近期HuggingFace发布了能满足各种音频处理需求的AI解决方案AudioGPT。我觉得种模式以后会经常见到,即ChatGPT等大型LLM充当大脑,其他专业模型充当工具,实现1+1>2的效果。
各种资源地址:
代码地址:https://github.com/AIGC-Audio/AudioGPT
Demo:AudioGPT - a Hugging Face Space by AIGC-Audio
简单介绍:
以下是 AudioGPT 的能力列表:
Speech
| Task | Supported Foundation Models | Status |
|---|---|---|
| Text-to-Speech | FastSpeech, SyntaSpeech, VITS | Yes (WIP) |
| Style Transfer | GenerSpeech | Yes |
| Speech Recognition | whisper, Conformer | Yes |
| Speech Enhancement | ConvTasNet | Yes (WIP) |
| Speech Separation | TF-GridNet | Yes (WIP) |
| Speech Translation | Multi-decoder | WIP |
| Mono-to-Binaural | NeuralWarp | Yes |
Sing
| Task | Supported Foundation Models | Status |
|---|---|---|
| Text-to-Sing | DiffSinger, VISinger | Yes (WIP) |
Audio
| Task | Supported Foundation Models | Status |
|---|---|---|
| Text-to-Audio | Make-An-Audio | Yes |
| Audio Inpainting | Make-An-Audio | Yes |
| Image-to-Audio | Make-An-Audio | Yes |
| Sound Detection | Audio-transformer | Yes |
| Target Sound Detection | TSDNet | Yes |
| Sound Extraction | LASSNet | Yes |
Talking Head
| Task | Supported Foundation Models | Status |
|---|---|---|
| Talking Head Synthesis | GeneFace | Yes (WIP) |
论文解读:
论文题目:AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head

论文的主题和研究目的是探索大型语言模型(LLM)在处理复杂音频信息和进行口语对话方面的能力,提出了一个名为AudioGPT的多模态AI系统,能够理解和生成语音、音乐、声音和说话头像。
模型架构:
AudioGPT 可以分为四个阶段,包括模式转换、任务分析、模型分配和响应生成。它为ChatGPT配备了音频基础模型来处理复杂的音频任务,并与模式转换接口连接以实现语音对话。研究者设计了评估多模式语言模型的原则,即一致性、能力和鲁棒性。模式转换阶段将语音输入转换为文本,以供ChatGPT理解。任务分析阶段确定语音命令的类型和参数。模型分配阶段选择适当的音频模型来完成任务。最后,响应生成阶段将模型的响应转换回语音。
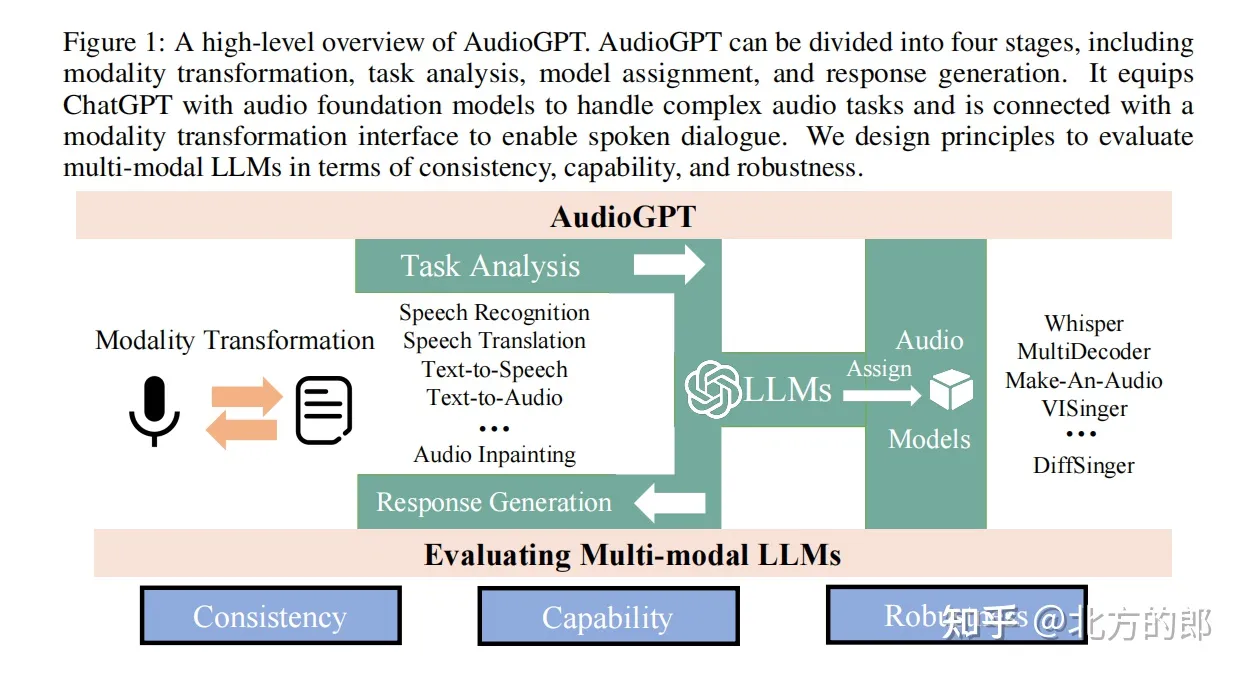
AudioGPT 具有处理不同类型音频任务的能力,如音乐生成、环境音效模拟和语音转换。它可以稳定地转换模式,并为不同的语音命令生成一致和适当的响应。此外,AudioGPT 对不同说话人和噪声环境也比较鲁棒。AudioGPT 通过将transformer语言模型与音频模型结合,实现了聊天机器人的语音交互功能。它打通了语言和音频的鸿沟,使聊天机器人的能力更加丰富多样。AudioGPT 为开发多模态语言模型提供了有价值的设计理念和框架。
模型评估:
研究者从以下三个方面评估语言模型:
1) 一致性,用于测量语言模型是否正确理解用户的意图,并分配与人类认知和问题解决能力密切相关的音频基础模型;
2) 能力,用于测量音频基础模型在零样本情况下处理复杂音频任务、理解和生成语音、音乐、声音及说话人头像的性能;
3) 鲁棒性,用于测量语言模型在特殊情况下的处理能力。
一致性检查语言模型是否可以根据上下文正确推断音频命令的类型和参数。它评估语言模型对人类思维方式和解决问题的方式的理解程度。

能力则评估音频基础模型处理各种音频任务的技能,如无样本生成语音、音乐、环境音效或视频。这显示语言模型及其音频基础模型在多模态方面的学习和理解能力。

最后,鲁棒性评估语言模型在噪声、口音或单词选择变化的情况下的表现。这显示其在特殊情况下的泛化能力。
总之,这三个标准可以全面而系统地评估语言模型在多模态环境下的性能。它们考察了语言模型在理解、生成和泛化各种模态内容方面的能力。这为开发更加高效和适应性强的多模态语言模型提供了有价值的指标
论文的研究方法和数据来源:
使用了一个包含多种音频类型和自然语言文本的海量数据集,来训练AudioGPT。该数据集包括了来自GitHub、Notebook等平台的源代码和文本,以及来自YouTube、Spotify等平台的语音、音乐、声音和说话头像。
论文的主要发现和结论:
AudioGPT在多个音频理解和生成任务上表现出优异的性能,超过了现有的模型和基线。这些任务包括文本到语音、语音到文本、语音到音乐、语音到声音、语音到说话头像等。论文还对AudioGPT进行了广泛的分析,探讨了其优势和局限性,并为未来的研究提供了一些启示。
论文的创新点和意义是:
首次提出了一个基于变压器的大型语言模型,用于处理复杂音频信息和进行口语对话,展示了其在多种音频类型和任务上的通用性和强大性。
首次构建了一个包含多种音频类型和自然语言文本的海量数据集,用于训练大型语言模型,并将其以开放访问、开放科学和开放治理的方式发布在arXiv平台上,供社区使用和改进。
首次采用了一种多模态的评估框架,对大型语言模型在人类意图理解和与基础模型合作方面进行了测试,考察了其在一致性、能力和鲁棒性方面的表现1。
初步测试:
AudioGPT - a Hugging Face Space by AIGC-Audio

大家需要注意的一点是,它是需要用户提供ChatGPT的Key的。简单测试了一下:

初步感受了一下,可以生成音频,对于要求生成狗叫等声音也都比较准确。对于其他一些任务,感觉还有较大的提升空间。
感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^