作者: cchouqiang 原文来源: https://tidb.net/blog/aa7aa7b8
背景
数据库对于企业来说是至关重要的,但是由于某些原因,会导致数据库的不可用,此时需要数据库自身的恢复能力,快速恢复数据库,恢复业务可用。
数据库大多采用三副本、两地三中心架构,但在极端场景下,需要数据库自恢复能力,不要求数据的一致性,但是要求尽快恢复业务。
恢复工具介绍
对于tidb数据库来说,最重要的组件有tidb、tikv、pd;其中tidb为计算节点,是不存储业务数据的,当出现问题时,可以扩容节点来解决;pd和tikv是会存储数据,当出现问题时,需要通过恢复工具来进行修复。
pd恢复工具为:pd-recover,官方使用手册如下:
https://docs.pingcap.com/zh/tidb/stable/pd-recover#pd-recover-%E4%BD%BF%E7%94%A8%E6%96%87%E6%A1%A3
tikv恢复工具为:online unsafe recovery,官方使用手册如下:
https://docs.pingcap.com/zh/tidb/dev/online-unsafe-recovery
灾难恢复场景
tikv灾难恢复
此前写过一篇关于tikv恢复文章,可以参考链接:
https://tidb.net/blog/75f7933e
pd灾难恢复
本文介绍pd最极端场景恢复,pd所有data和deploy目录全部损坏恢复
(一)查看集群状态,tiup cluster display tidb-test
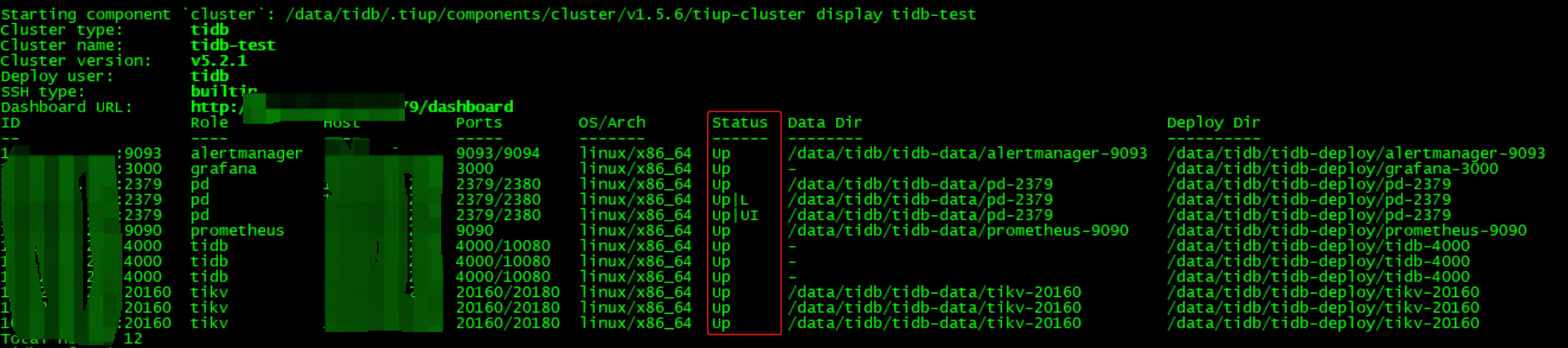
(二)模拟所有PD data、deploy目录损坏


(三)修复PD数据,查找cluster id和alloc-id
参考文档: https://docs.pingcap.com/zh/tidb/dev/pd-recover#pd-recover-%E4%BD%BF%E7%94%A8%E6%96%87%E6%A1%A3
获取cluster id
一般在 PD、TiKV 或 TiDB 的日志中都可以获取 Cluster ID。你可以直接在服务器上查看日志以获取 Cluster ID。
1.从 PD 日志获取 Cluster ID(推荐)
使用以下命令,从 PD 日志中获取 Cluster ID:
cat {
{/path/to}}/pd.log | grep "init cluster id"
[INFO] [server.go:212] ["init cluster id"] [cluster-id=6747551640615446306]
2.从 TiDB 日志获取 Cluster ID
使用以下命令,从 TiDB 日志中获取 Cluster ID:
cat {
{/path/to}}/tidb.log | grep "init cluster id"
client.go:161: [info] [pd] init cluster id 6747551640615446306
3.从 TiKV 日志获取 Cluster ID
使用以下命令,从 TiKV 日志中获取 Cluster ID:
cat {
{/path/to}}/tikv.log | grep "connect to PD cluster"
[INFO] [tikv-server.rs:464] ["connect to PD cluster 6747551640615446306"]
获取已分配 ID alloc-id
在指定已分配 ID 时,需指定一个比当前最大的已分配 ID 更大的值。可以从监控中获取已分配 ID,也可以直接在服务器上查看日志,如果无法确定最大的alloc-id,则可以根据预估设置一个较高的值,如设置100亿,alloc-id是uint64 位,最大可分配id为18446744073709551615。
1. 从监控中获取已分配 ID(推荐)
要从监控中获取已分配的 ID,需要确保你所查看的监控指标是上一任 PD Leader 的指标。可从 PD Dashboard 中 Current ID allocation 面板获取最大的已分配 ID。
2. 从 PD 日志获取已分配 ID
要从 PD 日志中获取分配的 ID,需要确保你所查看的日志是上一任 PD Leader 的日志。运行以下命令获取最大的已分配 ID:
cat {
{/path/to}}/pd*.log | grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -n 1
3. 从TiKV日志中获取已分配ID
如无法通过监控和PD日志查看alloc-id,则可以通过查看所有TiKV日志查看最大的region/peer id
cat tikv.log |grep "insert new region" cat tikv.log |grep "notify pd with change peer region"
(四)强制缩容任意两个PD,只保留一个PD
tiup cluster scale-in tidb-test -N pdip:2379,pdip:2379 --force
......
Start pdip success
+ [ Serial ] - UpdateTopology: cluster=tidb-test
{"level":"warn","ts":"2021-10-09T16:35:22.598+0800","logger":"etcd-client","caller":"[email protected]/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001b6700/#initially=[ip:2379]","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
Verbose debug logs has been written to /data/tidb/.tiup/logs/tiup-cluster-debug-2021-10-09-16-35-22.log.
Error: run `/data/tidb/.tiup/components/cluster/v1.5.6/tiup-cluster` (wd:/data/tidb/.tiup/data/SlKYAsl) failed: exit status 1
虽然会有报错,但是还是强制删除两个节点。
(五)根据display信息手动创建 pd deploy目录

cd /data/tidb/tidb-deploy/pd-2379
mkdir bin
mkdir log
mkdir conf
mkdir scripts
(六)恢复PD-server
通过集群安装介质包,解压缩pd-server,并拷贝到bin目录下(注意版本)
cd /home/tidb/tidb-community-server-v5.2.1-linux-amd64
tar -zxvf pd-recover-v5.2.1-linux-amd64.tar.gz
cp pd-server /data/tidb/tidb-deploy/pd-2379/bin/
权限:755
(七)恢复conf
cd /data/tidb/tidb-deploy/pd-2379/conf
vi pd.toml
# WARNING: This file is auto-generated. Do not edit! All your modification will be overwritten!
# You can use 'tiup cluster edit-config' and 'tiup cluster reload' to update the configuration
# All configuration items you want to change can be added to:
# server_configs:
# pd:
# aa.b1.c3: value
# aa.b2.c4: value
[replication]
isolation-level = "rack"
location-labels = ["rack", "host"]
pd.toml的配置可在.tiup下的meta文件查看
cat /home/tidb/.tiup/storage/cluster/clusters/tidb-test/meta.yaml
(八)恢复scripts
注意和上面恢复内容一致,删除--initial-cluster 中已踢掉的两个PD节点信息,其他信息可参考meta文件
cd /data/tidb/tidb-deploy/pd-2379/scripts
vi run_pd.sh
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=/tidb-data1/tidb-deploy/pd-2379
cd "${DEPLOY_DIR}" || exit 1
exec env GODEBUG=madvdontneed=1 bin/pd-server \
--name="pd-1-2379" \
--client-urls="http://0.0.0.0:2379" \
--advertise-client-urls="http://pdip:2379" \
--peer-urls="http://0.0.0.0:2380" \
--advertise-peer-urls="http://pdip:2380" \
--data-dir="/tidb-data1/tidb-data/pd-2379" \
--initial-cluster="pd-1-2379=http://pdip:2380" \
--config=conf/pd.toml \
--log-file="/tidb-data1/tidb-deploy/pd-2379/log/pd.log" 2>> "/tidb-data1/tidb-deploy/pd-2379/log/pd_stderr.log"
权限:755
(九)测试scripts
为防止start pd失败,可先通过./方式测试run_pd.sh脚本配置是否正常,如能启动pd说明正常,其他部分承接上面PD恢复内容
./run_pd.sh
(十)启动新pd集群
启动新pd,并禁用所有pd调度(如果alloc-id是预估的比较大的值)
tiup cluster start tidb-test -N pdip:2379
tiup cluster display tidb-test

tiup ctl:v5.2.1 pd -u http://127.0.0.1:2379 -i
config show
"schedule": {
"enable-cross-table-merge": "true",
"enable-joint-consensus": "true",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 4,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "10ms",
"region-schedule-limit": 2048,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
config set region-schedule-limit 0
config set leader-schedule-limit 0
(十一)PD-Recover
根据上面获取的cluster-id和alloc-id对pd进行恢复,注意:alloc-id值如果小于集群现有已分配的region id/store id,则可能会导致数据被覆盖。
执行pd-recover设置新PD集群的cluster-id与alloc-id
tiup pd-recover -endpoints http://pdip:2379 -cluster-id 7016973815389845033 -alloc-id 6000
Starting component `pd-recover`: /data/tidb/.tiup/components/pd-recover/v5.2.1/pd-recover -endpoints http://pdip:2379 -cluster-id 7016973815389845033 -alloc-id 6000
recover success! please restart the PD cluster
(十二)重启PD集群,并执行扩容
tiup cluster restart tidb-test -N pdip:2379
tiup cluster display tidb-test
tiup cluster scale-out pd.yaml
tiup cluster reload tidb-test -R pd
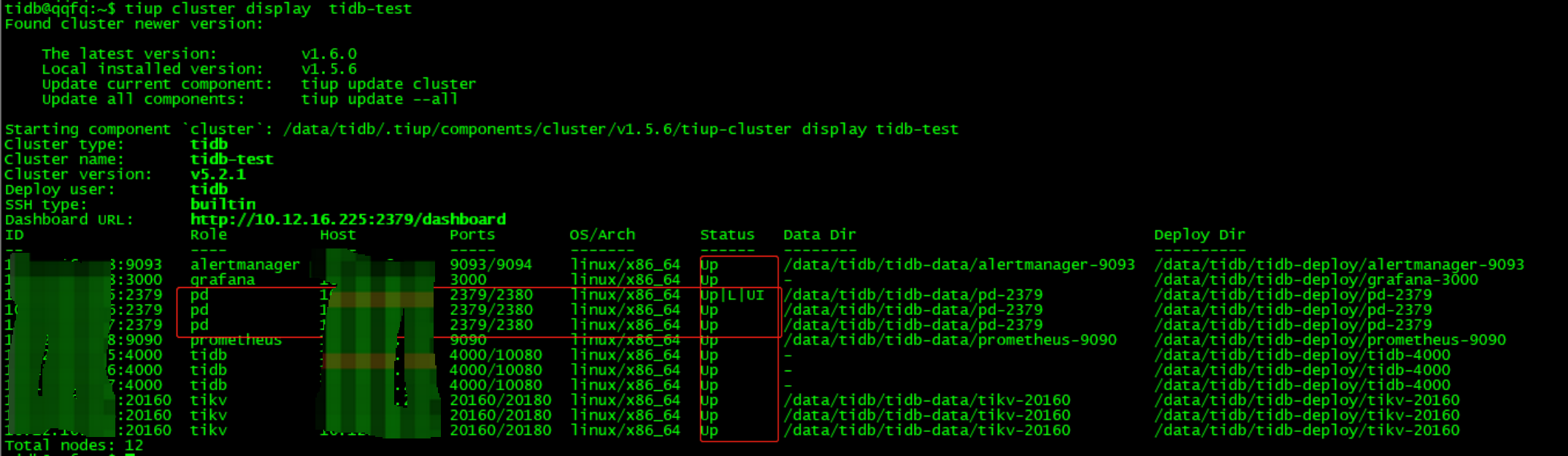
(十三)恢复PD调度,检查PD label 并重启集群
tiup ctl:v5.2.1 pd -u http://127.0.0.1:2379 -i
config show
"schedule": {
"enable-cross-table-merge": "true",
"enable-joint-consensus": "true",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 0,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "10ms",
"region-schedule-limit": 0,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
config set region-schedule-limit 2048
config set leader-schedule-limit 4
config show
{
"replication": {
"enable-placement-rules": "true",
"enable-placement-rules-cache": "false",
"isolation-level": "",
"location-labels": "rack,host",
"max-replicas": 3,
"strictly-match-label": "false"
},
config set location-labels rack,host
最后重启集群
tiup cluster restart tidb-test
多个组件损坏场景
tidb数据库若出现多个组件同时损坏,需要同时用到pd-recover和online unsafe recovery来进行恢复,下面我对多个组件同时损坏的场景进行总结:
tikv、pd都是3个节点
| 损坏场景 | 是否无损修复 | 是否有损修复 | 不可修复 | 修复手段 |
|---|---|---|---|---|
| pd和tikv同时损坏一个节点 | 是 | 通过扩容节点来修复 | ||
| pd损坏一个节点、tikv损坏多数派节点 | 是 | 通过online unsafe recovery进行修复 | ||
| pd损坏多数派节点、tikv损坏一个节点 | 是 | 通过pd-recover进行修复 | ||
| pd和tikv同时损坏多数派节点 | 是 | 通过online unsafe recovery和pd-recover进行修复 | ||
| pd全部损坏、tikv损坏多数派节点 | 是 | 通过online unsafe recovery和pd-recover进行修复 | ||
| pd损坏多数票节点、tikv全部损坏 | 是 | 无法通过online unsafe recovery修复,需要备份来进行恢复 | ||
| pd和tikv全部损坏 | 是 | 无法通过online unsafe recovery修复,需要备份来进行恢复 |
总结和思考
1、pd集群只是存储元数据信息,并且是通过tikv心跳上报,故pd集群的所有数据丢失后,整个tidb集群可以通过重建pd集群修复;
2、重建pd集群需要知道pd老集群的cluster-id和alloc-id,日常备份这两个值即可。
3、日常备份是非常重要的,在极端场景需要用到备份数据来进行恢复。