
ChatGPT 和 GPT-4 等大型基础模型 (LFM) 在广泛的任务中展示了令人印象深刻的零样本学习能力。他们的成功可以归功于模型和数据集大小的缩放,以及使它们与用户内容保持一致的微调过程。
随着这些模型继续蓬勃发展,一个有趣的问题出现了:这些模型能否在没有太多人为干预的情况下监督自己的行为或其他模型?
为了回答这个问题,大量研究涌入了使用 LFM 作为教师来生成数据集来训练较小模型的研究。然而,与他们的老师相比,生成的学生模型通常具有较差的推理和理解能力。
为了解决这个问题,在一篇新论文Orca: Progressive Learning from Complex Explanation Traces of GPT-4中,微软研究团队介绍了 Orca,这是一个学习解释轨迹的 130 亿参数模型;循序渐进的思维过程;以及来自 GPT-4 的复杂指令,这显着提高了现有最先进的指令调优模型的性能。
该团队做出了三个关键贡献,包括解释调整、扩展任务和指令以及评估,以解决指令调整模型在任务多样性、查询复杂性和数据扩展方面的当前挑战。
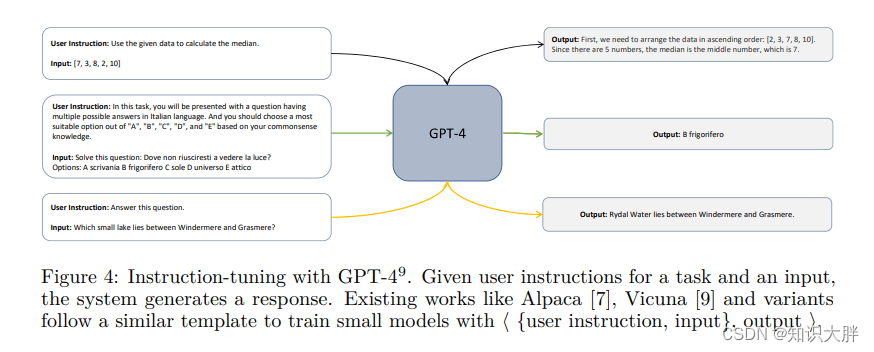
在解释调整中,研究人员从 GPT-4 中查询和响应对可以为学生模型学习提供有价值的信号。因此,他们用详细的回应来增加对,以更好地解释教师在产生回应时的推理过程。
在扩展任务和指令时,他们利用 Flan 2022 Collection 从其任务集合中采样以获得多样化的任务组合ÿ