文章目录
DWS层
设计要点:
(1)DWS层的设计参考指标体系;
(2)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(window)
注:window 表示窗口对应的时间范围。
流量域来源关键词粒度页面浏览各窗口汇总表(FlinkSQL,※)
主要任务
从 Kafka 页面浏览明细主题读取数据,过滤搜索行为,使用自定义 UDTF(一进多出)函数对搜索内容分词。统计各窗口各关键词出现频次,写入 ClickHouse。
思路分析
本程序将使用 FlinkSQL 实现。分词是个一进多出的过程,需要一个 UDTF 函数来实现,FlinkSQL 没有提供相关的内置函数,所以要自定义 UDTF 函数。
自定义函数的逻辑在代码中实现,要完成分词功能,需要导入相关依赖,此处将借助 IK 分词器完成分词。
最终要将数据写入 ClickHouse,需要补充相关依赖,封装 ClickHouse 工具类和方法。本节任务分为两部分:分词处理和数据写出。
1)分词处理
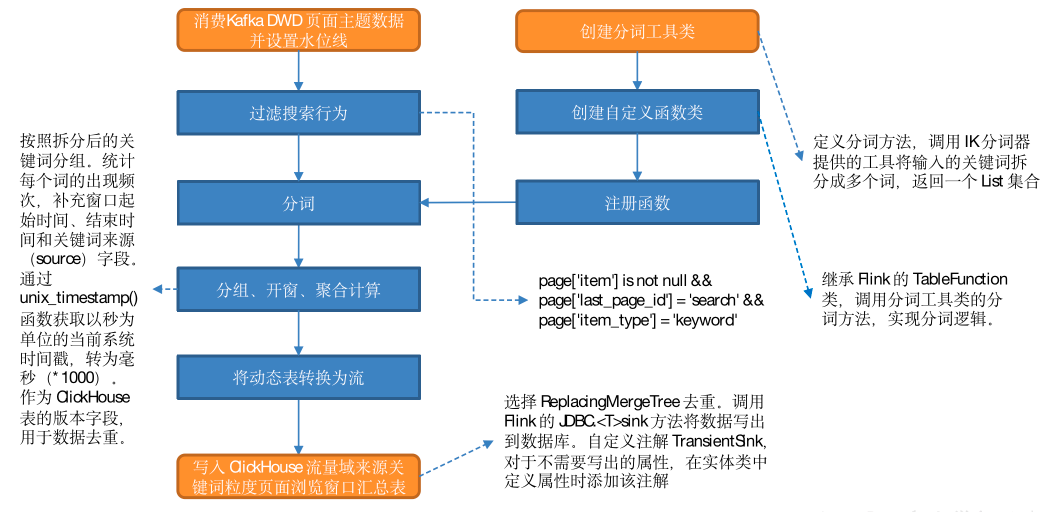
分词处理分为八个步骤,如下:
(1)创建分词工具类
定义分词方法,借助 IK 分词器提供的工具将输入的关键词拆分成多个词,返回一个 List 集合。
(2)创建自定义函数类
继承 Flink 的 TableFunction 类,调用分词工具类的分词方法,实现分词逻辑。
(3)注册函数
(4)从 Kafka 页面浏览明细主题读取数据并设置水位线
(5)过滤搜索行为
满足以下三个条件的即为搜索行为数据:
- page 字段下 item 字段不为 null;
- page 字段下 last_page_id 为 search;
- page 字段下 item_type 为 keyword。
(6)分词
(7)分组、开窗、聚合计算
按照拆分后的关键词分组。统计每个词的出现频次,补充窗口起始时间、结束时间和关键词来源(source)字段。调用 unix_timestamp() 函数获取以秒为单位的当前系统时间戳,转为毫秒(*1000),作为 ClickHouse 表的版本字段,用于数据去重。
(8)将动态表转换为流
2)将数据写入 ClickHouse
(1)建表
要将数据写入 ClickHouse,先要建表。首先要明确使用的表引擎。为了保证数据不重复,可以使用 ReplacingMergeTree(替换合并树) 或者 ReplicatedMergeTree(副本合并树),二者均可去重,区别如下:
-
副本通过对比插入的“数据块”(同一批次写入的数据)实现去重,如果插入的两批数据相似度达到 ClickHouse 的判断标准后插入的数据会被舍弃。副本的初衷是防止数据丢失,而非去重,如果重复数据夹杂在不同的数据块中并不能实现去重效果。假设向 ClickHouse 写入数据时 5 条一批,第一批次 ABCDE 第二批 FAGHI,只要没有达到 ClickHouse 对数据块重复的判断标准,重复的 A 依然会被写入。
-
ReplacingMergeTree 在建表时需要定义版本字段,它会对比排序字段(在ClickHouse 中排序字段可以唯一标识一行数据)相同数据的版本字段,如果设置了该字段,且多条数据的该字段值不同,则保留版本字段值最大的数据,如果没有设置该字段或者多条数据该字段的值相同,则按插入顺序保留最后一条。数据的去重只会在数据合并期间进行。合并操作会在后台一个不确定的时间执行,无法预先做出计划。因此无法保证每时每刻数据不会重复。可以执行 optimize table xxx final 手动对分区进行合并。
此处选择 ReplacingMergeTree,主要考虑到虽然去重有延迟,但在必要时可以通过optimize 去重。但这个命令会引发大量读写操作,对 ClickHouse 而言是非常重的,极其影响性能。生产环境不可能在每次查询前都做一次合并操作,不可过多依赖 optimize 去重。
(2)写出方式
调用Flink提供的JDBCSink.<T>sink(String sql,JdbcStatementBuilder<T> statementBuilder, JdbcExecutionOptions executionOptions, JdbcConnectionOptions connectionOptions) 方法创建 JDBC sink,返回 SinkFunction 类型的对象,将其作为流调用 addSink() 方法的参数,即可将数据以 JDBC 方式写入数据库。这种方式只能写入数据库中的一张表。参数解读如下
-
sql:任意的 DML 语句。
-
statementBuilder:构造者类 JDBCStatementBuilder 对象,用于为数据库操作对象 (PreparedStatement 对象)中的占位符传参。核心方法 accept(PreparedStatement preparedStatement, T obj),参数解读如下。
-
preparedStatement:数据库操作对象。
-
obj:流中数据对象。要给占位符传参,就必须将 SQL 中的占位符和流中数据对应起来。然而,不同 SQL 语句的占位符数量可能不同,不可能设置一个统一的数值指定占位符个数,然后简单地通过固定次数的循环完成传参。那么,如何在程序中将占位符和流中数据对应起来?可以这样做,用传入方法的流中数据对象(obj)获取类的 Class 对象,然后通过反射的方式获取所有属性的 Field 对象,再调用 field 对象的 setObject() 方法将流中数据传递给 SQL 中的占位符,完成传参。
-
T:泛型,指定流中数据类型。
-
executionOptions:SQL DML 语句是按照批次执行的,该参数用于设置执行参数,API 如下。
-
withBatchIntervalMs(long intervalMs) 设置批处理时间间隔,单位毫秒。默认值为0,表示不会基于时间对批处理进行控制。
-
withBatchSize(int size) 设置批次大小(数据的条数),默认为 5000 条。
-
withMaxRetries(int maxRetries) 设置最大重试次数,默认为 3 次。
-
批处理触发条件(满足其一即可):
a. 距离上次数据插入经过了 withBatchIntervalMs 设置的时间间隔
b. 数据量达到批大小
c. Flink 检查点启动时
-
-
connectionOptions:设置数据库连接参数
- withUrl:数据库 URL
- withDriverName:数据库驱动名称
- withUsername:连接数据库的用户名
- withPassword:连接数据库的密码
-
(3)TransientSink
在实体类中某些字段是为了辅助指标计算而设置的,并不会写入到数据库。那么,如何告诉程序哪些字段不需要写入数据库呢?Java 的反射提供了解决思路。类的属性对象 Field 可以调用 getAnnotation(Class annotationClass) 方法获取写在类中属性定义语句上方的注解中的信息,若注解存在则返回值不为 null。
定义一个可以写在属性上的注解,对于不需要写入数据库的属性,在实体类中属性定义语句上方添加该注解。为数据库操作对象传参时判断注解是否存在,是则跳过属性,即可实现对属性的排除。
图解
ClickHouse建表语句
drop table if exists dws_traffic_source_keyword_page_view_window;
create table if not exists dws_traffic_source_keyword_page_view_window
(
stt DateTime,
edt DateTime,
source String,
keyword String,
keyword_count UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt, source, keyword);
代码
1)IK分词器、ClickHouse依赖
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.0</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
</exclusions>
</dependency>
2)IK 分词工具类 KeywordUtil
public class KeywordUtil {
public static List<String> splitKeyword(String keyword) throws IOException {
//创建集合用于存放切分后的数据
ArrayList<String> list = new ArrayList<>();
//创建IK分词对象 ik_smart ik_max_word
StringReader reader = new StringReader(keyword);
IKSegmenter ikSegmenter = new IKSegmenter(reader, false);
//循环取出切分好的词
Lexeme next = ikSegmenter.next();
while (next != null) {
String word = next.getLexemeText();
list.add(word);
next = ikSegmenter.next();
}
//最终返回集合
return list;
}
public static void main(String[] args) throws IOException {
System.out.println(splitKeyword("Flink实时数仓"));
}
}
**3)FlinkSQL 用户自定义函数 SplitFunction **
@FunctionHint(output = @DataTypeHint("ROW<word STRING>"))
public class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
// for (String s : str.split(" ")) {
// collect(Row.of(s, s.length()));
// }
List<String> list = null;
try {
list = KeywordUtil.splitKeyword(str);
for (String word : list) {
collect(Row.of(word));
}
} catch (IOException e) {
collect(Row.of(str));
}
}
}
4)实体类 KeywordBean
@Data
@AllArgsConstructor
@NoArgsConstructor
public class KeywordBean {
// 窗口起始时间
private String stt;
// 窗口闭合时间
private String edt;
// 关键词来源 --- 辅助字段,不需要写入ClickHouse
//@TransientSink
private String source;
// 关键词
private String keyword;
// 关键词出现频次
private Long keyword_count;
// 时间戳
private Long ts;
}
5)常量类 GmallConstant
public class GmallConstant {
// 10 单据状态
public static final String ORDER_STATUS_UNPAID="1001"; //未支付
public static final String ORDER_STATUS_PAID="1002"; //已支付
public static final String ORDER_STATUS_CANCEL="1003";//已取消
public static final String ORDER_STATUS_FINISH="1004";//已完成
public static final String ORDER_STATUS_REFUND="1005";//退款中
public static final String ORDER_STATUS_REFUND_DONE="1006";//退款完成
// 11 支付状态
public static final String PAYMENT_TYPE_ALIPAY="1101";//支付宝
public static final String PAYMENT_TYPE_WECHAT="1102";//微信
public static final String PAYMENT_TYPE_UNION="1103";//银联
// 12 评价
public static final String APPRAISE_GOOD="1201";// 好评
public static final String APPRAISE_SOSO="1202";// 中评
public static final String APPRAISE_BAD="1203";// 差评
public static final String APPRAISE_AUTO="1204";// 自动
// 13 退货原因
public static final String REFUND_REASON_BAD_GOODS="1301";// 质量问题
public static final String REFUND_REASON_WRONG_DESC="1302";// 商品描述与实际描述不一致
public static final String REFUND_REASON_SALE_OUT="1303";// 缺货
public static final String REFUND_REASON_SIZE_ISSUE="1304";// 号码不合适
public static final String REFUND_REASON_MISTAKE="1305";// 拍错
public static final String REFUND_REASON_NO_REASON="1306";// 不想买了
public static final String REFUND_REASON_OTHER="1307";// 其他
// 14 购物券状态
public static final String COUPON_STATUS_UNUSED="1401";// 未使用
public static final String COUPON_STATUS_USING="1402";// 使用中
public static final String COUPON_STATUS_USED="1403";// 已使用
// 15退款类型
public static final String REFUND_TYPE_ONLY_MONEY="1501";// 仅退款
public static final String REFUND_TYPE_WITH_GOODS="1502";// 退货退款
// 24来源类型
public static final String SOURCE_TYPE_QUREY="2401";// 用户查询
public static final String SOURCE_TYPE_PROMOTION="2402";// 商品推广
public static final String SOURCE_TYPE_AUTO_RECOMMEND="2403";// 智能推荐
public static final String SOURCE_TYPE_ACTIVITY="2404";// 促销活动
// 购物券范围
public static final String COUPON_RANGE_TYPE_CATEGORY3="3301";//
public static final String COUPON_RANGE_TYPE_TRADEMARK="3302";//
public static final String COUPON_RANGE_TYPE_SPU="3303";//
//购物券类型
public static final String COUPON_TYPE_MJ="3201";//满减
public static final String COUPON_TYPE_DZ="3202";// 满量打折
public static final String COUPON_TYPE_DJ="3203";// 代金券
public static final String ACTIVITY_RULE_TYPE_MJ="3101";
public static final String ACTIVITY_RULE_TYPE_DZ ="3102";
public static final String ACTIVITY_RULE_TYPE_ZK="3103";
public static final String KEYWORD_SEARCH="SEARCH";
public static final String KEYWORD_CLICK="CLICK";
public static final String KEYWORD_CART="CART";
public static final String KEYWORD_ORDER="ORDER";
}
6)在 GmallConfig 常量类中补充常量
public class GmallConfig {
// Phoenix库名
public static final String HBASE_SCHEMA = "GMALL211126_REALTIME";
// Phoenix驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
// Phoenix连接参数
public static final String PHOENIX_SERVER = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
// ClickHouse 驱动
public static final String CLICKHOUSE_DRIVER = "ru.yandex.clickhouse.ClickHouseDriver";
// ClickHouse 连接 URL
public static final String CLICKHOUSE_URL = "jdbc:clickhouse://hadoop102:8123/gmall_211126";
}
7)ClickHouse 工具类
public class MyClickHouseUtil {
public static <T> SinkFunction<T> getSinkFunction(String sql) {
return JdbcSink.<T>sink(sql,
new JdbcStatementBuilder<T>() {
@SneakyThrows
@Override
public void accept(PreparedStatement preparedStatement, T t) throws SQLException {
//使用反射的方式获取t对象中的数据
Class<?> tClz = t.getClass();
// Method[] methods = tClz.getMethods();
// for (int i = 0; i < methods.length; i++) {
// Method method = methods[i];
// method.invoke(t);
// }
//获取并遍历属性
Field[] declaredFields = tClz.getDeclaredFields();
int offset = 0;
for (int i = 0; i < declaredFields.length; i++) {
//获取单个属性
Field field = declaredFields[i];
field.setAccessible(true);
//尝试获取字段上的自定义注解
TransientSink transientSink = field.getAnnotation(TransientSink.class);
if (transientSink != null) {
offset++;
continue;
}
//获取属性值
Object value = field.get(t);
//给占位符赋值
preparedStatement.setObject(i + 1 - offset, value);
}
}
},
new JdbcExecutionOptions.Builder()
.withBatchSize(5)
.withBatchIntervalMs(1000L)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName(GmallConfig.CLICKHOUSE_DRIVER)
.withUrl(GmallConfig.CLICKHOUSE_URL)
.build());
}
}
8)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwsTrafficSourceKeywordPageViewWindow > ClickHouse(ZK)
public class DwsTrafficSourceKeywordPageViewWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.使用DDL方式读取Kafka page_log 主题的数据创建表并且提取时间戳生成Watermark
String topic = "dwd_traffic_page_log";
String groupId = "dws_traffic_source_keyword_page_view_window_211126";
tableEnv.executeSql("" +
"create table page_log( " +
" `page` map<string,string>, " +
" `ts` bigint, " +
" `rt` as TO_TIMESTAMP(FROM_UNIXTIME(ts/1000)), " +
" WATERMARK FOR rt AS rt - INTERVAL '2' SECOND " +
" ) " + MyKafkaUtil.getKafkaDDL(topic, groupId));
//TODO 3.过滤出搜索数据
Table filterTable = tableEnv.sqlQuery("" +
" select " +
" page['item'] item, " +
" rt " +
" from page_log " +
" where page['last_page_id'] = 'search' " +
" and page['item_type'] = 'keyword' " +
" and page['item'] is not null");
tableEnv.createTemporaryView("filter_table", filterTable);
//TODO 4.注册UDTF & 切词
tableEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
Table splitTable = tableEnv.sqlQuery("" +
"SELECT " +
" word, " +
" rt " +
"FROM filter_table, " +
"LATERAL TABLE(SplitFunction(item))");
tableEnv.createTemporaryView("split_table", splitTable);
tableEnv.toAppendStream(splitTable, Row.class).print("Split>>>>>>");
//TODO 5.分组、开窗、聚合
Table resultTable = tableEnv.sqlQuery("" +
"select " +
" 'search' source, " +
" DATE_FORMAT(TUMBLE_START(rt, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') stt, " +
" DATE_FORMAT(TUMBLE_END(rt, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') edt, " +
" word keyword, " +
" count(*) keyword_count, " +
" UNIX_TIMESTAMP()*1000 ts " +
"from split_table " +
"group by word,TUMBLE(rt, INTERVAL '10' SECOND)");
//TODO 6.将动态表转换为流
DataStream<KeywordBean> keywordBeanDataStream = tableEnv.toAppendStream(resultTable, KeywordBean.class);
keywordBeanDataStream.print(">>>>>>>>>>>>");
//TODO 7.将数据写出到ClickHouse
keywordBeanDataStream.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_traffic_source_keyword_page_view_window values(?,?,?,?,?,?)"));
//TODO 8.启动任务
env.execute("DwsTrafficSourceKeywordPageViewWindow");
}
}
流量域版本-渠道-地区-访客类别粒度页面浏览各窗口汇总表(※)
主要任务
DWS 层是为 ADS 层服务的,通过对指标体系的分析,本节汇总表中需要有会话数、页面浏览数、浏览总时长、独立访客数、跳出会话数五个度量字段。本节的任务是统计这五个指标,并将维度和度量数据写入 ClickHouse 汇总表。
思路分析
任务可以分为两部分:统计指标的计算和数据写出,数据写出在前面已有介绍,不再赘述。此处仅对统计指标计算进行分析。
- 会话数、页面浏览数和浏览总时长三个指标均与页面浏览有关,可以由 DWD 层页面浏览明细表获得。
- 独立访客数可以由 DWD 层的独立访客明细表获得,跳出会话数可以由 DWD 层的用户跳出明细表获得。
三个主题读取的数据会在程序中被封装为三条流。处理后的数据要写入 ClickHouse 的同一张表,那么三条流的数据结构必须完全一致,这个问题很好解决,只要定义与表结构对应的实体类,然后将流中数据结构转换为实体类即可。除此之外,还有个问题需要考虑,三条流是否需要合并?ClickHouse 表的字段将按照窗口 + 表中所有维度做 order by,排序键是 ClickHouse 中的唯一键。如果三条流分别将数据写出到 ClickHouse,则对于唯一键相同的数据,不考虑重复写入的情况下会存在三条需要保留的数据(度量数据分别存在于三条数据中)。我们使用了 ReplacingMergeTree,在分区合并时会按照排序键去重,排序字段相同的数据仅保留一条,将造成数据丢失。显然,这种方案是不可行的。此处将三条流合并为一条,对于每一排序键只生成一条数据。
1)知识储备
常见的多流合并算子及应用场景如下。
-
union():用于两条及多条流之间的合并,对流的数量没有限制,但是要求所有流中的数据结构完全一致。
-
connect():用于两条流的合并,其后紧邻的 process 算子中可以使用的 CoProcessFunction 是双流处理最底层的 API,可以通过键控状态和定时器的运用实现join、广播join、段join等各种关联。connect() 只能对两条流做关联,且对两条流的数据结构没有要求。
-
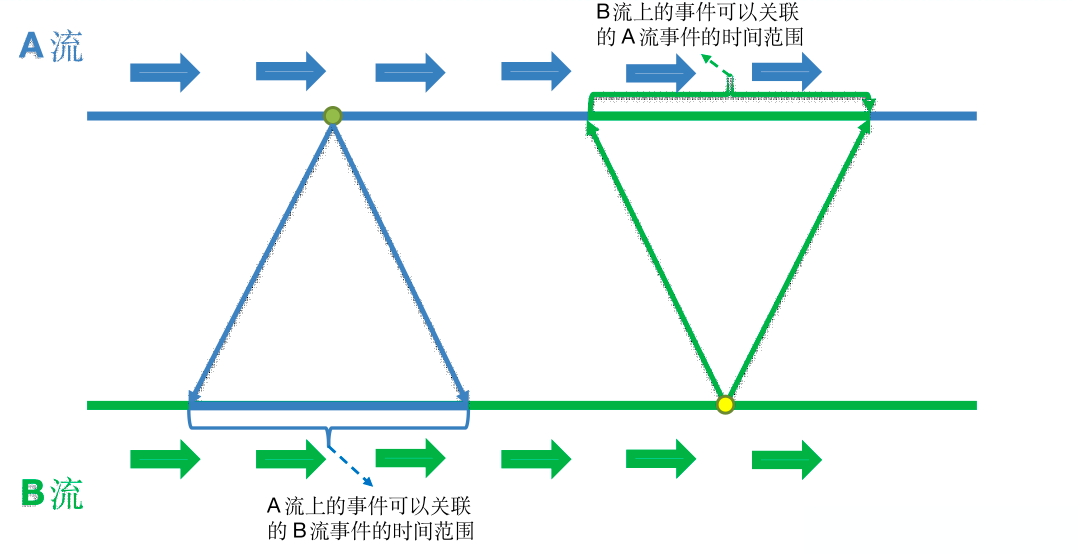
intervalJoin:段 join,两条流的每一条数据都可以与另一条流某个时间范围内的数据做关联。底层实现原理:以 A.intervalJoin(B) 为例,A 流中的数据进入算子后,会被保存到键控状态中,同时注册一个定时器,定时器触发时清空 A 流状态中的数据。在定时器触发之前,B 流中的每一条数据都可以与状态中保存的 A 流数据关联。同理,B 流中也维护了状态定时器。由此实现了段 join。假定A流中的定时器存在时长为3s,B流中的定时器存在时长为5s,A 流中某条数据抵达时间为 tA,可与 tA – 5s ~ tA + 3s 时间范围内抵达的 B 流数据关联;B 流中某条数据抵达时间为 tB,可与 tB – 3s ~ tB + 5s 时间范围内抵达的 A 流数据关联。
-
join():该算子的功能可以被其它算子替代,目前基本不用。
connect()、intervalJoin()、join() 都是双流合并算子,这里需要对三条流进行合并,且流中数据结构一致,选择 union() 更为合理。
2)执行步骤
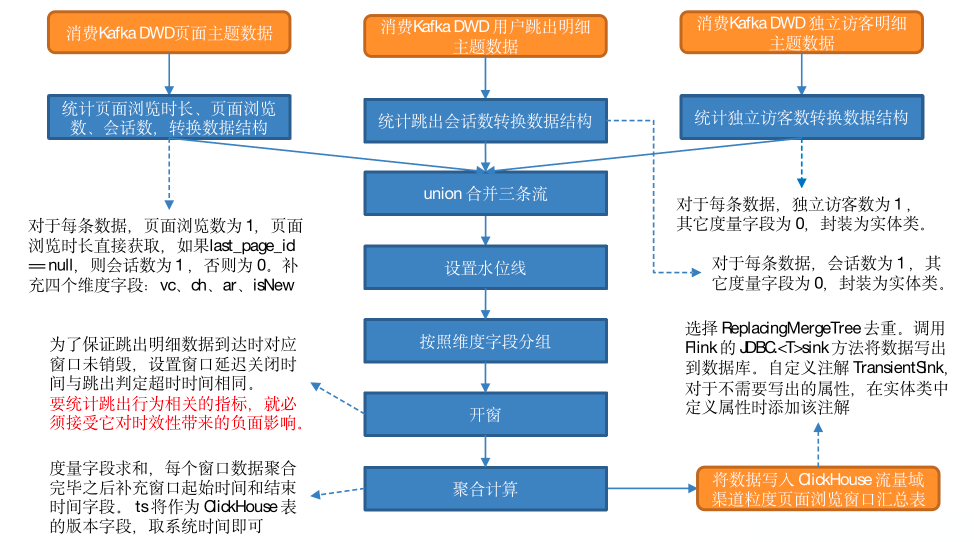
(1)读取页面主题数据,封装为流
(2)统计页面浏览时长、页面浏览数、会话数,转换数据结构
创建实体类,将独立访客数、跳出会话数置为 0,将页面浏览数置为 1(只要有一条页面浏览日志,则页面浏览数加一),获取日志中的页面浏览时长,赋值给实体类的同名字段,最后判断 last_page_id 是否为 null,如果是,说明页面是首页,开启了一个新的会话,将会话数置为 1,否则置为 0。补充维度字段,窗口起始和结束时间置为空字符串。下游要根据水位线开窗,所以要补充事件时间字段,此处将日志生成时间 ts 作为事件时间字段即可。最后将实体类对象发往下游。
(3)读取用户跳出明细数据
(4)转换用户跳出流数据结构
封装实体类,维度字段和时间戳处理与页面流相同,跳出数置为1,其余度量字段置为 0。将数据发往下游。
(5)读取独立访客明细数据
(6)转换独立访客流数据结构
处理过程与跳出流同理。
(7)union 合并三条流
(8)设置水位线;
(9)按照维度字段分组;
(10)开窗
跳出行为判定的超时时间为 10s,假设某条日志属于跳出数据,如果它对应的事件时间为 15s,要判定是否跳出需要在水位线达到 25s 时才能做到,若窗口大小为 10s,这条数据应进入 10~20s 窗口,但是拿到这条数据时水位线已达到 25s,所属窗口已被销毁。这样就导致跳出会话数永远为 0,显然是有问题的。要避免这种情况,必须设置窗口延迟关闭,延迟关闭时间大于等于跳出判定的超时时间才能保证跳出数据不会被漏掉,可以将水位线的forBoundedOutOfOrderness延迟时间设置为14。但是这样会严重影响时效性,如果企业要求延迟时间设置为半小时,那么窗口就要延迟半小时关闭。要统计跳出行为相关的指标,就必须接受它对时效性带来的负面影响。
(11)聚合计算
度量字段求和,每个窗口数据聚合完毕之后补充窗口起始时间和结束时间字段。
在 ClickHouse 中,ts 将作为版本字段用于去重,ReplacingMergeTree 会在分区合并时对比排序字段相同数据的 ts,保留 ts 最大的数据。此处将时间戳字段置为当前系统时间,这样可以保证数据重复计算时保留的是最后一次计算的结果。
(12)将数据写入 ClickHouse。
图解
ClickHouse建表语句
drop table if exists dws_traffic_vc_ch_ar_is_new_page_view_window;
create table if not exists dws_traffic_vc_ch_ar_is_new_page_view_window
(
stt DateTime,
edt DateTime,
vc String,
ch String,
ar String,
is_new String,
uv_ct UInt64,
sv_ct UInt64,
pv_ct UInt64,
dur_sum UInt64,
uj_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt, vc, ch, ar, is_new);
代码
1)实体类TrafficPageViewBean
@Data
@AllArgsConstructor
public class TrafficPageViewBean {
// 窗口起始时间
String stt;
// 窗口结束时间
String edt;
// app 版本号
String vc;
// 渠道
String ch;
// 地区
String ar;
// 新老访客状态标记
String isNew;
// 独立访客数
Long uvCt;
// 会话数
Long svCt;
// 页面浏览数
Long pvCt;
// 累计访问时长
Long durSum;
// 跳出会话数
Long ujCt;
// 时间戳
Long ts;
}
2)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD)
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD)
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD)
======> FlinkApp -> ClickHouse(DWS)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwdTrafficUserJumpDetail -> Kafka(ZK)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwdTrafficUniqueVisitorDetail -> Kafka(ZK)
======> DwsTrafficVcChArIsNewPageViewWindow -> ClickHouse(ZK)
public class DwsTrafficVcChArIsNewPageViewWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.读取三个主题的数据创建流
String uvTopic = "dwd_traffic_unique_visitor_detail";
String ujdTopic = "dwd_traffic_user_jump_detail";
String topic = "dwd_traffic_page_log";
String groupId = "vccharisnew_pageview_window_1126";
DataStreamSource<String> uvDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(uvTopic, groupId));
DataStreamSource<String> ujDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(ujdTopic, groupId));
DataStreamSource<String> pageDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.统一数据格式
SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithUvDS = uvDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
JSONObject common = jsonObject.getJSONObject("common");
return new TrafficPageViewBean("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
1L, 0L, 0L, 0L, 0L,
jsonObject.getLong("ts"));
});
SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithUjDS = ujDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
JSONObject common = jsonObject.getJSONObject("common");
return new TrafficPageViewBean("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
0L, 0L, 0L, 0L, 1L,
jsonObject.getLong("ts"));
});
SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithPageDS = pageDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
JSONObject common = jsonObject.getJSONObject("common");
JSONObject page = jsonObject.getJSONObject("page");
String lastPageId = page.getString("last_page_id");
long sv = 0L;
if (lastPageId == null) {
sv = 1L;
}
return new TrafficPageViewBean("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
0L, sv, 1L, page.getLong("during_time"), 0L,
jsonObject.getLong("ts"));
});
//TODO 4.将三个流进行Union
DataStream<TrafficPageViewBean> unionDS = trafficPageViewWithUvDS.union(
trafficPageViewWithUjDS,
trafficPageViewWithPageDS);
//TODO 5.提取事件时间生成WaterMark
//这里注意一下:forBoundedOutOfOrderness延迟时间要设置为14,如果为2的话会出错,因为在DWD中用户跳出事务中,使用了CEP,会产生10+2s的延迟。
SingleOutputStreamOperator<TrafficPageViewBean> trafficPageViewWithWmDS = unionDS.assignTimestampsAndWatermarks(WatermarkStrategy.<TrafficPageViewBean>forBoundedOutOfOrderness(Duration.ofSeconds(14)).withTimestampAssigner(new SerializableTimestampAssigner<TrafficPageViewBean>() {
@Override
public long extractTimestamp(TrafficPageViewBean element, long recordTimestamp) {
return element.getTs();
}
}));
//TODO 6.分组开窗聚合
WindowedStream<TrafficPageViewBean, Tuple4<String, String, String, String>, TimeWindow> windowedStream = trafficPageViewWithWmDS.keyBy(new KeySelector<TrafficPageViewBean, Tuple4<String, String, String, String>>() {
@Override
public Tuple4<String, String, String, String> getKey(TrafficPageViewBean value) throws Exception {
return new Tuple4<>(value.getAr(),
value.getCh(),
value.getIsNew(),
value.getVc());
}
}).window(TumblingEventTimeWindows.of(Time.seconds(10)));
// //增量聚合
// windowedStream.reduce(new ReduceFunction<TrafficPageViewBean>() {
// @Override
// public TrafficPageViewBean reduce(TrafficPageViewBean value1, TrafficPageViewBean value2) throws Exception {
// return null;
// }
// });
// //全量聚合
// windowedStream.apply(new WindowFunction<TrafficPageViewBean, TrafficPageViewBean, Tuple4<String, String, String, String>, TimeWindow>() {
// @Override
// public void apply(Tuple4<String, String, String, String> key, TimeWindow window, Iterable<TrafficPageViewBean> input, Collector<TrafficPageViewBean> out) throws Exception {
//
// }
// });
SingleOutputStreamOperator<TrafficPageViewBean> resultDS = windowedStream.reduce(new ReduceFunction<TrafficPageViewBean>() {
@Override
public TrafficPageViewBean reduce(TrafficPageViewBean value1, TrafficPageViewBean value2) throws Exception {
value1.setSvCt(value1.getSvCt() + value2.getSvCt());
value1.setUvCt(value1.getUvCt() + value2.getUvCt());
value1.setUjCt(value1.getUjCt() + value2.getUjCt());
value1.setPvCt(value1.getPvCt() + value2.getPvCt());
value1.setDurSum(value1.getDurSum() + value2.getDurSum());
return value1;
}
}, new WindowFunction<TrafficPageViewBean, TrafficPageViewBean, Tuple4<String, String, String, String>, TimeWindow>() {
@Override
public void apply(Tuple4<String, String, String, String> key, TimeWindow window, Iterable<TrafficPageViewBean> input, Collector<TrafficPageViewBean> out) throws Exception {
//获取数据
TrafficPageViewBean next = input.iterator().next();
//补充信息
next.setStt(DateFormatUtil.toYmdHms(window.getStart()));
next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
//修改TS
next.setTs(System.currentTimeMillis());
//输出数据
out.collect(next);
}
});
//TODO 7.将数据写出到ClickHouse
resultDS.print(">>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_traffic_vc_ch_ar_is_new_page_view_window values(?,?,?,?,?,?,?,?,?,?,?,?)"));
//TODO 8.启动任务
env.execute("DwsTrafficVcChArIsNewPageViewWindow");
}
}
流量域页面浏览各窗口汇总表
主要任务
从 Kafka 页面日志主题读取数据,统计当日的首页和商品详情页独立访客数。
思路分析
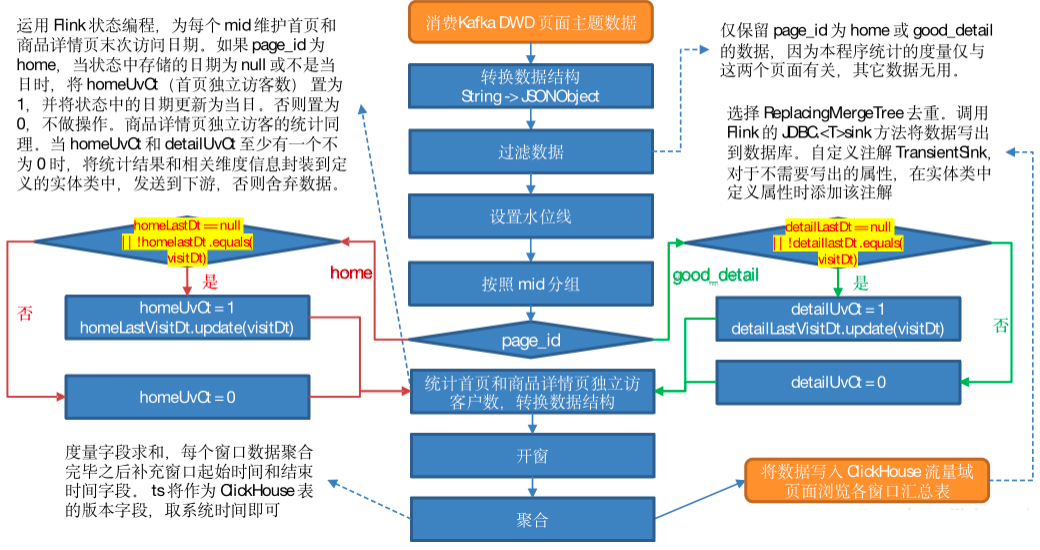
1)读取 Kafka页面主题数据
2)转换数据结构
将流中数据由 String 转换为 JSONObject。
3)过滤数据
仅保留 page_id 为 home 或 good_detail 的数据,因为本程序统计的度量仅与这两个页面有关,其它数据无用。
4)设置水位线
*5)按照 mid 分组
6)统计首页和商品详情页独立访客数,转换数据结构**
运用 Flink 状态编程,为每个 mid 维护首页和商品详情页末次访问日期。如果 page_id 为 home,当状态中存储的日期为 null 或不是当日时,将 homeUvCt(首页独立访客数) 置为 1,并将状态中的日期更新为当日。否则置为 0,不做操作。商品详情页独立访客的统计同理。当 homeUvCt 和 detailUvCt 至少有一个不为 0 时,将统计结果和相关维度信息封装到定义的实体类中,发送到下游,否则舍弃数据。
7)开窗
8)聚合
9)将数据写出到 ClickHouse
图解
ClickHouse建表语句
drop table if exists dws_traffic_page_view_window;
create table if not exists dws_traffic_page_view_window
(
stt DateTime,
edt DateTime,
home_uv_ct UInt64,
good_detail_uv_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 TrafficHomeDetailPageViewBean
@Data
@AllArgsConstructor
public class TrafficHomeDetailPageViewBean {
// 窗口起始时间
String stt;
// 窗口结束时间
String edt;
// 首页独立访客数
Long homeUvCt;
// 商品详情页独立访客数
Long goodDetailUvCt;
// 时间戳
Long ts;
}
2)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwsTrafficPageViewWindow -> ClickHouse(ZK)
public class DwsTrafficPageViewWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.读取 Kafka 页面日志主题数据创建流
String topic = "dwd_traffic_page_log";
String groupId = "dws_traffic_page_view_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JSON对象并过滤(首页与商品详情页)
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
//转换为JSON对象
JSONObject jsonObject = JSON.parseObject(value);
//获取当前页面id
String pageId = jsonObject.getJSONObject("page").getString("page_id");
//过滤出首页与商品详情页的数据
if ("home".equals(pageId) || "good_detail".equals(pageId)) {
out.collect(jsonObject);
}
}
});
//TODO 4.提取事件时间生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = jsonObjDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
return element.getLong("ts");
}
}));
//TODO 5.按照Mid分组
KeyedStream<JSONObject, String> keyedStream = jsonObjWithWmDS.keyBy(json -> json.getJSONObject("common").getString("mid"));
//TODO 6.使用状态编程过滤出首页与商品详情页的独立访客
SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> trafficHomeDetailDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, TrafficHomeDetailPageViewBean>() {
private ValueState<String> homeLastState;
private ValueState<String> detailLastState;
@Override
public void open(Configuration parameters) throws Exception {
StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.build();
ValueStateDescriptor<String> homeStateDes = new ValueStateDescriptor<>("home-state", String.class);
ValueStateDescriptor<String> detailStateDes = new ValueStateDescriptor<>("detail-state", String.class);
//设置TTL
homeStateDes.enableTimeToLive(ttlConfig);
detailStateDes.enableTimeToLive(ttlConfig);
homeLastState = getRuntimeContext().getState(homeStateDes);
detailLastState = getRuntimeContext().getState(detailStateDes);
}
@Override
public void flatMap(JSONObject value, Collector<TrafficHomeDetailPageViewBean> out) throws Exception {
//获取状态数据以及当前数据中的日期
Long ts = value.getLong("ts");
String curDt = DateFormatUtil.toDate(ts);
String homeLastDt = homeLastState.value();
String detailLastDt = detailLastState.value();
//定义访问首页或者详情页的数据
long homeCt = 0L;
long detailCt = 0L;
//如果状态为空或者状态时间与当前时间不同,则为需要的数据
if ("home".equals(value.getJSONObject("page").getString("page_id"))) {
if (homeLastDt == null || !homeLastDt.equals(curDt)) {
homeCt = 1L;
homeLastState.update(curDt);
}
} else {
if (detailLastDt == null || !detailLastDt.equals(curDt)) {
detailCt = 1L;
detailLastState.update(curDt);
}
}
//满足任何一个数据不等于0,则可以写出
if (homeCt == 1L || detailCt == 1L) {
out.collect(new TrafficHomeDetailPageViewBean("", "",
homeCt,
detailCt,
ts));
}
}
});
//TODO 7.开窗聚合
SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> resultDS = trafficHomeDetailDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))).reduce(new ReduceFunction<TrafficHomeDetailPageViewBean>() {
@Override
public TrafficHomeDetailPageViewBean reduce(TrafficHomeDetailPageViewBean value1, TrafficHomeDetailPageViewBean value2) throws Exception {
value1.setHomeUvCt(value1.getHomeUvCt() + value2.getHomeUvCt());
value1.setGoodDetailUvCt(value1.getGoodDetailUvCt() + value2.getGoodDetailUvCt());
return value1;
}
}, new AllWindowFunction<TrafficHomeDetailPageViewBean, TrafficHomeDetailPageViewBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<TrafficHomeDetailPageViewBean> values, Collector<TrafficHomeDetailPageViewBean> out) throws Exception {
//获取数据
TrafficHomeDetailPageViewBean pageViewBean = values.iterator().next();
//补充字段
pageViewBean.setTs(System.currentTimeMillis());
pageViewBean.setStt(DateFormatUtil.toYmdHms(window.getStart()));
pageViewBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
//输出数据
out.collect(pageViewBean);
}
});
//TODO 8.将数据写出到ClickHouse
resultDS.print(">>>>>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_traffic_page_view_window values(?,?,?,?,?)"));
//TODO 9.启动任务
env.execute("DwsTrafficPageViewWindow");
}
}
用户域用户登陆各窗口汇总表
主要任务
从 Kafka 页面日志主题读取数据,统计七日回流用户和当日独立用户数。
思路分析
之前的活跃用户,一段时间未活跃(流失),今日又活跃了,就称为回流用户。此处要求统计回流用户总数。规定当日登陆,且自上次登陆之后至少 7 日未登录的用户为回流用户。
1)读取 Katka 页面主题数据
2)转换数据结构
流中数据由 String 转换为 JSONObject。
3)过滤数据
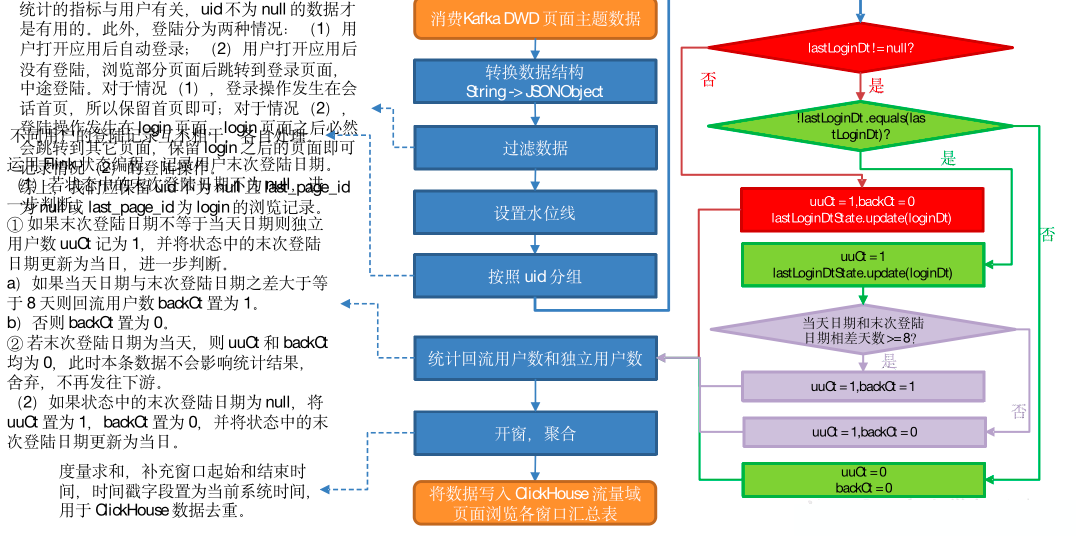
统计的指标与用户有关,uid 不为 null 的数据才是有用的。此外,登陆分为两种情况:
- 用户打开应用后自动登录;
- 用户打开应用后没有登陆,浏览部分页面后跳转到登录页面,中途登陆。
对于情况(1),登录操作发生在会话首页,所以保留首页即可;对于情况(2),登陆操作发生在 login 页面,login 页面之后必然会跳转到其它页面,保留 login 之后的页面即可记录情况(2)的登陆操作。
综上,我们应保留 uid 不为 null 且 last_page_id 为 null 或 last_page_id 为 login 的浏览记录。
4)设置水位线
5)按照 uid分组
不同用户的登陆记录互不相干,各自处理。
6)统计回流用户数和独立用户数
运用 Flink 状态编程,记录用户末次登陆日期。
-
若状态中的末次登陆日期不为 null,进一步判断。
-
如果末次登陆日期不等于当天日期则独立用户数 uuCt 记为 1,并将状态中的末次登陆日期更新为当日,进一步判断。
a)如果当天日期与末次登陆日期之差大于等于 8 天则回流用户数 backCt 置为 1。
b)否则 backCt 置为 0。
-
若末次登陆日期为当天,则 uuCt 和 backCt 均为 0,此时本条数据不会影响统计结果,舍弃,不再发往下游。
-
-
如果状态中的末次登陆日期为 null,将 uuCt 置为 1,backCt 置为 0,并将状态中的末次登陆日期更新为当日。
7)开窗,聚合
度量字段求和,补充窗口起始和结束时间,时间戳字段置为当前系统时间,用于 ClickHouse 数据去重。
8)写入 ClickHouse
图解
ClickHouse建表语句
drop table if exists dws_user_user_login_window;
create table if not exists dws_user_user_login_window
(
stt DateTime,
edt DateTime,
back_ct UInt64,
uu_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 UserLoginBean
@Data
@AllArgsConstructor
public class UserLoginBean {
// 窗口起始时间
String stt;
// 窗口终止时间
String edt;
// 回流用户数
Long backCt;
// 独立用户数
Long uuCt;
// 时间戳
Long ts;
}
2)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwsUserUserLoginWindow -> ClickHouse(ZK)
public class DwsUserUserLoginWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.读取Kafka 页面日志主题创建流
String topic = "dwd_traffic_page_log";
String groupId = "dws_user_login_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.转换数据为JSON对象并过滤数据
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
//转换为JSON对象
JSONObject jsonObject = JSON.parseObject(value);
//获取UID以及上一跳页面
String uid = jsonObject.getJSONObject("common").getString("uid");
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
//当UID不等于空并且上一跳页面为null或者为"login"才是登录数据
if (uid != null && (lastPageId == null || lastPageId.equals("login"))) {
out.collect(jsonObject);
}
}
});
//TODO 4.提取事件时间生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = jsonObjDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
return element.getLong("ts");
}
}));
//TODO 5.按照uid分组
KeyedStream<JSONObject, String> keyedStream = jsonObjWithWmDS.keyBy(json -> json.getJSONObject("common").getString("uid"));
//TODO 6.使用状态编程获取独立用户以及七日回流用户
SingleOutputStreamOperator<UserLoginBean> userLoginDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, UserLoginBean>() {
private ValueState<String> lastLoginState;
@Override
public void open(Configuration parameters) throws Exception {
lastLoginState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-login", String.class));
}
@Override
public void flatMap(JSONObject value, Collector<UserLoginBean> out) throws Exception {
//获取状态日期以及当前数据日期
String lastLoginDt = lastLoginState.value();
Long ts = value.getLong("ts");
String curDt = DateFormatUtil.toDate(ts);
//定义当日独立用户数&七日回流用户数
long uv = 0L;
long backUv = 0L;
if (lastLoginDt == null) {
uv = 1L;
lastLoginState.update(curDt);
} else if (!lastLoginDt.equals(curDt)) {
uv = 1L;
lastLoginState.update(curDt);
if ((DateFormatUtil.toTs(curDt) - DateFormatUtil.toTs(lastLoginDt)) / (24 * 60 * 60 * 1000L) >= 8) {
backUv = 1L;
}
}
if (uv != 0L) {
out.collect(new UserLoginBean("", "",
backUv, uv, ts));
}
}
});
//TODO 7.开窗聚合
SingleOutputStreamOperator<UserLoginBean> resultDS = userLoginDS.windowAll(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<UserLoginBean>() {
@Override
public UserLoginBean reduce(UserLoginBean value1, UserLoginBean value2) throws Exception {
value1.setBackCt(value1.getBackCt() + value2.getBackCt());
value1.setUuCt(value1.getUuCt() + value2.getUuCt());
return value1;
}
}, new AllWindowFunction<UserLoginBean, UserLoginBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<UserLoginBean> values, Collector<UserLoginBean> out) throws Exception {
UserLoginBean next = values.iterator().next();
next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
next.setStt(DateFormatUtil.toYmdHms(window.getStart()));
next.setTs(System.currentTimeMillis());
out.collect(next);
}
});
//TODO 8.将数据写出到ClickHouse
resultDS.print(">>>>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_user_user_login_window values(?,?,?,?,?)"));
//TODO 9.启动任务
env.execute("DwsUserUserLoginWindow");
}
}
用户域用户注册各窗口汇总表
主要任务
从 DWD 层用户注册表中读取数据,统计各窗口注册用户数,写入 ClickHouse。
思路分析
1)读取 Kafka 用户注册主题数据
2)转换数据结构
String 转换为 JSONObject。
3)设置水位线
4)开窗、聚合
5)写人 ClickHouse
图解

ClickHouse建表语句
drop table if exists dws_user_user_register_window;
create table if not exists dws_user_user_register_window
(
stt DateTime,
edt DateTime,
register_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 UserRegisterBean
@Data
@AllArgsConstructor
public class UserRegisterBean {
// 窗口起始时间
String stt;
// 窗口终止时间
String edt;
// 注册用户数
Long registerCt;
// 时间戳
Long ts;
}
2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdUserRegister -> Kafka(ZK) -> DwsUserUserRegisterWindow -> ClickHouse(ZK)
public class DwsUserUserRegisterWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.读取Kafka DWD层用户注册主题数据创建流
String topic = "dwd_user_register";
String groupId = "dws_user_user_register_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JavaBean对象
SingleOutputStreamOperator<UserRegisterBean> userRegisterDS = kafkaDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
//yyyy-MM-dd HH:mm:ss
String createTime = jsonObject.getString("create_time");
return new UserRegisterBean("",
"",
1L,
DateFormatUtil.toTs(createTime, true));
});
//TODO 4.提取时间戳生成Watermark
SingleOutputStreamOperator<UserRegisterBean> userRegisterWithWmDS = userRegisterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<UserRegisterBean>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<UserRegisterBean>() {
@Override
public long extractTimestamp(UserRegisterBean element, long recordTimestamp) {
return element.getTs();
}
}));
//TODO 5.开窗聚合
SingleOutputStreamOperator<UserRegisterBean> resultDS = userRegisterWithWmDS.windowAll(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<UserRegisterBean>() {
@Override
public UserRegisterBean reduce(UserRegisterBean value1, UserRegisterBean value2) throws Exception {
value1.setRegisterCt(value1.getRegisterCt() + value2.getRegisterCt());
return value1;
}
}, new AllWindowFunction<UserRegisterBean, UserRegisterBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<UserRegisterBean> values, Collector<UserRegisterBean> out) throws Exception {
UserRegisterBean userRegisterBean = values.iterator().next();
userRegisterBean.setTs(System.currentTimeMillis());
userRegisterBean.setStt(DateFormatUtil.toYmdHms(window.getStart()));
userRegisterBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
out.collect(userRegisterBean);
}
});
//TODO 6.将数据写出到ClickHouse
resultDS.print(">>>>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_user_user_register_window values(?,?,?,?)"));
//TODO 7.启动任务
env.execute("DwsUserUserRegisterWindow");
}
}
交易域加购各窗口汇总表
主要任务
从 Kafka 读取用户加购明细数据,统计每日各窗口加购独立用户数,写入 ClickHouse。
思路分析
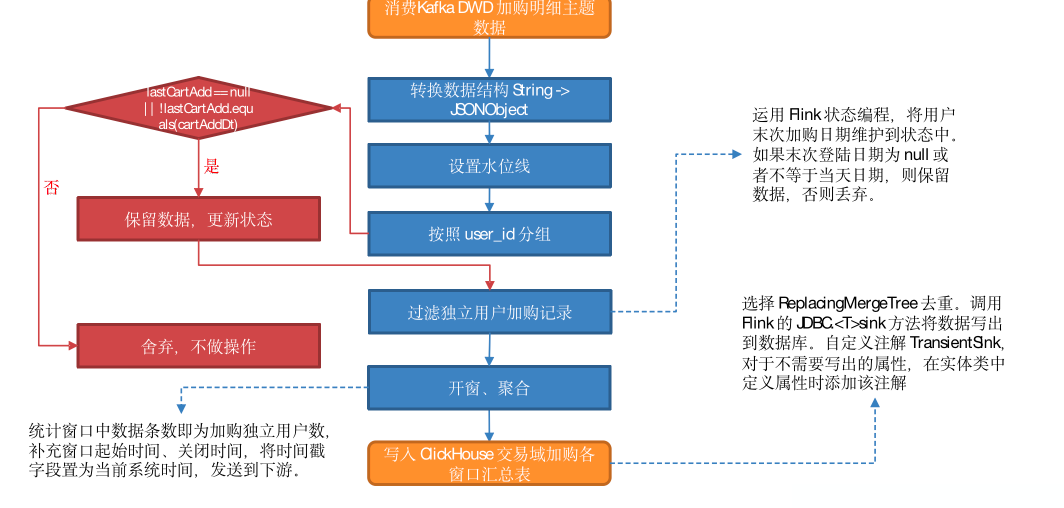
1) 从 Katka 加购明细主题读取数据
2)转换数据结构
将流中数据由 String 转换为 JSONObject。
3)设置水位线
4) 按照用户 id 分组
5)过滤独立用户加购记录
运用 Flink 状态编程,将用广末次加购日期维护到状态中。
如果末次登陆日期为 null 或者不等于当天日期,则保留数据并更新状态,否则丢弃,不做操作。
6)开窗、聚合
统计窗口中数据条数即为加购独立用户数,补充窗口起始时间、关闭时间,将时间戳字段置为当前系统时间,发送到下游。
7)将数据写入 ClickHouse.
图解
ClickHouse建表语句
drop table if exists dws_trade_cart_add_uu_window;
create table if not exists dws_trade_cart_add_uu_window
(
stt DateTime,
edt DateTime,
cart_add_uu_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 CartAddUuBean
@Data
@AllArgsConstructor
public class CartAddUuBean {
// 窗口起始时间
String stt;
// 窗口闭合时间
String edt;
// 加购独立用户数
Long cartAddUuCt;
// 时间戳
Long ts;
}
2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeCartAdd -> Kafka(ZK) -> DwdTradeCartAdd -> ClickHouse(ZK)
public class DwsTradeCartAddUuWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.读取 Kafka DWD层 加购事实表
String topic = "dwd_trade_cart_add";
String groupId = "dws_trade_cart_add_uu_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject);
//TODO 4.提取事件时间生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = jsonObjDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
String operateTime = element.getString("operate_time");
if (operateTime != null) {
return DateFormatUtil.toTs(operateTime, true);
} else {
return DateFormatUtil.toTs(element.getString("create_time"), true);
}
}
}));
//TODO 5.按照user_id分组
KeyedStream<JSONObject, String> keyedStream = jsonObjWithWmDS.keyBy(json -> json.getString("user_id"));
//TODO 6.使用状态编程提取独立加购用户
SingleOutputStreamOperator<CartAddUuBean> cartAddDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, CartAddUuBean>() {
private ValueState<String> lastCartAddState;
@Override
public void open(Configuration parameters) throws Exception {
StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("last-cart", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
lastCartAddState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void flatMap(JSONObject value, Collector<CartAddUuBean> out) throws Exception {
//获取状态数据以及当前数据的日期
String lastDt = lastCartAddState.value();
String operateTime = value.getString("operate_time");
String curDt = null;
if (operateTime != null) {
curDt = operateTime.split(" ")[0];
} else {
String createTime = value.getString("create_time");
curDt = createTime.split(" ")[0];
}
if (lastDt == null || !lastDt.equals(curDt)) {
lastCartAddState.update(curDt);
out.collect(new CartAddUuBean(
"",
"",
1L,
null));
}
}
});
//TODO 7.开窗、聚合
SingleOutputStreamOperator<CartAddUuBean> resultDS = cartAddDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10)))
.reduce(new ReduceFunction<CartAddUuBean>() {
@Override
public CartAddUuBean reduce(CartAddUuBean value1, CartAddUuBean value2) throws Exception {
value1.setCartAddUuCt(value1.getCartAddUuCt() + value2.getCartAddUuCt());
return value1;
}
}, new AllWindowFunction<CartAddUuBean, CartAddUuBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<CartAddUuBean> values, Collector<CartAddUuBean> out) throws Exception {
CartAddUuBean next = values.iterator().next();
next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
next.setStt(DateFormatUtil.toYmdHms(window.getStart()));
next.setTs(System.currentTimeMillis());
out.collect(next);
}
});
//TODO 8.将数据写出到ClickHouse
resultDS.print(">>>>>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_cart_add_uu_window values (?,?,?,?)"));
//TODO 9.启动任务
env.execute("DwsTradeCartAddUuWindow");
}
}
交易域支付各窗口汇总表(※)
主要任务
从 Kafka 读取交易域支付成功主题数据,统计支付成功独立用户数和首次支付成功用户数。
思路分析
我们在 DWD 层提到,订单明细表数据生成过程中会形成回撤流。left join 生成的数据集中,相同唯一键的数据可能会有多条。上文已有讲解,不再赘述。回撤数据在 Kafka 中以 null 值的形式存在,只需要简单判断即可过滤。我们需要考虑的是如何对其余数据去重。
对回撤流数据生成过程进行分析,可以发现,字段内容完整数据的生成一定晚于不完整数据的生成,要确保统计结果的正确性,我们应保留字段内容最全的数据,基于以上论述,内容最全的数据生成时间最晚。要想通过时间筛选这部分数据,首先要获取数据生成时间。
1)知识储备
FlinkSQL 提供了几个可以获取当前时间戳的函数:
- localtimestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- current_timestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- now():与 current_timestamp 相同。
- current_row_timestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。无论在流处理模式还是批处理模式下,都会对每行数据计算一次时间。
函数测试。查询语句如下:
tableEnv.sqlQuery("select localtimestamp," +
"current_timestamp," +
"now()," +
"current_row_timestamp()")
.execute()
.print();
查询结果如下:
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| op | localtimestamp | current_timestamp | EXPR$2 | EXPR$3 |
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| +I | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529Z |
+----+-------------------------+-------------------------+-------------------------+-------------------------+
1 row in set
动态表属于流处理模式,所以四种函数任选其一即可。此处选择 current_row_timestamp()。
2)时间比较工具类
动态表中获取的数据生成时间精确到毫秒,前文提供的日期格式化工具类无法实现此类日期字符串向时间戳的转化,也就不能通过直接转化为时间戳的方式比较两条数据的生成时间。因此,单独封装工具类用于比较 TIME_STAMP(3) 类型的时间。比较逻辑是将时间拆分成两部分:小数点之前和小数点之后的。小数点之前的日期格式为 yyyy-MM-dd HH:mm:ss,这部分可以直接转化为时间戳比较,如果这部分时间相同,再比较小数点后面的部分,将小数点后面的部分转换为整型比较,从而实现 TIME_STAMP(3) 类型时间的比较。
3)去重思路
获取了数据生成时间,接下来要考虑的问题就是如何获取生成时间最晚的数据。此处提供三种思路:
- 按照唯一键分组,开窗,在窗口闭合前比较窗口中所有数据的时间,将生成时间最晚的数据发送到下游,其它数据舍弃。
- 按照唯一键分组,对于每一个唯一键,维护状态和定时器,当状态中数据为 null 时注册定时器,把数据维护到状态中。此后每来一条数据都比较它与状态中数据的生成时间,状态中只保留生成最晚的数据。如果两条数据生成时间相同(系统时间精度不足),则保留后进入算子的数据。因为我们的 Flink 程序并行度和 Kafka 分区数相同,可以保证数据有序,后来的数据就是最新的数据。(参考交易域支付各窗口汇总表)
- 如果后续需求没有用到left join右表的字段,那么则可以只保留第一条数据进行输出。(参考交易域下单各窗口汇总表)
看需求使用第三种方案,前两种方案都可行,此处选择方案二。(注:本需求其实可以使用方案三)
本节的数据来源于 Kafka dwd_trade_pay_detail_suc 主题,后者的数据由 payment_info、dwd_trade_order_detail、base_dic 三张表通过内连接关联获得,这一过程不会产生重复数据,因此,该表的重复数据由订单明细表决定。而 dwd_trade_order_detail 表的数据来源于 dwd_trade_order_pre_process,后者数据生成过程中使用了 left join,因此包含 null 数据和重复数据。订单明细表读取数据使用的 Kafka Connector 会过滤掉 null 数据,程序内只做了过滤没有去重,因此该表不存在 null 数据,但对于相同唯一键 order_detail_id 存在重复数据。综上,支付成功明细表存在唯一键 order_detail_id 相同的数据,但不存在 null 数据,因此仅须去重。
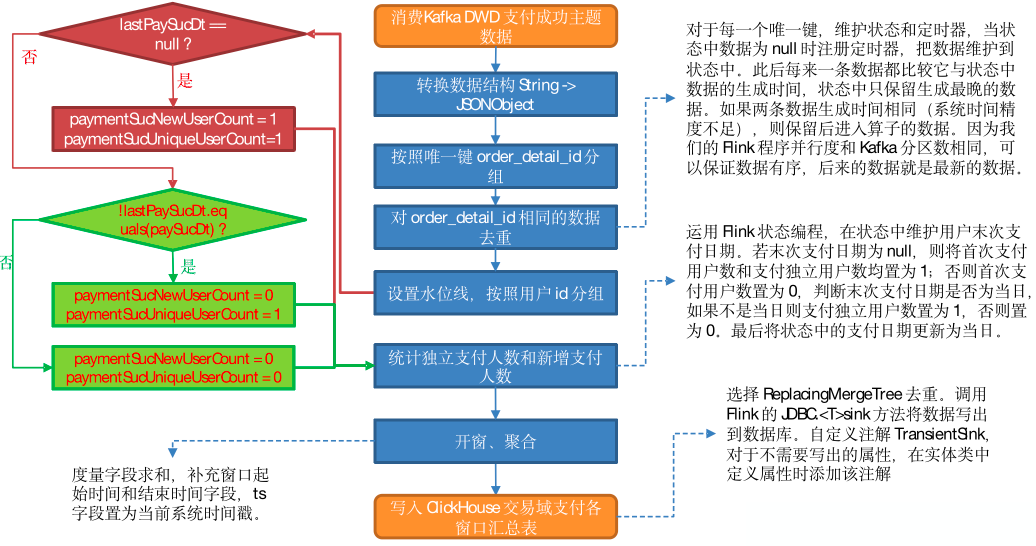
4)实现步骤
(1)从 Kafka 支付成功明细主题读取数据
(2)转换数据结构
String 转换为 JSONObject。
(3)按照唯一键分组
(4)去重
与前文同理。
(5)设置水位线,按照 user_id 分组
(6)统计独立支付人数和新增支付人数
运用 Flink 状态编程,在状态中维护用户末次支付日期。
若末次支付日期为 null,则将首次支付用户数和支付独立用户数均置为 1;否则首次支付用户数置为 0,判断末次支付日期是否为当日,如果不是当日则支付独立用户数置为 1,否则置为 0。最后将状态中的支付日期更新为当日。
(7)开窗、聚合
度量字段求和,补充窗口起始时间和结束时间字段,ts 字段置为当前系统时间戳。
(8)写出到 ClickHouse
图解
ClickHouse建表语句
drop table if exists dws_trade_payment_suc_window;
create table if not exists dws_trade_payment_suc_window
(
stt DateTime,
edt DateTime,
payment_suc_unique_user_count UInt64,
payment_new_user_count UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 TradePaymentWindowBean
@Data
@AllArgsConstructor
public class TradePaymentWindowBean {
// 窗口起始时间
String stt;
// 窗口终止时间
String edt;
// 支付成功独立用户数
Long paymentSucUniqueUserCount;
// 支付成功新用户数
Long paymentSucNewUserCount;
// 时间戳
Long ts;
}
2)FlinkSQL 时间数据类型 TimestampLtz3 比较工具类 TimestampLtz3CompareUtil
public class TimestampLtz3CompareUtil {
// 数据格式 2022-04-01 10:20:47.302Z
// 数据格式 2022-04-01 10:20:47.041Z
// 数据格式 2022-04-01 10:20:47.410Z
// 数据格式 2022-04-01 10:20:47.41Z
public static int compare(String timestamp1, String timestamp2) {
// 1. 去除末尾的时区标志,'Z' 表示 0 时区
String cleanedTime1 = timestamp1.substring(0, timestamp1.length() - 1);
String cleanedTime2 = timestamp2.substring(0, timestamp2.length() - 1);
// 2. 提取小于 1秒的部分
String[] timeArr1 = cleanedTime1.split("\\.");
String[] timeArr2 = cleanedTime2.split("\\.");
String microseconds1 = new StringBuilder(timeArr1[timeArr1.length - 1])
.append("000").toString().substring(0, 3);
String microseconds2 = new StringBuilder(timeArr2[timeArr2.length - 1])
.append("000").toString().substring(0, 3);
int micro1 = Integer.parseInt(microseconds1);
int micro2 = Integer.parseInt(microseconds2);
// 3. 提取 yyyy-MM-dd HH:mm:ss 的部分
String date1 = timeArr1[0];
String date2 = timeArr2[0];
Long ts1 = DateFormatUtil.toTs(date1, true);
Long ts2 = DateFormatUtil.toTs(date2, true);
// 4. 获得精确到毫秒的时间戳
long microTs1 = ts1 + micro1;
long microTs2 = ts2 + micro2;
long divTs = microTs1 - microTs2;
return divTs < 0 ? -1 : divTs == 0 ? 0 : 1;
}
public static void main(String[] args) {
System.out.println(compare("2022-04-01 11:10:55.042Z","2022-04-01 11:10:55.041Z"));
//System.out.println(Integer.parseInt("095"));
}
}
3)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) -> DwdTradePayDetailSuc -> Kafka(ZK) -> DwsTradePaymentSucWindow -> ClickHouse(ZK)
public class DwsTradePaymentSucWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //生产环境中设置为Kafka主题的分区数
//1.1 开启CheckPoint
//env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//1.2 设置状态后端
//env.setStateBackend(new HashMapStateBackend());
//env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck");
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//1.3 设置状态的TTL 生产环境设置为最大乱序程度
//tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));
//TODO 2.读取DWD层成功支付主题数据创建流
String topic = "dwd_trade_pay_detail_suc";
String groupId = "dws_trade_payment_suc_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
System.out.println(">>>>>>>" + value);
}
}
});
//TODO 4.按照订单明细id分组
KeyedStream<JSONObject, String> jsonObjKeyedByDetailIdDS = jsonObjDS.keyBy(json -> json.getString("order_detail_id"));
//TODO 5.使用状态编程保留最新的数据输出
SingleOutputStreamOperator<JSONObject> filterDS = jsonObjKeyedByDetailIdDS.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() {
private ValueState<JSONObject> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<JSONObject>("value-state", JSONObject.class));
}
@Override
public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {
//获取状态中的数据
JSONObject state = valueState.value();
//判断状态是否为null
if (state == null) {
valueState.update(value);
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 5000L);
} else {
String stateRt = state.getString("row_op_ts");
String curRt = value.getString("row_op_ts");
int compare = TimestampLtz3CompareUtil.compare(stateRt, curRt);
if (compare != 1) {
valueState.update(value);
}
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception {
super.onTimer(timestamp, ctx, out);
//输出并清空状态数据
JSONObject value = valueState.value();
out.collect(value);
valueState.clear();
}
});
//TODO 6.提取事件时间生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
String callbackTime = element.getString("callback_time");
return DateFormatUtil.toTs(callbackTime, true);
}
}));
//TODO 7.按照user_id分组
KeyedStream<JSONObject, String> keyedByUidDS = jsonObjWithWmDS.keyBy(json -> json.getString("user_id"));
//TODO 8.提取独立支付成功用户数
SingleOutputStreamOperator<TradePaymentWindowBean> tradePaymentDS = keyedByUidDS.flatMap(new RichFlatMapFunction<JSONObject, TradePaymentWindowBean>() {
private ValueState<String> lastDtState;
@Override
public void open(Configuration parameters) throws Exception {
lastDtState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-dt", String.class));
}
@Override
public void flatMap(JSONObject value, Collector<TradePaymentWindowBean> out) throws Exception {
//取出状态中以及当前数据的日期
String lastDt = lastDtState.value();
String curDt = value.getString("callback_time").split(" ")[0];
//定义当日支付人数以及新增付费人数
long paymentSucUniqueUserCount = 0L;
long paymentSucNewUserCount = 0L;
//判断状态日期是否为null
if (lastDt == null) {
paymentSucUniqueUserCount = 1L;
paymentSucNewUserCount = 1L;
lastDtState.update(curDt);
} else if (!lastDt.equals(curDt)) {
paymentSucUniqueUserCount = 1L;
lastDtState.update(curDt);
}
//返回数据
if (paymentSucUniqueUserCount == 1L) {
out.collect(new TradePaymentWindowBean("",
"",
paymentSucUniqueUserCount,
paymentSucNewUserCount,
null));
}
}
});
//TODO 9.开窗、聚合
SingleOutputStreamOperator<TradePaymentWindowBean> resultDS = tradePaymentDS.windowAll(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<TradePaymentWindowBean>() {
@Override
public TradePaymentWindowBean reduce(TradePaymentWindowBean value1, TradePaymentWindowBean value2) throws Exception {
value1.setPaymentSucUniqueUserCount(value1.getPaymentSucUniqueUserCount() + value2.getPaymentSucUniqueUserCount());
value1.setPaymentSucNewUserCount(value1.getPaymentSucNewUserCount() + value2.getPaymentSucNewUserCount());
return value1;
}
}, new AllWindowFunction<TradePaymentWindowBean, TradePaymentWindowBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<TradePaymentWindowBean> values, Collector<TradePaymentWindowBean> out) throws Exception {
TradePaymentWindowBean next = values.iterator().next();
next.setTs(System.currentTimeMillis());
next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
next.setStt(DateFormatUtil.toYmdHms(window.getStart()));
out.collect(next);
}
});
//TODO 10.将数据写出到ClickHouse
resultDS.print(">>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_payment_suc_window values(?,?,?,?,?)"));
//TODO 11.启动任务
env.execute("DwsTradePaymentSucWindow");
}
}
交易域下单各窗口汇总表(※)
主要任务
从 Kafka 订单明细主题读取数据,对数据去重,统计当日下单独立用户数和新增下单用户数,封装为实体类,写入 ClickHouse。
思路分析
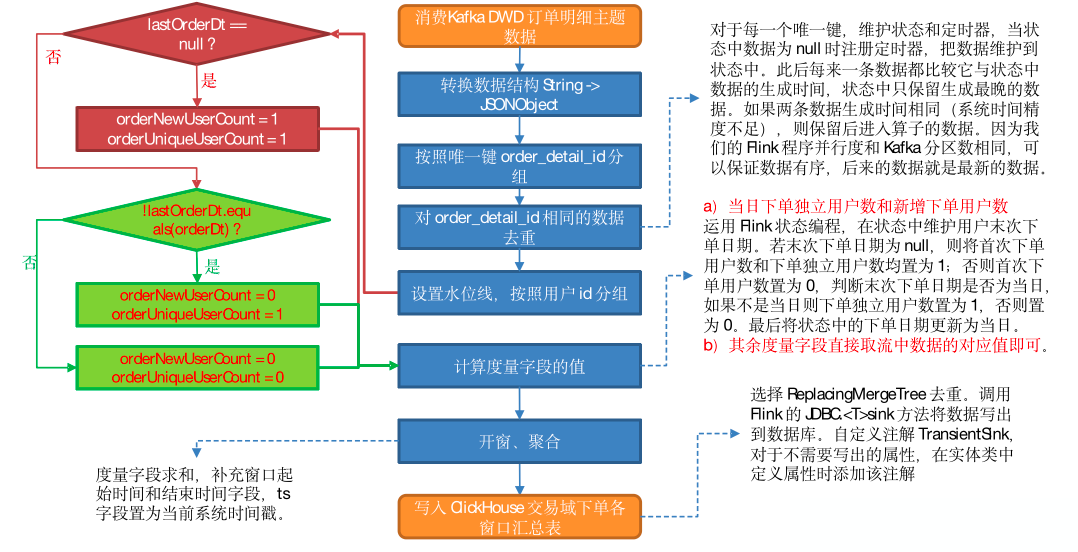
1)从 Kafka订单明细主题读取数据
2)转换数据结构
Kafka 订单明细主题的数据是通过 Kafka-Connector 从订单预处理主题读取后进行过滤获取的,Kafka-Connector 会过滤掉主题中的 null 数据,因此订单明细主题不存在为 null 的数据,直接转换数据结构即可。
3)按照 order_detail_id分组
order_detail_id 为数据唯一键。
4)对 order_detailid 相同的数据去重
按照上文提到的方案对数据去重。
5)设置水位线
6)按照用户 id 分组
7)计算度量字段的值
(1)当日下单独立用户数和新增下单用户数
运用 Flink 状态编程,在状态中维护用户末次下单日期。
若末次下单日期为 null,则将首次下单用户数和下单独立用户数均置为 1;否则首次下单用户数置为 0,判断末次下单日期是否为当日,如果不是当日则下单独立用户数置为 1,否则置为 0。最后将状态中的下单日期更新为当日。
(2)其余度量字段直接取流中数据的对应值即可。
8)开窗、聚合
度量字段求和,补充窗口起始时间和结束时间字段,ts 字段置为当前系统时间戳。
9)写出到 ClickHouse
图解
建表语句
drop table if exists dws_trade_order_window;
create table if not exists dws_trade_order_window
(
stt DateTime,
edt DateTime,
order_unique_user_count UInt64,
order_new_user_count UInt64,
order_activity_reduce_amount Decimal(38, 20),
order_coupon_reduce_amount Decimal(38, 20),
order_origin_total_amount Decimal(38, 20),
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);
代码
1)实体类 TradeOrderBean
@Data
@AllArgsConstructor
@Builder
public class TradeOrderBean {
// 窗口起始时间
String stt;
// 窗口关闭时间
String edt;
// 下单独立用户数
Long orderUniqueUserCount;
// 下单新用户数
Long orderNewUserCount;
// 下单活动减免金额
Double orderActivityReduceAmount;
// 下单优惠券减免金额
Double orderCouponReduceAmount;
// 下单原始金额
Double orderOriginalTotalAmount;
// 时间戳
Long ts;
}
2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) -> DwsTradeOrderWindow -> ClickHouse(ZK)
public class DwsTradeOrderWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //生产环境中设置为Kafka主题的分区数
//1.1 开启CheckPoint
//env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//1.2 设置状态后端
//env.setStateBackend(new HashMapStateBackend());
//env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck");
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//1.3 设置状态的TTL 生产环境设置为最大乱序程度
//tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));
//TODO 2.读取Kafka DWD层下单主题数据创建流
String topic = "dwd_trade_order_detail";
String groupId = "dws_trade_order_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
System.out.println("Value>>>>>>>>" + value);
}
}
});
//TODO 4.按照 order_detail_id 分组
KeyedStream<JSONObject, String> keyedByDetailIdDS = jsonObjDS.keyBy(json -> json.getString("id"));
//TODO 5.针对 order_detail_id 进行去重(保留第一条数据即可)
SingleOutputStreamOperator<JSONObject> filterDS = keyedByDetailIdDS.filter(new RichFilterFunction<JSONObject>() {
private ValueState<String> valueState;
@Override
public void open(Configuration parameters) throws Exception {
StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.seconds(5))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("is-exists", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
valueState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public boolean filter(JSONObject value) throws Exception {
//获取状态数据
String state = valueState.value();
//判断状态是否为null
if (state == null) {
valueState.update("1");
return true;
} else {
return false;
}
}
});
//TODO 6.提取事件时间生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjWithWmDS = filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
return DateFormatUtil.toTs(element.getString("create_time"), true);
}
}));
//TODO 7.按照 user_id 分组
KeyedStream<JSONObject, String> keyedByUidDS = jsonObjWithWmDS.keyBy(json -> json.getString("user_id"));
//TODO 8.提取独立下单用户
SingleOutputStreamOperator<TradeOrderBean> tradeOrderDS = keyedByUidDS.map(new RichMapFunction<JSONObject, TradeOrderBean>() {
private ValueState<String> lastOrderDtState;
@Override
public void open(Configuration parameters) throws Exception {
lastOrderDtState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-order", String.class));
}
@Override
public TradeOrderBean map(JSONObject value) throws Exception {
//获取状态中以及当前数据的日期
String lastOrderDt = lastOrderDtState.value();
String curDt = value.getString("create_time").split(" ")[0];
//定义当天下单人数以及新增下单人数
long orderUniqueUserCount = 0L;
long orderNewUserCount = 0L;
//判断状态是否为null
if (lastOrderDt == null) {
orderUniqueUserCount = 1L;
orderNewUserCount = 1L;
lastOrderDtState.update(curDt);
} else if (!lastOrderDt.equals(curDt)) {
orderUniqueUserCount = 1L;
lastOrderDtState.update(curDt);
}
//取出下单件数以及单价
Integer skuNum = value.getInteger("sku_num");
Double orderPrice = value.getDouble("order_price");
Double splitActivityAmount = value.getDouble("split_activity_amount");
if (splitActivityAmount == null) {
splitActivityAmount = 0.0D;
}
Double splitCouponAmount = value.getDouble("split_coupon_amount");
if (splitCouponAmount == null) {
splitCouponAmount = 0.0D;
}
return new TradeOrderBean("", "",
orderUniqueUserCount,
orderNewUserCount,
splitActivityAmount,
splitCouponAmount,
skuNum * orderPrice,
null);
}
});
//TODO 9.开窗、聚合
SingleOutputStreamOperator<TradeOrderBean> resultDS = tradeOrderDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10)))
.reduce(new ReduceFunction<TradeOrderBean>() {
@Override
public TradeOrderBean reduce(TradeOrderBean value1, TradeOrderBean value2) throws Exception {
value1.setOrderUniqueUserCount(value1.getOrderUniqueUserCount() + value2.getOrderUniqueUserCount());
value1.setOrderNewUserCount(value1.getOrderNewUserCount() + value2.getOrderNewUserCount());
value1.setOrderOriginalTotalAmount(value1.getOrderOriginalTotalAmount() + value2.getOrderOriginalTotalAmount());
value1.setOrderActivityReduceAmount(value1.getOrderActivityReduceAmount() + value2.getOrderActivityReduceAmount());
value1.setOrderCouponReduceAmount(value1.getOrderCouponReduceAmount() + value2.getOrderCouponReduceAmount());
return value1;
}
}, new AllWindowFunction<TradeOrderBean, TradeOrderBean, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<TradeOrderBean> values, Collector<TradeOrderBean> out) throws Exception {
TradeOrderBean tradeOrderBean = values.iterator().next();
tradeOrderBean.setTs(System.currentTimeMillis());
tradeOrderBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
tradeOrderBean.setStt(DateFormatUtil.toYmdHms(window.getStart()));
out.collect(tradeOrderBean);
}
});
//TODO 10.将数据写出到ClickHouse
resultDS.print(">>>>>>>>>>>");
resultDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_order_window values(?,?,?,?,?,?,?,?)"));
//TODO 11.启动任务
env.execute("DwsTradeOrderWindow");
}
}
交易域用户-SPU粒度下单各窗口汇总表(※)
主要任务
从 Kafka 订单明细主题读取数据,过滤 null 数据并按照唯一键对数据去重,关联维度信息,按照维度分组,统计各维度各窗口的订单数和订单金额,将数据写入 ClickHouse 交易域品牌-品类-用户-SPU粒度下单各窗口汇总表。
思路分析
与上文提到的 DWS 层宽表相比,本程序新增了维度关联操作。
维度表保存在 HBase,首先要在 PhoenixUtil 工具类中补充查询方法。
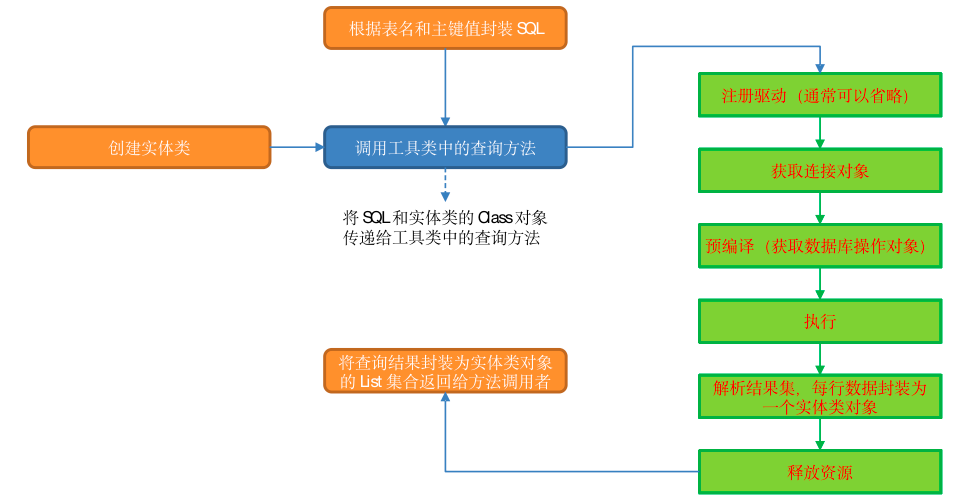
PhoenixUtil查询方法思路
本程序要通过已知的主键、表名从 HBase 中获取相关维度字段的值。根据已知信息,我们可以拼接查询语句,通过参数传递给查询方法,在方法内部执行注册驱动、获取连接对象、预编译(获取数据库操作对象)、执行、解析结果集、关闭资源六个步骤即可取出数据。
查询结果必然要通过返回值的方式将数据传递给调用者。那么,返回值应该是什么类型?查询结果可能有多条,所以返回值应该是一个集合。确定了这一点,接下来要考虑集合元素用什么类型?查询结果可能有多个字段,此处提出两种方案:元组或实体类。下文将对两种方案的实现方式进行分析。
(1)元组
如果用元组封装每一行的查询结果,可以有两种策略:
- 把元组的元素个数传递给方法,然后通过 switch … case … 针对不同的元素个数调用对应的元组 API 对查询结果进行封装;
- 把元组的 Class 对象传给方法,通过反射的方式将查询结果赋值给元组对象。
第一种方案的问题是需要编写大量的重复代码,对于每一个分支都要写一遍相同的处理逻辑;方法二的问题是丢失了元组元素的类型信息。方案二实现示例如下:
public class TupleTest {
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Tuple3> tuple3Class = Tuple3.class;
Tuple3 tuple3 = tuple3Class.newInstance();
Field[] declaredFields = tuple3Class.getDeclaredFields();
for (int i = 1; i < declaredFields.length; i++) {
Field declaredField = declaredFields[i];
declaredField.setAccessible(true);
declaredField.set(tuple3, (char)('a' + i));
}
System.out.println(tuple3);
}
}
结果如下:
(b,c,d)
由于没有元组元素的类型信息,所以只能调用 Field 对象的 set 方法赋值,导致元组元素类型均为 Object,如此一来可能会为下游数据处理带来不便。
此外,Flink 提供的元组最大元素个数为 25,当查询结果字段过多时会出问题。
(2)实体类
将实体类的 Class 对象通过参数传递到方法内,通过反射将查询结果赋值给实体类对象。
基于以上分析,此处选择自定义实体类作为集合元素,查询结果的每一行对应一个实体类对象,将所有对象封装到 List 集合中,返回给方法调用者。
Phoenix 维度查询图解:
旁路缓存优化
外部数据源的查询常常是流式计算的性能瓶颈。以本程序为例,每次查询都要连接 Hbase,数据传输需要做序列化、反序列化,还有网络传输,严重影响时效性。可以通过旁路缓存对查询进行优化。
旁路缓存模式是一种非常常见的按需分配缓存模式。所有请求优先访问缓存,若缓存命中,直接获得数据返回给请求者。如果未命中则查询数据库,获取结果后,将其返回并写入缓存以备后续请求使用。
(1)旁路缓存策略应注意两点
- 缓存要设过期时间,不然冷数据会常驻缓存,浪费资源。
- 要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
(2)缓存的选型
一般两种:堆缓存或者独立缓存服务(memcache,redis)
- 堆缓存,性能更好,效率更高,因为数据访问路径更短。但是难于管理,其它进程无法维护缓存中的数据。
- 独立缓存服务(redis,memcache),会有创建连接、网络IO等消耗,较堆缓存略差,但性能尚可。独立缓存服务便于维护和扩展,对于数据会发生变化且数据量很大的场景更加适用,此处选择独立缓存服务,将 redis 作为缓存介质。
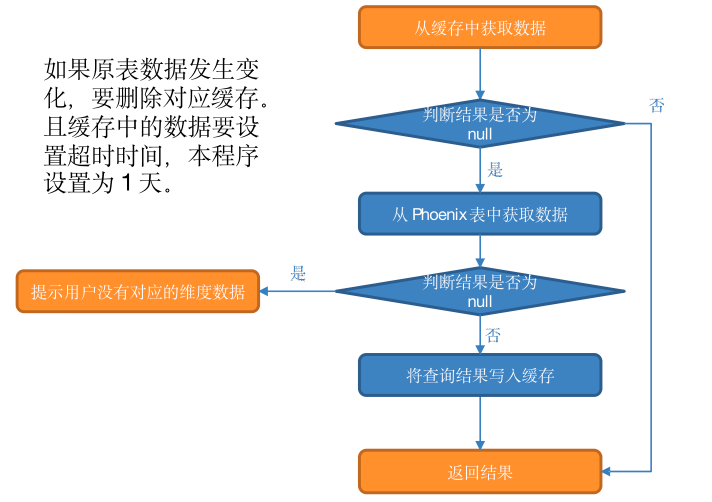
(3)实现步骤
-
从缓存中获取数据:
如果查询结果不为 null,则返回结果。
如果缓存中获取的结果为 null,则从 Phoenix 表中查询数据。
-
如果结果非空则将数据写入缓存后返回结果。
否则提示用户:没有对应的维度数据
注意:缓存中的数据要设置超时时间,本程序设置为 1 天。此外,如果原表数据发生变化,要删除对应缓存。为了实现此功能,需要对维度分流程序做如下修改:
- 在 MyBroadcastFunction的 processElement 方法内将操作类型字段添加到 JSON 对象中。
- 在 DimUtil 工具类中添加 deleteCached 方法,用于删除变更数据的缓存信息。
- 在 MyPhoenixSink 的 invoke 方法中补充对于操作类型的判断,如果操作类型为 update 则清除缓存。
旁路缓存图解
异步 IO
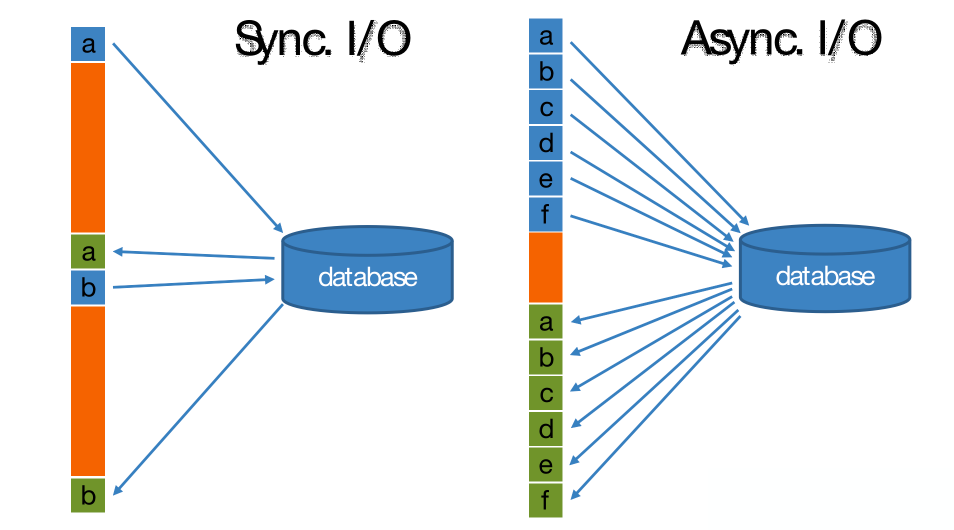
在Flink 流处理过程中,经常需要和外部系统进行交互,如通过维度表补全事实表中的维度字段。
默认情况下,在Flink 算子中,单个并行子任务只能以同步方式与外部系统交互:将请求发送到外部存储,IO阻塞,等待请求返回,然后继续发送下一个请求。这种方式将大量时间耗费在了等待结果上。
为了提高处理效率,可以有两种思路。
- 增加算子的并行度,但需要耗费更多的资源。
- 异步 IO。
Flink 在1.2中引入了Async I/O,将IO操作异步化。在异步模式下,单个并行子任务可以连续发送多个请求,按照返回的先后顺序对请求进行处理,发送请求后不需要阻塞式等待,省去了大量的等待时间,大幅提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的特性,呼声很高,可用于解决与外部系统交互时网络延迟成为系统瓶颈的问题。
**异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,因此单个并行子任务可以连续发送多个请求,从而提高并发效率。**对于涉及网络IO的操作,可以显著减少因为请求等待带来的性能损耗。
举个例子,假设你用 windows iocp 写了一个 HTTP server。然后来了一个 http 请求访问 index.html。这个请求被分配给 server 的某个线程。然后它一看 index.html 不在内存里,就发起了一个同步的 io 请求去硬盘上读。同时该线程被挂起,从而不计入活跃线程数量。接着又来了第二个 http 请求,同样。然后来了 1000 个,都是这样,都被挂起。然后硬盘把数据给我们读上了!于是这 1000 个线程同时回到 RUNNABLE 的状态,于是 CPU 傻掉了。所谓的让内核统一管理 IO 和线程池就是为了解决这样的问题。
但是缺点是如果线程池在内核态,那么每次调度的开销就很大,导致它不适合轻量级的计算任务(如矩阵乘法)。
异步IO图解
模板方法设计模式
(1)定义
在父类中定义完成某一个功能的核心算法骨架,具体的实现可以延迟到子类中完成。模板方法类一定是抽象类,里面有一套具体的实现流程(可以是抽象方法也可以是普通方法)。这些方法可能由上层模板继承而来。
(2)优点
在不改变父类核心算法骨架的前提下,每一个子类都可以有不同的实现。我们只需要关注具体方法的实现逻辑而不必在实现流程上分心。
本程序中定义了模板类 DimAsyncFunction,在其中定义了维度关联的具体流程:
- 根据流中对象获取维度主键。
- 根据维度主键获取维度对象。
- 用上一步的查询结果补全流中对象的维度信息。
执行步骤和图解
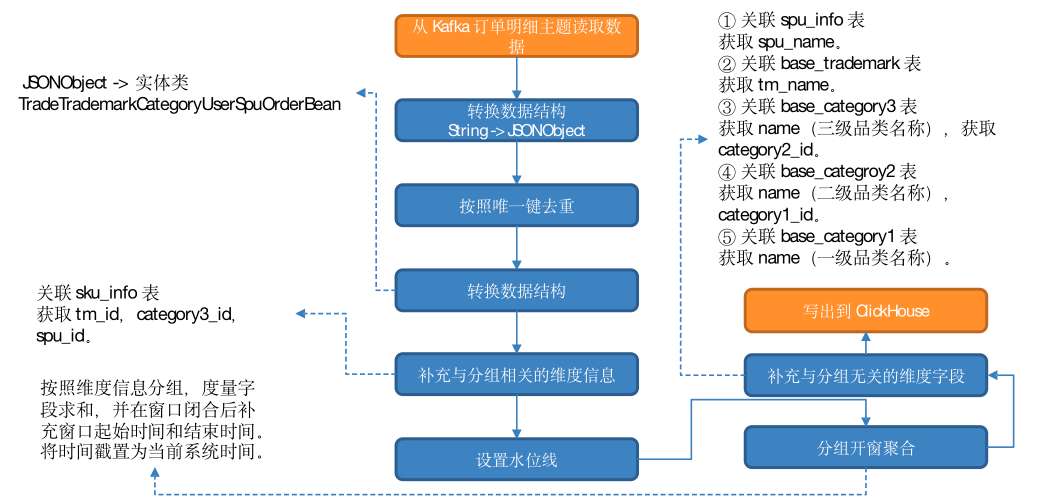
(1)从 Kafka 订单明细主题读取数据
(2)转换数据结构
(3)按照唯一键去重
(4)转换数据结构
JSONObject 转换为实体类 TradeTrademarkCategoryUserSpuOrderBean。
(5)补充与分组相关的维度信息
关联 sku_info 表,获取 tm_id,category3_id,spu_id。
(6)设置水位线
(7)分组、开窗、聚合
按照维度信息分组,度量字段求和,并在窗口闭合后补充窗口起始时间和结束时间。将时间戳置为当前系统时间。
(8)维度关联,补充与分组无关的维度字段
- 关联 spu_info 表,获取 spu_name。
- 关联 base_trademark 表,获取 tm_name。
- 关联 base_category3 表,获取 name(三级品类名称),获取 category2_id。
- 关联 base_categroy2 表,获取 name(二级品类名称),category1_id。
- 关联 base_category1 表,获取 name(一级品类名称)。
(9)写出到 ClickHouse。
图解
ClickHouse建表语句
drop table if exists dws_trade_user_spu_order_window;
create table if not exists dws_trade_user_spu_order_window
(
stt DateTime,
edt DateTime,
trademark_id String,
trademark_name String,
category1_id String,
category1_name String,
category2_id String,
category2_name String,
category3_id String,
category3_name String,
user_id String,
spu_id String,
spu_name String,
order_count UInt64,
order_amount Decimal(38, 20),
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt, spu_id, spu_name, user_id);
代码
(1)补充 Jedis 相关依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
(2)Phoenix 查询数据方法 queryList()
public class JdbcUtil {
public static <T> List<T> queryList(Connection connection, String sql, Class<T> clz, boolean underScoreToCamel) throws SQLException, IllegalAccessException, InstantiationException, InvocationTargetException {
//创建集合用于存放结果数据
ArrayList<T> result = new ArrayList<>();
//编译SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//执行查询
ResultSet resultSet = preparedStatement.executeQuery();
//获取查询的元数据信息
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
//遍历结果集,将每行数据转换为T对象并加入集合 行遍历
while (resultSet.next()) {
//创建T对象
T t = clz.newInstance();
//列遍历,并给T对象赋值
for (int i = 0; i < columnCount; i++) {
//获取列名与列值
String columnName = metaData.getColumnName(i + 1);
Object value = resultSet.getObject(columnName);
//判断是否需要进行下划线与驼峰命名转换
if (underScoreToCamel) {
columnName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, columnName.toLowerCase());
}
//赋值
BeanUtils.setProperty(t, columnName, value);
}
//将T对象放入集合
result.add(t);
}
resultSet.close();
preparedStatement.close();
//返回集合
return result;
}
public static void main(String[] args) throws Exception {
DruidDataSource dataSource = DruidDSUtil.createDataSource();
DruidPooledConnection connection = dataSource.getConnection();
List<JSONObject> jsonObjects = queryList(connection,
"select * ct from GMALL211027_REALTIME.DIM_BASE_TRADEMARK where id='1'",
JSONObject.class,
true);
for (JSONObject jsonObject : jsonObjects) {
System.out.println(jsonObject);
}
connection.close();
}
}
(3)Jedis 工具类 JedisUtil
public class JedisUtil {
private static JedisPool jedisPool;
private static void initJedisPool() {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(5);
poolConfig.setMinIdle(5);
poolConfig.setBlockWhenExhausted(true);
poolConfig.setMaxWaitMillis(2000);
poolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(poolConfig, "hadoop102", 6379, 10000);
}
public static Jedis getJedis() {
if (jedisPool == null) {
initJedisPool();
}
// 获取Jedis客户端
return jedisPool.getResource();
}
public static void main(String[] args) {
Jedis jedis = getJedis();
String pong = jedis.ping();
System.out.println(pong);
}
}
(4)维度查询工具类 DimUtil
public class DimUtil {
public static JSONObject getDimInfo(Connection connection, String tableName, String key) throws InvocationTargetException, SQLException, InstantiationException, IllegalAccessException {
//先查询Redis
Jedis jedis = JedisUtil.getJedis();
String redisKey = "DIM:" + tableName + ":" + key;
String dimJsonStr = jedis.get(redisKey);
if (dimJsonStr != null) {
//重置过期时间
jedis.expire(redisKey, 24 * 60 * 60);
//归还连接
jedis.close();
//返回维度数据
return JSON.parseObject(dimJsonStr);
}
//拼接SQL语句
String querySql = "select * from " + GmallConfig.HBASE_SCHEMA + "." + tableName + " where id='" + key + "'";
System.out.println("querySql>>>" + querySql);
//查询数据
List<JSONObject> queryList = JdbcUtil.queryList(connection, querySql, JSONObject.class, false);
//将从Phoenix查询到的数据写入Redis
JSONObject dimInfo = queryList.get(0);
jedis.set(redisKey, dimInfo.toJSONString());
//设置过期时间
jedis.expire(redisKey, 24 * 60 * 60);
//归还连接
jedis.close();
//返回结果
return dimInfo;
}
public static void delDimInfo(String tableName, String key) {
//获取连接
Jedis jedis = JedisUtil.getJedis();
//删除数据
jedis.del("DIM:" + tableName + ":" + key);
//归还连接
jedis.close();
}
public static void main(String[] args) throws Exception {
DruidDataSource dataSource = DruidDSUtil.createDataSource();
DruidPooledConnection connection = dataSource.getConnection();
long start = System.currentTimeMillis();
JSONObject dimInfo = getDimInfo(connection, "DIM_BASE_TRADEMARK", "18");
long end = System.currentTimeMillis();
JSONObject dimInfo2 = getDimInfo(connection, "DIM_BASE_TRADEMARK", "18");
long end2 = System.currentTimeMillis();
System.out.println(dimInfo);
System.out.println(dimInfo2);
System.out.println(end - start); //159 127 120 127 121 122 119
System.out.println(end2 - end); //8 8 8 1 1 1 1 0 0.5
connection.close();
}
}
(5)修改 MyBroadcastFunction 中的 processElement 方法
补充操作类型字段,用于清除过期缓存,当操作类型为 update 时,清除缓存。
@Override
public void processElement(JSONObject jsonObj, ReadOnlyContext readOnlyContext, Collector<JSONObject> out) throws Exception {
ReadOnlyBroadcastState<String, TableProcess> tableConfigState = readOnlyContext.getBroadcastState(tableConfigDescriptor);
// 获取配置信息
String sourceTable = jsonObj.getString("table");
TableProcess tableConfig = tableConfigState.get(sourceTable);
if (tableConfig != null) {
JSONObject data = jsonObj.getJSONObject("data");
// 获取操作类型
String type = jsonObj.getString("type");
String sinkTable = tableConfig.getSinkTable();
// 根据 sinkColumns 过滤数据
String sinkColumns = tableConfig.getSinkColumns();
filterColumns(data, sinkColumns);
// 将目标表名加入到主流数据中
data.put("sinkTable", sinkTable);
// 将操作类型加入到 JSONObject 中
data.put("type", type);
out.collect(data);
}
}
(6)修改 MyPhoenixSink 类中的 invoke 方法,补充对于操作类型的判断,当操作类型为修改(update)时清除缓存,并补充写入 HBase 之前 JSON 对象中 type 字段的清除操作。
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
private DruidDataSource druidDataSource = null;
@Override
public void open(Configuration parameters) throws Exception {
druidDataSource = DruidDSUtil.createDataSource();
}
//value:{"database":"gmall-211126-flink","table":"base_trademark","type":"update","ts":1652499176,"xid":188,"commit":true,"data":{"id":13,"tm_name":"atguigu"},"old":{"logo_url":"/aaa/aaa"},"sinkTable":"dim_xxx"}
//value:{"database":"gmall-211126-flink","table":"order_info","type":"update","ts":1652499176,"xid":188,"commit":true,"data":{"id":13,...},"old":{"xxx":"/aaa/aaa"},"sinkTable":"dim_xxx"}
@Override
public void invoke(JSONObject value, Context context) throws Exception {
//获取连接
DruidPooledConnection connection = druidDataSource.getConnection();
String sinkTable = value.getString("sinkTable");
JSONObject data = value.getJSONObject("data");
//获取数据类型
String type = value.getString("type");
//如果为更新数据,则需要删除Redis中的数据
if ("update".equals(type)) {
DimUtil.delDimInfo(sinkTable.toUpperCase(), data.getString("id"));
}
//写出数据
PhoenixUtil.upsertValues(connection, sinkTable, data);
//归还连接
connection.close();
}
}
(7)模板方法设计模式模板接口 DimJoinFunction
public interface DimJoinFunction<T> {
String getKey(T input);
void join(T input, JSONObject dimInfo);
}
(8)线程池工具类 ThreadPoolUtil
public class ThreadPoolUtil {
private static ThreadPoolExecutor threadPoolExecutor;
private ThreadPoolUtil() {
}
public static ThreadPoolExecutor getThreadPoolExecutor() {
if (threadPoolExecutor == null) {
synchronized (ThreadPoolUtil.class) {
if (threadPoolExecutor == null) {
threadPoolExecutor = new ThreadPoolExecutor(4,
20,
100,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>());
}
}
}
return threadPoolExecutor;
}
}
(9)异步 IO 函数 DimAsyncFunction
public abstract class DimAsyncFunction<T> extends RichAsyncFunction<T, T> implements DimJoinFunction<T> {
private DruidDataSource dataSource;
private ThreadPoolExecutor threadPoolExecutor;
private String tableName;
public DimAsyncFunction() {
}
public DimAsyncFunction(String tableName) {
this.tableName = tableName;
}
@Override
public void open(Configuration parameters) throws Exception {
dataSource = DruidDSUtil.createDataSource();
threadPoolExecutor = ThreadPoolUtil.getThreadPoolExecutor();
}
@Override
public void asyncInvoke(T input, ResultFuture<T> resultFuture) throws Exception {
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
try {
//获取连接
DruidPooledConnection connection = dataSource.getConnection();
//查询维表获取维度信息
String key = getKey(input);
JSONObject dimInfo = DimUtil.getDimInfo(connection, tableName, key);
//将维度信息补充至当前数据
if (dimInfo != null) {
join(input, dimInfo);
}
//归还连接
connection.close();
//将结果写出
resultFuture.complete(Collections.singletonList(input));
} catch (Exception e) {
e.printStackTrace();
System.out.println("关联维表失败:" + input + ",Table:" + tableName);
//resultFuture.complete(Collections.singletonList(input));
}
}
});
}
@Override
public void timeout(T input, ResultFuture<T> resultFuture) throws Exception {
System.out.println("TimeOut:" + input);
}
}
(10)实体类 TradeUserSpuOrderBean
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class TradeUserSpuOrderBean {
// 窗口起始时间
String stt;
// 窗口结束时间
String edt;
// 品牌 ID
String trademarkId;
// 品牌名称
String trademarkName;
// 一级品类 ID
String category1Id;
// 一级品类名称
String category1Name;
// 二级品类 ID
String category2Id;
// 二级品类名称
String category2Name;
// 三级品类 ID
String category3Id;
// 三级品类名称
String category3Name;
// 订单 ID
@TransientSink
Set<String> orderIdSet;
// sku_id
@TransientSink
String skuId;
// 用户 ID
String userId;
// spu_id
String spuId;
// spu 名称
String spuName;
// 下单次数
Long orderCount;
// 下单金额
Double orderAmount;
// 时间戳
Long ts;
}
(11)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) -> DwsTradeUserSpuOrderWindow(Phoenix-(HBase-HDFS、ZK)、Redis) -> ClickHouse(ZK)
public class DwsTradeUserSpuOrderWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //生产环境中设置为Kafka主题的分区数
//1.1 开启CheckPoint
//env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//1.2 设置状态后端
//env.setStateBackend(new HashMapStateBackend());
//env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck");
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//1.3 设置状态的TTL 生产环境设置为最大乱序程度
//tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));
//TODO 2.读取Kafka DWD层下单主题数据创建流
String topic = "dwd_trade_order_detail";
String groupId = "dws_trade_user_spu_order_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
System.out.println("Value>>>>>>>>" + value);
}
}
});
//TODO 4.按照 order_detail_id 分组
KeyedStream<JSONObject, String> keyedByDetailIdDS = jsonObjDS.keyBy(json -> json.getString("id"));
//TODO 5.针对 order_detail_id 进行去重(保留第一条数据即可)
SingleOutputStreamOperator<JSONObject> filterDS = keyedByDetailIdDS.filter(new RichFilterFunction<JSONObject>() {
private ValueState<String> valueState;
@Override
public void open(Configuration parameters) throws Exception {
StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.seconds(5))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("is-exists", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
valueState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public boolean filter(JSONObject value) throws Exception {
//获取状态数据
String state = valueState.value();
//判断状态是否为null
if (state == null) {
valueState.update("1");
return true;
} else {
return false;
}
}
});
//TODO 6.将数据转换为JavaBean对象
SingleOutputStreamOperator<TradeUserSpuOrderBean> tradeUserSpuDS = filterDS.map(jsonObject -> {
HashSet<String> orderIds = new HashSet<>();
//使用orderIds这个set,是因为是按照SPU的粒度来算订单数的,
// 而如果存在{orderId:1,skuId:1,spuId:1},{orderId:1,skuId:2,spuId:1}这样的数据应该算一条
orderIds.add(jsonObject.getString("order_id"));
return TradeUserSpuOrderBean.builder()
.skuId(jsonObject.getString("sku_id"))
.userId(jsonObject.getString("user_id"))
.orderAmount(jsonObject.getDouble("split_total_amount"))
.orderIdSet(orderIds)
.ts(DateFormatUtil.toTs(jsonObject.getString("create_time"), true))
.build();
});
tradeUserSpuDS.print("tradeUserSpuDS>>>>>>>>>>>>>>");
//TODO 7.关联sku_info维表 补充 spu_id,tm_id,category3_id
// tradeUserSpuDS.map(new RichMapFunction<TradeUserSpuOrderBean, TradeUserSpuOrderBean>() {
// @Override
// public void open(Configuration parameters) throws Exception {
// //创建Phoenix连接池
// }
// @Override
// public TradeUserSpuOrderBean map(TradeUserSpuOrderBean value) throws Exception {
// //查询维表,将查到的信息补充至JavaBean中
// return null;
// }
// });
SingleOutputStreamOperator<TradeUserSpuOrderBean> tradeUserSpuWithSkuDS = AsyncDataStream.unorderedWait(
tradeUserSpuDS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_SKU_INFO") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getSkuId();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setSpuId(dimInfo.getString("SPU_ID"));
input.setTrademarkId(dimInfo.getString("TM_ID"));
input.setCategory3Id(dimInfo.getString("CATEGORY3_ID"));
}
},
100, TimeUnit.SECONDS);
tradeUserSpuWithSkuDS.print("tradeUserSpuWithSkuDS>>>>>>>>>>>");
//TODO 8.提取事件时间生成Watermark
SingleOutputStreamOperator<TradeUserSpuOrderBean> tradeUserSpuWithWmDS = tradeUserSpuWithSkuDS.assignTimestampsAndWatermarks(WatermarkStrategy.<TradeUserSpuOrderBean>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<TradeUserSpuOrderBean>() {
@Override
public long extractTimestamp(TradeUserSpuOrderBean element, long recordTimestamp) {
return element.getTs();
}
}));
//TODO 9.分组、开窗、聚合
KeyedStream<TradeUserSpuOrderBean, Tuple4<String, String, String, String>> keyedStream = tradeUserSpuWithWmDS.keyBy(new KeySelector<TradeUserSpuOrderBean, Tuple4<String, String, String, String>>() {
@Override
public Tuple4<String, String, String, String> getKey(TradeUserSpuOrderBean value) throws Exception {
return new Tuple4<>(value.getUserId(),
value.getSpuId(),
value.getTrademarkId(),
value.getCategory3Id());
}
});
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceDS = keyedStream.window(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10)))
.reduce(new ReduceFunction<TradeUserSpuOrderBean>() {
@Override
public TradeUserSpuOrderBean reduce(TradeUserSpuOrderBean value1, TradeUserSpuOrderBean value2) throws Exception {
value1.getOrderIdSet().addAll(value2.getOrderIdSet());
value1.setOrderAmount(value1.getOrderAmount() + value2.getOrderAmount());
return value1;
}
}, new WindowFunction<TradeUserSpuOrderBean, TradeUserSpuOrderBean, Tuple4<String, String, String, String>, TimeWindow>() {
@Override
public void apply(Tuple4<String, String, String, String> key, TimeWindow window, Iterable<TradeUserSpuOrderBean> input, Collector<TradeUserSpuOrderBean> out) throws Exception {
TradeUserSpuOrderBean userSpuOrderBean = input.iterator().next();
userSpuOrderBean.setTs(System.currentTimeMillis());
userSpuOrderBean.setOrderCount((long) userSpuOrderBean.getOrderIdSet().size());
userSpuOrderBean.setStt(DateFormatUtil.toYmdHms(window.getStart()));
userSpuOrderBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
out.collect(userSpuOrderBean);
}
});
//TODO 10.关联spu,tm,category维表补充相应的信息
//10.1 关联SPU表
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceWithSpuDS = AsyncDataStream.unorderedWait(reduceDS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_SPU_INFO") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getSpuId();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setSpuName(dimInfo.getString("SPU_NAME"));
}
}, 100, TimeUnit.SECONDS);
//10.2 关联Tm表
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceWithTmDS = AsyncDataStream.unorderedWait(reduceWithSpuDS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_BASE_TRADEMARK") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getTrademarkId();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setTrademarkName(dimInfo.getString("TM_NAME"));
}
}, 100, TimeUnit.SECONDS);
//10.3 关联Category3
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceWithCategory3DS = AsyncDataStream.unorderedWait(reduceWithTmDS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_BASE_CATEGORY3") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getCategory3Id();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setCategory3Name(dimInfo.getString("NAME"));
input.setCategory2Id(dimInfo.getString("CATEGORY2_ID"));
}
}, 100, TimeUnit.SECONDS);
//10.4 关联Category2
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceWithCategory2DS = AsyncDataStream.unorderedWait(reduceWithCategory3DS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_BASE_CATEGORY2") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getCategory2Id();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setCategory2Name(dimInfo.getString("NAME"));
input.setCategory1Id(dimInfo.getString("CATEGORY1_ID"));
}
}, 100, TimeUnit.SECONDS);
//10.5 关联Category1
SingleOutputStreamOperator<TradeUserSpuOrderBean> reduceWithCategory1DS = AsyncDataStream.unorderedWait(reduceWithCategory2DS,
new DimAsyncFunction<TradeUserSpuOrderBean>("DIM_BASE_CATEGORY1") {
@Override
public String getKey(TradeUserSpuOrderBean input) {
return input.getCategory1Id();
}
@Override
public void join(TradeUserSpuOrderBean input, JSONObject dimInfo) {
input.setCategory1Name(dimInfo.getString("NAME"));
}
}, 100, TimeUnit.SECONDS);
//TODO 11.将数据写出到ClickHouse
reduceWithCategory1DS.print(">>>>>>>>>>>>>>>>>");
reduceWithCategory1DS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_user_spu_order_window values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"));
//TODO 12.启动
env.execute("DwsTradeUserSpuOrderWindow");
}
}
交易域省份粒度下单各窗口汇总表
主要任务
从 Kafka 读取订单明细数据,过滤 null 数据并按照唯一键对数据去重,统计各省份各窗口订单数和订单金额,将数据写入 ClickHouse 交易域省份粒度下单各窗口汇总表。
思路分析
1)从 Kafka 订单明细主题读取数据
2)转换数据结构
3)按照唯一键去重
4)转换数据结构
JSONObject 转换为实体类 TradeProvinceOrderWindow。
5)设置水位线
6)按照省份 ID 分组
provinceld 可以唯一标识数据。
7)开窗
8)聚合计算
度量字段求和,并在窗口闭合后补充窗口起始时间和结束时间。将时间戳置为当前系统时间。
9)关联省份信息
补全省份名称字段。
10)写出到 ClickHouse.
图解
ClickHouse 建表语句
drop table if exists dws_trade_province_order_window;
create table if not exists dws_trade_province_order_window
(
stt DateTime,
edt DateTime,
province_id String,
province_name String,
order_count UInt64,
order_amount Decimal(38, 20),
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt, province_id);
代码
(1)实体类
@Data
@AllArgsConstructor
@Builder
public class TradeProvinceOrderWindow {
// 窗口起始时间
String stt;
// 窗口结束时间
String edt;
// 省份 ID
String provinceId;
// 省份名称
@Builder.Default
String provinceName = "";
// 累计下单次数
Long orderCount;
// 订单 ID 集合,用于统计下单次数
@TransientSink
Set<String> orderIdSet;
// 累计下单金额
Double orderAmount;
// 时间戳
Long ts;
}
(2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) -> DwsTradeProvinceOrderWindow(Phoenix-(HBase-HDFS、ZK)、Redis) -> ClickHouse(ZK)
public class DwsTradeProvinceOrderWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //生产环境中设置为Kafka主题的分区数
//1.1 开启CheckPoint
//env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//1.2 设置状态后端
//env.setStateBackend(new HashMapStateBackend());
//env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck");
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//1.3 设置状态的TTL 生产环境设置为最大乱序程度
//tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));
//TODO 2.读取Kafka DWD层下单主题数据创建流
String topic = "dwd_trade_order_detail";
String groupId = "dws_trade_province_order_window_211126";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
System.out.println("Value>>>>>>>>" + value);
}
}
});
//TODO 4.按照 order_detail_id 分组、去重(取最后一条数据)
KeyedStream<JSONObject, String> keyedByDetailIdDS = jsonObjDS.keyBy(json -> json.getString("id"));
SingleOutputStreamOperator<JSONObject> filterDS = keyedByDetailIdDS.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() {
private ValueState<JSONObject> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<JSONObject>("value-state", JSONObject.class));
}
@Override
public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {
//取出状态中的数据
JSONObject lastValue = valueState.value();
//判断状态数据是否为null
if (lastValue == null) {
valueState.update(value);
long processingTime = ctx.timerService().currentProcessingTime();
ctx.timerService().registerProcessingTimeTimer(processingTime + 5000L);
} else {
//取出状态数据以及当前数据中的时间字段
String lastTs = lastValue.getString("row_op_ts");
String curTs = value.getString("row_op_ts");
if (TimestampLtz3CompareUtil.compare(lastTs, curTs) != 1) {
valueState.update(value);
}
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception {
//输出数据并清空状态
out.collect(valueState.value());
valueState.clear();
}
});
//TODO 5.将每行数据转换为JavaBean
SingleOutputStreamOperator<TradeProvinceOrderWindow> provinceOrderDS = filterDS.map(line -> {
HashSet<String> orderIdSet = new HashSet<>();
orderIdSet.add(line.getString("order_id"));
return new TradeProvinceOrderWindow("", "",
line.getString("province_id"),
"",
0L,
orderIdSet,
line.getDouble("split_total_amount"),
DateFormatUtil.toTs(line.getString("create_time"), true));
});
//TODO 6.提取时间戳生成Watermark
SingleOutputStreamOperator<TradeProvinceOrderWindow> tradeProvinceWithWmDS = provinceOrderDS.assignTimestampsAndWatermarks(WatermarkStrategy.<TradeProvinceOrderWindow>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<TradeProvinceOrderWindow>() {
@Override
public long extractTimestamp(TradeProvinceOrderWindow element, long recordTimestamp) {
return element.getTs();
}
}));
//TODO 7.分组开窗聚合
SingleOutputStreamOperator<TradeProvinceOrderWindow> reduceDS = tradeProvinceWithWmDS.keyBy(TradeProvinceOrderWindow::getProvinceId)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<TradeProvinceOrderWindow>() {
@Override
public TradeProvinceOrderWindow reduce(TradeProvinceOrderWindow value1, TradeProvinceOrderWindow value2) throws Exception {
value1.getOrderIdSet().addAll(value2.getOrderIdSet());
value1.setOrderAmount(value1.getOrderAmount() + value2.getOrderAmount());
return value1;
}
}, new WindowFunction<TradeProvinceOrderWindow, TradeProvinceOrderWindow, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<TradeProvinceOrderWindow> input, Collector<TradeProvinceOrderWindow> out) throws Exception {
TradeProvinceOrderWindow provinceOrderWindow = input.iterator().next();
provinceOrderWindow.setTs(System.currentTimeMillis());
provinceOrderWindow.setOrderCount((long) provinceOrderWindow.getOrderIdSet().size());
provinceOrderWindow.setStt(DateFormatUtil.toYmdHms(window.getStart()));
provinceOrderWindow.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
out.collect(provinceOrderWindow);
}
});
reduceDS.print("reduceDS>>>>>>>>>>>>");
//TODO 8.关联省份维表补充省份名称字段
SingleOutputStreamOperator<TradeProvinceOrderWindow> reduceWithProvinceDS = AsyncDataStream.unorderedWait(reduceDS,
new DimAsyncFunction<TradeProvinceOrderWindow>("DIM_BASE_PROVINCE") {
@Override
public String getKey(TradeProvinceOrderWindow input) {
return input.getProvinceId();
}
@Override
public void join(TradeProvinceOrderWindow input, JSONObject dimInfo) {
input.setProvinceName(dimInfo.getString("NAME"));
}
}, 100, TimeUnit.SECONDS);
//TODO 9.将数据写出到ClickHouse
reduceWithProvinceDS.print("reduceWithProvinceDS>>>>>>>>>>>");
reduceWithProvinceDS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_province_order_window values(?,?,?,?,?,?,?)"));
//TODO 10.启动任务
env.execute("DwsTradeProvinceOrderWindow");
}
}
交易域品牌-品类-用户粒度退单各窗口汇总表
主要任务
从 Kafka 读取退单明细数据,过滤 null 数据并按照唯一键对数据去重,关联维度信息,按照维度分组,统计各维度各窗口的订单数和订单金额,将数据写入 ClickHouse 交易域品牌-品类-用户粒度退单各窗口汇总表。
思路分析
1)从Kafka 退单明细主题读取数据
2)转换数据结构
JSONObject 转换为实体类 TradeTrademarkCategoryUserRefundBean。
3)补充与分组相关的维度信息
关联 sku info 表,获取 tm id, category3 id。
4)设置水位线
5)分组、开窗、聚合
按照维度信息分组,度量字段求和,并在窗口闭合后补充窗口起始时间和结束时间。将时间戳置为当前系统时间。
6)补充与分组无关的维度信息
7) 写出到 ClickHouse
图解
ClickHouse 建表语句
drop table if exists dws_trade_trademark_category_user_refund_window;
create table if not exists dws_trade_trademark_category_user_refund_window
(
stt DateTime,
edt DateTime,
trademark_id String,
trademark_name String,
category1_id String,
category1_name String,
category2_id String,
category2_name String,
category3_id String,
category3_name String,
user_id String,
refund_count UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt, trademark_id, trademark_name, category1_id,
category1_name, category2_id, category2_name, category3_id, category3_name, user_id);
代码
(1)实体类 TradeTrademarkCategoryUserRefundBean
@Data
@AllArgsConstructor
@Builder
public class TradeTrademarkCategoryUserRefundBean {
// 窗口起始时间
String stt;
// 窗口结束时间
String edt;
// 品牌 ID
String trademarkId;
// 品牌名称
String trademarkName;
// 一级品类 ID
String category1Id;
// 一级品类名称
String category1Name;
// 二级品类 ID
String category2Id;
// 二级品类名称
String category2Name;
// 三级品类 ID
String category3Id;
// 三级品类名称
String category3Name;
// 订单 ID
@TransientSink
Set<String> orderIdSet;
// sku_id
@TransientSink
String skuId;
// 用户 ID
String userId;
// 退单次数
Long refundCount;
// 时间戳
Long ts;
public static void main(String[] args) {
TradeTrademarkCategoryUserRefundBean build = builder().build();
System.out.println(build);
}
}
(2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderRefund -> Kafka(ZK) -> DwsTradeTrademarkCategoryUserRefundWindow(Phoenix(HBase-HDFS、ZK)、Redis) -> ClickHouse(ZK)
public class DwsTradeTrademarkCategoryUserRefundWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //生产环境中设置为Kafka主题的分区数
//1.1 开启CheckPoint
//env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//1.2 设置状态后端
//env.setStateBackend(new HashMapStateBackend());
//env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck");
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//1.3 设置状态的TTL 生产环境设置为最大乱序程度
//tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5));
//TODO 2.读取 Kafka DWD层 退单主题数据
String topic = "dwd_trade_order_refund";
String groupId = "dws_trade_trademark_category_user_refund_window";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//TODO 3.将每行数据转换为JavaBean
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> tradeTmCategoryUserDS = kafkaDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
HashSet<String> orderIds = new HashSet<>();
orderIds.add(jsonObject.getString("order_id"));
return TradeTrademarkCategoryUserRefundBean.builder()
.skuId(jsonObject.getString("sku_id"))
.userId(jsonObject.getString("user_id"))
.orderIdSet(orderIds)
.ts(DateFormatUtil.toTs(jsonObject.getString("create_time"), true))
.build();
});
//TODO 4.关联sku_info维表补充 tm_id以及category3_id
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> tradeWithSkuDS = AsyncDataStream.unorderedWait(
tradeTmCategoryUserDS,
new DimAsyncFunction<TradeTrademarkCategoryUserRefundBean>("DIM_SKU_INFO") {
@Override
public String getKey(TradeTrademarkCategoryUserRefundBean input) {
return input.getSkuId();
}
@Override
public void join(TradeTrademarkCategoryUserRefundBean input, JSONObject dimInfo) {
input.setTrademarkId(dimInfo.getString("TM_ID"));
input.setCategory3Id(dimInfo.getString("CATEGORY3_ID"));
}
}, 100, TimeUnit.SECONDS);
//TODO 5.分组开窗聚合
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> reduceDS = tradeWithSkuDS.assignTimestampsAndWatermarks(WatermarkStrategy.<TradeTrademarkCategoryUserRefundBean>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<TradeTrademarkCategoryUserRefundBean>() {
@Override
public long extractTimestamp(TradeTrademarkCategoryUserRefundBean element, long recordTimestamp) {
return element.getTs();
}
})).keyBy(new KeySelector<TradeTrademarkCategoryUserRefundBean, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> getKey(TradeTrademarkCategoryUserRefundBean value) throws Exception {
return new Tuple3<>(value.getUserId(),
value.getTrademarkId(),
value.getCategory3Id()
);
}
}).window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<TradeTrademarkCategoryUserRefundBean>() {
@Override
public TradeTrademarkCategoryUserRefundBean reduce(TradeTrademarkCategoryUserRefundBean value1, TradeTrademarkCategoryUserRefundBean value2) throws Exception {
value1.getOrderIdSet().addAll(value2.getOrderIdSet());
return value1;
}
}, new WindowFunction<TradeTrademarkCategoryUserRefundBean, TradeTrademarkCategoryUserRefundBean, Tuple3<String, String, String>, TimeWindow>() {
@Override
public void apply(Tuple3<String, String, String> stringStringStringTuple3, TimeWindow window, Iterable<TradeTrademarkCategoryUserRefundBean> input, Collector<TradeTrademarkCategoryUserRefundBean> out) throws Exception {
TradeTrademarkCategoryUserRefundBean refundBean = input.iterator().next();
refundBean.setTs(System.currentTimeMillis());
refundBean.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));
refundBean.setStt(DateFormatUtil.toYmdHms(window.getStart()));
refundBean.setRefundCount((long) refundBean.getOrderIdSet().size());
out.collect(refundBean);
}
});
//TODO 6.关联维表补充其他字段
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> reduceWithTmDS = AsyncDataStream.unorderedWait(
reduceDS,
new DimAsyncFunction<TradeTrademarkCategoryUserRefundBean>("DIM_BASE_TRADEMARK") {
@Override
public String getKey(TradeTrademarkCategoryUserRefundBean input) {
return input.getTrademarkId();
}
@Override
public void join(TradeTrademarkCategoryUserRefundBean input, JSONObject dimInfo) {
input.setTrademarkName(dimInfo.getString("TM_NAME"));
}
}, 100, TimeUnit.SECONDS);
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> reduceWith3DS = AsyncDataStream.unorderedWait(
reduceWithTmDS,
new DimAsyncFunction<TradeTrademarkCategoryUserRefundBean>("DIM_BASE_CATEGORY3") {
@Override
public String getKey(TradeTrademarkCategoryUserRefundBean input) {
return input.getCategory3Id();
}
@Override
public void join(TradeTrademarkCategoryUserRefundBean input, JSONObject dimInfo) {
input.setCategory3Name(dimInfo.getString("NAME"));
input.setCategory2Id(dimInfo.getString("CATEGORY2_ID"));
}
}, 100, TimeUnit.SECONDS);
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> reduceWith2DS = AsyncDataStream.unorderedWait(
reduceWith3DS,
new DimAsyncFunction<TradeTrademarkCategoryUserRefundBean>("DIM_BASE_CATEGORY2") {
@Override
public String getKey(TradeTrademarkCategoryUserRefundBean input) {
return input.getCategory2Id();
}
@Override
public void join(TradeTrademarkCategoryUserRefundBean input, JSONObject dimInfo) {
input.setCategory2Name(dimInfo.getString("NAME"));
input.setCategory1Id(dimInfo.getString("CATEGORY1_ID"));
}
}, 100, TimeUnit.SECONDS);
SingleOutputStreamOperator<TradeTrademarkCategoryUserRefundBean> reduceWith1DS = AsyncDataStream.unorderedWait(
reduceWith2DS,
new DimAsyncFunction<TradeTrademarkCategoryUserRefundBean>("DIM_BASE_CATEGORY1") {
@Override
public String getKey(TradeTrademarkCategoryUserRefundBean input) {
return input.getCategory1Id();
}
@Override
public void join(TradeTrademarkCategoryUserRefundBean input, JSONObject dimInfo) {
input.setCategory1Name(dimInfo.getString("NAME"));
}
}, 100, TimeUnit.SECONDS);
//TODO 7.将数据写出到ClickHouse
reduceWith1DS.print(">>>>>>>>>>>>");
reduceWith1DS.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_trade_trademark_category_user_refund_window values(?,?,?,?,?,?,?,?,?,?,?,?,?)"));
//TODO 8.启动任务
env.execute("DwsTradeTrademarkCategoryUserRefundWindow");
}
}