方案
调整这几个参数来调大nginx的超时时间。
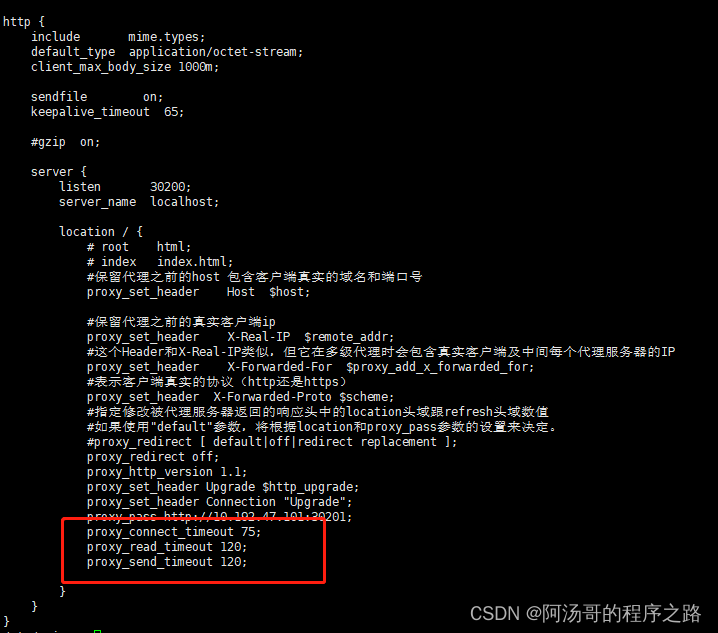
proxy_connect_timeout
proxy_send_timeout
proxy_read_timeout
nginx 三个代理超时时间配置
proxy_connect_timeout 60s;
Defines a timeout for establishing a connection with a proxied server. It should be noted that this timeout cannot usually exceed 75seconds.
定义与被代理服务器建立连接的超时时间。请注意,此超时通常不能超过75秒。
proxy_send_timeout dedault 60s
Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
设置将请求传输到被代理服务器的超时时间。只在两个连续的写操作之间设置超时,而不是整个请求的传输。如果代理服务器在这段时间内没有收到数据,连接将被关闭。
proxy_read_timeout default 60s
Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
定义从被代理服务器读取响应的超时。超时设置仅在两个连续的读取操作之间,而不是整个响应的传输。如果代理服务器在这段时间内没有传输数据,连接将被关闭。
为什么不建议调大proxy_connect_timeout
- 生产环境中nginx和后端服务器一般是走内网通讯,正常情况下建链时间本来就不应该太长
- nginx开启的被动健康检查,过长的proxy_connect_timeout 会严重影响被动健康检查的效果
nginx的被动健康检查 (阅)
upstream upcheck { server 127.0.0.1:8000 max_fails=1 fail_timeout=10s ; } 这个一个默认的nginx被动健康检查的配置max_fails=1 fail_timeout=10s
这段的大致意思是10s内,这个节点的请求失败数超过1则会将其标记为down,下个10s内不会有新的请求到达该节点。详细的介绍大家可以去官网或者论坛去搜索,这里不再赘述。下面我着重讲一下proxy_conncet_timeout对他的影响。被动健康检查一个常见的场景就是当后端有台服务器宕机的时候,如果proxy_connect_timeout
设置为5s,5s后nginx和后端建链超时,该条请求被标记为失败,该节点被置为down。这样可以在一定程度上做到快速止损。而假如我们将proxy_connect_timeout
设置为60s,所有到达该节点的请求60s后才会因为超时剔除宕机节点。下面我做一个简单的实验来对比一下宕机情况下proxy_connect_timeout设置为5s和60s的区别
两组upstream都为2个节点,采用默认被动健康检查配置(max_fails=1
fail_timeout=10s),其中一个节点不可用(ping不通),关闭nginx重试,每秒请求一次,持续10分钟
nginx配置
server {
listen 80;
server_name _ ;
access_log /opt/log/ngx-lan_access.log main;
location = /upcheck {
proxy_next_upstream_tries 1;
proxy_connect_timeout 5s;
proxy_pass http://upcheck;
}
location = /upcheck2 {
proxy_next_upstream_tries 1;
proxy_connect_timeout 60s;
proxy_pass http://upcheck2;
}
upstream upcheck {
server 127.0.0.1:8500 max_fails=1 fail_timeout=10s ;
server 192.168.100.100:8500 max_fails=1 fail_timeout=10s ;
}
upstream upcheck2 {
server 127.0.0.1:8500 max_fails=1 fail_timeout=10s ;
server 192.168.100.100:8500 max_fails=1 fail_timeout=10s ;
}
}
用curl访问
for i in {
1..600}; do curl http://127.0.0.1/upcheck -I > /dev/null 2>&1 & sleep 1; done
for i in {
1..600}; do curl http://127.0.0.1/upcheck2 -I > /dev/null 2>&1 & sleep 1; done
然后统计一下这两组配置的200状态码
5s的这组 200状态码个数是 558
60s的这组 200状态码个数是 468