在hibernate中我们使用注解,可以帮助我们简化hbm文件配置。
PO类注解配置
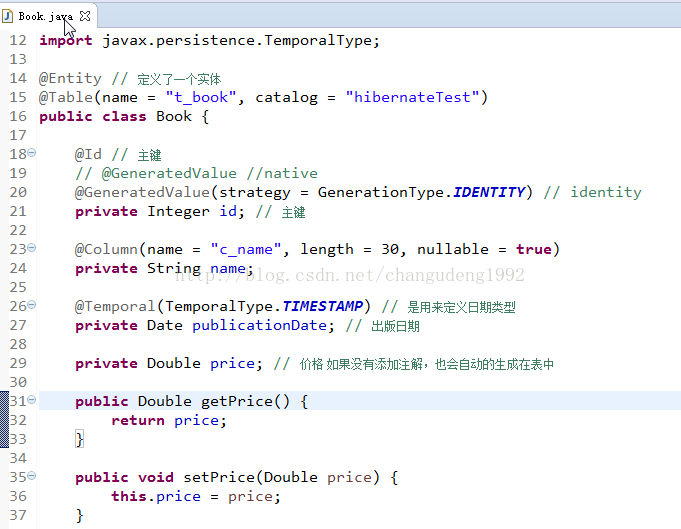
@Entity 声明一个实体
@Table来描述类与表对应

@GenerateValue 用它来声明一个主键生成策略

默认情况下相当于native
使用注解的方式来配置UUID的生成策略,需要先使用@GenericGenerator定义一个UUID的生成器,然后使用@GeneratedValue来引用它
可以选择的主键生成策略 AUTO IDENTITY SEQUENCE
@Column来定义列

注意:对于PO类中所有属性,如果你不写注解,默认情况下也会在表中生成对应的列。
列的名称就是属性的名称
@Temporal来声明日期类型

可以选择
TemporalType.DATA 只有年月日
TemporalType.TIME 只有小时分钟秒
TemporalType.TIMESTAMP 有年月日小时分钟秒
我们最终需要在hibernate.cfg.xml文件中将我们类中的注解配置引用生效

测试的注解开发的代码:

问题:1.如果我们主键生成策略想使用UUID类型?
首先生成一个叫myuuid的uuid主键生成策略, 然后再引用这个策略;

问题2:如果设定类的属性不在表中映射?

对于我们以上讲解的关于属性配置的注解,我们也可以在其对应的getXxx方法去使用
编写domain类:

在核心配置文件中配置映射:

测试uuid主键生成策略以及不生成表中映射:

一对多(多对一)
@OneToMany
@ManyToOne
以Customer与Order为例
targetEntity:配置要关联的实体类名。它可以省略。
mappedBy:和inverse很像。其实就是表示外键由另外一方来维护。这个mappedBy是配置的关联类的哪一个属性来维护外键。所以这个Customer中的,@OneToMany的mapperBy属性配置的是Order类中的customer。
@Cascade:这个是使用的是Hibernate中的注解,所以我们需要引入Hibernate中的数据类型。
在多的一方,有一个@JoinColumn,它主要就是配置关联的外键,所以它的值配置为外键的名词。
Customer类

Order类

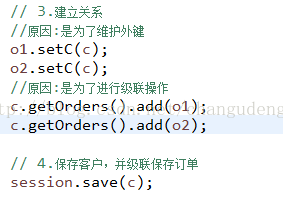
示例:保存客户时,保存订单
对于这个示例我们需要在Customer中配置cascade操作,save-update
第一种方式,可以使用JPA提供的注解

第二种方式:可以使用hibernate提供的注解

配置核心配置文件中的映射;

以下是示例代码

执行后的结果

订单中没有关联客户的id,为什么?
原因:我们在Customer中配置了mappedBy=”c”它代表的是外键的维护由Order方来维护,而Customer不维护,这时你在保存客户时,级联保存订单,是可以的,但是不能维护外键,所以,我们必须在代码中添加订单与客户关系。
扩展:关于hibernate注解@Cascade中的DELETE_ORPHAN过时

使用下面方案来替换过时方案

总结:对于API中过时的操作,查看对应的源码其中会有提示应该用什么办法去替代
Hibernate关联映射-多对多
我们使用注解完成多对多配置.
描述学生与老师.
使用@ManyToMany来配置多对多,只需要在一端配置中间表,另一端使用mappedBy表示放置外键维护权。
找谁,怎么找?
@ManyToMany要通过一个中间表(使用@JoinTable来指定中间表的表名)来找。首先找自己,再找别人。
通过配置joinColumn来找到中间表中与StudentID对应的列,再配置inverseJoinColumn来找到中间表中与Teach ID对应的列。
创建PO类
Teacher类中

Student类中

级联保存操作测试
因为我们将外键的维护权利由Student来维护,我们演示保存学生时,将都也级联保存。
核心配置文件中添加映射:


我们在Student类中配置了级联

级联删除操作测试

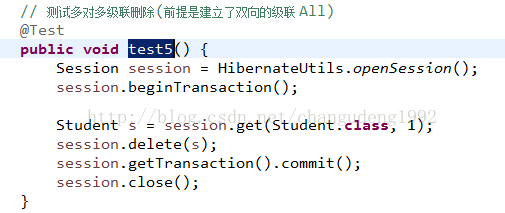
注意:要谨慎配置双方的级联删除。
在实际项目开发过程中,要谨慎的去使用删除数据功能。会将删除功能实现为隐藏,添加一个表示状态的字段。删除只是在前端不展示这个数据,数据库中并不直接将数据删除。
Hibernate关联映射-一对一
以人与身份证号为例
一对一操作有两种映射方式:
1. 在任意一方添加外键
2. 主键映射
外键映射
创建实体
User类

IDCard类
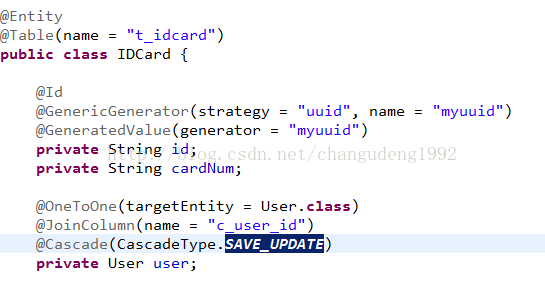
joinColumn指定外键列名称,当前配置外键是在t_idcard表中
cfg.xml文件中添加映射文件

测试代码

主键映射(了解)
以Husband与Wife为例

@PrimaryKeyJoinColumn 说明husband与wife是使用主键映射
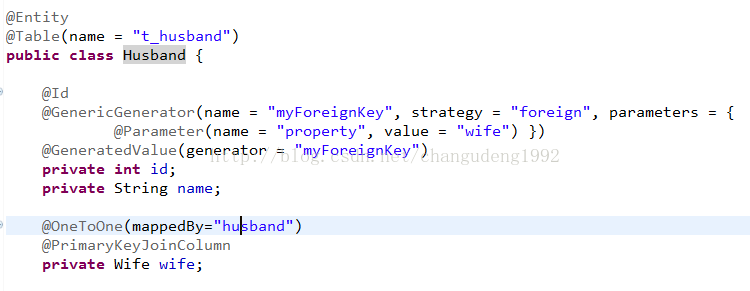
Husband的主键我们设置成参考wife的主键方式
记得在cfg.xml中配置映射:


Hibernate检索方式概述
对数据库操作中,最常用的是select.使用hibernate如何select操作。
分为五种:
1导航对象图检索方式,根据已加载的对象导航到其它对象
2.OID检索方式,按照对象的OID来检索对象
3.HQL检索方式,使用面向对象的HQL查询语言
4.QBC检索方式,使用QBC(Queryby Criteria)API来检索对象,这种API封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口
5.本地SQL检索方式,使用本地数据库的SQL查询语句
导航对象图检索方式
Customerc=session.get(Customer.class,2);
c.getOrders().size()
通过在hibernate中进行映射关系,在hibernate操作时,可以通过导航方式得到
其关联的持久化对象信息。
OID检索方式
Session.get(Customer.class,3);
Session.load(Order.class,1);
Hibernate中通过get/load方法查询指定的对象,要通过OID来查询。
HQL检索方式
HQL是我们在hibernate中是常用的一种检索方式。
HQL(Hibernate QueryLanguage)提供更加丰富灵活、更为强大的查询能力
因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装。完整的HQL语句形式如下: Select/update/delete…… from …… where …… group by …… having …… orderby …… asc/desc 其中的update/delete为Hibernate3中所新添加的功能,可见HQL查询非常类似于标准SQL查询。
基本步骤:
1. 得到Session
2. 编写HQL语句
3. 通过session.createQuery(hql)创建一个Query对象
4. 为Query对象设置条件参数
5. 执行list查询所有,它返回的是List集合 uniqueResut()返回一个查询结果。
编写代码的时候要注意代码的格式:
静态测试工具(扫描代码格式、统计代码复杂度)
缩进,使用TAB键来进行缩进(往前缩进SHIFT+TAB),保持代码的层次感
回车换行:要保持代码的逻辑层次,用回车来分层次
一行最好不要超过200个字符
《写给大家看的设计书》——对比、重复、对齐
数据准备
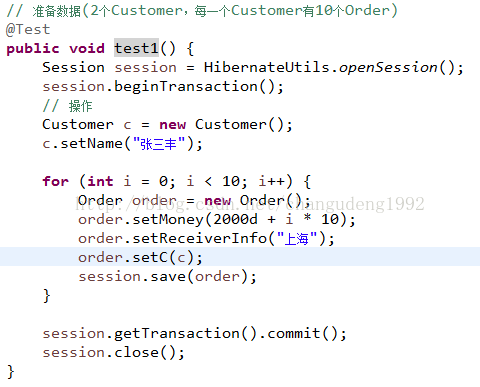
基本检索
From 类名;

排序检索
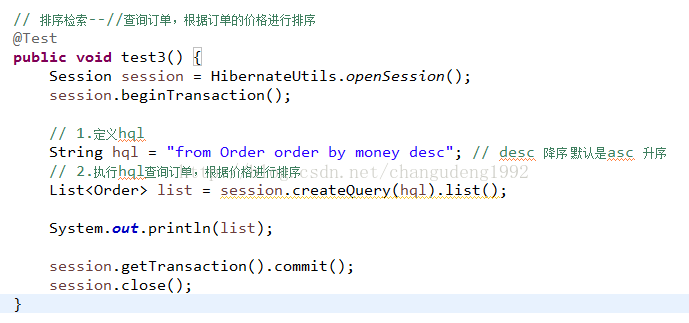
需要注意的问题:Customer和Order中都重写toString方法,因为二者相互打印对方的信息所以会导致死循环, 因此我们要注意,在一方的toString方法中要删除掉打印对方对象的部分.
条件检索
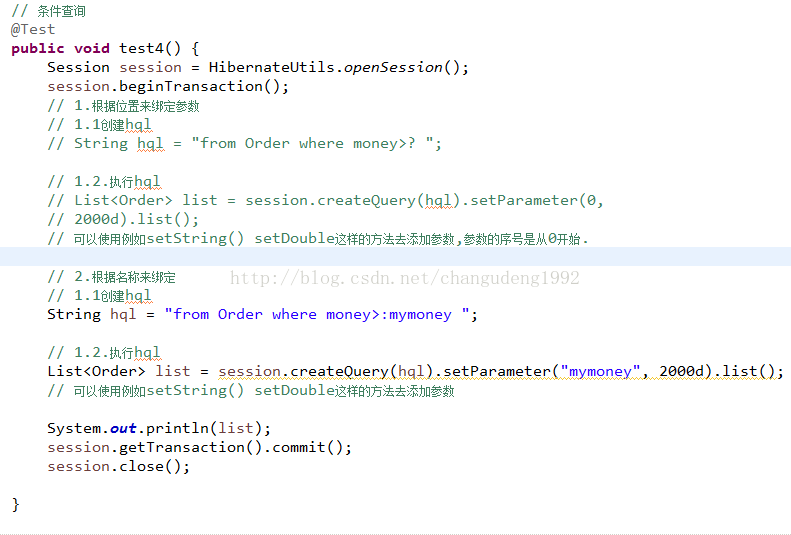
分页检索

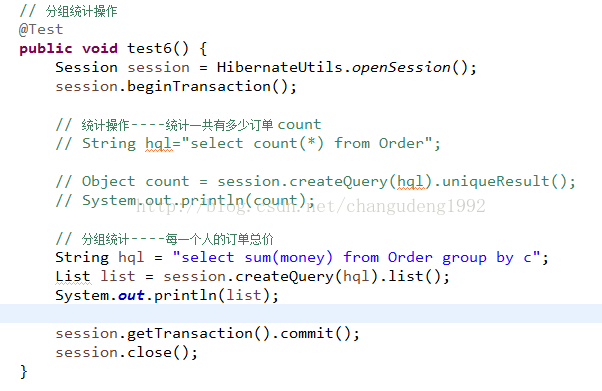
分组统计检索
group by name1,name2,根据哪些字段来进行分组
聚合函数(avg、sum、count)
注意:group by 后边的字段要写成实体中的属性名称,不要写成表的列名。
投影检索
我们主要讲解是关于部分属性查询,可以使用投影将部分属性封装到对象中。
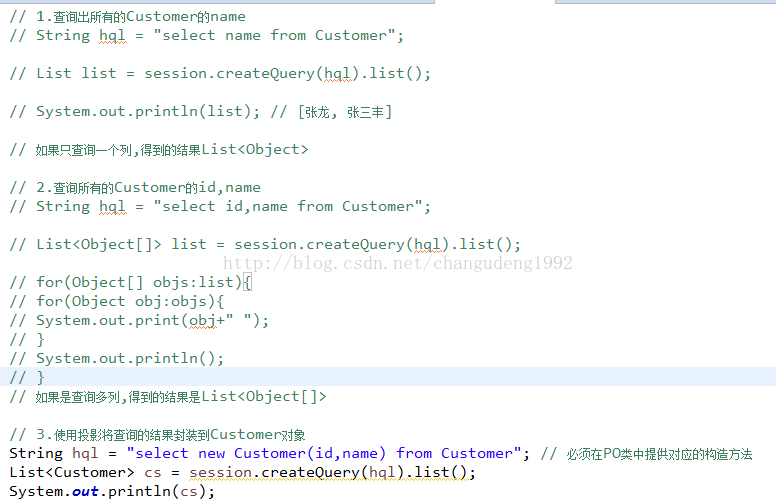
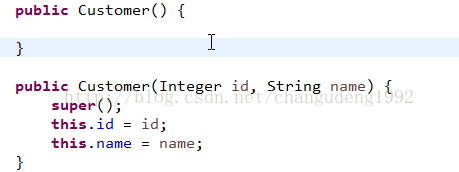
注意:我们必须在PO类中提供对应属性的构造方法,也要有无参数构造。
命名检索
我们可以将hql语句先定义出来,在使用时通过session.getNamedQuery(hqlName);得到一个Query,在执行.
问题:hql定义在什么位置?
1.如果你有XXX.hbm.xml配置文件,那么当前的hql操作是对哪一个实体进行操作,就在哪一个实体的配置文件中声明。

2.如果是使用注解来描述PO的配置
我们直接在PO类中使用

如何使用?



总结:HQL是完全面向对象的, 操作过程中要从sql语句的思想中解放出来,现在可以操作的都是对象.
应用场景: 当在开发过程中,如果写了很多重复的SQL,就可以考虑将这些重复的SQL放在注解(或者XML映射文件)中。
Ø 高内聚、低耦合
单一职责(少管闲事),一个类只做自己相关的事
OrderService:编写的都是与订单相关的代码(方法)
CustomerService:编写的都是与客户相关的代码(方法)
QBC
QBC(query by criteria),它是一种更加面向对象的检索方式。
QBC步骤:
1.通过Session得到一个Criteria对象 session.createCriteria()
2.设定条件 Criterion实例它的获取可以通过Restrictions类提供静态。
Criteria的add方法用于添加查询条件
1. 调用list进行查询 criteria.list.
基本检索

Ø 表驱动编程法(Table-Driven)
if(param==1){
month = "一月";
}
else if(flag ==2){
month = "二月";
}
else if(flag ==3){
month = "三月";
}
else if(flag ==4){
month = "四月";
}
else if(flag ==5){
month = "五月";
}
else ...
String[] monthTable={"一月","二月","三月","四月","五月"...};
month = monthTable[param];
Map<String, String> monthMap=new HashMap<String, String>();
monthMap.put("1","一月");
monthMap.put("2","二月");
monthMap.put("3","三月");
Map<String, String> monthMap=new HashMap<String, String>();
monthMap.put("1","method1");
monthMap.put("2","method2");
monthMap.put("3","method3");
month = monthMap.get(param);
Method m = object.getClass().getMethod(monthMap[param], Object.class);
排序检索
@Test
public void randOrderTest(){
//排序检索
Sessionsession = HibernateUtils.getSession();
session.beginTransaction();
//要注意此时的Order是自建Order类.
Criteriacriteria =session.createCriteria(oneToMany.Order.class);
//此时的Order.asc是Hibernate中的Order类
criteria.addOrder(Order.asc("money"));
List<Order>list =criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}

注意在criteri.addOrder()方法的参数使用的Order是hibernate中的类,而不是我们自己建的Order类 , 因为上面的Order.class的时候导入的是我们自己建的Order类,所以下面使用hibernate中的order类的时候自动填入它的全名.
我的错题:此处注意自己建的类名与工具的自带类名相同时的区分与辨别,不仔细很容易出错而且难以排查.
条件检索


注意:首先要明确uniqueResult()方法适用的是结果是唯一的情形,但是此时我的数据库中的张三丰和张四风都是三个字的名字,所以是两个结果,必须用criteria.list();才能正确得出结果.还要注意的是下划线表示一个占位符,任意个数统配符是%,.这个问题耽误我1个小时.
分页检索

统计分组检索
Count sum avg max min
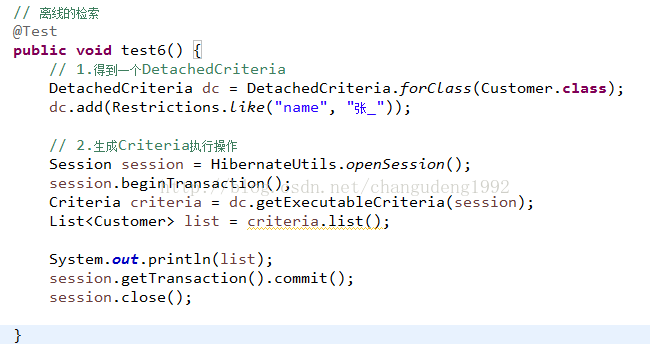
离线条件检索
可以在没有Session的情况下去创建一个DetachedCriteria(用法与Criteria一样) , 例如 , 可以在web层去拼接