实验环境
ASUS VivoBook + Windows10 + Pycharm Community Edition 2021.2.3 + Anaconda3
使用到的核心库
nltk
Natural Language Toolkit,自然语言处理工具包,在NLP领域中最常使用的一个Python库。
本实验中使用ntlk库主要实现词语的形式转换,对词语还原其原形(形容词、副词还原至原形,动词去除时态,名词变为单数等)。
库的注意事项
在使用nltk库之前,需要安装库。使用pip iinstall nltk安装合适的版本。
使用nltk库需要下载停用词库等,控制台会报错,要按照要求在代码中补充以下内容:
import nltk
nltk.download('wordnet')若加入以上内容后,出现nltk.download(‘wordnet‘)错误;Resource wordnet not found. Please use the NLTK Downloader to obtain... 意为连接有误,此时可自行下载语料库后添加到指定位置。参考:https://blog.csdn.net/Gabriel_wei/article/details/113360751
出现以下内容,意为安装成功,可以正常使用:
re
re库是Python的标准库,主要用于字符串匹配。其中正则表达式常作为函数参数来使用。
本实验中使用re库主要实现去除英语句子中的解释性中文及其标点,去除英文标点及数字,仅保留句子中的英文单词。
参考:https://blog.csdn.net/weixin_43360896/article/details/114499028
ele[1] = "我是12345星球的喜欢用!和@说话的good guy."
punctuation_string = string.punctuation
ele[1] = re.sub('[{}]'.format(punctuation_string), " ", ele[1])
ele[1] = re.sub('[{}]'.format(punctuation), " ", ele[1])
ele[1] = re.sub('[\d]', ' ', ele[1])
ele[1] = re.sub('[\u4e00-\u9fa5]', ' ', ele[1])
代码
from nltk.stem import WordNetLemmatizer
from zhon.hanzi import punctuation
from collections import Counter
from nltk.book import *
import string
import nltk
import csv
import re
# 按照词频排序
def sort_by_wordFrequency(d):
'''
d.items() 返回元素为 (key, value) 的可迭代类型(Iterable),
key 函数的参数 k 便是元素 (key, value),所以 k[0] 取到字典的键。
'''
# lambda表达式多字段排序
return sorted(d.items(), key=lambda k: (k[1][0], k[0]), reverse=True)
# 加载语料库
nltk.download('wordnet')
wnl = WordNetLemmatizer()
# 打开文件
f = open('docu.txt', encoding='utf-8')
# 建立词语-词频 词语-题号 两个字典
counter_num = {}
counter_pos = {}
# 将每句话视作列表res的元素,每个元素又包括题号和原句两部分
res = []
for line in f:
dic = [0, 0]
dic[0] = line.strip()[1:8]
dic[1] = line.strip()[9:].lower()
res.append(dic)
# 对每个句子进行分析,先去除标点符号
for ele in res:
punctuation_string = string.punctuation
ele[1] = re.sub('[{}]'.format(punctuation_string), " ", ele[1])
ele[1] = re.sub('[{}]'.format(punctuation), " ", ele[1])
ele[1] = re.sub('[\d]', ' ', ele[1])
ele[1] = re.sub('[\u4e00-\u9fa5]', ' ', ele[1])
# 将得到的去除标点符号的句子进行切分
words = ele[1].split()
# 得到切分后的列表中各词语的词性
pos_tags = nltk.pos_tag(words)
# 为每个句子建立记录词频和位置的字典
num = {}
pos = set()
# 对每个单词进行分析,还原其原形(形容词、副词还原至原形,动词去除时态,名词变为单数等)
for i in range(len(words)):
if pos_tags[i][1].startswith('J'): # 形容词
origin = wnl.lemmatize(words[i], wordnet.ADJ)
elif pos_tags[i][1].startswith('V'): # 动词
origin = wnl.lemmatize(words[i], wordnet.VERB)
elif pos_tags[i][1].startswith('N'): # 名词
origin = wnl.lemmatize(words[i], wordnet.NOUN)
elif pos_tags[i][1].startswith('R'): # 副词
origin = wnl.lemmatize(words[i], wordnet.ADV)
else: # 其他词
origin = words[i]
num[origin] = 1
# 记录该句中所有出现的词语
pos.add(origin)
# 字典值加和,记录单词的总出现次数
X, Y = Counter(counter_num), Counter(num)
counter_num = dict(X + Y)
# 若没有建立字典,若有则补充
for index in pos:
if index not in counter_pos.keys():
counter_pos[index] = [ele[0]]
else:
counter_pos[index].append(ele[0])
final = {}
for i in counter_num.keys():
final[i] = [counter_num[i], counter_pos[i]]
# 输出
final = dict(sort_by_wordFrequency(final))
print(final)
# 写入csv文件
file = open('wordFrequency.csv', 'w', encoding='utf-8', newline='' "")
csv_writer = csv.writer(file)
csv_writer.writerow(["单词", "词频", "年份"])
for ke in final.keys():
csv_writer.writerow([ke, final[ke][0], final[ke][1]])
file.close()多字段排序
使用Lambda表达式对多字段进行排序,如:
按照字段A进行排序;字段A值相同时,按照字段B排序;字段B值相同时,按照字段C排序。
参考:https://blog.csdn.net/TomorrowAndTuture/article/details/100551727
语料格式

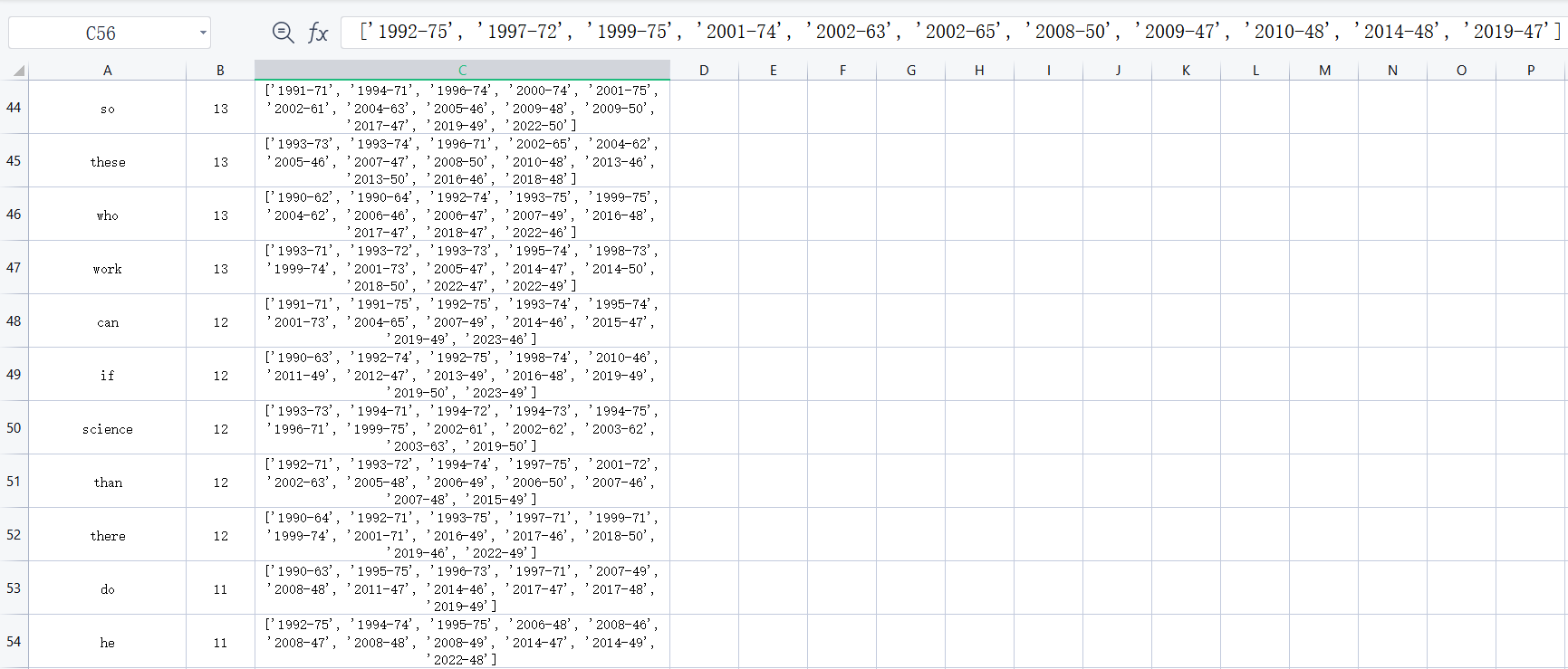
结果展示(部分)
源码及语料链接:https://github.com/YourHealer/WordFrequencyCount.git