
在当今社会,人工智能(AI)正以不可思议的速度发展,并在各个领域崭露头角,给人们的生活和工作带来许多便利。AI大模型被誉为人类“第二大脑”,成为人们学习、生活、工作的 “智能助手”。
公务员考试在我国教育领域独具特色,受到了众多考生的关注和青睐。众所周知,在公务员考试的过程中,行测真题中以数量关系最难也最耗时,使得考生们备考压力不小。在这样的背景下,用AI大模型来做行测真题,它们能做对吗?

今天,我们来简单测评一下GPT-3.5、GPT-4、文心一言及通义千问在特定的场景下的实际能力究竟如何。
我们选取21年国家公务员考试《行测》真题
某地调派 96 人分赴车站、机场、超市和学校四个人流密集的区域进行卫生安全检查,其中公共卫生专业人员有 62 人。已知派往机场的人员是四个区域中最多的,派往车站和超市的人员中,专业人员分别占 64%和 65%, 派往学校的人员中,非专业人员比专业人员少 30%,问派往机场的人员中,专业人员的占比在四个区域中排名第几?
正确答案:排名第一
第一位AI大模型选手:GPT-4
简介:GPT-4是OpenAI发布的最新一代语言模型,于2023年3月14日正式发布,并通过API和ChatGPT Plus平台向用户开放。
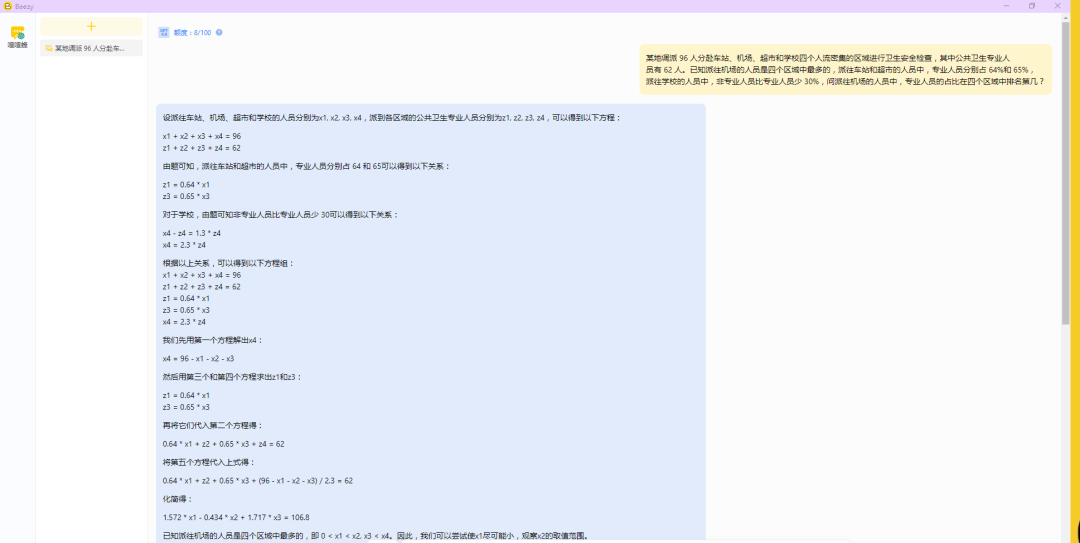
答案:在四个区域中,机场的专业人员占比排名是第1。
答案完全正确,过程十分详尽。
第二位AI大模型选手:GPT-3.5
简介:OpenAI于2023年3月1日正式发布GPT-3.5-turbo,它是目前最大规模的预训练语言模型之一,包含超过1亿个参数,可用于各种自然语言处理任务。
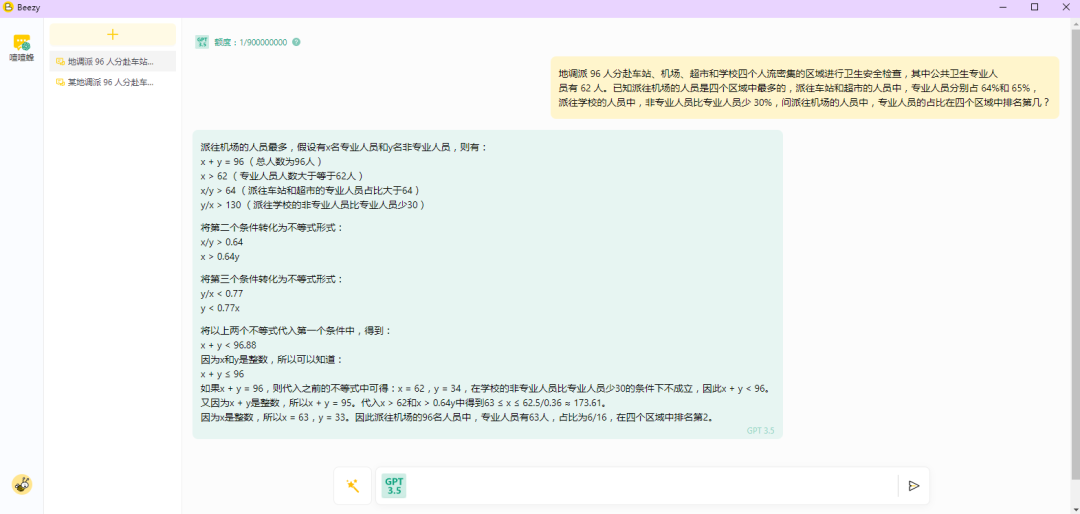
答案:在四个区域中排名第2。
错误。
第三位AI大模型选手:通义千问
简介:通义千问是阿里巴巴推出的预训练语言模型。它是达摩院自主研发的超大规模语言模型,也能够回答问题、创作文字,还能表达观点、撰写代码。

答案:因此,在四个区域中,专业人员的占比排名为第 4 位。
错误。
第四位AI大模型选手:文心一言
简介:文心一言(英文名:ERNIE Bot)是百度基于文心大模型技术推出的生成式对话产品,被外界誉为“中国版ChatGPT”,将于2023年3月份面向公众开放。

答案:在四个区域中排名第2。
错误。
Beezy点评
1.准确性
GPT-4的回答
通过建立多个方程并进行代数运算,最终得到了机场的专业人员占比排名是第一。整个过程有明确的推导过程,考虑了所有限定条件。过程详尽且答案完全正确。
GPT-3.5的回答
不等式形式的推导不清晰、且错误,没有给出具体实际情况下的求解。
通义千问的回答
通过计算在四个区域的专业人员占比及非专业人员占比,然后求取排名,这个过程中存在明显错误。在计算四个区域的专业人员比例时,通义千问未考虑到不同区域的总人数已知且有限制条件,而直接将比例相加。此回答是错误的。
文心一言的回答
未建立方程,也没有给出详细推导过程,仅仅给出了结论。在准确性上,此回答并不可靠。
2.实用性
从实用性方面出发,GPT-4的回答明确描述了解题思路,并通过方程的建立及化简找到答案。相对于其他回答者,实用性更强。但考虑考公行测有非常强的时间限制,解题需要早1-2分钟内完成,因此,GPT-4可能在奥数方面不占优势。
3.数学逻辑推导
GPT-4的回答有明确的方程建立,符合题意,通过代入及化简,达到求解目的。推导过程较为严谨。
GPT-3.5的回答由于不等式条件的错误,导致其推导不清晰且错误,不符合题目条件。
通义千问的回答虽然有一定的推导过程,但其错误地将比例相加而未考虑实际限制条件,计算过程错误。
文心一言的回答没有建立方程,缺乏严谨的数学推导过程。
综合来看:GPT-4的回答在准确性、实用性和数学推导方面具有较优的表现。GPT-3.5、通义千问、文心一言三个回答的问题分别在于不等式条件错误、计算过程错误和缺乏推导过程。但结合实际考公行测过程中,严苛的时限性质,其实AI大模型未未必能完全达标。
END