NiFi基本概念
概述
一个易于使用,功能强大,可靠的处理和分发数据框架。主要用于数据的同步传输,支持灵活的数据格式转换,同时可以设置定时调度任务。主要用于离线同步。
核心概念
NiFi的基本设计概念与基于流程的编程的主要思想密切相关。以下是一些主要的NiFi概念以及它们如何映射到FBP:
| NiFi 术语 | 描述 |
|---|---|
| FlowFile | 数据在NIFI中传输时封装的对象,分为属性(attribute)和内容,其中属性是键值对的头信息,内容为字符串。 |
| FlowFile Processor | 数据处理器组件,通过选择不同的处理器,对数据进行不同的读写或者转换清洗等操作。 |
| Connection | 处理器直接的连接,单个处理器可以有多个连接完成数据的分流。 |
| Flow Controller | 流控制器管理连接器中的资源分配。 |
| Process Group | 处理组,将多个处理器连接的链路封装起来作为一个组管理。 |
NiFi架构原理
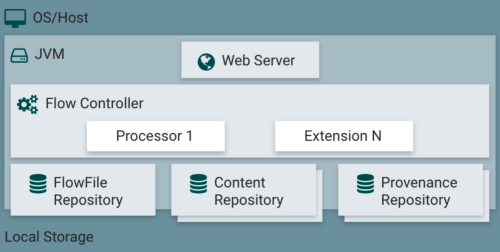
NiFi在主机操作系统上的JVM内执行。JVM上NiFi的主要组件如下:
(1)Web Server
Web服务器提供webUI页面给用户操作执行。
(2)Flow Controller
流量控制器是操作的大脑。管理任务的资源。
(3)Extensions
各种处理器。
(4)FlowFile Repository
FlowFile存储库是用于存储正在传输时候的数据对象,主要存储数据状态信息,存储在磁盘。
(5)Content Repository
内容存储库主要存储数据内容,也是FlowFile的主要存储地址,支持多磁盘。
(6)Provenance Repository
来源数据库,存储不同的数据来源信息。
NiFi运行在集群
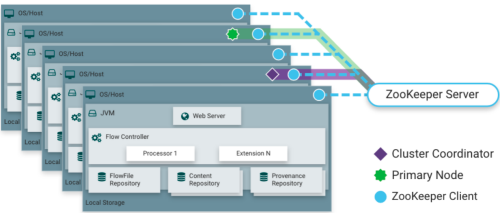
从NiFi 1.0版本开始,采用了Zero-Master Clustering范例。NiFi群集中的每个节点对数据执行相同的任务,但每个节点都在不同的数据集上运行。Zookeeper选择单个节点作为集群协调器,Zookeeper自动处理故障转移。所有群集节点都会向群集协调器报告心跳和状态信息。群集协调器负责断开和连接节点。此外,每个群集都有一个主节点,也由Zookeeper选举。作为DataFlow管理器,您可以通过任何节点的用户界面(UI)与NiFi群集进行交互。您所做的任何更改都将复制到群集中的所有节点,从而允许多个入口点。
NiFi安装
NiFi安装地址
(1)NiFi官网地址
(2)文档查看地址
http://nifi.apache.org/docs.html
(3)下载地址
http://nifi.apache.org/download.html
安装NiFi
(1)NiFi安装
-
把nifi-1.19.1-bin.zip上传到linux的/opt/software目录下
-
解压nifi-1.19.1-bin.zip到/opt/module/目录下面
注意:如果没有unzip工具可以使用yum先安装一下
[atguigu@hadoop102 software]$ sudo yum -y install unzip [atguigu@hadoop102 software]$ unzip nifi-1.19.1-bin.zip -d /opt/module/ -
修改名称为NiFi
[atguigu@hadoop102 module]$ mv nifi-1.19.1/ nifi
(2)NiFi核心配置
-
修改web地址和端口号
[atguigu@hadoop102 nifi]$ vim conf/nifi.properties ############################################# 152行(填写127.0.0.1在虚拟机里面,windows无法访问) nifi.web.https.host=hadoop102 nifi.web.https.port=8443提示:更多属性配置可以参考如下:http://nifi.apache.org/docs.html
-
设置登录账号
密码有要求,最低12位
[atguigu@hadoop102 nifi]$ bin/nifi.sh set-single-user-credentials admin 123456789012
(3)启动
-
NiFi后台启动/关闭命令
[atguigu@hadoop102 nifi]$ bin/nifi.sh start [atguigu@hadoop102 nifi]$ bin/nifi.sh stop [atguigu@hadoop102 nifi]$ bin/nifi.sh status -
NiFi前台启动/关闭命令
[atguigu@hadoop102 nifi]$ bin/nifi.sh run #Ctrl+c 关闭 -
web访问
输入账号密码即可进入控制台:

实现分布式
NIFI实现分布式需要使用nifi-toolkit生成验证证书,所以需要上传解压对应的文件。
禁用 selinux
修改对应文件,禁用selinux。
[atguigu@hadoop102 nifi]$ sudo vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
分发文件并重启虚拟机。
[atguigu@hadoop102 nifi]$ sudo /home/atguigu/bin/xsync /etc/selinux/config
[atguigu@hadoop102 nifi]$ sudo reboot
[atguigu@hadoop103 nifi]$ sudo reboot
[atguigu@hadoop104 nifi]$ sudo reboot
分发NiFi
[atguigu@hadoop102 module]$ xsync nifi
生成证书
(1)在102上传解压nifi-toolkit-1.19.1-bin.zip并解压
[atguigu@hadoop102 software]$ unzip nifi-toolkit-1.19.1-bin.zip -d /opt/module/
(2)执行脚本命令生成证书
[atguigu@hadoop102 nifi]$ bin/tls-toolkit.sh standalone -C 'CN=username, OU=NIFI' -n 'hadoop102,hadoop103,hadoop104' -K 123456789012 -S 123456789012 -P 123456789012 -o 'outlog'
参数解析:
- -C 生成适合在指定 DN 的浏览器中使用的客户端证书 里面的都是一些标记配置
- -n 设置节点地址
- –keyPassword(-K) 设置需要使用的密码
- –keyStorePassword(-S)设置要使用的密钥库密码
- –trustStorePassword (-P)设置要使用的密钥库密码
- -o 设置一个输出目录
(3)分发证书
把制作的证书全部分发到102,103,104节点的。

[atguigu@hadoop102 outlog]$ cp CN* hadoop102
[atguigu@hadoop102 outlog]$ cp CN* hadoop103
[atguigu@hadoop102 outlog]$ cp CN* hadoop104
[atguigu@hadoop102 outlog]$ cp nifi-* hadoop102
[atguigu@hadoop102 outlog]$ cp nifi-* hadoop103
[atguigu@hadoop102 outlog]$ cp nifi-* hadoop104
[atguigu@hadoop102 outlog]$ scp hadoop102/* hadoop102:/opt/module/nifi/conf/
[atguigu@hadoop102 outlog]$ scp hadoop103/* hadoop103:/opt/module/nifi/conf/
[atguigu@hadoop102 outlog]$ scp hadoop104/* hadoop104:/opt/module/nifi/conf/
修改配置
(1)设置3台zk连接
[atguigu@hadoop102 nifi]$ vim conf/state-management.xml
61行
<property name="Connect String">hadoop102:2181,hadoop103:2181,hadoop104:2181</property>
启动zk
[atguigu@hadoop102 nifi]$ zk.sh start
(2)修改3台节点的配置文件
[atguigu@hadoop102 nifi]$ vim conf/nifi.properties
152行
nifi.web.https.host=hadoop102
258行
nifi.cluster.is.node=true
nifi.cluster.node.address=hadoop102
278行
nifi.zookeeper.connect.string=hadoop102:2181,hadoop103:2181,hadoop104:2181
(3)设置更新初始密码
[atguigu@hadoop102 nifi]$ bin/nifi.sh set-sensitive-properties-key 123456789012
[atguigu@hadoop103 nifi]$ bin/nifi.sh set-sensitive-properties-key 123456789012
[atguigu@hadoop104 nifi]$ bin/nifi.sh set-sensitive-properties-key 123456789012
[atguigu@hadoop102 nifi]$ bin/nifi.sh set-single-user-credentials admin 123456789012
[atguigu@hadoop103 nifi]$ bin/nifi.sh set-single-user-credentials admin 123456789012
[atguigu@hadoop104 nifi]$ bin/nifi.sh set-single-user-credentials admin 123456789012
(4)启动nifi
[atguigu@hadoop102 nifi]$ bin/nifi.sh start
[atguigu@hadoop103 nifi]$ bin/nifi.sh start
[atguigu@hadoop104 nifi]$ bin/nifi.sh start
(5)登录webUI
集群模式的NIFI默认登录端口号为9443
NiFi 的使用
Web页面简介
(1)NiFi登陆界面解读
我们现在可以通过在画布中添加Processor来开始创建数据流。要执行此操作,请将处理器图标从屏幕左上方拖动到画布中间(图纸类背景)并将其放在那里。这将为我们提供一个对话框,允许我们选择要添加的处理器:

提示:各个处理器的用途及配置在官网上都有介绍,大约提供了近300个常用处理器。包含但不限于:数据格式转换、数据采集、数据(local/kafka/solr/hdfs/hbase/mysql/hive/http等)的读写等功能,使用方便,如果不能满足需求,还可以自定义处理器。
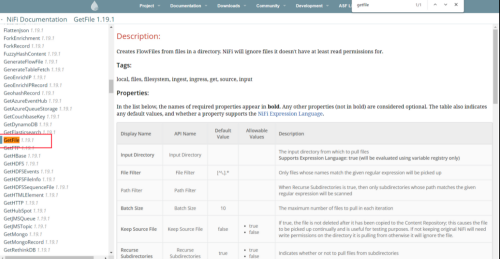
(2)配置处理器(以GetFile为例)




提示:详细properties配置可参考官网:
案例一 同步文件
需求:同步本地磁盘文档上传到hdfs,通过NIFI自动监控磁盘文件上传到hdfs对应的文件夹。
添加处理组
将一个任务的processer放到一个组里面,便于管理:
鼠标双击点进去,左下角退出:
添加处理器
首先添加getFile处理器,填写监控的文件夹,读取对应文件夹文件。之后添加putHdfs将数据写出到hdfs。
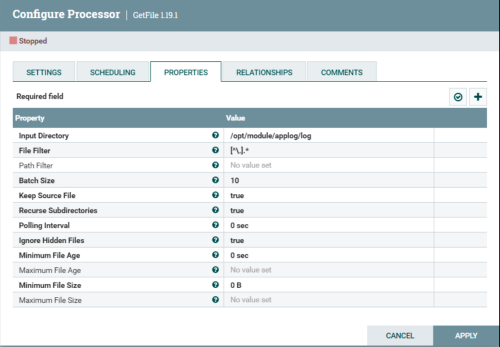
参数解析:
(1)Input Directory: 监控的文件夹,写linux本地的地址
(2)File Filter: 正则匹配监控的哪些文件
(3)Keep Source File: 传输数据之后是否保留源文件,默认删除
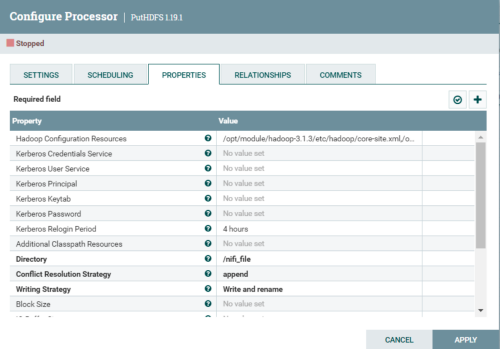
参数解析:
(1)Hadoop Configuration Resources:hadoop配置文件的地址,写core-site.xml和hdfs-site.xml的地址
(2)Directory:写入到hdfs的路径
(3)Conflict Resolution Strategy:文件名冲突解决策略,默认fail报错,同步文件选择append追加写入
(4)Writing Strategy: 写入策略,默认写入加改名。打到块大小文件滚动
(5)Block Size: 块大小
(6)Compression codec: 压缩格式,这里选择通用性更高的GZIP
连接处理器
点击上游处理器的箭头拖动到下游即可连接,连接时需要点击将上游哪种情况的数据输出到下游,这里只有一种success。
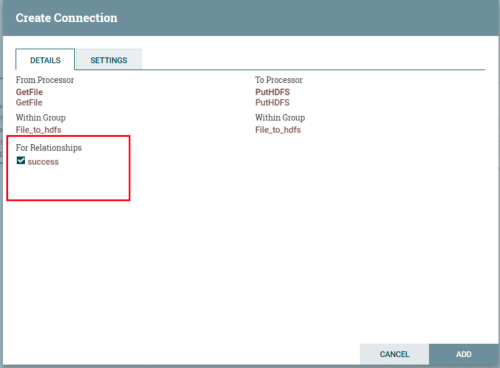
添加成功之后,上游处理完毕。Nifi运行要求每一个处理器的数据情况都要有处理。所以PutHDFS需要自己解决自身数据的情况。
数据发送失败或者成功都直接终止当前数据flowFile即可。
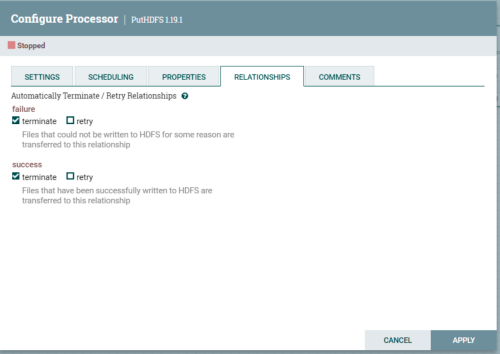
选择当前任务的运行节点,调整调度周期:

配置完成之后如果参数没有问题,处理器会出现终止的按钮,表示没有运行。

运行处理器
Nifi可以选择部分处理器启动,所以我们先启动getFile。使用日志生成脚本造log数据即可。

可以看到数据已经成功传输到管道中,点击可以查看:

之后启动hadoop,然后开启putHDFS的processer。
[atguigu@hadoop102 nifi\]\$ myhadoop.sh start

可以看出数据全部写出,同时能够在hdfs查找到对应的文件。
注意:nifi读取数据之后会删除文件,需要不断写新的文件才能不断上传。
案例二 离线同步mysql数据到hdfs
需求:导出Mysql数据转换为Json串并保存到hdfs。
读取mysql数据
(1)添加消费者组

(2)添加ExecuteSQL到面板
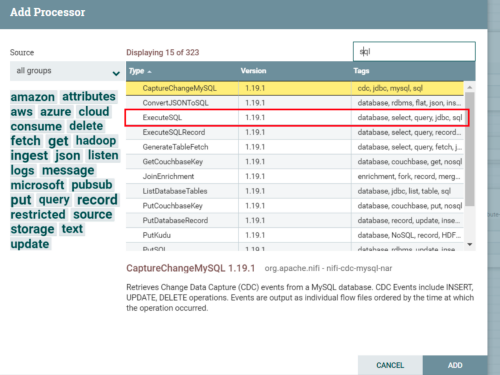
(3)创建连接池
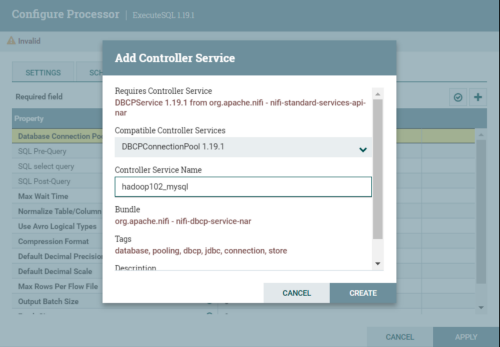
点击箭头进行编辑连接池。
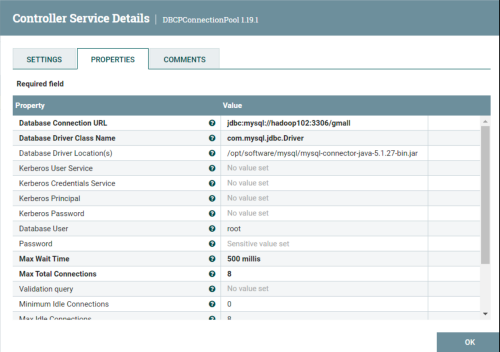
注意:一定要将state改为Enable。

(4)编辑executeSQL信息
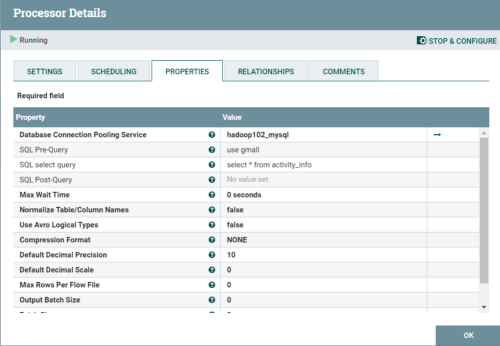
添加ConvertAvroToJson

添加PutHDFS
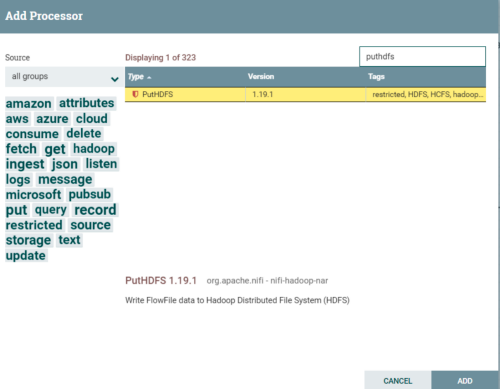

连接处理器
(1)拖动箭头指向下一层,并勾选success。
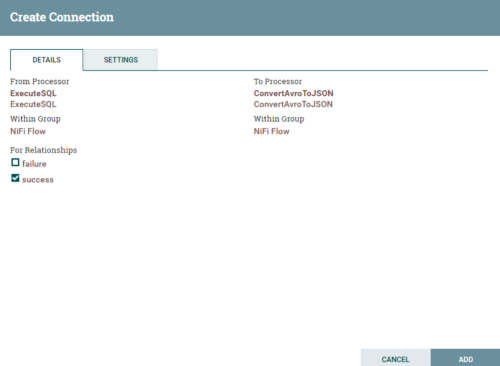
(2)自身的关系选择failure。

(2)启动任务,选择对应处理器,点击启动按钮。
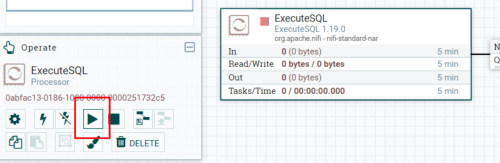
修改读取数据周期
直接启动之后会发现hdfs上面上传了过多的文件。
设置一天
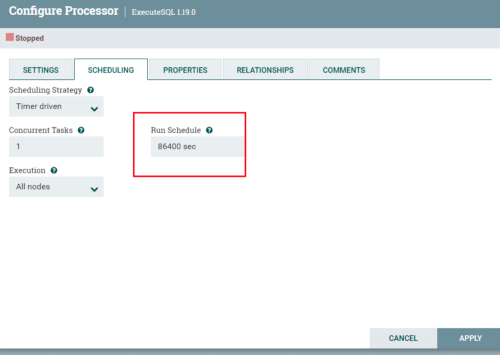
优化
修改动态目录
需求:添加动态参数控制数据写入到hdfs的路径。
默认情况下所有的上传文件都会发送到同一个文件夹,导致文件混乱。
通过引入NiFi Expression Language函数可以动态修改最终导出的路径。具体内容可以参考官方网站https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html#dates。
(1)修改PutHDFS
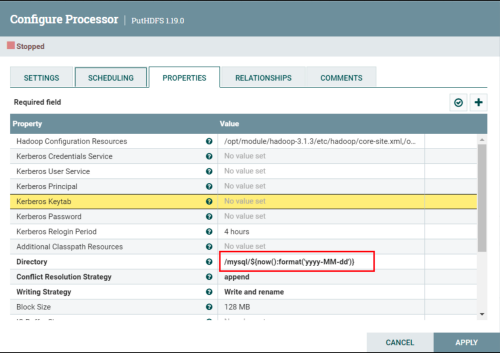
注意:首先需要确定当前参数框可以填写Expression Language语法。
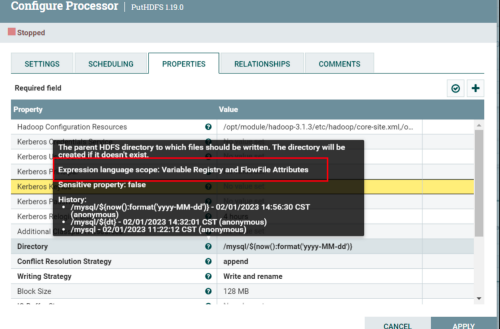
${}是特定的符号,中间可以填写函数,也允许填写NIFI的Attribute参数(数据头信息)。
修改完成之后重新发送数据,之后到hdfs上面查看数据。
自定义修改文件名称
需求:添加动态参数控制数据写入到hdfs的路径。
NIFI读取数据的文件名称为自动生成的字符串,没有任何含义,可以通过修改Attribute参数来修改fileName。
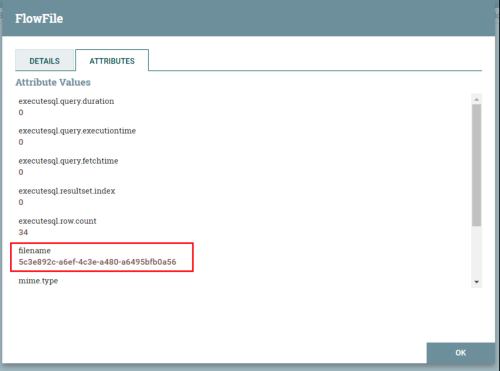
(1)查看Attribute参数
首先发送数据到queue中。
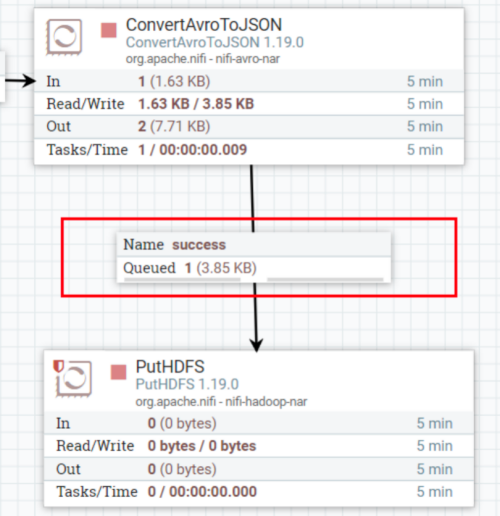
点击list Queue,之后点击感叹号查看参数。

(2)添加UpdateAttribute
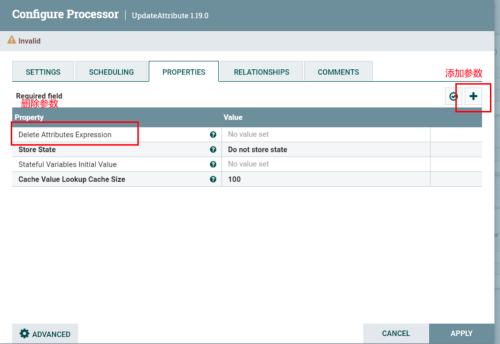
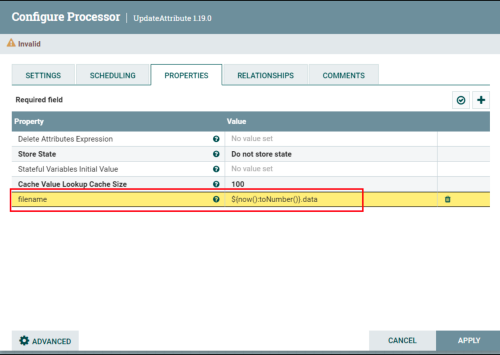
修改配置参数。
修改文件名称为当前时间戳加data后缀。
(3)重新连接处理器
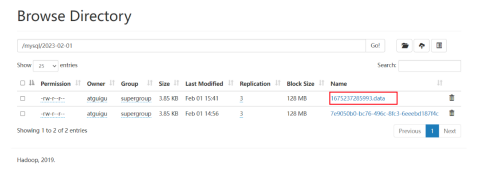
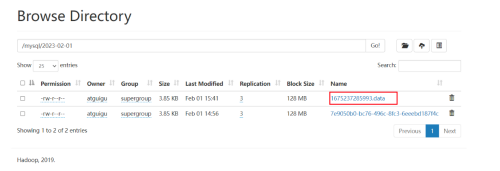
重新发送数据,检查hdfs。
案例三 实时监控kafka数据到hdfs
需求:实时监控kafka主题,将数据同步发送到hdfs。
新建组
新建处理器ConsumeKafka_2_6
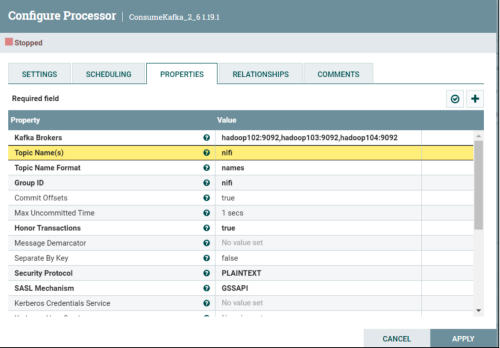
新建处理器PutHDFS
选择文件名相同使用追加写模式。
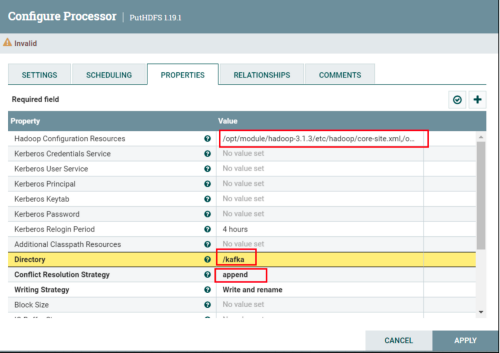
修改文件名称避免小文件问题

运行测试
启动hadoop和kafka,命令行使用一个kafka生成者发送消息
[atguigu@hadoop102 hadoop]$ kf.sh start
[atguigu@hadoop102 hadoop]$ myhadoop.sh start
[atguigu@hadoop102 hadoop]$ kafka-console-producer.sh --broker-list hadoop102:9092 --topic nifi
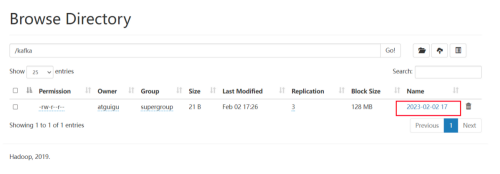
到hdfs上能看到追加写的文件。