目录:导读
前言
目标制定以及业务规则梳理
① 目标制定
衡量性能最重要的三个指标是TPS、响应时间、报错率。那如何制定性能测试的指标呢?你的依据是什么呢?
列举几个常见的误区答案:
我是根据二八原则,老板说我们百万日活,80% 的用户在 20% 的时间段里访问,响应时间是根据业内的 2-5-8 来制定;
我是根据竞品数据分析,他们产品的 PV 应该是百万级,所以我们的产品也是这么制定的;
这个指标是业务定的,他们和开发讨论过,应该没什么问题。
以上回答不仅从道理上讲有些牵强,而且也没有任何制定性能测试可以参考的有效信息。性能测试是一项非常严谨的工作,通过间接或者普适规则不可能满足具体特定的分析,所以对这个问题的理解基本可以判断一位同学是否真正做过性能测试。
对于每一个接口都会有访问计数,这是目前业内比较常见的,也是衡量接口访问能力最准确的指标之一。
一般大公司会自己开发相应的监控工具,发展中的公司也会使用一些开源或者商业工具进行监控。比如从ELK就可以提取这些数据,通过实际访问的频次去指定目标Tps。
② 业务规则的调研
对于性能测试而言,业务规则的了解也是不可或缺的。一些公司的性能测试组在进行压测时,业务线的测试也需要协助支持压测的进行,由此可以体现业务的重要性。
对业务的充分了解不仅可以帮助你提高写脚本的效率,也可以帮助你构造更为真实的性能测试场景。
举个简单的例子,你模拟下单的时候是否考虑商品属性会员属性等,比如是单一商品还是套餐商品,下单的时候购物车里有几件商品,通过不同条件的组合,这些都会影响性能测试的结果。
这一部分很重要,比如你测试过促销,有可能功能的组合会产生上千条case,活动会触发很多规则,如果你只走一个简单的流程,逻辑复杂度根本不是一回事,性能差异会跟真实的逻辑差别很大,而交易又作为最核心的链路,如果出了问题,这锅挺大的,这一块需要好好思考。
部署架构调研
被测的业务部署架构是什么意思呢,简单来说就是 被测服务涉及哪些组件,每个组件部署在哪些服务器上,服务器的配置是怎样的?
你需要画一个部署架构示意图,有了这张图,才能知道如何做到全貌监控,以及遇到问题从哪些服务入手。
一个经典的链路:
从客户端发起到服务端,服务端从代理层到应用层,最后到数据层。需要注意的是,你需要明确被测的环境里的各个服务有多少节点,比如客户层的压测机节点有几台,分别在哪个网段。同理我们可以去调研服务层和数据层的节点。
而且现在都是云服务,会做到弹性扩容,不同的时间节点会有不同的实例节点,这些都应当做好记录。
对测试数据进行调研
关于测试数据调研,包含了非常多的内容,对于业务测试来说数据调研就是获取必要的参数来满足既定的场景可以跑通。那对于性能测试来说,需要做哪些方面的数据调研呢?
① 数据库基础数据量分析
数据库的基础数据量就是目前线上数据库实际的数据量,为什么要统计基础数据量呢?
很多公司往往有独立的性能测试环境,但是数据库的数据量与线上相比差距较大,可能出现一条 SQL 在性能测试环境执行很快,但上了生产却会很慢的问题。这就导致测试觉得该测的都测了,但上了生产还是会有问题出现。
这种问题可能会因为索引缺失以及性能环境数据量较少而不能将问题暴露出来,所以在 性能测试环境下的数据量一定要和生产上一致。
为了达到这个目的,有的公司可以将生产数据脱敏后备份,有的则需要你自己写脚本来根据业务规则批量造数据。
② 压测增量数据分析
除了数据库的基础数据量,我们也需要考虑一轮性能测试下来会增加多少数据量。
往往增加的数据量最终落到数据库,可能会经过各种中间件如 Redis、Mq 等,所以涉及的链路可能存在数据量的激增,所以这方面需要根据增加情况制定相应的兜底方案(即:最差情况下的临时解决办法)
③ 冷热数据的分析
以我的从业经历来讲,能够在方案阶段考虑到冷热数据分布的公司并不多,往往都是从性能测试结果的一些异常点或者实际产线出现的问题去追溯。
接下来我就带你了解下什么是冷热数据,以及如果不对其进行分析可能会带来什么影响。
冷数据,是指没有经常被访问的数据,通常情况下将其存放到数据库中,读写效率相对较低。
热数据,是经常被用户访问的数据,一般会放在缓存中。
在性能测试的过程中,被频繁访问的冷数据会转变为热数据。如果参数化数据量比较少,持续压测会让 TPS 越来越高。
而在实际大促情况下,往往有千万级的用户直接访问,但大多都是冷数据,会存在处理能力还没达到压测结果的指标,系统就出现问题的情况。所以在需求调研时,你也需要考虑:数据会不会被缓存,缓存时间多久的问题?
性能监控
为什么监控很重要,它是发现问题的眼睛,而且一旦在过程中没有及时监控和发现,还原现场是有难度的。不仅需要罗列清楚你所需要的监控工具和访问方式,同时也需要层次分明地传递你监控的内容。对我来说做监第一个关键词:全。
怎么去理解“全”呢?
先举一个典型的例子,有时候做一个新的项目,询问支持的同学有没有部署监控,他们说已经部署了,但等你真正使用的时候发现只监控了一台应用服务器的 CPU。
这个例子我相信大多数人都似曾相识,所以我说的全,至少包含两个方面:
涉及所有服务器;
涉及服务器基础监控,包括 CPU、磁盘、内存、网络等。
第二是分层,不仅仅硬件相关的,还有链路相关的,都要监控,工具如skywalking,pinpoint等。
监控还有个很重要的点是设置阈值来报警,无论是线上和线下的性能测试,报警功能都是必需的。因为通过人工的观察,往往不能以最快的速度发现问题。一旦能够及时报警,涉及的人员就可以快速响应,尽可能降低风险。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
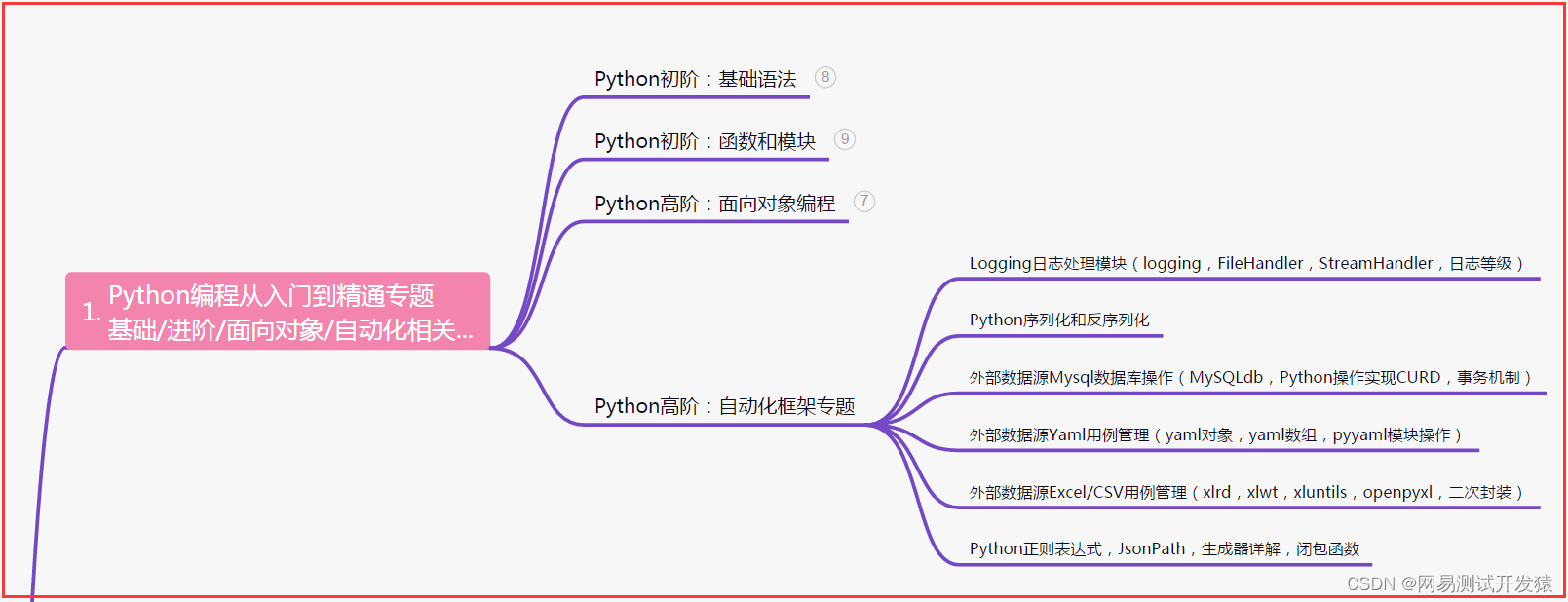
一、Python编程入门到精通
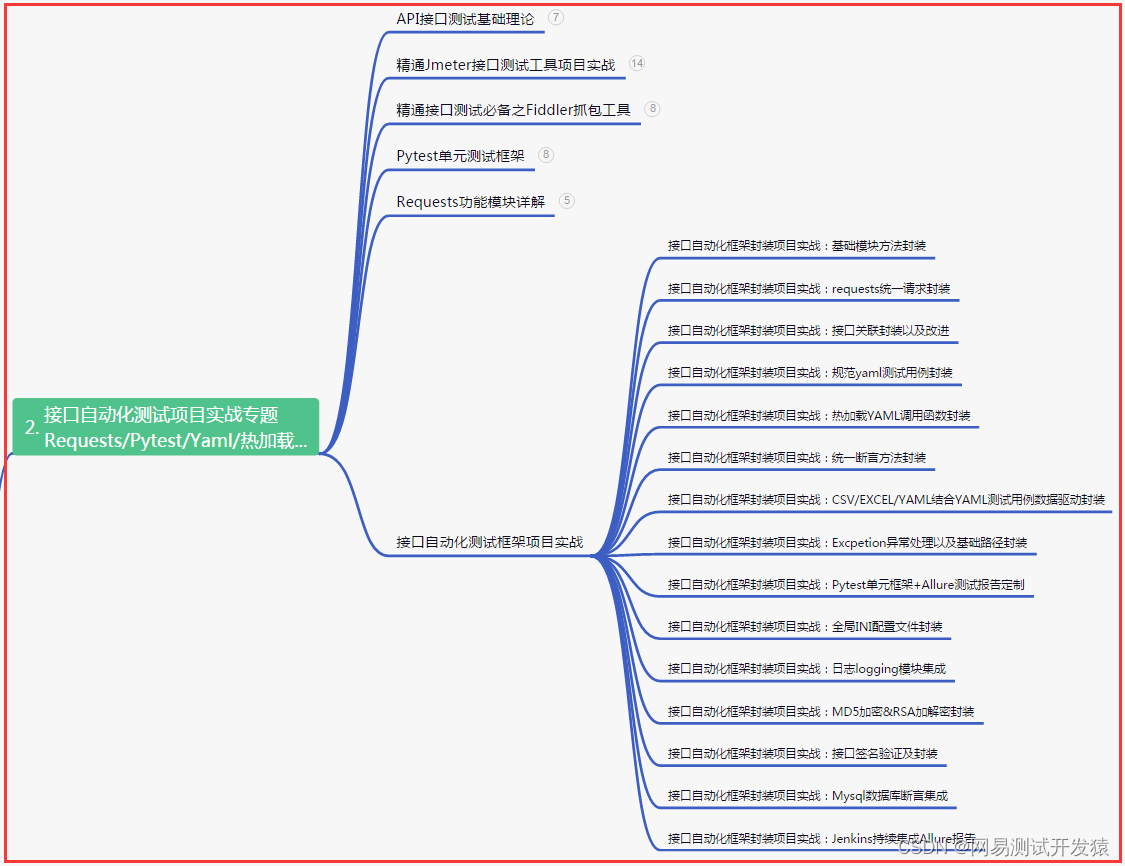
二、接口自动化项目实战
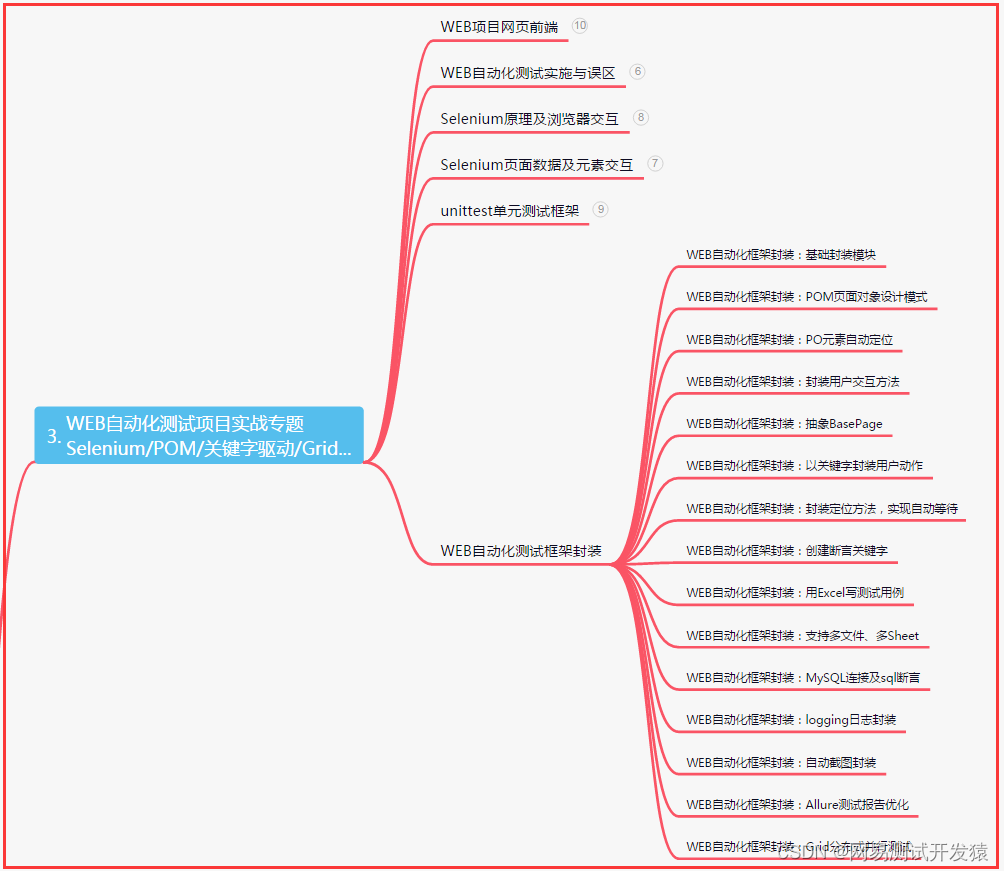
三、Web自动化项目实战
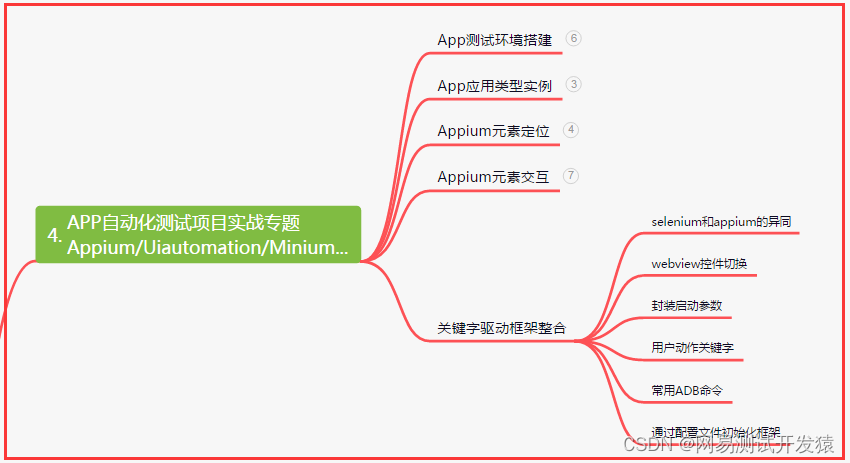
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
每一次的努力都是未来的投资,尽管困难重重,成功路上充满坎坷,但坚持不懈的奋斗将会使你获得自己更多意想不到的成果,也会让你成为更好的自己,让我们一起努力吧!
每个人都有选择放弃或者奋斗的权利,但只有那些勇敢拿起武器、冲破障碍的人才能迎来更美好的明天。所以不要轻易放弃,坚持自己的梦想,继续向前走!
岁月不等人,现在就是改变未来的最佳时机。只要你心怀信念、勇往直前、孜孜不倦地努力,即使路途崎岖,也终将到达成功的彼岸。让我们一起为梦想而奋斗,创造更美好的明天!