1.@Autowired和@Resource区别:
@Autowired是spring提供的,默认按照类型来匹配注入
@Resource是java提供的,可以使用name属性来指定要注入的ben,如果没有使用name属性,那么就按照类型来匹配注入,如果此时要注入的ben有多个实例,则会报错
@autowired可以用于构造器,属性和方法中,resource只能用于属性和方法中
@autowired加上@Qualifier注解可以指定要注入的ben
2.使用@JsonFormat(shape = JsonFormat.Shape.STRING)
注解
在数据库中,有关于涉及到金额问题的都会使用decimal类型,通常后面都是保留两位小数,但是在发送给前端的时候,经过Json格式装换的时候,会把数字后面为0的去掉,所以就需要在金额字段上加@JsonFormat(shape = JsonFormat.Shape.STRING),让json格式化的时候,不要去掉0

3.数据库中的datetime问题
在我现在的项目中,创建表的时候,时间类型是使用datetime,如果不设置长度的话,默认不保存毫秒值,如果设置的话,一般设置3,表示保留三位毫秒数,然后对应到java字段的 LocalDateTime 类型、这个时候通常会使用注解:
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone="GMT+8")会把时间以json形式放回给前端,进行日期的格式化,前端传递过来的时候,根据 pattern 中的格式,可以进行格式化成 LocalDateTime
4.数据库中表字段涉及到小数点的情况
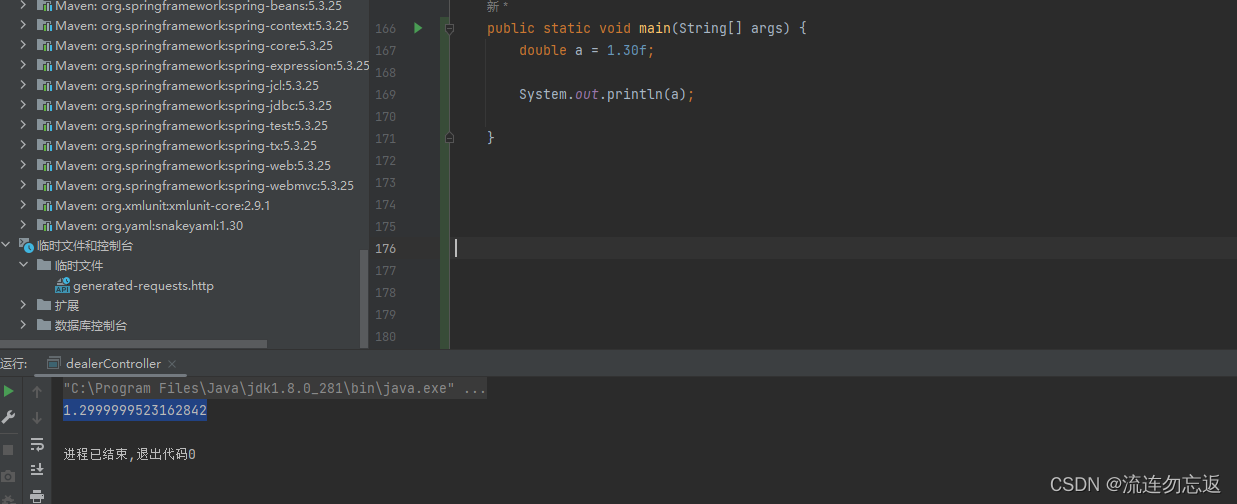
如果是自己设置数据库字段的时候,有涉及到小数点的一定要使用 decimal 类型,别想着使用flaot类型可以省点字节长度,因为使用double类型或者float类型的话,对应到java的时候就是double类型的属性,如果使用double类型会出现各种精度丢失的情况,比如定义1.30的一个值,使用System.out.println输出就会出现精度丢失的情况,而且使用double的时候,会自动把最后的一个0去掉
5.在写xml文件的时候,如果不想使用java对象来接收的返回值,可直接使用Map来接收查询出来的值
在写查询语句的时候,如果有一条数据想以Map的形式返回,那么在mapper接口的返回值可以写Map<String,Object>,如果有多条数据以Map的形式返回,在mapper接口的返回值就写List<Map<String,Object>> ,只要在xml文件中的resultMap值写:java.util.Map,就可以对应以上两种情况了
如果使用这种方式的话,就有很多需要注意的地方了,那就是resultType="java.util.Map" 这里是不能指定泛型的,所以无论接口的返回值用什么接收,在xml文件中查出来的结果,最终都是以Map<Object,Object>来返回,尽管接口的返回值有指定泛型,例如接口的返回值是:Map<String,String> 但是这个Map的实际泛型是:Map<Object,Object>
所以当返回的结果里面有long类型,或者大数类型的时候,直接使用Map.get("字段名")有可能会类型转换异常,例如:
而且在前后端分离的时候,假设接口中的返回值类型是Map<String,Object> 然后通过xml文件查询的结果中有长整数型,那么使用@responseBody注解 传递给前端之后,会出现精度丢失的情况,这个问题不是json工具包的问题,而是由于js存储大数字丢失精度引起。
当js表达整数时,最多表达15位数字,如果超过15位就会出现精度丢失
所以需要数字类型改为字符串,转为json,传到前端就不会丢失精度了
注意:因为xml文件中 resultType="java.util.Map" 指定不了泛型,所以在接口的返回值中最好使用Map<String,Object>来接收


6.xml文件中的模糊查询和分页以及排序编写

7.js的常见操作

8.小程序的抽奖简单算法
public static int lottery(double[] prob) { double rand = Math.random(); // 生成一个0到1之间的随机数 double cumulativeProb = 0.0; // 初始化累积概率为0 for (int i = 0; i < prob.length; i++) { // 遍历每个奖项的概率 cumulativeProb += prob[i]; // 累加奖项概率 if (rand < cumulativeProb) { // 如果随机数小于累积概率,表示抽中该奖项 return i; // 返回该奖项的索引 } } return -1; // 如果所有奖项概率之和小于1,则返回-1表示抽奖失败 }该算法的基本思路是,首先生成一个0到1之间的随机数 rand,然后遍历每个奖项的概率,并将这些概率逐个累加到变量 cumulativeProb 中。如果随机数小于 cumulativeProb,则表示抽中了对应的奖项,返回该奖项的索引;否则继续累加下一个奖项的概率,直到找到抽中的奖项或者所有奖项的概率之和大于等于1。
如果一等奖的礼品已经送完了,那么在进行抽奖时就不能再抽到一等奖了。这种情况下,可以将一等奖的概率设置为0,然后重新计算所有奖项的概率之和,再进行抽奖即可。public static int lottery(double[] prob, boolean[] isPrizeAvailable) { double rand = Math.random(); double cumulativeProb = 0.0; for (int i = 0; i < prob.length; i++) { if (!isPrizeAvailable[i]) { // 如果该奖项的礼品已经送完,则概率设置为0 prob[i] = 0.0; } cumulativeProb += prob[i]; } if (cumulativeProb == 0.0) { // 如果所有奖项的概率都为0,则返回-1表示抽奖失败 return -1; } for (int i = 0; i < prob.length; i++) { prob[i] /= cumulativeProb; // 重新计算每个奖项的概率 } cumulativeProb = 0.0; for (int i = 0; i < prob.length; i++) { cumulativeProb += prob[i]; if (rand < cumulativeProb) { isPrizeAvailable[i] = false; // 将抽中的奖项标记为已送完 return i; } } return -1; }如果`prob`数组中的所有奖项概率之和等于1,则该算法不会返回-1,因为在抽奖过程中总会抽中一个奖项。如果所有奖项的概率之和小于1,则该算法会返回-1,表示抽奖失败。
在代码中,如果所有奖项的概率之和等于0,则会直接返回-1,表示抽奖失败。如果概率之和大于0,则会在循环中逐个计算每个奖项的概率之和,并与随机数进行比较,返回对应的奖项。