循环依赖问题
A类中有b对象,B类中有a对象,互相引用,
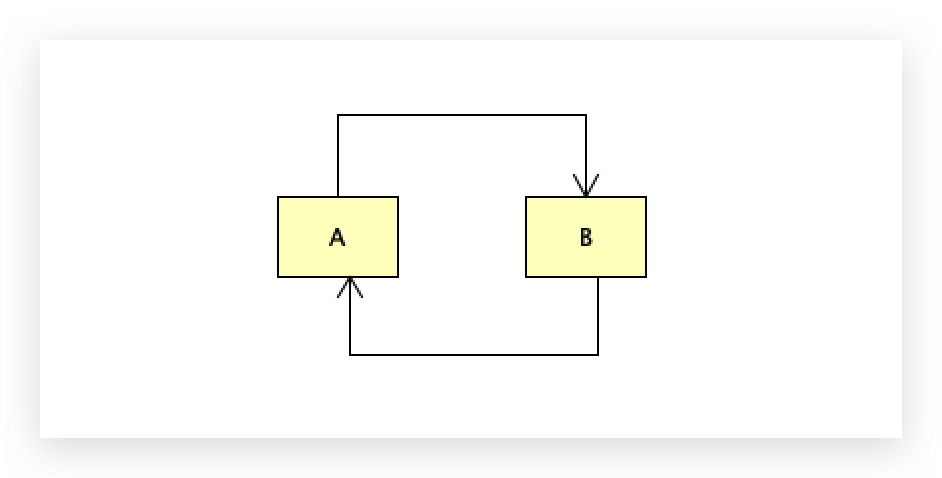
在spring整个生命周期里面,所有bean默认都是单例的,通过反射创建一个具体的对象,设置对象属性值。
当前这种情况,要么先创建a,要么先创建b。
如果a对象创建好了,b对象还没有创建,此时需要把b对象也完成实例化,才能给a对象完成一个赋值。
在spring中除了实例化,还有一个初始化 ,这里面就会牵扯到一个循环引用的问题。
怎么解决循环依赖的问题?
所谓实例化,就是在堆中开辟一块空间,实例化要么通过反射要么new的方式。
初始化的时候给某些类的属性进行赋值,设置属性有2种方式,set和构造方法,
set是额外的一个独立的方法,用来设置属性值;
构造方法是既创建了对象又给属性赋值。
set可以解决循环依赖问题,
构造方法不能解决循环依赖。
set先有对象,再给对象set即分成2步。
构造方法创建出对象之后立马给对象属性值赋值,将两步合成一步。
把步骤分开可以解决这个问题,步骤合起来是没有办法解决这个问题的。
当使用三级缓存解决循环依赖问题的时候,本质的点在于将实例化和初始化分开处理。
提前暴露对象 :已经完成实例化但是未完成初始化的对象。
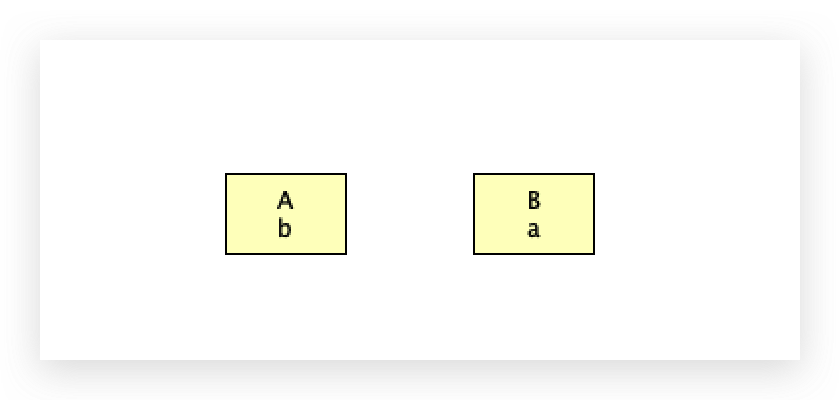
把这两个类放入spring之后,会帮我们进行具体对象的创建,创建的时候对象都是单例的。
单例意味着整个空间中有且仅有这一个对象。
两个bean不可能同时创建,而是一个一个来创建的。
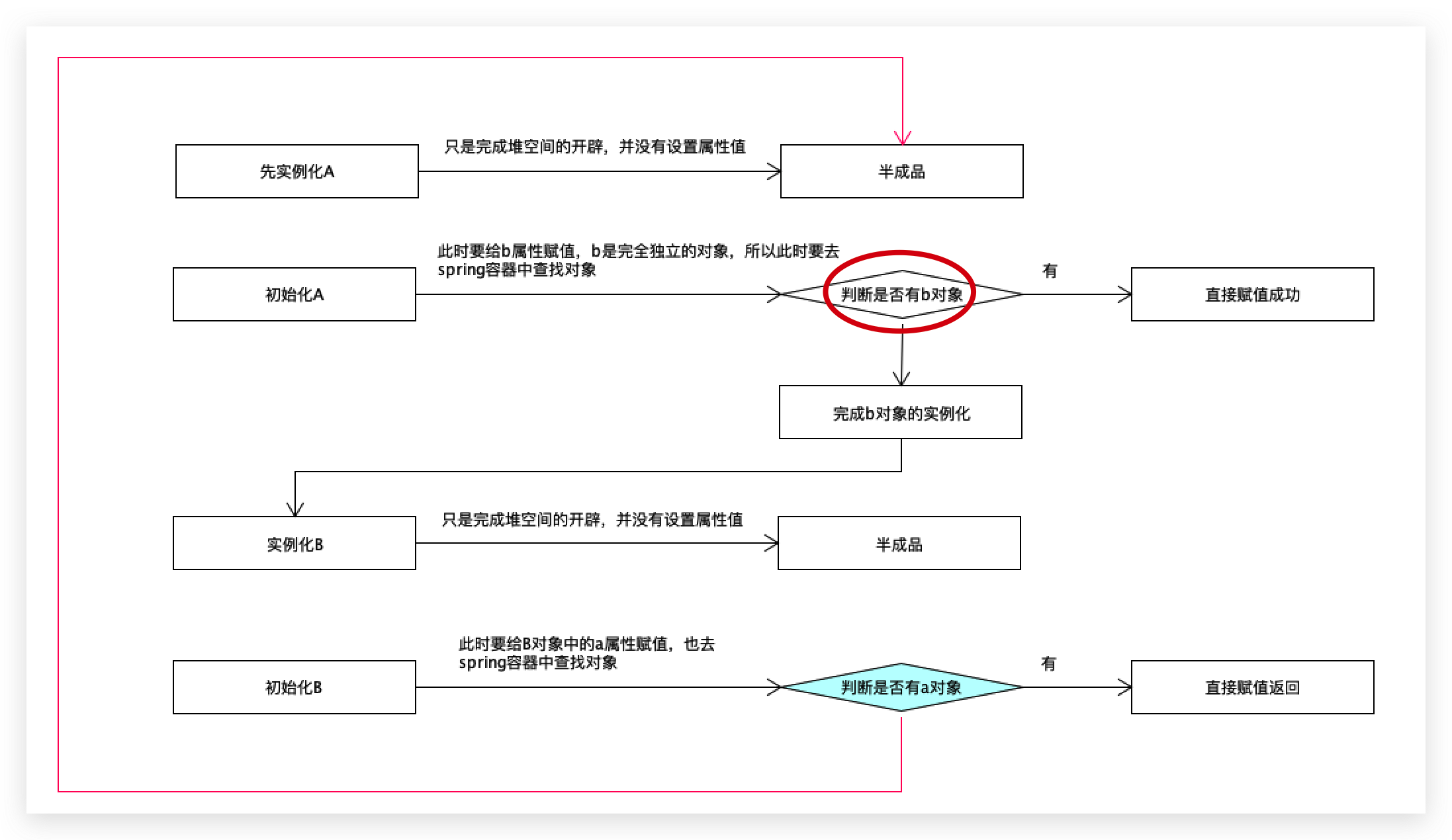
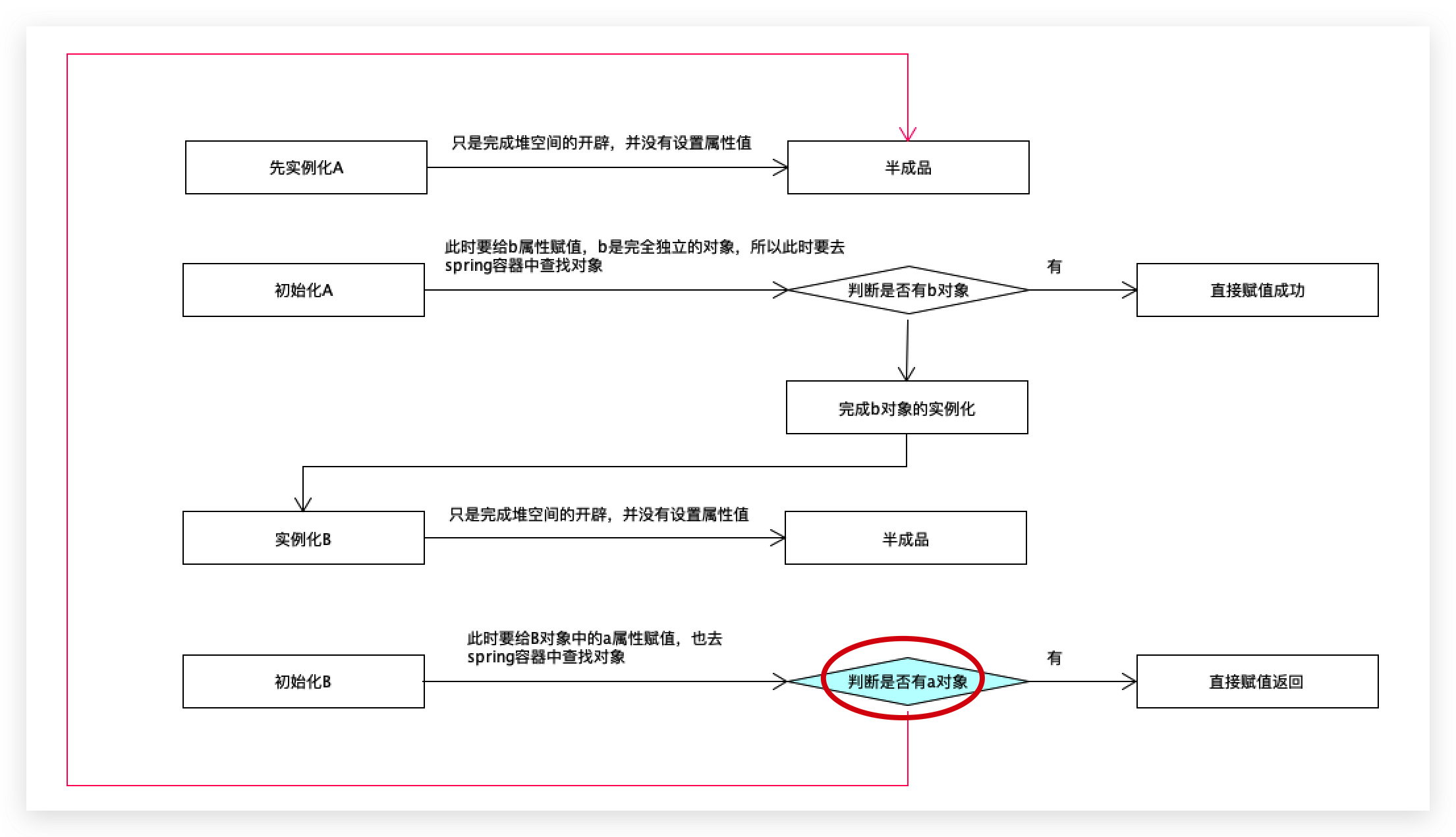
第一步先实例化a对象,此时只是堆空间开辟,并没有设置属性值,此时不是一个完整的对象,是半成品,当有了半成品之后,要初始化a对象,就是给a对象中的b属性完成赋值操作,此时要给b属性赋值了,b是一个完全独立的对象,所以此时要去beanfactory或spring容器中查找b对象,
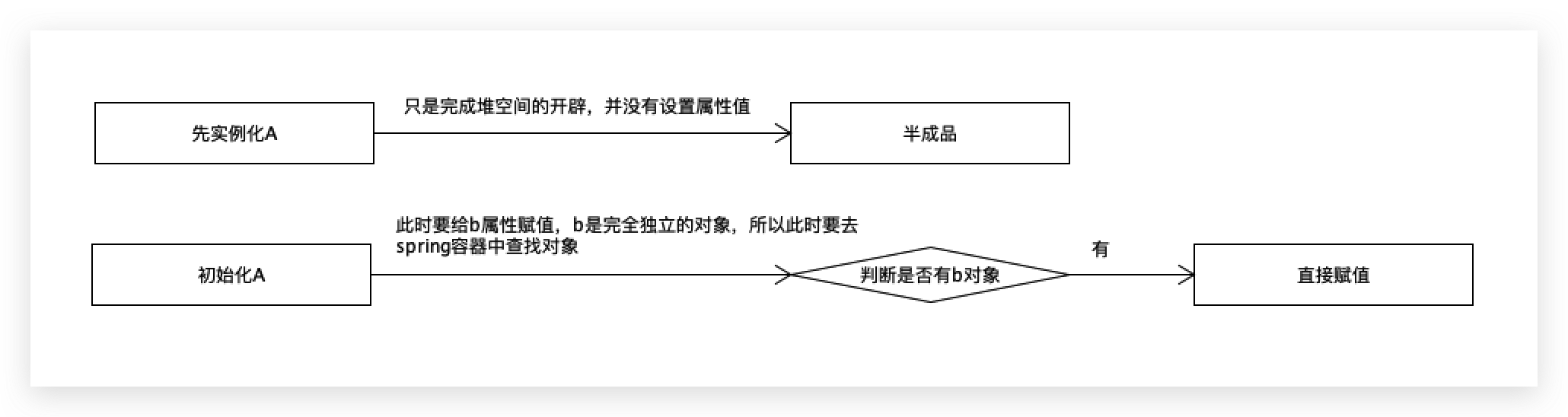
判断是否有b对象,如果有直接赋值,没有的话,要完成b对象的实例化,
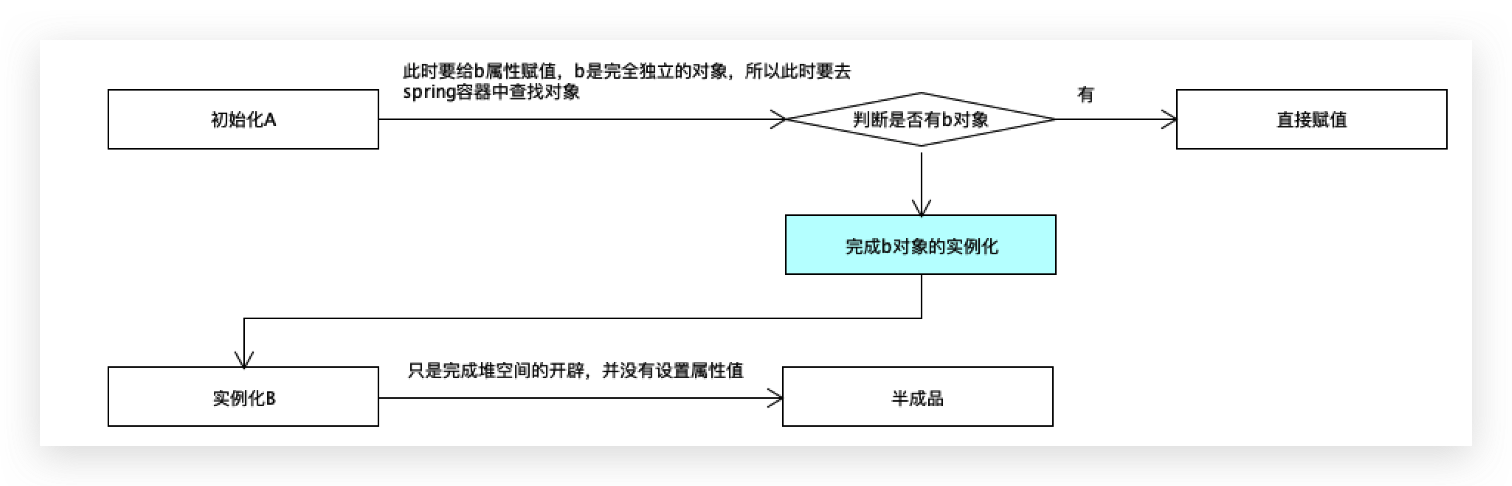
先实例化b对象,如果能成功,说明只是在堆中分配了一块内存空间,并没有设置一个具体的属性值,这里也是半成品,接下来要完成b对象的初始化操作即给b对象中的a属性赋值,去spring容器中查找a对象,如果有的话,直接赋值返回;如果没有怎么办?再次去实例化a,

此时就变成一个环了,永远结束不了。
此时找a对象的时候是否需要把a再重新实例化取决于当前容器里面是否有a,此时a已经完成了实例化,因为之前已经用过了,只不过它不是一个完整的对象,只是一个半成品对象,既然是半成品能不能在半成品里面直接获取到?
直接可以把对应的半成品放到spring容器里面来,半成品放进来之后,会思考一件事情,里面没有属性还不能使用,就意味着在后续的一个处理过程中,最终还是要把当前的a对象完成初始化操作的。
此时最起码已经找到半成品了或者容器里面已经有对象了,只不过这个对象还不能直接拿过来使用,还要进行相关的其他操作。
怎么把半成品放到容器里面?

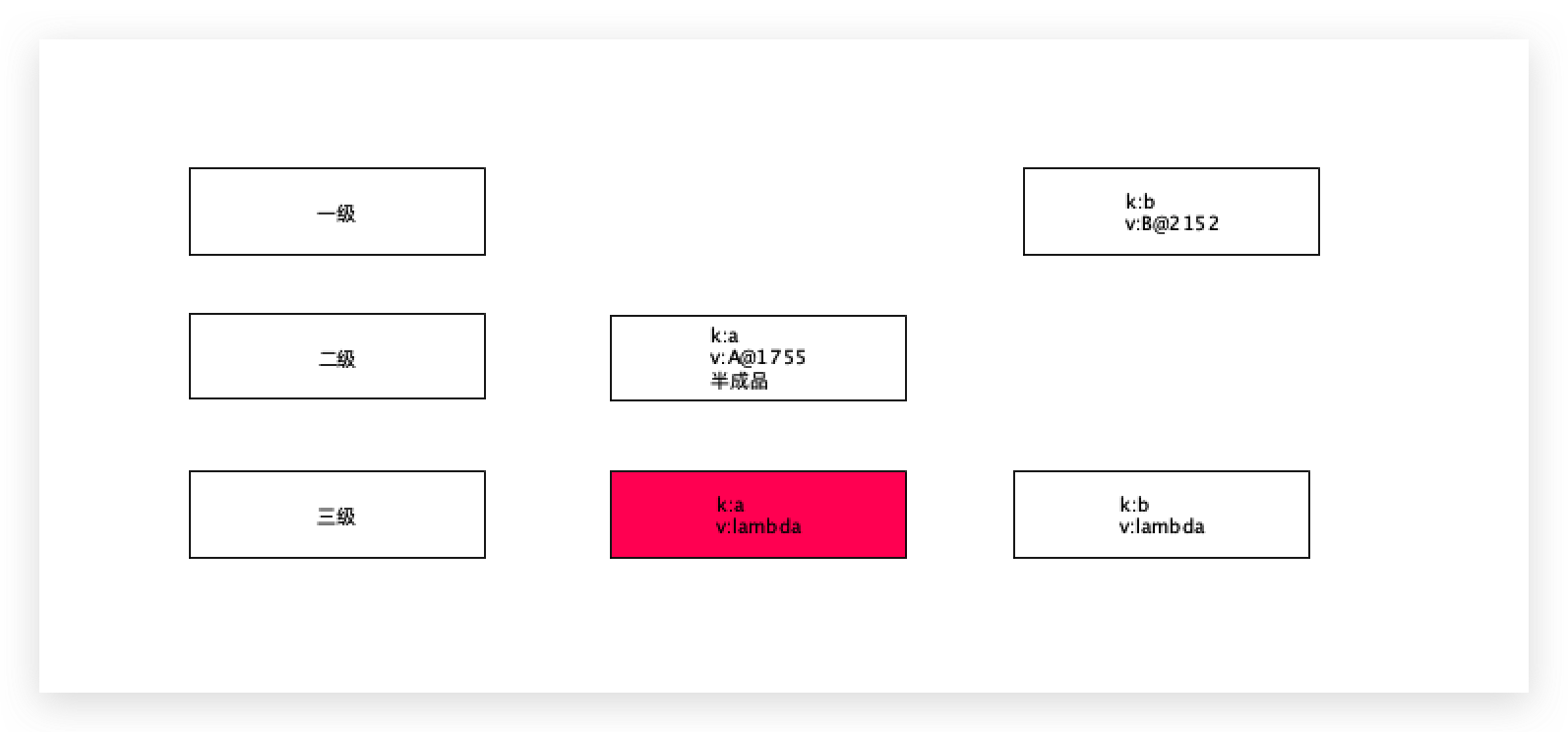
为什么要设计三级缓存的存在? 这三个缓存有什么不同的点?
除了容量和类型之外,不同的地方在于整个集合的范型,一级缓存和二级缓存是Object,三级缓存里面放的是ObjectFactory,
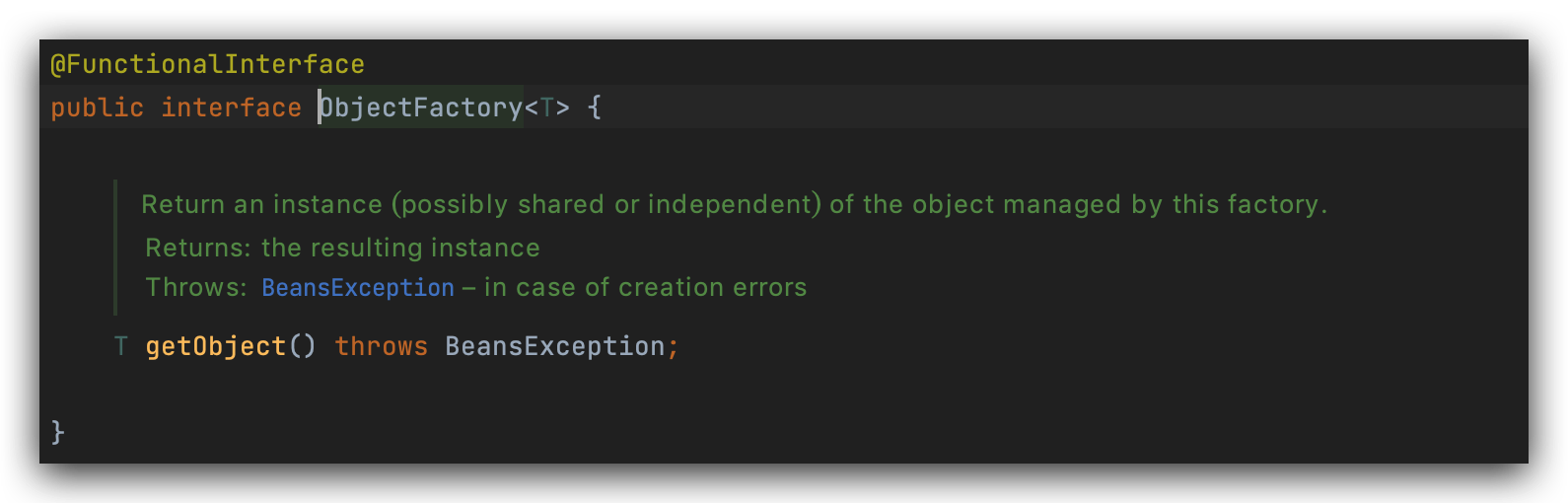
ObjectFactory是函数式接口,仅有一个方法,可以往里面传入一个lamda表达式或传入一个匿名内部类,可以通过getObject方法执行相关的具体逻辑,
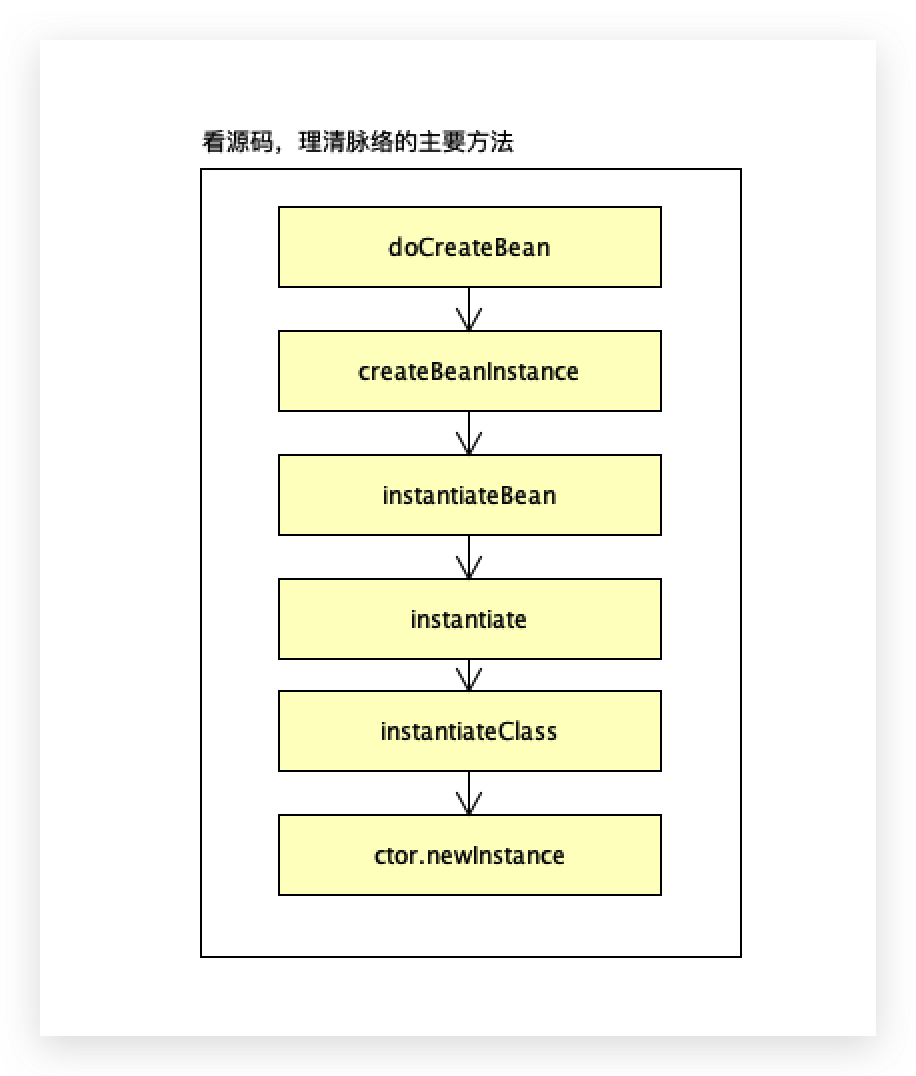
refresh包含的13个方法是spring处理的核心,循环依赖涉及到bean的实例化过程,所以进行相关实例化的时候,要看finishBeanFactoryInitialization(beanFactory)方法,调用beanFactory.preInstantiateSingletons()。
通过debug的方式看bean实例化的过程

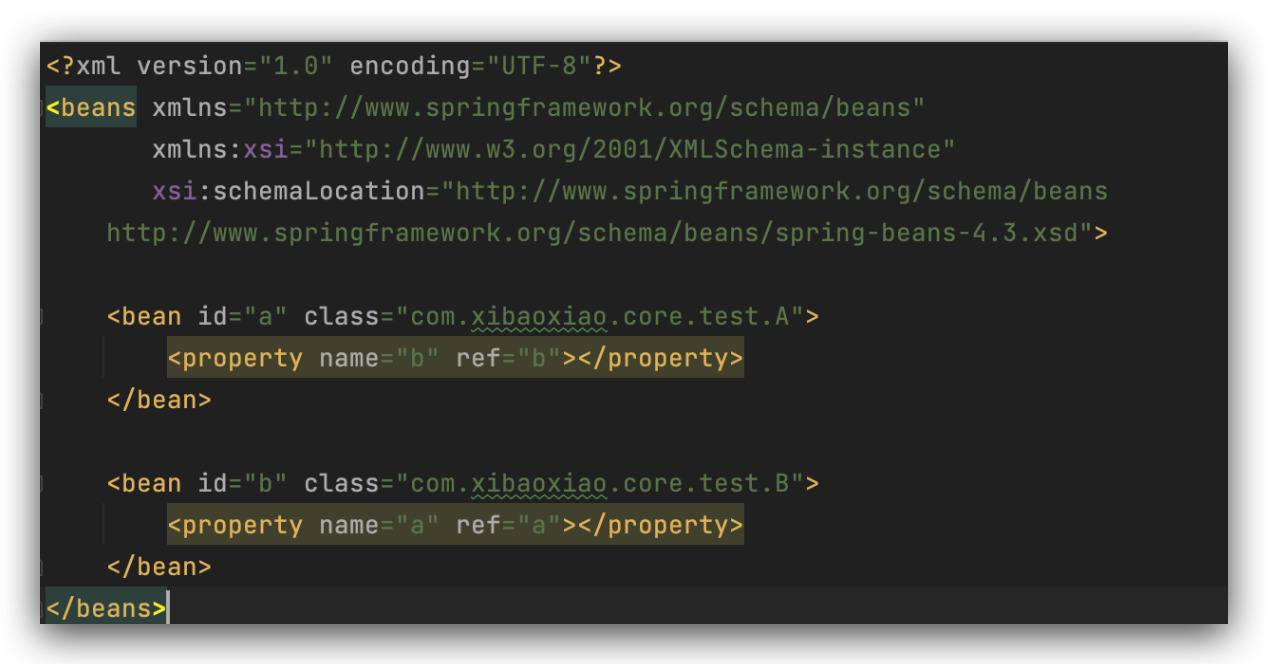
当开始实例化的时候,并没有指定要实例化几个bean,scope默认是单例(singleton),
当执行到finishBeanFactoryInitialization(beanFactory)这一步的时候,配置文件中的2个bean已经被加载了,放到了beanDefinitionNames map集合中,

从这行开始进行实例化,
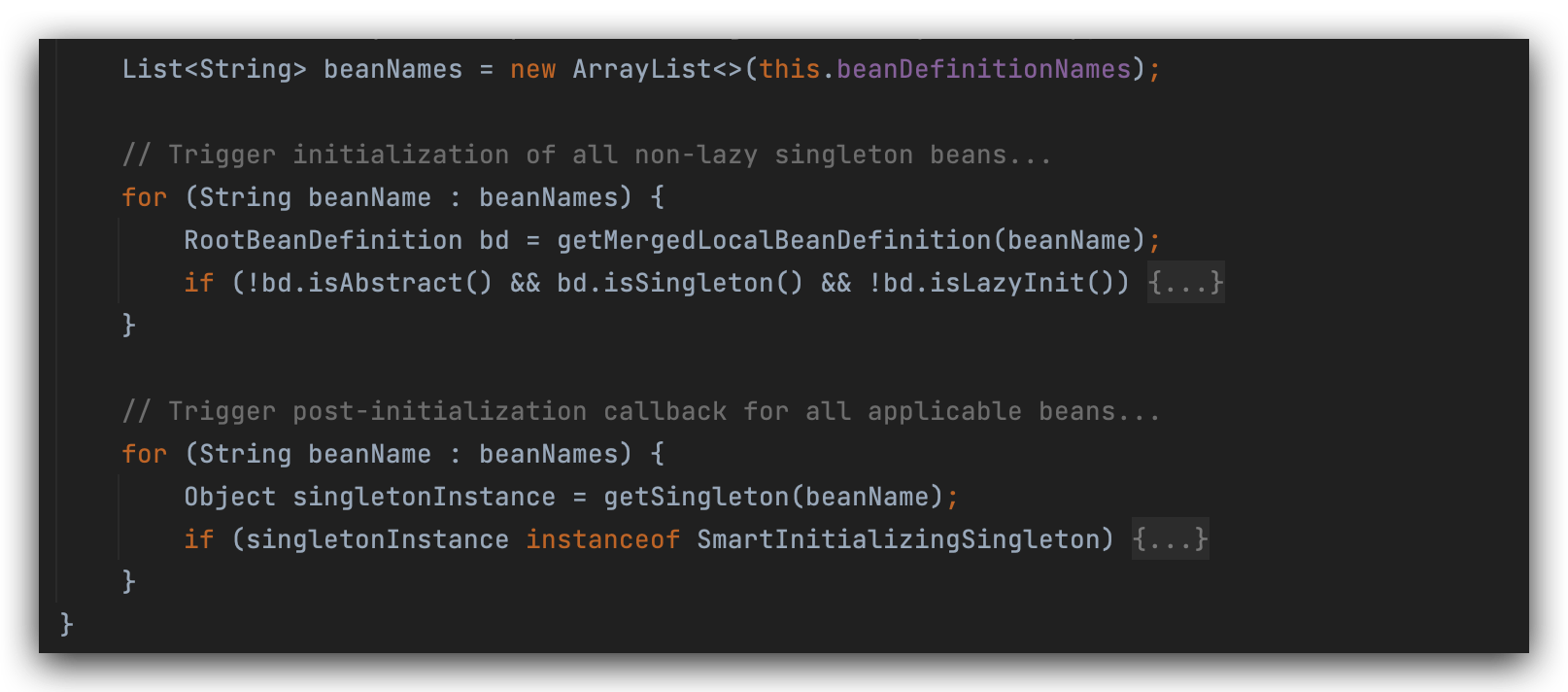
当前空间里包含了2个对象,所以此时要去循环的进行创建。
要么先a后b,要么先b后a,
若a先实例化,a先获取BeanDefinition,判断下是否是抽象的(a不是抽象的),判断下是否是单例的(a是单例的),是否是懒加载的(a不是懒加载的),

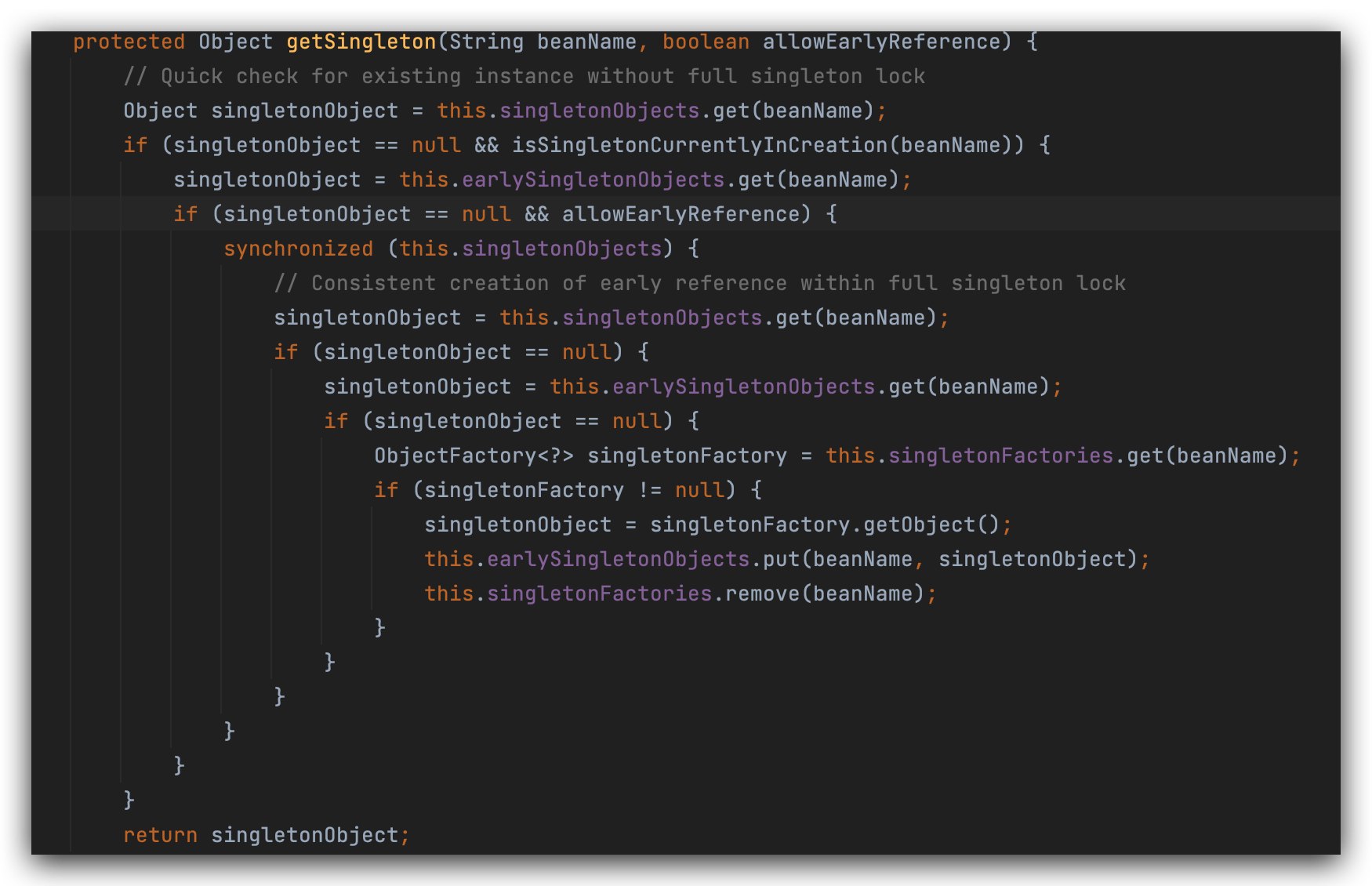
所以条件为true,再判断有没有实现FactoryBean接口,没有,则执行getBean方法(spring在创建对象之前,每次都是先从容器中查找,找不到再创建),
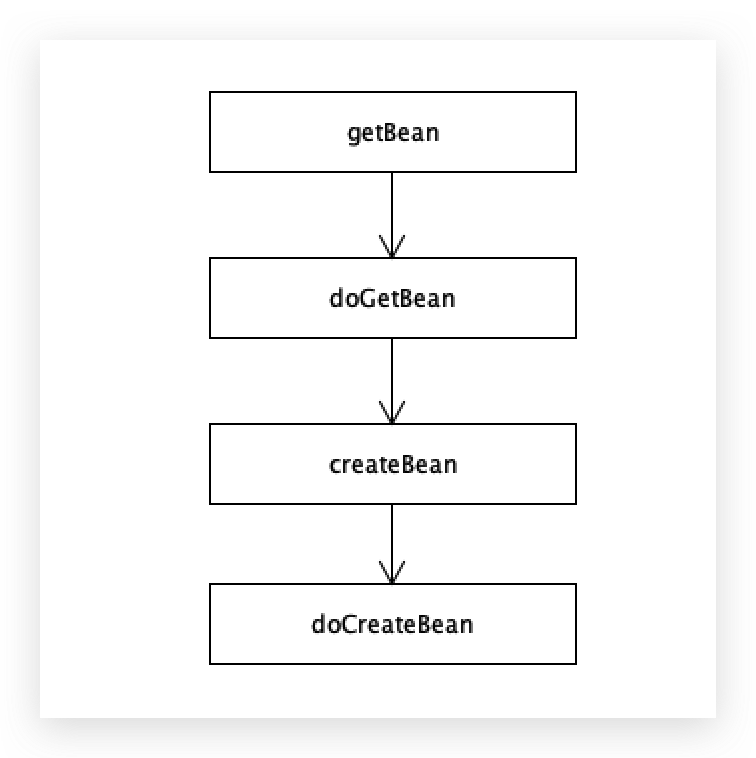

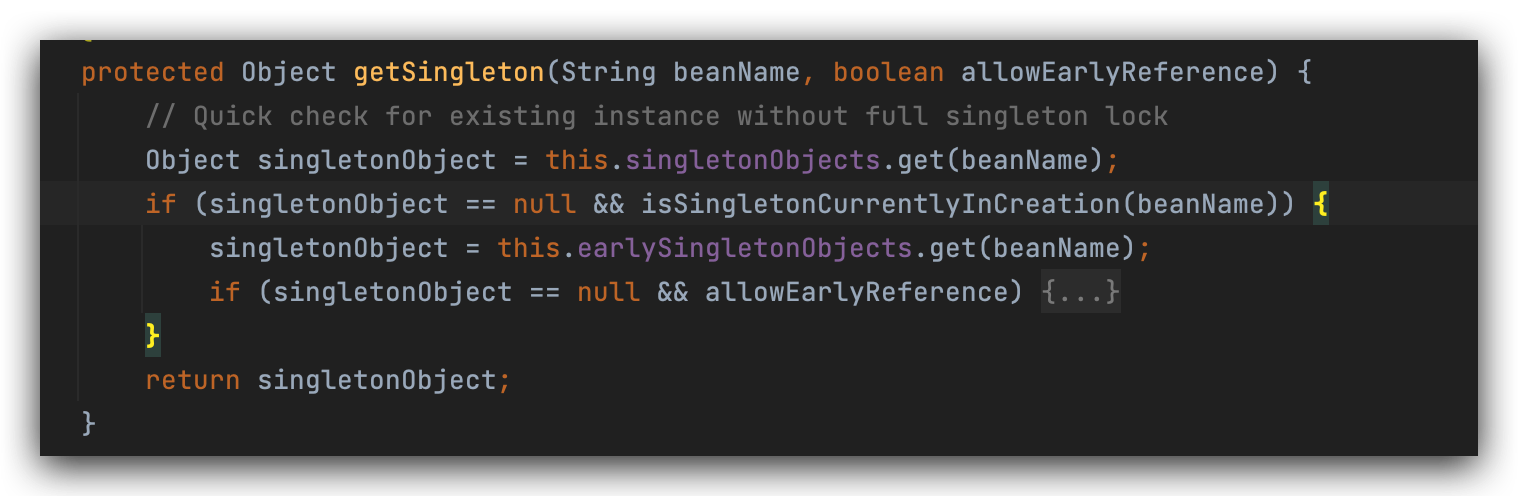
要去容器里面进行一个查找工作,先去一级缓存进行查找,判断当前这个单例对象是否在被创建的过程当中,
a此时还没有开始创建,所以条件为false。
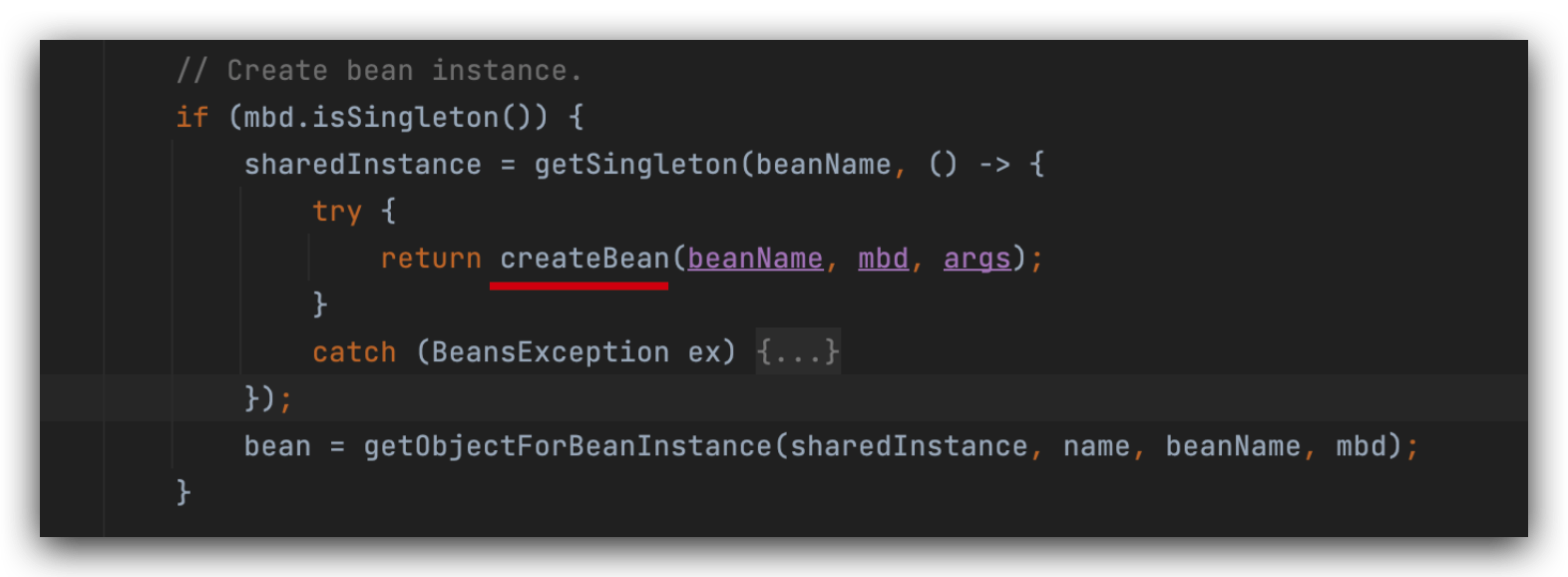
lambda表达式和匿名内部类是一样的,里面最核心的方法是createBean,

先从一级缓存singletonObjects中获取,一级缓存没有的话,调用lambda表,当你看到getObject的时候,它实际上调用的createBean,

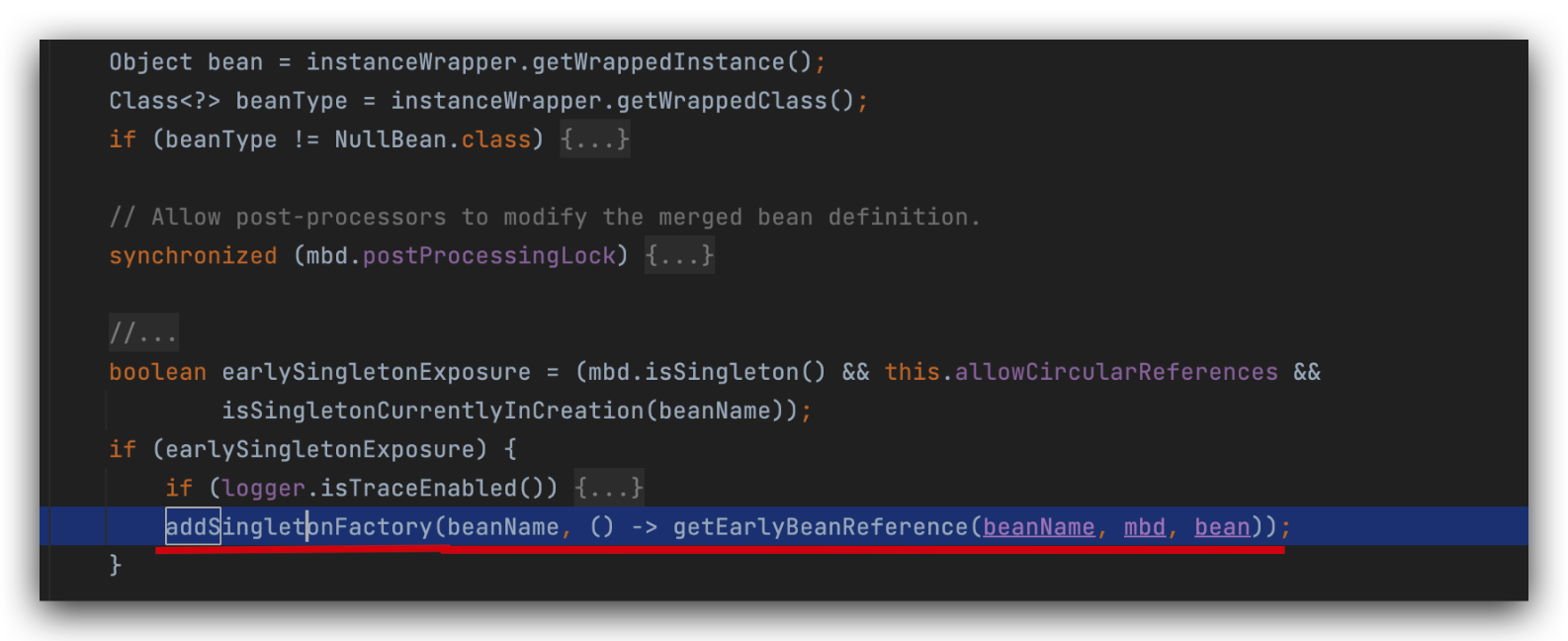
执行到这里,就获取到了a对象了(A@1755),只是b属性是null即还没有给b属性赋值,此时的bean对象是一个半成品,还没有进行初始化。
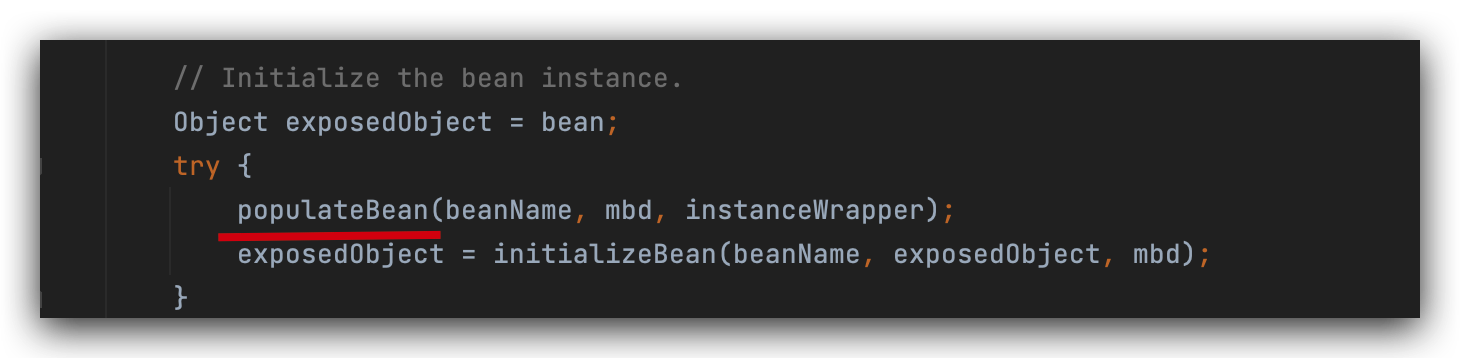
当a实例化完成之后,要完成整体对象的填充即属性填充(给b填充属性值),

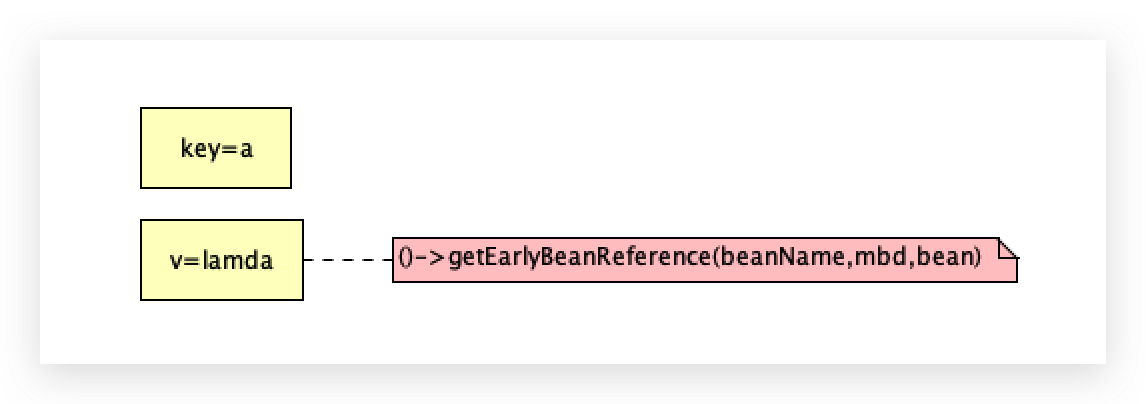
只有调用getObject才会执行lamda表达式。
先判断一级缓存singletonObjects是否包含a(此时不包含),条件为true,将a对应的lambda表达式放三级缓存singletonFactories中,
registeredSingletons这个集合表示哪些对象已经注册过了。

这一步就是完整的属性填充方法,
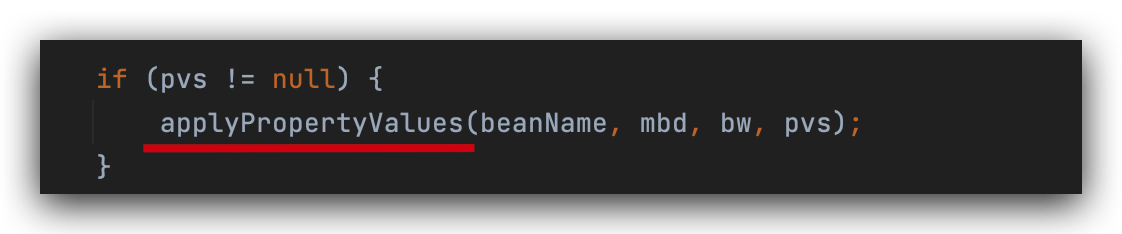
开始填充属性值,给a对象里面的b填充属性,
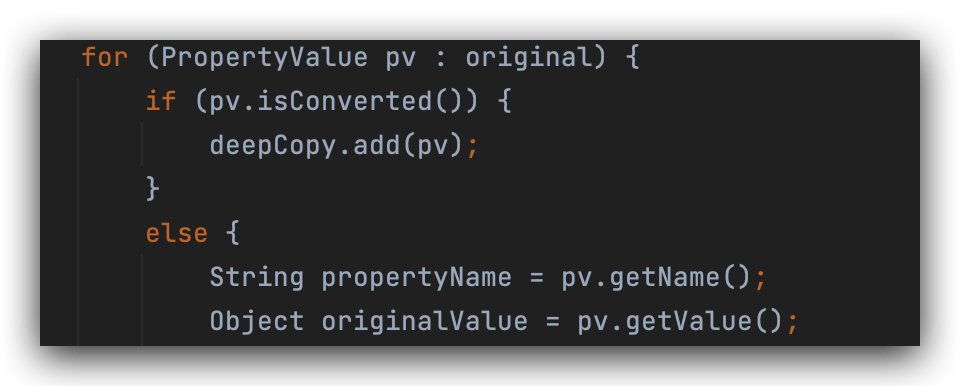
此时属性名称是b,属性值不是bean对象,而是运行时的bean引用,

对当前这个值进行相关的处理工作,
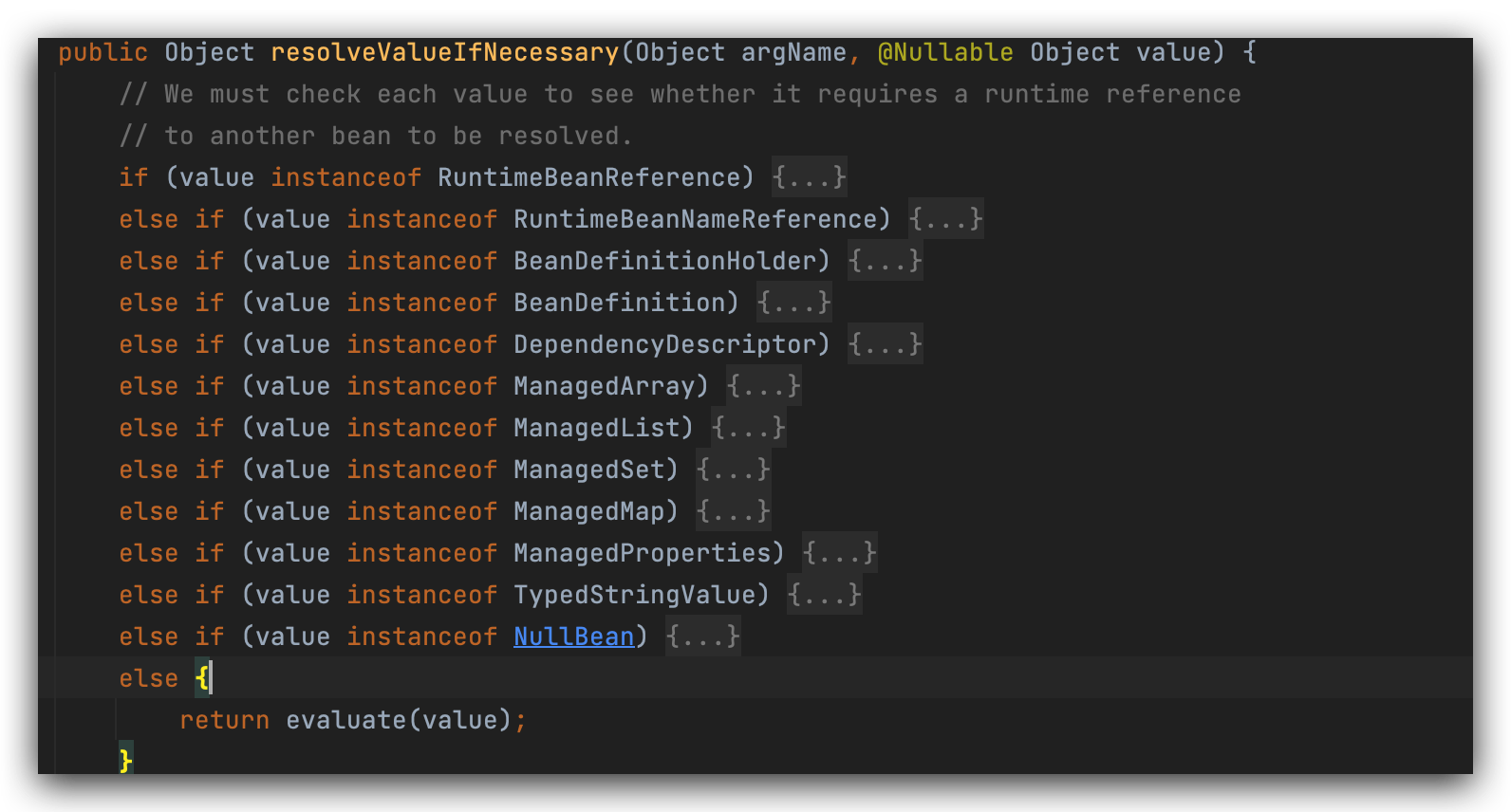
判断value是什么类型,进行相应的解析,


去容器中找b,对应着这一步,

一级缓存没有b对象,b对象也没有在创建,条件不满足,直接返回。
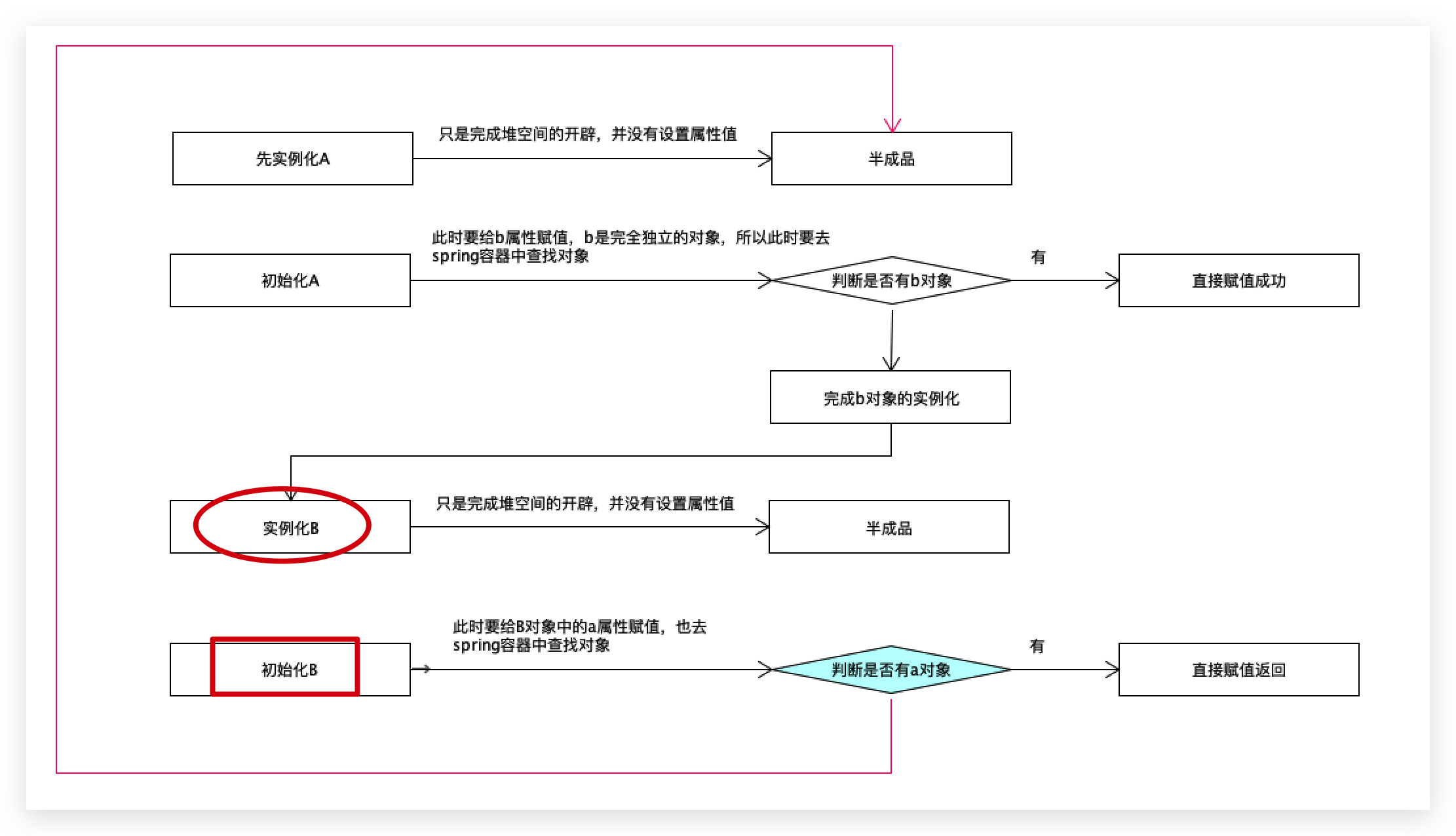
接下来,实例化b对象,

调用createBean->doCreateBean方法,

实例化b,

此时已经有了b对象了,还没有给b初始化,所以a属性是空的,此时b是半成品对象,

此时这两个对象都是半成品对象,只完成了实例化并没有初始化操作,
此时b已经完成了实例化,接下来给b填充属性,

往三级缓存加b的lamda函数,


给b对象里面的a属性填充,因为a还是空的,

从容器中获取a,对应着这一步,

截止目前,已经是第3次调用getBean方法了:
第一次创建a的时候,第二次创建b的时候,第三次给b里面的a属性赋值的时候,
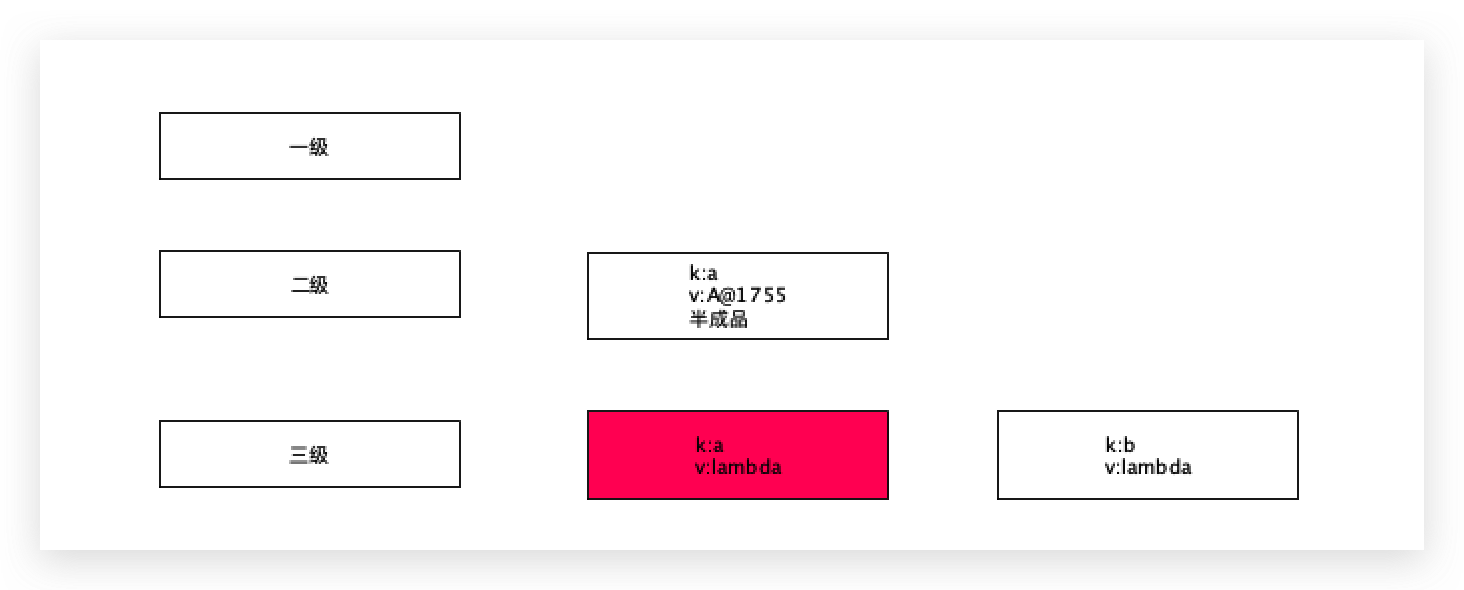
一级缓存中没有,a对象现在是在被创建过程中,再从二级缓存再获取,二级缓存没有,去三级缓存中获取,
根据a去三级缓存中获取到a所对应的lambda表达式,调用getObject方法,实际上执行的是lambda表达式,


这里的bean对象是A@1755,属性b为null,这个时候取到a对象了,只不过此时的a对象是一个半成品对象,然后删除三级缓存中的a对应的lambda表达式,
刚才是为了给b里面的a属性赋值:先实例化a再初始化a,初始化a的时候找b,先实例化b,再初始化b,初始化b的时候要去容器里面找a,a找回来了,赋值给b中的a属性,当赋值完成之后,相当于把a的半成品取回来,完成了整体的赋值操作,意味着b的实例化和初始化都完成了。
一开始为了给a进行初始化,现在b完成了,该去初始化a了,此时a是半成品状态,b是成品状态。
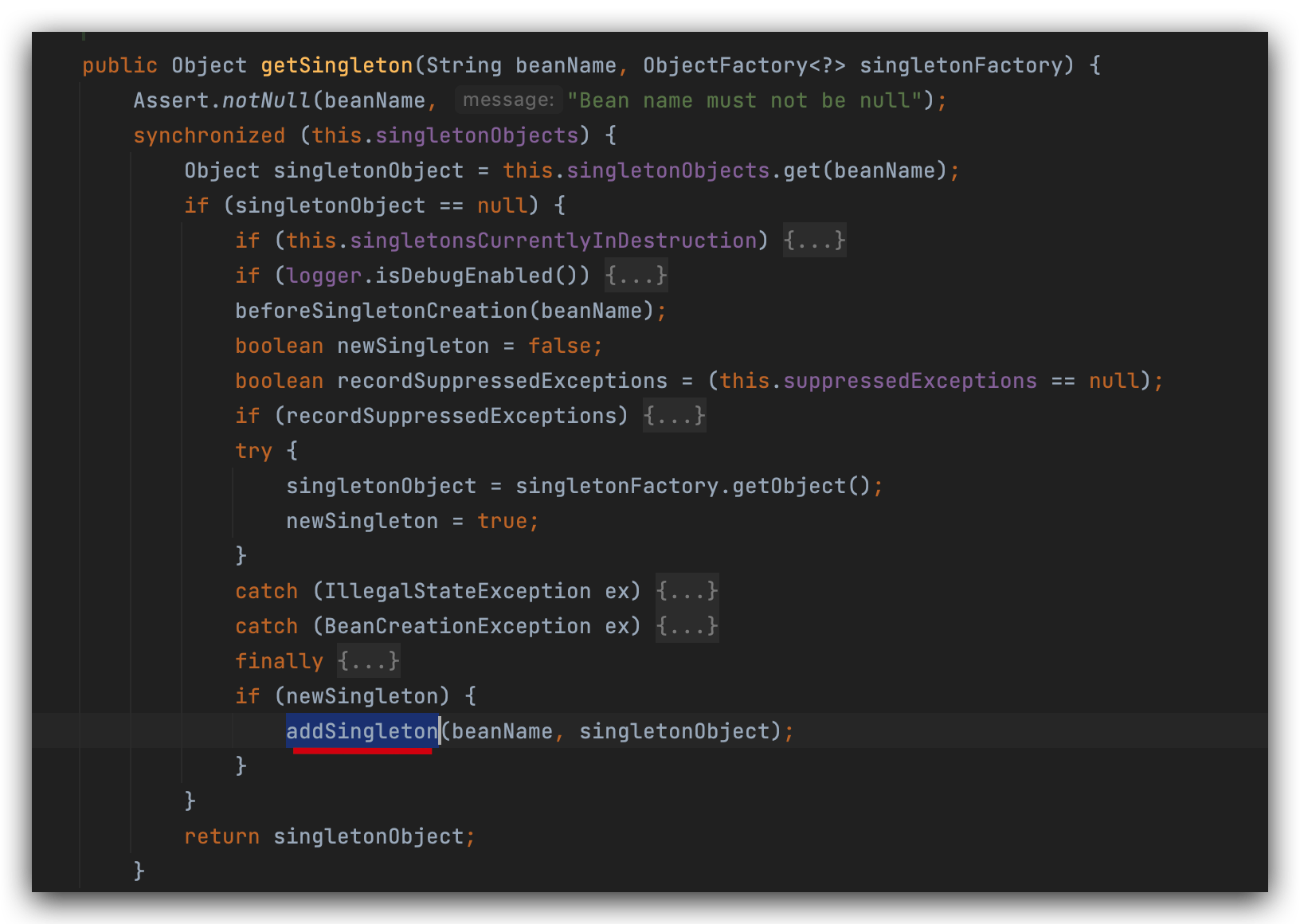
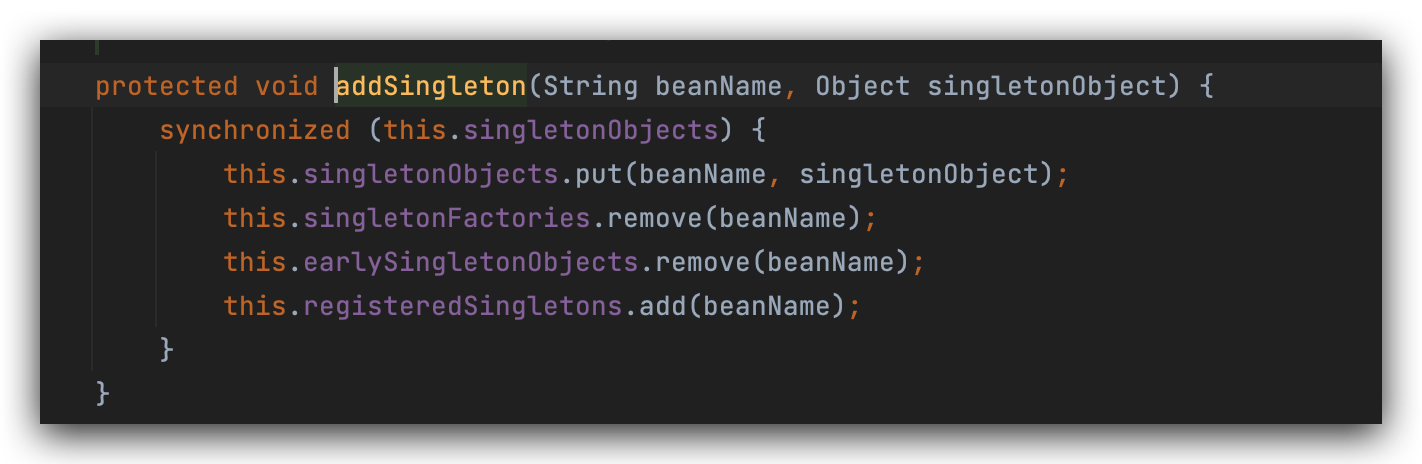
往一级缓存放入对象B@2152,
然后把二级和三级缓存删掉,

然后给a对象的b属性赋值,
执行完这一步就得到了A@1755,属性b为B@2151,现在完成了a对象的初始化工作,a是成品对象了,然后放入一级缓存,把二级三级缓存清理掉,


第一次for循环是为了创建a,此时a对象实例化完成了,第二次循环是要实例化b了,而此时一级缓存已经有b了,直接返回b对象。
小结
三级缓存解决循环依赖问题的关键是通过提前暴露对象来解决,就在于实例化和初始化分开操作,在中间过程中给其他对象赋值的并不是一个完整的对象,而是半成品对象。
先实例化a,再初始化a,然后再实例化b,再初始化b,要找到对应的a,此时取的a是一个半成品状态,所以就解决了循环依赖的问题。