听,获取全部子节点列表后,如果当前是读,对比自己小的最后一个写节点注册监听; 如果是写,对比自己小的最后一个节点做监听。 收到监听的通知后,即可执行业务(不用再反复判断/lock下所有子节点情况)。
当然了,以上虽然有羊群效应的说法,也是这针对于规模大,量大的情况。 这时要尽量把锁粒度最小化。 如果规模本来就很小,按照常规的共享锁最简单。
分布式队列:
在指定节点/queue下创建临时顺序节点,获取/queue下所有子节点,对自己的前一个节点做监听,收到通知后执行业务逻辑,这样就能按顺序实现队列的FIFO。 共享锁比较像,只是不需要R,W来区分读写。
四: 高级知识点
ZAB协议: 此协议有两个特点,消息广播 和 崩溃恢复。 这是zk中特有的 用来保证集群节点数据一致性的方式。 在zk的架构中,是主备模式的集群,一个leader和多个follower。 leader处理所有的写操作,因此能够很好地处理客户端⼤量的并发请求,再将数据变更广播到所有的follower。 另外,leader可能发生故障,所以需要有崩溃恢复的能力。
消息广播:
- leader接收client的事务并同步到follower,此过程中会为每个follower分配一个队列,将事务依次放入,并为每一个事务生成全局依次递增的事务id-ZXID。 然后通过TCP协议的网络通信同步到follower。
- Follower收到队列中的事务后,以事务日志形式写入磁盘并返回ACK确认响应,leader收到半数以上响应后,执行commit,并发送commit命令给所有Follower执行commit。 所以这是一个两阶段提交。
崩溃恢复:
ZAB崩溃恢复需要保证两点:
- 丢弃掉原leader未commit的事务
- 已在原leader上已经commit的事务(肯定已同步到follower),最终被所有服务器提交。
基于前面两点,崩溃回复就是需要重新选举leader,并保证新选举的leader在所有服务器中是拥有最大ZXID那个节点,那么它的事务执行肯定是最全的(如果ZXID一样,机器id-SID最大的成为leader)。
数据同步:完成选举后,在接收client请求前,需要保证过半follower同步了leader的数据。 然后剩下的follower和新加入的follower继续同步,整体开始对外工作
状态: LOOKING-选举阶段 FOLLOWING-follower和leader保持同步状态 LEADING-当前节点是leader
leader选举:
选举策略:指leader崩溃或与半数以上follower失联,则需要重新选举leader。
选举时间:启动时或崩溃时
过程:
- 将自己机器的最大事务id和机器id作为投票依据,如(2,0),先投给自己
- 将依据发给集群其他服务器,接收者会检查投递者是否LOOKING状态判断投递者是否有效
- 对比ZXID和SID选出leader(如果不是自己,将投票依据改为其他机器的),继续投给其他服务器,每次选举后会统计是否过半,如果是则确定最终结果。
- leader和follower变更自己的状态,并开始进行数据同步。
- 选举,在集群启动 或 leader崩溃时都会执行。
五:自定义rpc升级:
在前面章节使用Netty自定义了rpc框架,这里加上zk,就可以模拟dubbo的实现。
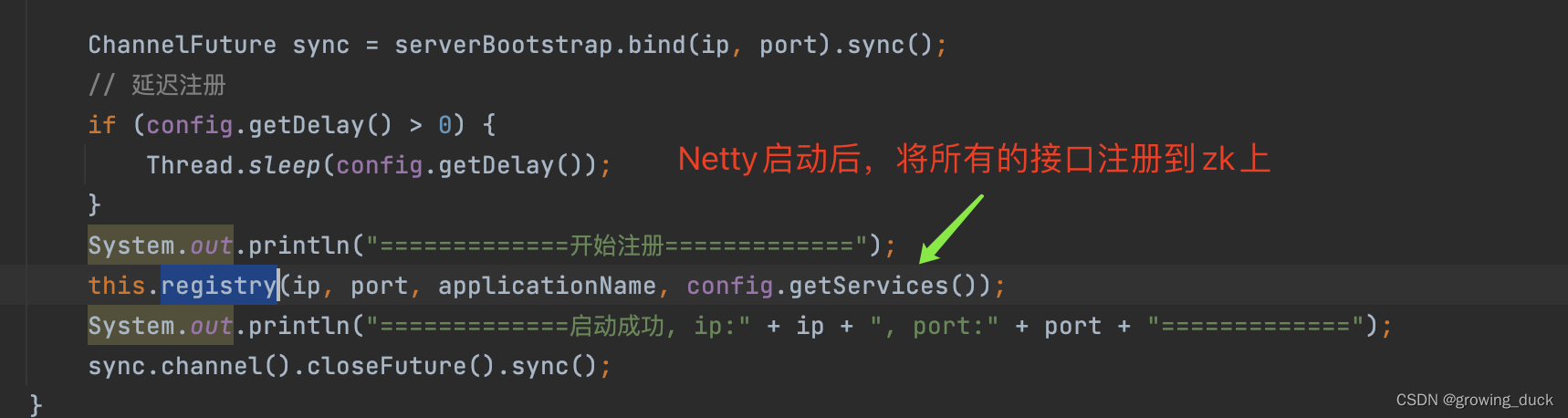
服务端:
就是将所有接口的全限定名,注册为zk的临时节点,不同实例的ip:port为子节点。类似于:
/dubbo/com.java.edu.api.UserService/provider/127.0.0.1:8990, /dubbo/com.java.edu.api.UserService/provider/127.0.0.1:8991
客户端:
通过接口全限定名就能达到具体实例的ip:port,然后通过Netty连接访问。
如上,在接口代理对象的invoke方法中,RpcClient就没有写死服务端的ip和端口了,而是通过负载均衡策略,在服务端的实例列表中选择一个。 服务端的实例列表,就是在zk中获取的/dubbo/com.java.edu.api.UserService/provider下的子节点列表,也就是所有的ip:port。
