GNU C特殊语法部分详解
一、指定初始化
1、数组初始化
在C语言标准中,当我们定义并初始化一个数组时,常用方法如下。
int a[10] = {
0,1,2,3,4,5,6,7,8};
当数组比较大,而且数组里的非零元素并不连续时,再按照固定顺序初始化就比较麻烦了。C99标准改进了数组的初始化方式,支持指定元素初始化。通过数组元素索引,我们可以直接给指定的数组元素赋值。
int b[100] = {
[10] = 1, [30] = 2};
如果我们想给数组中某一个索引范围的数组元素初始化,可以采用下面的方式。我们使用[10…30]表示一个索引范围,相当于给a[10]到a[30]之间的20个数组元素赋值为1。
int b[100] = {
[10...30] = 1,[50...60] = 2};
GNU C支持使用...表示范围扩展,这个特性不仅可以使用在数组初始化中,也可以使用在switch-case语句中,如下面的程序。

在这个程序中,如果当case值为2~8时,都执行相同的case分支,我们就可以通过case 2 ... 8:的形式来简化代码。这里同样有一个细节需要注意,就是...和其两端的数据范围2和8之间也要有空格,不能写成2...8的形式,否则会报编译错误。
2、指定初始化结构体成员
和数组类似,在C语言标准中,初始化结构体变量也要按照固定的顺序,但在GNU C中我们可以通过结构域来指定初始化某个成员。如下程序所示。

初始化stu2时,我们采用GNU C的初始化方式,通过结构域名.name和.age,就可以给结构体变量的某一个指定成员直接赋值。当结构体的成员很多时,使用第二种初始化方式会更加方便。
3、指定初始化的好处
指定初始化不仅使用灵活,而且还有一个好处,就是代码易于维护。如果采用C标准按照固定顺序赋值,当file_operations结构体类型发生变化时,如添加了一个成员、删除了一个成员、调整了成员顺序,那么使用该结构体类型定义变量的大量C文件都需要重新调整初始化顺序,牵一发而动全身。
我们通过指定初始化方式,就可以避免这个问题。无论file_operations结构体类型如何变化,添加成员也好、删除成员也好、调整成员顺序也好,都不会影响其他文件的使用。
二、宏构造利器:语句表达式
1、表达式、语句和代码块
表达式和语句是C语言中的基础概念。什么是表达式呢?表达式就是由一系列操作符和操作数构成的式子。操作符可以是C语言标准规定的各种算术运算符、逻辑运算符、赋值运算符、比较运算符。操作数可以是一个常量,也可以是一个变量。表达式也可以没有操作符,单独的一个常量甚至一个字符串,都是一个表达式。下面的字符序列都是表达式。
2 + 3
2
i = 2 + 3
i = i++ + 3
"关注Owl City 点赞收藏不迷路"
表达式一般用来计算数据或实现某种功能的算法。表达式有两个基本属性:值和类型。
表达式可以分为多种类型,具体如下。
- 关系表达式
- 逻辑表达式
- 条件表达式
- 赋值表达式
- 算术表达式
值得注意的是,不同的语句,使用大括号{}括起来,就构成了一个代码块。C语言允许在代码块内定义一个变量,这个变量的作用域也仅限于这个代码块内,因为编译器就是根据{}来管理变量的作用域的,如下面的程序。

程序运行结果如下。


2、语句表达式
GNU C对C语言标准作了扩展,允许在一个表达式里内嵌语句,允许在表达式内部使用局部变量、for循环和goto跳转语句。这种类型的表达式,我们称为语句表达式。

语句表达式最外面使用小括号()括起来,里面一对大括号{}包起来的是代码块,代码块里允许内嵌各种语句。语句的格式可以是一般表达式,也可以是循环、跳转语句。
语句表达式的值为内嵌语句中最后一个表达式的值。我们举个程序示例

在上面的程序中,通过语句表达式实现了从1到10的累加求和,因为语句表达式的值等于最后一个表达式的值,所以在for循环的后面,我们要添加一个s;语句表示整个语句表达式的值。如果不加这一句,你会发现sum=0。或者你将这一行语句改为100;,你会发现最后sum的值就变成了100,这是因为语句表达式的值总等于最后一个表达式的值。
3、宏定义中的语句表达式
语句表达式的主要用途在于定义功能复杂的宏。使用语句表达式来定义宏,不仅可以实现复杂的功能,还能避免宏定义带来的歧义和漏洞。
提出一个问题:请定义一个宏,求两个数的最大值。
入门级写法
#define MAX(x,y) x > y ? x : y
这是一个很基础的写法,但是存在问题,在实际使用中,会因为运算符优先级问题使得输出结果不符合预期。做如下测试。

测试第4行语句,当宏的参数是一个表达式,发现实际运行结果为max=0,和我们预期结果max=1不一样。这是因为,宏展开后,变成如下样子。

因为比较运算符>的优先级为6,大于!=(优先级为7),所以在展开的表达式中,运算顺序发生了改变,结果就和预期不一样了。
中等级写法
为了避免上面展开错误,我们可以给宏的参数加一个小括号(),防止展开后表达式的运算顺序发生变化。
#define MAX(x,y) (x) > (y) ? (x) : (y)
使用小括号将宏定义包起来,这样就避免了当一个表达式同时含有宏定义和其他高优先级运算符时,破坏整个表达式的运算顺序。
良好级写法
中等级写法的宏,虽然解决了运算符优先级带来的问题,但是仍存在一定的漏洞。例如,我们使用下面的代码来测试我们定义的宏。
在程序中,我们定义两个变量i和j,然后比较两个变量的大小,并作自增运算。实际运行结果发现max=7,而不是预期结果max=6。这是因为变量i和j在宏展开后,做了两次自增运算,导致打印出的i值为7。
这时候,语句表达式就该上场了。我们可以使用语句表达式来定义这个宏,在语句表达式中定义两个临时变量,分别来暂时存储i和j的值,然后使用临时变量进行比较,这样就避免了两次自增、自减问题。
#define MAX(x,y) ({
\
int _x = y; \
int _y = y; \
_x > _y ? _x : _y; \
})
在上述语句表达式中,我们定义了2个局部变量_x、_y来存储宏参数x和y的值,然后使用_x和_y来比较大小,这样就避免了i和j带来的2次自增运算问题。
优秀级写法
在良好级这个宏中,我们定义的两个临时变量数据类型是int型,只能比较两个整型数据。那么对于其他类型的数据,就需要重新定义一个宏了,这样太麻烦了!我们可以基于上面的宏继续修改,让它可以支持任意类型的数据比较大小。
#define MAX(type,x,y) ({
\
type _x = y; \
type _y = y; \
_x > _y ? _x : _y; \
})
在上述宏中,我们添加一个参数type,用来指定临时变量_x和_y的类型。这样,我们在比较两个数的大小时,只要将2个数据的类型作为参数传给宏,就可以比较任意类型的数据了。
顶级优化写法
在优秀级的宏定义中,我们增加了一个type类型参数,来适配不同的数据类型。此时此刻,为了薪水,我们应该尝试进一步优化,把这个参数也省去。该如何做到呢?使用typeof就可以了,typeof是GNU C新增的一个关键字,用来获取数据类型,我们不用传参进去,让typeof直接获取!
#define MAX(x,y) ({
\
typeof(x) _x = y; \
typeof(y) _y = y; \
(void) (&_x == &_y); \
_x > _y ? _x : _y; \
})
在上面的宏定义中,我们使用了typeof关键字来自动获取宏的两个参数类型。比较难理解的是(void)(&x==&y);这句话,看起来很多余,仔细分析一下,你会发现这条语句很有意思。它的作用有两个:
- 一是用来给用户提示一个警告,对于不同类型的指针比较,编译器会发出一个警告,提示两种数据的类型不同。

- 二是两个数进行比较运算,运算的结果却没有用到,有些编译器可能会给出一个warning,加一个(void)后,就可以消除这个警告。
三、typeof 与container_of 宏
1、typeof 关键字宏
GNU C扩展了一个关键字typeof,用来获取一个变量或表达式的类型。typeof的参数有两种形式:表达式或类型。

上面的代码中,因为变量i的类型为int,所以typeof(i)就等于int,typeof(i) j=20就相当于int j=20,typeof(int*) a;相当于int*a,f()函数的返回值类型是int,所以typeof(f()) k;就相当于int k;。
typeof的高级用法。

2、Linux内核中的container_of 宏
分析Linux内核第一宏:container_of了。这个宏在Linux内核中应用甚广。

作为内核第一宏,它包含了GNU C编译器扩展特性的综合运用,宏中有宏,有时候不得不佩服内核开发者如此犀利的设计。
它的主要作用就是,根据结构体某一成员的地址,获取这个结构体的首地址。根据宏定义,我们可以看到,这个宏有三个参数:type为结构体类型,member为结构体内的成员,ptr为结构体内成员member的地址。也就是说,如果我们知道了一个结构体的类型和结构体内某一成员的地址,就可以获得这个结构体的首地址。container_of宏返回的就是这个结构体的首地址。
应用场景:在内核中,我们经常会遇到这种情况:我们传给某个函数的参数是某个结构体的成员变量,在这个函数中,可能还会用到此结构体的其他成员变量,那么该怎么操作呢?container_of就是干这个的,通过它,我们可以首先找到结构体的首地址,然后通过结构体的成员访问就可以访问其他成员变量了。

在这个程序中,我们定义一个结构体变量stu,知道了它的成员变量math的地址:&stu.math,就可以通过container_of宏直接获得stu结构体变量的首地址,然后就可以访问stu变量的其他成员stup->age和stup->num。
3、Linux内核中的container_of 宏实现分析
一个结构体数据类型,在同一个编译环境下,各个成员相对于结构体首地址的偏移是固定不变的。因此当知道了结构体成员的地址,直接用结构体成员的地址,减去该成员在结构体内的偏移,就可以得到该结构体的首地址了。如下面程序实现

在上面的程序中,我们没有直接定义结构体变量,而是将数字0通过强制类型转换,转换为一个指向结构体类型为student的常量指针,然后分别打印这个常量指针指向的各成员地址。运行结果如下。

因为常量指针的值为0,即可以看作结构体首地址为0,所以结构体中每个成员变量的地址即该成员相对于结构体首地址的偏移。container_of宏的实现就是使用这个技巧来实现的。
有了上面的基础,我们再去分析container_of宏的实现就比较简单了。从语法角度来看,container_of宏的实现由一个语句表达式构成。语句表达式的值即最后一个表达式的值。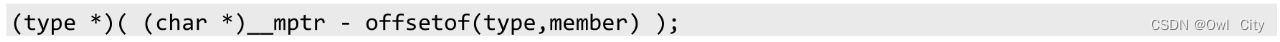
最后一句的意义就是,**取结构体某个成员member的地址,减去这个成员在结构体type中的偏移,运算结果就是结构体type的首地址。因为语句表达式的值等于最后一个表达式的值,所以这个结果也是整个语句表达式的值,container_of最后会返回这个地址值给宏的调用者。
那么该如何计算结构体某个成员在结构体内的偏移呢?内核中定义了offset宏来实现这个功能,我们且看它的定义。

这个宏有两个参数,一个是结构体类型TYPE,一个是结构体TYPE的成员MEMBER,它使用的技巧和我们上面计算零地址常量指针的偏移是一样的。将0强制转换为一个指向TYPE类型的结构体常量指针,然后通过这个常量指针访问成员,获取成员MEMBER的地址,其大小在数值上等于MEMBER成员在结构体TYPE中的偏移。
结构体的成员数据类型可以是任意数据类型,为了让这个宏兼容各种数据类型,我们定义了一个临时指针变量__mptr,该变量用来存储结构体成员MEMBER的地址,即存储宏中的参数ptr的值。如何获取ptr指针类型呢,可以通过下面的方式。
 我们知道,宏的参数ptr代表的是一个结构体成员变量MEMBER的地址,所以ptr的类型是一个指向MEMBER数据类型的指针,当我们使用临时指针变量__mptr来存储ptr的值时,必须确保__mptr的指针类型和ptr一样,是一个指向MEMBER类型的指针变量。typeof(((type)0)->member)表达式使用typeof关键字,用来获取结构体成员MEMBER的数据类型,然后使用该类型,通过typeof(((type)0)->member)__mptr这条程序语句,就可以定义一个指向该类型的指针变量了。
我们知道,宏的参数ptr代表的是一个结构体成员变量MEMBER的地址,所以ptr的类型是一个指向MEMBER数据类型的指针,当我们使用临时指针变量__mptr来存储ptr的值时,必须确保__mptr的指针类型和ptr一样,是一个指向MEMBER类型的指针变量。typeof(((type)0)->member)表达式使用typeof关键字,用来获取结构体成员MEMBER的数据类型,然后使用该类型,通过typeof(((type)0)->member)__mptr这条程序语句,就可以定义一个指向该类型的指针变量了。
在语句表达式的最后,因为返回的是结构体的首地址,所以整个地址还必须强制转换一下,转换为TYPE,即返回一个指向TYPE结构体类型的指针。
四、零长度数组
零长度数组、变长数组都是GNU C编译器支持的数组类型。
1、定义
零长度数组就是长度为0的数组。零长度数组的定义如下。
int a[0];
零长度数组有一个奇特的地方,就是它不占用内存存储空间。长度大小为0。零长度数组一般单独使用的机会很少,它常常作为结构体的一个成员,构成一个变长结构体。
如下代码所示。

零长度数组在结构体中同样不占用存储空间,所以buffer结构体的大小为4。
2、零长度数组使用示例
零长度数组经常以变长结构体的形式,在某些特殊的应用场合使用。在一个变长结构体中,零长度数组不占用结构体的存储空间,但是我们可以通过使用结构体的成员a去访问内存,非常方便。变长结构体的使用示例如下。
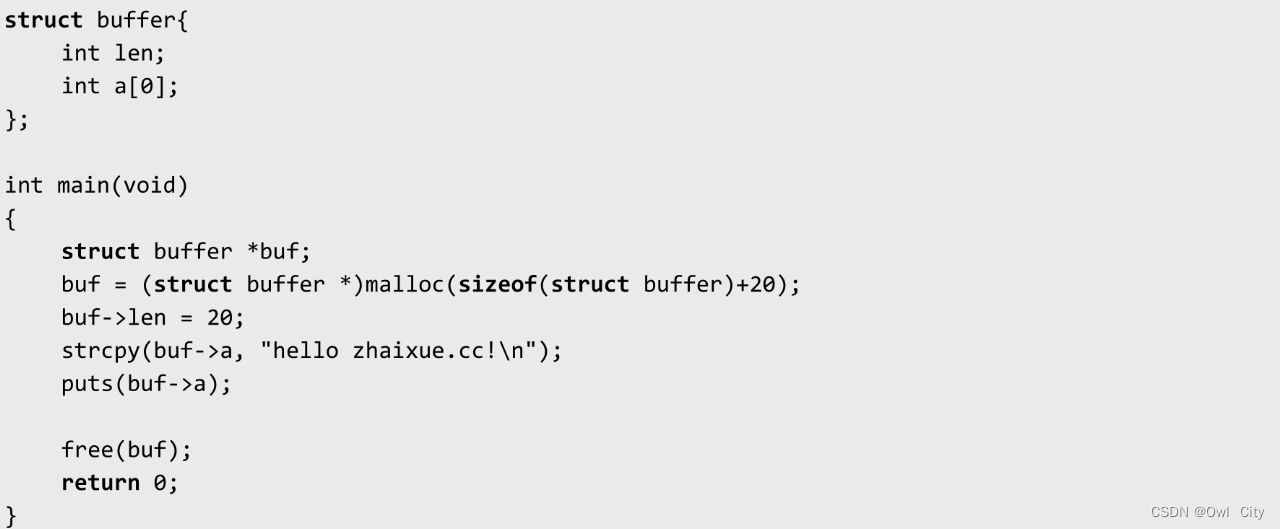
在这个程序中,我们使用malloc申请一片内存,大小为sizeof(buffer)+20,即24字节。其中4字节用来表示内存的长度20,剩下的20字节空间,才是我们真正可以使用的内存空间。我们可以通过结构体成员a直接访问这片内存。
3、内核中的零长度数组
零长度数组在内核中一般以变长结构体的形式出现。我们就分析一下变长结构体内核USB驱动中的应用。在网卡驱动中,大家可能都比较熟悉一个名字:套接字缓冲区,即Socket Buffer,用来传输网络数据包。同样,在USB驱动中,也有一个类似的东西,叫作URB,其全名为USB Request Block,即USB请求块,用来传输USB数据包。

这个结构体内定义了USB数据包的传输方向、传输地址、传输大小、传输模式等。这些细节我们不深究,只看最后一个成员。
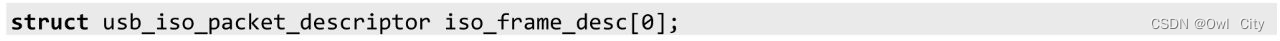
在URB结构体的最后定义一个零长度数组,主要用于USB的同步传输。USB有4种传输模式:中断传输、控制传输、批量传输和同步传输。不同的USB设备对传输速度、传输数据安全性的要求不同,所采用的传输模式也不同。USB摄像头对视频或图像的传输实时性要求较高,对数据的丢帧不是很在意,丢一帧无所谓,接着往下传就可以了。所以USB摄像头采用的是USB同步传输模式。
USB摄像头一般会支持多种分辨率,从16*16到高清720P多种格式。不同分辨率的视频传输,一帧图像数据的大小是不一样的,对USB传输数据包的大小和个数需求是不一样的。那么USB到底该如何设计,才能在不影响USB其他传输模式的前提下,适配这种不同大小的数据传输需求呢?答案就在结构体内的这个零长度数组上。
当用户设置不同分辨率的视频格式时,USB就使用不同大小和个数的数据包来传输一帧视频数据。通过零长度数组构成的这个变长结构体就可以满足这个要求。USB驱动可以根据一帧图像数据的大小,灵活地申请内存空间,以满足不同大小的数据传输。 而且这个零长度数组又不占用结构体的存储空间。当USB使用其他模式传输时,不受任何影响,完全可以当这个零长度数组不存在。所以不得不说,这个设计还是很巧妙的。
4、思考:指针和零长度数组
为什么不使用指针来代替零长度数组?
我们常常看到:数组名在作为函数参数进行参数传递时,就相当于一个指针。注意,我们千万别被这句话迷惑了:数组名在作为参数传递时,传递的确实是一个地址,但数组名绝不是指针,两者不是同一个东西。数组名用来表征一块连续内存空间的地址,而指针是一个变量,编译器要给它单独分配一个内存空间,用来存放它指向的变量的地址。如下程序所示。

运行结果如下。

对于一个指针变量,编译器要为这个指针变量单独分配一个存储空间,然后在这个存储空间上存放另一个变量的地址,我们就说这个指针指向这个变量。对于数组名,编译器不会再给它分配一个单独的存储空间,它仅仅是一个符号,和函数名一样,用来表示一个地址。
因此为什么选择不用指针,而使用零长度数组原因是如下:
- 指针本身占用存储空间,零长度数组不占用存储空间
- 根据上面的USB驱动的案例分析,你会发现,它远远没有零长度数组用得巧妙:零长度数组不会对结构体定义造成冗余,而且使用起来很方便。