1、什么是递归SQL
递归 SQL(Recursive SQL)是一种 SQL 查询语言的扩展,它允许在查询中使用递归算法。递归 SQL 通常用于处理树形结构或层次结构数据,例如组织结构、产品分类、地理位置等。 递归 SQL 语句通常包含两个部分:递归部分和终止部分
递归部分定义了如何从一个节点到达下一个节点,而终止部分定义了递归何时结束。递归 SQL 语句通常使用 WITH RECURSIVE 关键字来定义
优点:在于它可以处理复杂的层次结构数据,而不需要编写复杂的程序或使用循环语句
缺点:存在性能、内存、可读性和数据一致性(多线程或分布式情况下)等问题
2、递归SQL的基本用法
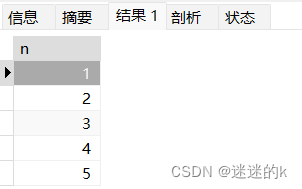
例:创建一个递归主表 t1 ,由初始值1 开始,输出小于5的正整数
SQL如下:
with recursive t1 as(
select 1 as n #从1开始,相当于初始值
UNION ALL #将初始条件与终止条件连接
select n+1 from t1 where n<5 #递归语句终止条件
)
select * from t1;输出结果:
3、案例演示
【前端】需要传入的部分参数样式:
JSON
[
{
"childrenTreeNodes" : [
{
"childrenTreeNodes" : null,
"id" : "1-1-1",
"isLeaf" : null,
"isShow" : null,
"label" : "HTML/CSS",
"name" : "HTML/CSS",
"orderby" : 1,
"parentid" : "1-1"
},
{
"childrenTreeNodes" : null,
"id" : "1-1-2",
"isLeaf" : null,
"isShow" : null,
"label" : "JavaScript",
"name" : "JavaScript",
"orderby" : 2,
"parentid" : "1-1"
},
{
"childrenTreeNodes" : null,
"id" : "1-1-6",
"isLeaf" : null,
"isShow" : null,
"label" : "ReactJS",
"name" : "ReactJS",
"orderby" : 6,
"parentid" : "1-1"
},
{
"childrenTreeNodes" : null,
"id" : "1-1-7",
"isLeaf" : null,
"isShow" : null,
"label" : "Bootstrap",
"name" : "Bootstrap",
"orderby" : 7,
"parentid" : "1-1"
},
{
"childrenTreeNodes" : null,
"id" : "1-1-10",
"isLeaf" : null,
"isShow" : null,
"label" : "其它",
"name" : "其它",
"orderby" : 10,
"parentid" : "1-1"
}
],
"id" : "1-1",
"isLeaf" : null,
"isShow" : null,
"label" : "前端开发",
"name" : "前端开发",
"orderby" : 1,
"parentid" : "1"
},
{
"childrenTreeNodes" : [
{
"childrenTreeNodes" : null,
"id" : "1-2-1",
"isLeaf" : null,
"isShow" : null,
"label" : "微信开发",
"name" : "微信开发",
"orderby" : 1,
"parentid" : "1-2"
},
{
"childrenTreeNodes" : null,
"id" : "1-2-2",
"isLeaf" : null,
"isShow" : null,
"label" : "iOS",
"name" : "iOS",
"orderby" : 2,
"parentid" : "1-2"
},
{
"childrenTreeNodes" : null,
"id" : "1-2-3",
"isLeaf" : null,
"isShow" : null,
"label" : "手游开发",
"name" : "手游开发",
"orderby" : 3,
"parentid" : "1-2"
},
{
"childrenTreeNodes" : null,
"id" : "1-2-7",
"isLeaf" : null,
"isShow" : null,
"label" : "Cordova",
"name" : "Cordova",
"orderby" : 7,
"parentid" : "1-2"
},
{
"childrenTreeNodes" : null,
"id" : "1-2-8",
"isLeaf" : null,
"isShow" : null,
"label" : "其它",
"name" : "其它",
"orderby" : 8,
"parentid" : "1-2"
}
],
"id" : "1-2",
"isLeaf" : null,
"isShow" : null,
"label" : "移动开发",
"name" : "移动开发",
"orderby" : 2,
"parentid" : "1"
}
]对应的【数据库】course_category表 信息(这里只截取一部分):
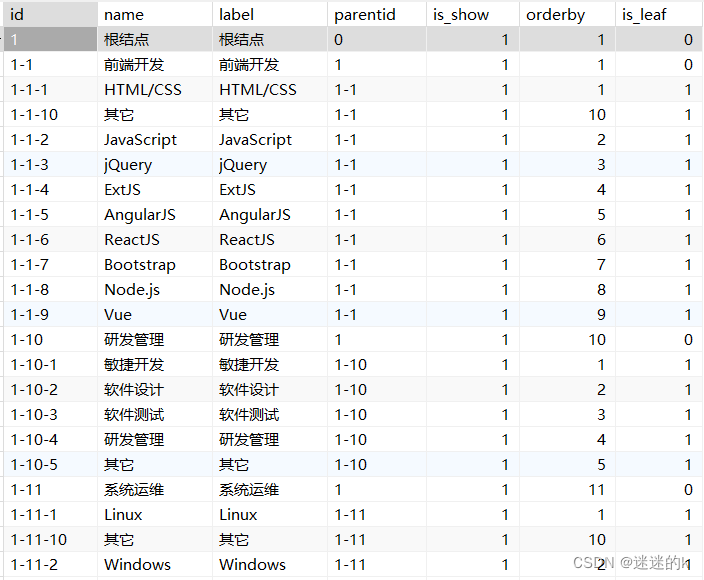
这里,从数据库中的字段信息中可以看出,Id 与 parentId 是相关联的,所以需要采取自连接;但是,若级数多的情况下,使用平时的表自连接将会使SQL代码变得复杂且冗长,所以这里根据场景,使用SQL递归来进行多级信息的查询
SQL实现:
with recursive t1 as(
select * from course_category where id = '1' #初始值从根节点1开始
union all #将初始条件与终止条件连接
select t2.* from course_category t2 inner join t1 #然后采取自连接进行递归操作
on t2.parentid = t1.id
)
select * from t1
ORDER BY t1.id代码实现:
【DTO】在主类的基础上,创建子节点(主类属性这里省略):
@Data
public class CourseCategoryTreeDto extends CourseCategory implements Serializable {
private List<CourseCategoryTreeDto> childrenTreeNodes; //子节点
}【Mybatis】创建查询:
<!--这里进行 【递归查询】,以查出树形分类表信息-->
<select id="selectTreeNodes" parameterType="string" resultType="MyPro.Dto.CourseCategoryTreeDto">
with recursive t1 as(
select * from course_category where id = #{id}
union all
select t2.* from course_category t2 inner join t1
on t2.parentid = t1.id
)
select * from t1
ORDER BY t1.id
</select>【Service】进行树形结构的转换:
public List<CourseCategoryTreeDto> queryTreeNodes(String id) {
//1.查询分类信息【这里调用的就是上面的 SQL 代码】
List<CourseCategoryTreeDto> courseCategoryTreeDtos = courseCategoryMapper.selectTreeNodes(id);
//2.由于前端接口的需求,封装为 DTO 对象
//2.1先将 list 对象转为 map,更方便的进行获取节点
Map<String, CourseCategoryTreeDto> categoryTreeDtoMap = courseCategoryTreeDtos.stream()
//2.1.1 由于前端需要的结果集中,根节点不需要,这里将根节点过滤
.filter(new Predicate<CourseCategoryTreeDto>() {
@Override
public boolean test(CourseCategoryTreeDto courseCategoryTreeDto) {
//2.1.2 只保留符合条件,不符合的则进行过滤
return !courseCategoryTreeDto.getId().equals(id); //该方法传入的 id 即是根节点 id
}
})
.collect(Collectors.toMap(
courseCategoryTreeDto -> courseCategoryTreeDto.getId(),
courseCategoryTreeDto -> courseCategoryTreeDto
));
//2.2 将上面的 map 集合转换为 tree 树形结构
ArrayList<CourseCategoryTreeDto> treeDtoArtrayList = new ArrayList<>();
courseCategoryTreeDtos.stream()
.filter(new Predicate<CourseCategoryTreeDto>() {
@Override
public boolean test(CourseCategoryTreeDto courseCategoryTreeDto) {
return !courseCategoryTreeDto.getId().equals(id); //过滤根节点
}
})
.forEach(new Consumer<CourseCategoryTreeDto>() {
@Override
public void accept(CourseCategoryTreeDto courseCategoryTreeDto) {
//2.2.1 先将一级子节点存入 list 集合中
if(courseCategoryTreeDto.getParentid().equals(id)) { //若该节点的父节点等于根节点1(即一级子节点)则进行存储
treeDtoArtrayList.add(courseCategoryTreeDto);
}
//2.2.2 获取各个节点的父节点,以用来存放对应子节点信息
CourseCategoryTreeDto courseCategoryParent = categoryTreeDtoMap.get(courseCategoryTreeDto.getParentid());
if(courseCategoryParent !=null){ //父节点存在
if(courseCategoryParent .getChildrenTreeNodes()==null){ //若子节点为空,则创建一个 【懒加载】
courseCategoryParent.setChildrenTreeNodes(new ArrayList<>());
}
//2.2.3 将各个子节点放入各个对应父节点中
courseCategoryParent.getChildrenTreeNodes().add(courseCategoryTreeDto);
}
}
});
return treeDtoArtrayList;
}上面方法的调用:
【Controller】这里传入的 id 是根节点 1
@RestController
public class CourseCategoryController {
@Resource
private CourseCategoryService categoryService;
@GetMapping(value = "/course-category/tree-nodes")
public List<CourseCategoryTreeDto> queryTreeNodes(){
return categoryService.queryTreeNodes("1");
}
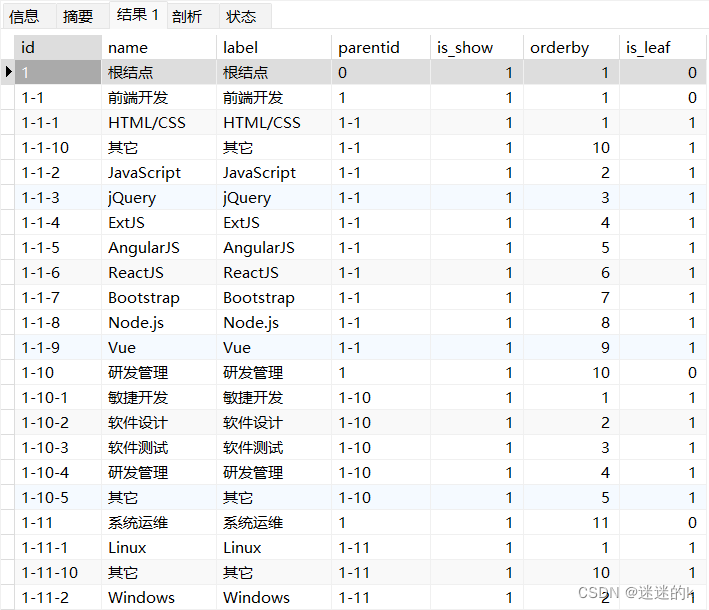
}查询结果:
可见,SQL得出的结果与数据库中的一致,查询成功 o(* ̄▽ ̄*)ブ,然后再使用 Service 层进行树形参数的封装,返回给前端即可
页面效果:

4、使用递归 SQL 的注意事项
- 递归 SQL 的性能较差,因此在处理大量数据时需要谨慎使用
- 递归 SQL 的语法较为复杂,需要仔细理解和掌握
- 需要设置递归终止条件,否则可能会导致死循环
- 递归 SQL 中的查询语句需要谨慎设计,避免出现重复数据或者数据丢失的情况
- 需要注意数据库的版本和配置,不同的数据库可能会有不同的限制和特性
- 需要注意数据的完整性和一致性,避免出现数据错误或者不一致的情况
- 需要注意数据的安全性,避免出现数据泄露或者数据被篡改的情况