shell函数及数组
一.函数
使用函数可以避免代码重复并将大的工程分割为若干个小的功能模块,代码可读性更强
1.定义函数格式:
function 函数名 {
命令序列
}
函数名(){
命令序列
}
2.返回函数的值
function xc01 {
read -p "请输入:" num
return $[num * 2]
}
xc01
echo $?
在函数体内使用return退出函数并返回函数的值,在函数体外用echo $?获取返回值
注:返回值的范围只能在0~255,超过即需除以256取余

xc01() {
read -p "请输入:" num
echo $[num * 2]
}
xc02=$(xc01)
echo $xc02
在函数体内使用echo输出值,在函数体外可用==变量=$(函数名)==获取函数的返回值

3.函数的传参

内部
-
函数体内部的
$1$2代表的是调用函数时,函数后面跟的位置参数 -
在函数体内部的$#代表调用函数时,函数后面跟的参数个数
-
在函数体内部的
$@$*代表调用函数时,函数后面跟的所有参数
外部
-
函数体外的
$1$2代表的是执行脚本时,脚本后面跟的位置参数 -
在函数体外时$#代表脚本后面跟的参数个数
-
在函数体外时
$@$*代表脚本后面跟的所有参数
注:不管在函数体内还是函数体外,$0都代表脚本本身

4.函数变量的作用范围
-
函数默认只能脚本内的shell环境有效(使用source执行脚本,也会影响系统的当前shell环境)
-
脚本中的变量默认全局有效(即函数体内外都有效)
-
在函数体内执行local变量,可将变量限定在函数体内部使用

5.函数的递归:函数调用自己本身的函数
(1)阶乘

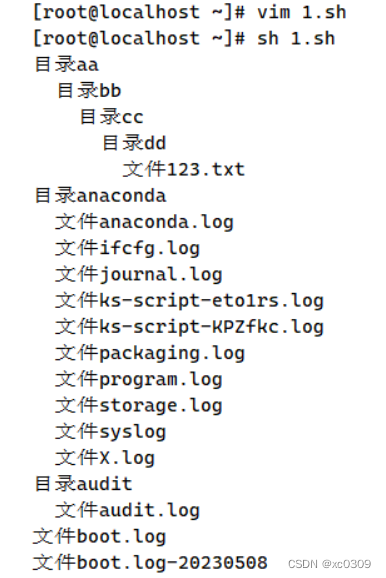
(2)递归目录

6.函数库:即创建一个文件在其中写入常用函数以方便平时写脚本时再重复写入函数(例)


二.数组
1.数组定义方法
(1)数组名=(元素1 元素2 元素3 ……)
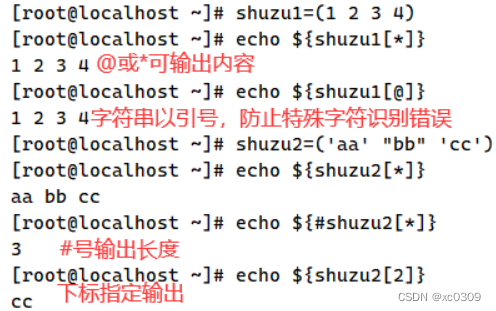
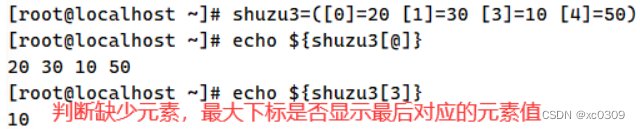
(2)数组名=([下标0]=元素1 [下标1]=元素2 [下标2]=元素3 ……)
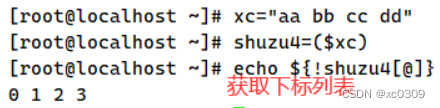
(3)列表名=“元素1 元素2 元素3 ……”
数组名=($列表名)
(4)数组名[下标0]=“元素1”
数组名[下标1]=“元素2”
数组名[下标2]=“元素3”
2.数组切片
格式:==${数组名[@或]:元素起始位置:长度}==*

3.数组替换
格式:==${数组名[@或]/查找需要替换的旧字符/替换旧字符的新字符}==*
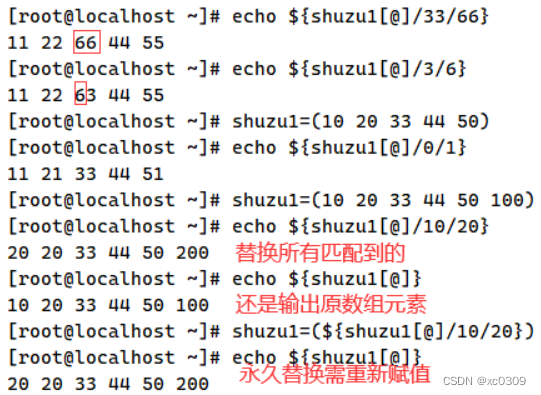
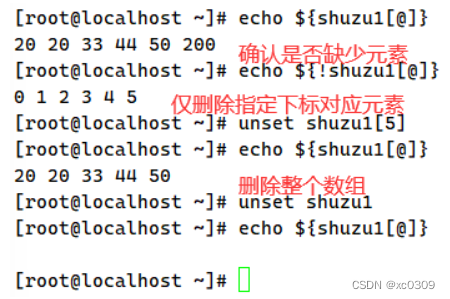
4.数组删除
5.追加元素
方法(1)(2)

方法(3)
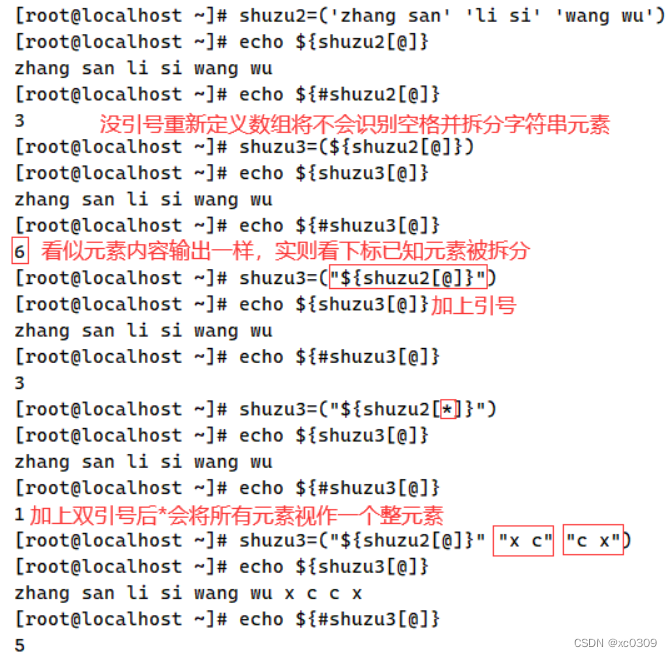
方法(4)

6.向函数传数组参数
注:如果将数组变量作为函数参数,函数则只会取数组变量的第一个值
解决方法:需要将数组变量的值分解成单个的值,然后将这些值作为函数参数使用,在函数内部,再将所有的参数重新合成一个新的数组变量


从函数返回数组


三.排序
1.冒泡

基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到妖组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部
算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了,而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数阻排序轮数而减少


2.直接选择:(交换次数比冒泡少,所以速度更快)

基本思想:
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式


3.直接插入
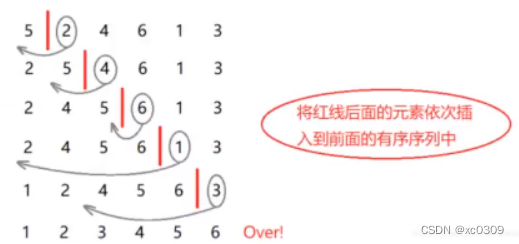
在待排序的元素中,假设前n-1个元素已有序,现将第n个元素插入到前面已经排好的序列中,使得前n个元素有序,按照此法对所有元素进行插入,直到整个序列有序,但我们并不能确定待排元素中究竟哪一部分是有序的,所以我们一开始只能认为第一个元素是有序的,依次将其后面的元素插入到这个有序序列中来,直到整个序列有序为止

4.反转:以相反的顺序把原有|数组的内容重新排序
基本思想:
把数组最后一个元素与第一个元素替换,例数第二个元素与第二个元素替换,以此类拖,直到把所有数组元素反转替换

四.shell脚本内容编辑命令
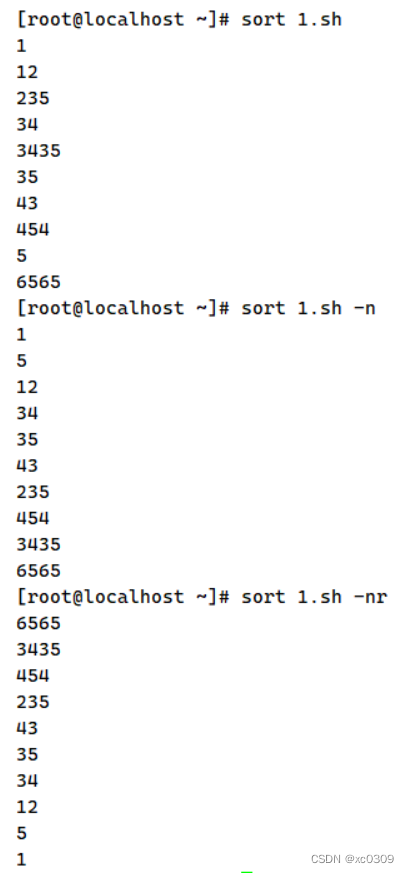
1.sort
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序比较原则是从首字符向后依次按ASCII码值进行比较,最后将它们按升序输出
格式:
sort [选项] 参数
cat 文件名 | sort 选项
| 选项 | 说明 |
|---|---|
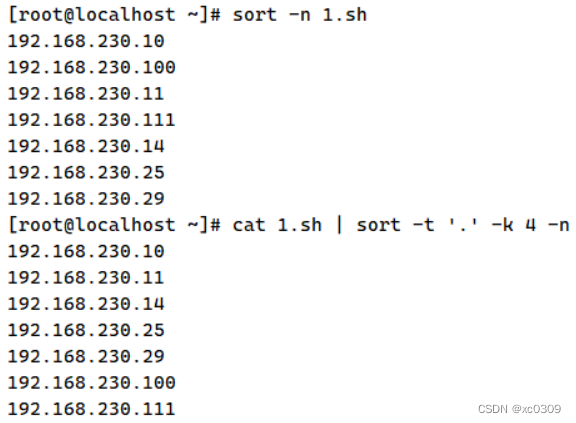
| -n | 按照数字进行排序 |
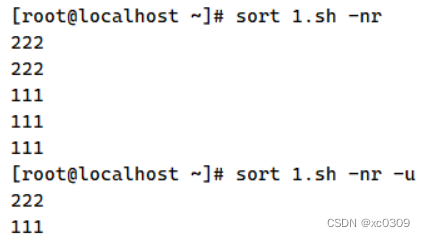
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用Tab键分隔 |
| -k | 指定排序字段 |
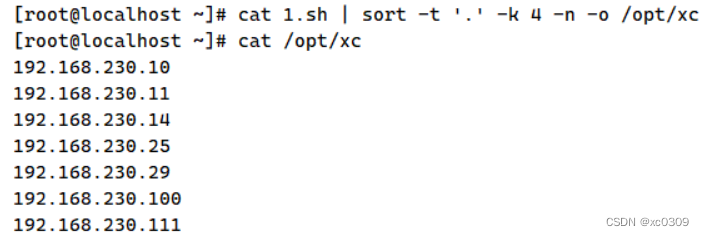
| -o | <输出文字>:将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
2.uniq
用于报告或者忽略文件中连续的重复行,常与sort命令结合使用
格式:
uniq [选项] 参数
cat 文件名 | uniq 选项
| 选项 | 说明 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
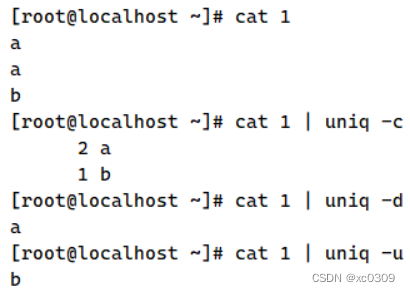
查看处理日志文件示例
3.tr
常用来对来自标准输入的字符进行替换、压缩和删除
格式:tr [选项] [参数]
参数:
字符集1:指定要转换或删除的原字符集,当执行转换操作时,必须使用参数"字符集2"指定转换的目标字符集,但执行删除操作时,不需要参数"字符集2"
字符集2:指定要转换成的目标字符集
| 选项 | 说明 |
|---|---|
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符也可用字符集2替换字符集1 |
| -t | 字符集2替换字符集1,不加选项同结果 |

合并空格的三种方式

4.cut
显示行中的指定部分,删除文件中指定字段
格式:
cut 参数
cat 文件名 | cut 选项
| 选项 | 说明 |
|---|---|
| -f | 通过指定字段进行提取 |
| -d | 将默认的Tab分隔符更改为其他的分隔符 |
| –complement | 排除所指定的字段 |
| –output-delimiter | 更改输出内容的分隔符 |
5.split
Linux下将一个大的文件拆分成若干小文件
格式:split 选项 参数 原文件 拆分后文件名前缀
| 选项 | 说明 |
|---|---|
| -l | 以行数拆分 |
| -b | 以大小拆分 |
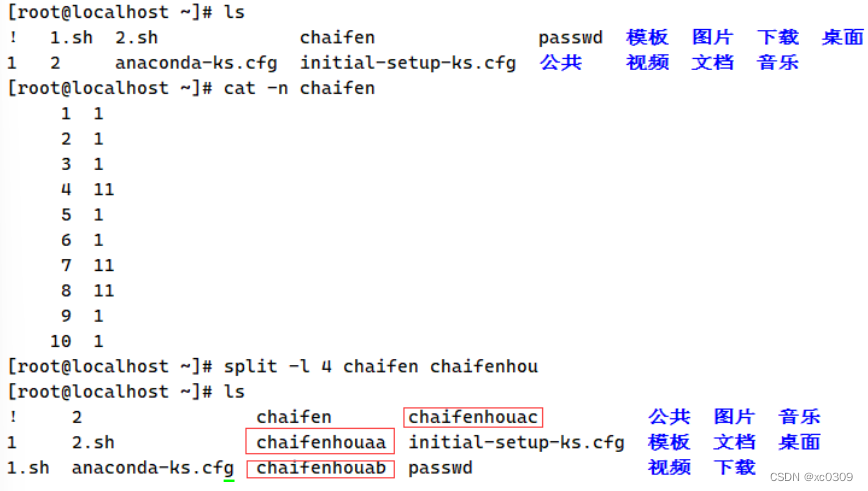
6.eval
命令字前加上eval时 , shell会在执行命令之前扫描它两次,eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令,该命令适用于那些一次扫描无法实现其功能的变量,该命令对变量进行两次扫描

7.paste:以列合并文件内容,默认以制表符分隔
| 选项 | 说明 |
|---|---|
| -d | 指定分隔符合并 |
| -s | 将列成行输出 |
