数组与字符串解法(双指针,快慢指针,哈希表,KMP算法等)
数组解法
1. 快慢指针遍历
往往时间复杂度为O(n)
基本思路:
- 首先确定快慢指针各自的功能:
- 快指针负责遍历全数组,慢指针负责指向最后的值;
- (移动零);
- 快指针与慢指针定步长,两者达到距离要求,输出符合值;
- 快指针循环遍历数组,直达与慢指针汇合;
- 快指针负责遍历全数组,慢指针负责指向最后的值;
- 其次确定快指针与慢指针各自的步长;
- 确定指针遍历的终止条件,并且明确指针目标
2. 切片+双指针遍历
- 旋转数组
输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
k %=len(nums) #当要求数值长度大于数组长度,切记取模!!!!很关键
nums=self.reverse(nums)
#数组切片修改具体位置的内容
nums[0:k]=self.reverse(nums[0:k])
nums[k:len(nums)]=self.reverse(nums[k:len(nums)])
#双指针定义反转函数
def reverse(self,lists):
left=0
right=len(lists)-1
while left<right:
lists[left],lists[right]=lists[right],lists[left]
left+=1
right-=1
#要返回修改后的数组,否则主函数接收不到修改信息
return lists
字符串切片操作
python字符串修改,不如数组方便,其修改方式有三种:
#方法一:字符串支持切片合并操作
#方法二:直接全修改
#方法三:使用replace函数修改特定位置
str="1,2,3,4,5"
res=str[4:1:-1]
#str[1:3]="ans" #TypeError:“str”对象不支持项分配
#方法一:字符串支持切片合并操作
str=str[1:5]+"-ans-" +res #,2,3-ans-3,2
print(str)
#方法二:直接全修改
str=res #3,2
print(str)
#方法三:使用replace函数修改特定位置
ress="abcds-"
str=str.replace(str[0:2],ress) #abcds-2,3,4,5
str=str.replace(str[0:2],"abc--") #abc--2,3,4,5
print(str)
3. 哈希表法**
python中一般可以用字典表示哈希表;当然是用列表也没问题
大多数数组问题,可以使用哈希表进行求解,思考问题可首先想哈希是否可以做。
*两数之和;
*有效的数独
- 核心思路:
将数组元素以键值对的方式存放在字典中,以方便对比该值是否出现过,以及出现了多少次:
#举例
nums=[2,1,3,4,7,2,2,3]
dist={
}
for val in nums:
dist[val]=dist.get(val,0)+1
#字典中键为数组元素;字典值为数组元素出现次数
print(dist) #{2: 3, 1: 1, 3: 2, 4: 1, 7: 1}
另外:
python中还支持字典之间的&操作,但是需要哈希表在python中可以用collections.Counter计数来体现。
该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。但类型其实是Counter。
def intersect(nums1, nums2) :
num1 = collections.Counter(nums1)
num2 = collections.Counter(nums2)
print(num1,num2)
num = num1 & num2
return list(num.keys())
num1=[2,3,4,5,1]
num2=[2,4]
n=intersect(num1,num2)
print(n) #[2, 4]
#-------------------------------
nums = [1, 2, 3, 1, 2, 1]
counts = collections.Counter(nums)
print(counts)
## Counter({1: 3, 2: 2, 3: 1})
print(max(counts)) # 3,这里只是求得最大的键值
print(max(counts.keys(), key=counts.get)) # 1,这里是最大值所对应的键key
dic = dict(counts) #直接转换为字典
print(dic.get(1)) # 3 get在字典中就是传一个键,根据键求对应的值。
字符串解法
1. 字符串在条件允许的情况下,可以转换为列表操作
2.这里在python取模时,当数组为负数时,需要注意的情况:
digit = x % 10
# Python3 的取模运算在 x 为负数时也会返回 [0, 9) 以内的结果,因此这里需要进行特殊判断
if x < 0 and digit > 0:
digit -= 10
# 同理,Python3 的整数除法在 x 为负数时会向下(更小的负数)取整,因此不能写成 x //= 10
x = (x - digit) // 10
3.想要计算字符串字符出现次数可以使用collection.Counter(s)
frequency = collections.Counter(s) #按顺序计算字符次数
4.判断字符串
- 是否为数字 ----->str.isdigit()
- 是否为字母 ------>str.isalpha()
- 字母转换大小写------->str.upper() str.lower()
- 字符串也可以排序---->sorted(str) #默认排序后返回的是分开字符的列表,只有用join方法,可以将每个字符再连成一个
s="AfghwjbH"
s=s.upper() #转换为大写 AFGHWJBH
s=s.lower() #转换为小写 afghwjbh
print(s.isalpha()) #是否为字母串或者字母 True
print(s.isdigit()) #是否为数字 False
s1="AfghwjbH213"
print(s1.isalpha()) #是否为字母串或者字母 False--因为有数字
s2="232314"
print(s2.isdigit()) #是否为数字 True
ss="eat"
inf = sorted(ss) #['a', 'e', 't']
#默认排序后返回的是分开字符的列表,只有用join方法,可以将每个字符再连成一个
inff="".join(sorted(ss)) #aet
5.字符串匹配
字符串匹配最经典算法为KMP算法,几乎能解决大多数字符串匹配问题
KMP算法
- 前缀表
- 定义:一个字符串不包括最后一个字符的子串(例如:aabaaf的前缀为aabaa)
- 后缀表
- 定义:一个字符串不包括首字符的子串(例如:aabaaf的后缀为abaaf)
步骤:
-
①寻找前缀后缀最长公共元素长度
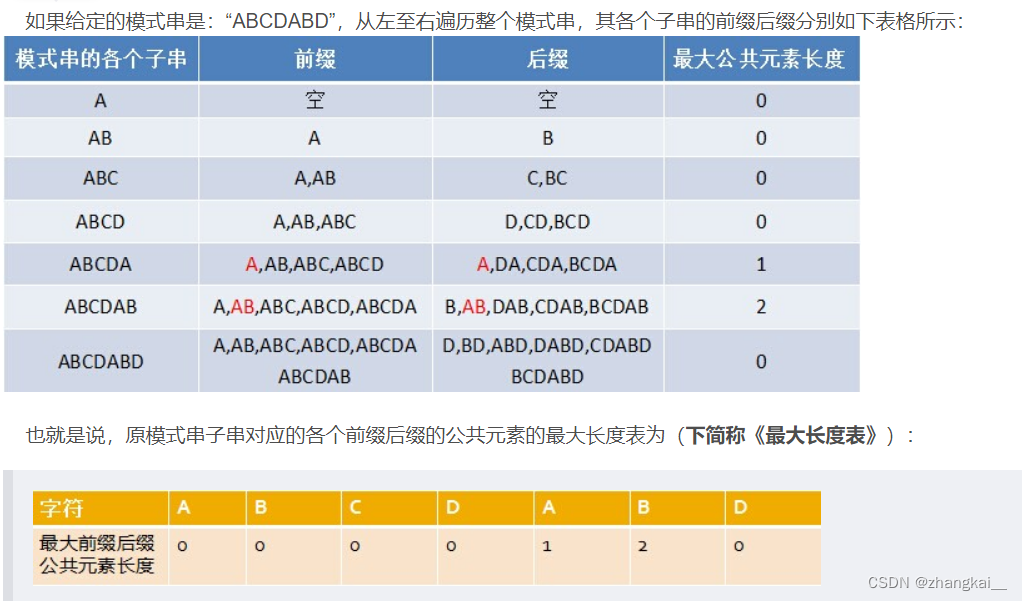
-
②求next数组
我们每次失配时,都是看的失配字符的上一位字符对应的最大长度值。
next 数组考虑的是除当前字符外的最长相同前缀后缀,所以通过第①步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第①步骤中求得的值整体右移一位,然后初值赋为-1,如下表格所示:
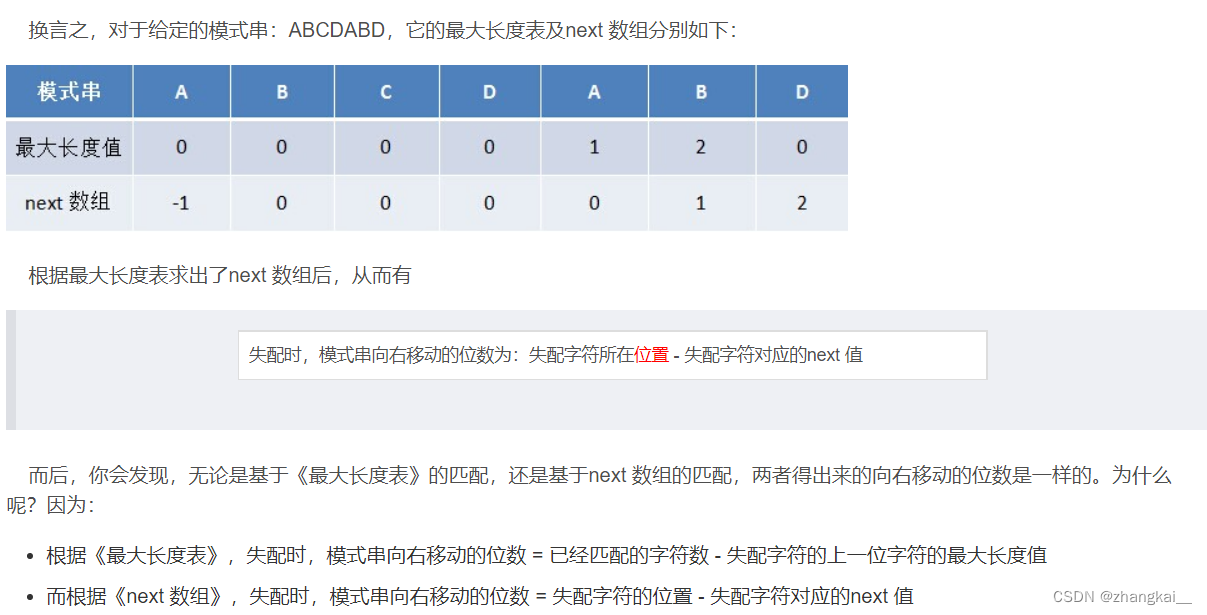
-
③根据next数组进行匹配
在正式匹配之前,让我们来再次回顾下上文2.1节所述的KMP算法的匹配流程:
“假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。”- 最开始匹配时
P[0]跟S[0]匹配失败
所以执行“如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]”,所以j = -1,故转而执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”,得到i = 1,j = 0,即P[0]继续跟S[1]匹配。
P[0]跟S[1]又失配,j再次等于-1,i、j继续自增,从而P[0]跟S[2]匹配。
P[0]跟S[2]失配后,P[0]又跟S[3]匹配。
P[0]跟S[3]再失配,直到P[0]跟S[4]匹配成功,开始执行此条指令的后半段:“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”。

2. P[1]跟S[5]匹配成功,P[2]跟S[6]也匹配成功, …,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next 值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j - next[j] = 6 - 2 =4 位。
-
向右移动4位后,P[2]处的C再次失配,由于C对应的next值为0,所以下一步用P[0]处的字符继续跟S[10]匹配,相当于向右移动:j - next[j] = 2 - 0 = 2 位。

-
移动两位之后,A 跟空格不匹配,模式串后移1 位。

-
P[6]处的D再次失配,因为P[6]对应的next值为2,故下一步用P[2]继续跟文本串匹配,相当于模式串向右移动 j - next[j] = 6 - 2 = 4 位。

-
匹配成功,过程结束。

- 最开始匹配时
实现代码如下:
class Solution:
# 获取next数组
def get_next(self, T):
i = 0 # 指向模式串的遍历指针
j = -1 # 最大前缀长度下标 相当于next数组的下标位置
next_val = [-1] * len(T)
while i < len(T)-1:
# 如果j==-1,说明最长前缀为0,需要从T[0]开始比较
if j == -1 or T[i] == T[j]: #如果T[i] == T[j]说明T[i]位置的字符和当前next数组指针指向的T数组位置相同
i += 1
j += 1
# next_val[i] = j #在相同后一个的位置改为指向next数组后一个的位置
print("true",next_val,i,j)
#if-else优化对比,效率更高
# 如果增加后的位置数值和next下标指向位置的值不相等了,那么它的next数组中的指针可以指向index---j的位置
if i < len(T) and T[i] != T[j]:
next_val[i] = j
#如果增加后的位置数值和next下标指向位置的值相等,那么即使这个位置与主串不相等而指向index位置的值,也必然不相等,
# 所以要指向index之前的的index;index前的index已经填入next中,直接使用即可(类似动态规划)
else:
next_val[i] = next_val[j]
else:
#如果不相同,则指向比较元素的next下标指的next下标,继续比较,直到找到,或者index=-1,重头开始
j = next_val[j]
print("false",next_val,i,j)
#优化后“AAAAB”的next数组[-1, -1, -1, -1, 3] 未优化[-1, 0, 1, 2, 3]
print(next_val)
return next_val
# KMP算法
def kmp(self, S, T):
i = 0
j = 0
next = self.get_next(T)
while i < len(S) and j < len(T):
# 如果j=-1说明从模式串头重新开始对比
if j == -1 or S[i] == T[j]:
i += 1
j += 1
else:
#不相等 模式串指针返回到最长前缀下标处继续对比,这里i,j不增加,为了重新对比主串和模式串
j = next[j]
if j == len(T):
print(i,j)
return i - j
else:
return -1
if __name__ == '__main__':
haystack = 'BBC ABCDAB ABCDABCDABDE'
#[0,0,0,0,1,2,2]最大长度表
#needle = 'ABCDABD'
needle = 'AACAB'
s = Solution()
print(s.kmp(haystack, needle)) # 输出 "5"
KMP算法讲解借鉴https://blog.csdn.net/v_JULY_v/article/details/7041827?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165986282016782388062203%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165986282016782388062203&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~hot_rank-2-7041827-null-null.142v39pc_rank_34_ctr0,185v2control&utm_term=KMP&spm=1018.2226.3001.4187