目录
1.Redis中什么是Big Key(大key)
Redis中的Big Key(大key)指的是占用大量内存的键值对。在Redis中,内存是一种宝贵的资源,如果有些键值对占用过多的内存,会导致Redis服务器的性能下降,甚至可能导致内存溢出。
具体来说,Redis中的Big Key通常是指占用内存超过一定阈值(例如10KB)的键值对。这些键值对可能包括大量的文本或二进制数据,或者包括大量的哈希字段或集合元素等。对于这些Big Key,需要进行特殊的处理和优化,以减少内存占用,并提高Redis服务器的性能和可靠性。
出现Redis Big Key的原因可能是存储了大量的文本或二进制数据,或者存储了大量的哈希字段或集合元素等。
2.Big Key会导致什么问题
Big Key(大key)是Redis中占用大量内存的键值对,如果存在过多的Big Key,会对Redis服务器的性能和可靠性产生负面影响,具体包括以下几个方面的危害:
-
内存占用:Big Key占用大量内存,如果Redis服务器的内存不足,就会导致Redis服务器的性能下降,甚至可能导致Redis服务器崩溃。
-
操作延迟:对Big Key进行读写操作时,会占用大量CPU资源和IO资源,从而导致操作延迟增加。如果有多个客户端同时操作Big Key,就会出现大量的等待,从而导致Redis服务器的性能下降。
-
持久化延迟:如果需要对Big Key进行持久化,例如写入到RDB文件或AOF文件中,就会占用大量CPU资源和IO资源,从而导致持久化延迟增加。如果Redis服务器的负载过高,就可能导致持久化失败或延迟过高,从而影响数据的可靠性和一致性。
-
数据丢失:如果Redis服务器的内存不足,就可能出现内存溢出的情况,从而导致Big Key数据丢失。如果Big Key包含重要的数据,就可能导致数据丢失或数据不一致的问题。
综上所述,Big Key的存在会对Redis服务器的性能和可靠性产生负面影响,可能导致内存占用、操作延迟、持久化延迟、数据丢失等问题。因此,需要对Big Key进行特殊处理和优化,以减少内存占用,并提高Redis服务器的性能和可靠性。
3.如何发现 bigkey?
1.使用Redis自带的--bigkeys参数可以快速地查找Big Key,具体步骤如下:
- 启动Redis客户端时,添加
--bigkeys参数,例如:redis-cli --bigkeys - Redis客户端连接到Redis服务器后,执行命令,例如:
bigkeys - Redis服务器会扫描所有的键值,找出占用内存较大的键值,并返回其信息,例如:
bigkeys # Scanning the entire keyspace to find biggest keys as well as # average sizes per key type. You can use -i 0.1 to sleep 0.1 sec # per 100 SCAN commands (not usually needed). [00.00%] Biggest string found so far 'my_big_string' with 100 bytes [00.00%] Biggest list found so far 'my_big_list' with 10 elements [00.00%] Biggest set found so far 'my_big_set' with 5 members [99.99%] Biggest zset found so far 'my_big_zset' with 1000 members [99.99%] Biggest hash found so far 'my_big_hash' with 10 fields -------- summary -------- Sampled 10000 keys in the keyspace! Total key length in bytes is 51451 (avg len 5.15) Biggest string found 'my_big_string' has 100 bytes Biggest list found 'my_big_list' has 10 items Biggest set found 'my_big_set' has 5 members Biggest zset found 'my_big_zset' has 1000 members Biggest hash found 'my_big_hash' has 10 fields通过上述方法,可以快速地找出所有的Big Key,并了解其大小和类型,从而进行进一步的优化和处理。需要注意的是,使用
--bigkeys参数会扫描整个Redis数据库,可能会对Redis服务器的性能造成一定的影响,因此应该在合适的时机进行使用。
2.使用Redis命令(生产环境慎用):Redis提供了一些命令可以查看所有键的信息和大小,例如KEYS命令可以列出所有键名,TYPE命令可以查看键值的类型,STRLEN命令可以查看字符串键值的长度,LLEN命令可以查看列表键值的长度等。通过这些命令可以发现Big Key,例如字符串键值长度超过阈值,列表键值长度超过阈值等。
3.使用Redis工具:Redis提供了一些工具可以帮助发现Big Key,例如redis-rdb-tools工具可以解析RDB文件,列出所有键值的信息和大小,redis-cli工具可以连接到Redis服务器,并执行一些命令,例如查看所有键值的信息和大小等。通过这些工具可以更方便地发现Big Key。
4.使用第三方工具:除了Redis自带的工具外,还有一些第三方工具可以帮助发现Big Key,例如Redis官方推荐的bigkeys工具可以扫描Redis数据库,发现所有的Big Key,并按照大小排序。
4.为什么redis生产环境慎用keys *命令
在Redis中,keys命令是用于模式匹配键名的命令,它可以根据指定的模式查找匹配的键名,从而实现对数据的快速检索。在实际开发中,我们可能需要使用keys命令来查询所有的键名。然而,在Redis的生产环境中,我们需要慎用keys *命令,原因如下:
-
性能问题:
keys *命令会遍历整个Redis数据库,将所有的键名加载到内存中,这可能会耗费大量的系统资源,导致Redis服务器的性能下降,甚至引起Redis服务器的宕机。 -
阻塞问题:在Redis执行
keys *命令时,会阻塞所有其他客户端的命令请求,直到keys *命令执行完成,这可能会导致其他客户端的请求被阻塞,从而影响系统的响应速度和稳定性。
如果你需要查询某个特定前缀的键名,可以使用Redis的SCAN命令,它可以分批次地迭代数据库中的键名,避免一次性加载全部键名,从而提高了性能和稳定性。例如,可以使用如下命令来查询所有以user:为前缀的键名:
SCAN 0 MATCH user:*
这个命令会返回一个游标和一批匹配的键名,你可以根据游标的值来获取下一批匹配的键名。需要注意的是,使用SCAN命令查询键名时,可能会出现重复或漏掉某些键名的情况,因此需要进行一定的处理和去重操作。
除了使用SCAN命令外,还可以在Redis的数据结构中设置索引或使用适当的命令来查询数据,以提高检索的效率和精度。例如,在使用Redis的Hash数据结构时,可以使用HGETALL命令来查询所有的字段和值,而不需要查询所有的键名。
5.如何处理大量 key 集中过期问题
在Redis中,当一个键过期时,Redis会自动将其从数据库中删除。如果一个Redis数据库中存在大量的键,且这些键的过期时间相近,当这些键过期时,可能会引发一些问题,例如:
-
内存使用问题:当大量键集中过期时,这些键占用的内存可能无法及时释放,从而导致Redis服务器的内存使用量持续升高,直到Redis服务器内存耗尽而崩溃。
-
性能问题:当大量键集中过期时,Redis服务器需要花费大量的CPU时间来处理这些过期键的删除操作,这可能会导致Redis服务器的性能下降,从而影响Redis服务器的响应速度和稳定性。
为了避免这些问题,我们可以采取一些措施来减轻过期键集中带来的影响,例如:
-
合理设置键的过期时间:在使用Redis时,需要根据业务需求和系统资源情况,合理设置键的过期时间,避免大量键集中过期。可以根据数据访问模式、业务需求等因素来调整过期时间。
-
分散过期时间:可以通过将键的过期时间随机分散开,避免过期键集中带来的问题。可以在设置键的过期时间时,加入一定的随机因素,使得过期时间不完全相同。
-
使用Redis的lazy-free特性,可以让Redis采用异步方式延迟释放键使用的内存,从而避免阻塞主线程,提高Redis服务器的性能和稳定性。
6.使用批量操作减少网络传输
Redis支持批量操作命令,通过一次性向Redis服务器发送多个命令请求,可以减少网络传输次数,从而提高Redis服务器的性能和效率。常见的批量操作命令有:
- MGET和MSET命令:MGET命令可以一次性获取多个键的值,而MSET命令可以一次性设置多个键的值。例如,下面的命令可以一次性获取键a、b、c的值:
MGET a b c - DEL命令:DEL命令可以一次性删除多个键。例如,下面的命令可以一次性删除键a、b、c:
DEL a b c - PIPES命令:PIPELINE命令可以将多个命令打包发送到Redis服务器,减少网络传输次数,并且可以通过一次性获取多个命令的返回结果,提高Redis服务器的性能。例如,下面的命令可以同时执行多个命令:
REDISCLI> PIPELINE REDISCLI> SET a 1 REDISCLI> INCR b REDISCLI> GET c REDISCLI> EXEC需要注意的是,使用批量操作命令时,需要根据实际情况,合理设置命令参数和调整Redis服务器的配置和参数,以达到最佳性能和稳定性。
7.缓存穿透
缓存穿透是指查询一个不存在的数据,由于缓存中没有数据,导致查询请求绕过缓存直接查询数据库,从而造成数据库压力过大的问题。缓存穿透问题是由于恶意攻击、缓存数据过期时间不合理、业务数据分布不均等因素造成的。
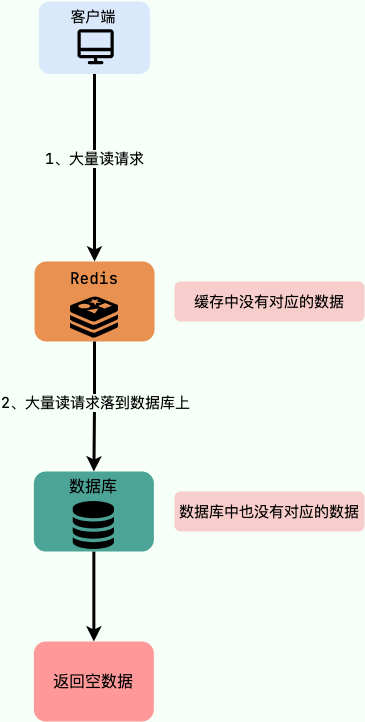
恶意攻击是缓存穿透的一种常见形式,攻击者故意发送不存在的查询请求,以达到消耗数据库资源的目的。例如,攻击者可以通过在查询参数中添加特殊字符或者构造恶意请求来绕过缓存查询数据库。
缓存数据过期时间不合理是缓存穿透的另一个常见原因。如果缓存中的数据过期时间设置得过短或者根本不设置,那么在数据过期后查询请求就会绕过缓存查询数据库。
业务数据分布不均也会导致缓存穿透的问题。例如,如果一些热点数据的访问频率非常高,而其他数据的访问频率很低,那么缓存中可能只存储了部分热点数据,而其他数据则没有被缓存。当查询请求访问的是缓存中没有的数据时,就会绕过缓存查询数据库,从而造成数据库压力过大。
为了解决缓存穿透的问题,可以采取以下措施:
-
布隆过滤器(Bloom Filter):使用布隆过滤器来过滤查询请求,可以有效地识别查询请求是否合法。布隆过滤器是一种基于哈希的数据结构,可以快速地判断一个元素是否在集合中,具有高效、快速、低存储等特点。
-
缓存空对象:在缓存中缓存一些空对象,当查询请求访问不存在的数据时,返回缓存中的空对象,避免查询请求绕过缓存直接访问数据库。
-
设置合理的缓存过期时间:设置合理的缓存过期时间,可以减少缓存穿透的问题。一般来说,缓存过期时间应该与业务数据的访问频率相匹配,以确保缓存中存储的数据都是热点数据。
-
限制恶意请求:限制查询请求的访问频率和查询参数,可以有效地防止恶意攻击和缓存穿透的问题。
8.缓存击穿
缓存击穿是指在高并发访问下,某个热点数据的缓存过期失效后,大量的请求涌入数据库,导致数据库瞬间压力激增,严重影响系统的稳定性和性能。缓存击穿通常是由于热点数据的访问频率非常高,导致缓存中的数据过期时间很短,同时查询请求也非常多,从而导致缓存中的数据被同时查询失效,造成大量请求绕过缓存直接查询数据库。
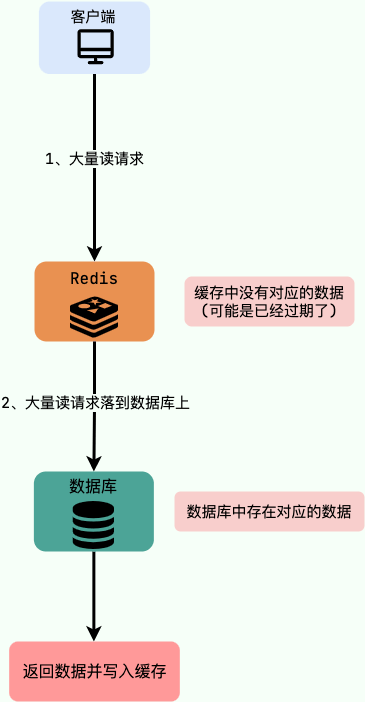
缓存击穿的解决方案一般有以下几种:
-
加锁:当缓存失效时,可以使用分布式锁的方式,将请求串行化,只允许一个请求访问数据库,其他请求等待结果返回。
-
限流:在热点数据的访问频率非常高的情况下,可以采用限流的方式,控制并发请求的数量,避免瞬间涌入大量的请求。
-
数据预热:将热点数据预先加载到缓存中,缓存失效时可以快速地从缓存中获取数据,避免大量请求绕过缓存直接查询数据库。
-
延迟缓存加载:当缓存失效时,不立即去数据库查询数据,而是等待一段时间后再去查询,期间如果有相同的查询请求,直接返回缓存中的数据。
-
使用二级缓存:将数据同时存储在多级缓存中,例如将热点数据存储在内存缓存和分布式缓存中,当内存缓存失效时,可以从分布式缓存中获取数据,避免大量请求绕过缓存直接查询数据库。
-
设置热点数据永远不过期。
9.缓存雪崩
缓存雪崩指的是在高并发访问下,缓存中大量的数据同时失效或者缓存服务不可用,导致大量请求涌入数据库,导致数据库瞬间压力激增,严重影响系统的稳定性和性能。缓存雪崩通常是由于缓存服务器宕机、缓存数据同一时间到期等因素造成的。
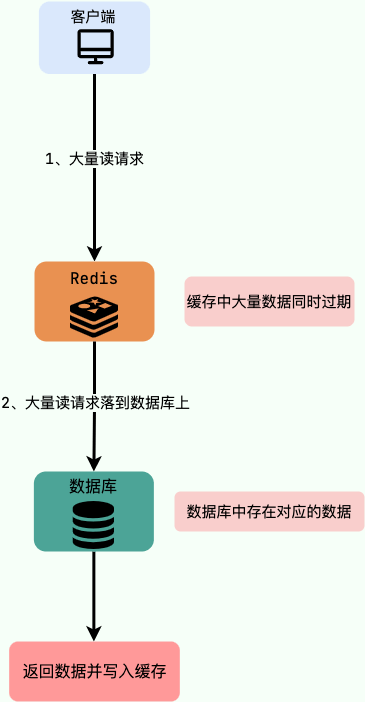
与缓存击穿不同,缓存雪崩是由于缓存中大量的数据同时失效或者缓存服务不可用造成的,而不是由某个热点数据的访问频率非常高导致的。
缓存雪崩的解决方案一般有以下几种:
-
数据分布:将缓存中的数据均匀地分布到不同的服务器上,避免某个缓存服务器宕机或者数据同时失效导致的问题。
-
限流:在缓存失效的情况下,采用限流的方式,控制并发请求的数量,避免瞬间涌入大量的请求。
-
备份缓存:将缓存中的数据备份到另一个缓存服务器或者本地文件系统中,当缓存失效或者服务不可用时,可以快速地从备份中恢复数据,避免大量请求绕过缓存直接查询数据库。
-
服务降级:当缓存失效或者服务不可用时,可以通过服务降级的方式,暂时屏蔽某些功能或者接口,保证核心功能的正常运行。
-
增加缓存有效期的随机性:在缓存中增加随机有效期,避免大量缓存同时失效,导致缓存雪崩的问题。
10.缓存污染(或满了)
缓存污染问题说的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。
缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会再次被访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会有额外开销,影响Redis性能。这部分额外开销主要是指写的时候判断淘汰策略,根据淘汰策略去选择要淘汰的数据,然后进行删除操作。
解决方案一般有以下几种:
1.设置多大最大缓存
系统的设计选择是一个权衡的过程:大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说,我会建议把缓存容量设置为总数据量的 15% 到 30%,兼顾访问性能和内存空间开销。
对于 Redis 来说,一旦确定了缓存最大容量,比如 4GB,你就可以使用下面这个命令来设定缓存的大小了:
不过,缓存被写满是不可避免的, 所以需要数据淘汰策略。
CONFIG SET maxmemory 4gb2.使用缓存淘汰策略
11.Redis共支持八种淘汰策略
Redis共支持八种淘汰策略,分别是noeviction、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
怎么理解呢?主要看分三类看:
不淘汰
- noeviction (v4.0后默认的)不进行淘汰,当内存不足时,新的写入操作会报错。
对设置了过期时间的数据中进行淘汰
- 随机:volatile-random,从所有的键中,随机淘汰一部分键。这种策略适合用于 Redis 所存储的数据没有重要性区分的情况,随机淘汰一部分键不会对数据产生太大影响。
- ttl:volatile-ttl,从设置了过期时间的键中,淘汰剩余时间最短的键。这种策略适合用于 Redis 所存储的数据有重要性区分的情况,对于过期时间短的数据优先淘汰。
- lru:volatile-lru,从所有的键中,使用 LRU 算法进行淘汰,即淘汰最近最少使用的键。这种策略适合用于 Redis 所存储的数据没有重要性区分的情况。
- lfu:volatile-lfu,从设置了过期时间的键中,使用 LFU 算法进行淘汰,即淘汰使用频率最少的键。这种策略适合用于 Redis 所存储的数据有重要性区分的情况,对于使用频率少的数据优先淘汰。
全部数据进行淘汰
- 随机:allkeys-random,从所有的键中,随机淘汰一部分键。这种策略适合用于 Redis 所存储的数据没有重要性区分的情况,随机淘汰一部分键不会对数据产生太大影响。
- lru:allkeys-lru,从所有的键中,使用 LRU 算法进行淘汰,即淘汰最近最少使用的键。这种策略适合用于 Redis 所存储的数据没有重要性区分的情况。
- lfu:allkeys-lfu,从所有的键中,使用 LFU 算法进行淘汰,即淘汰使用频率最少的键。这种策略适合用于 Redis 所存储的数据没有重要性区分的情况。
12.数据库和缓存一致性
在使用缓存时,最常见的问题之一就是缓存和数据库之间的一致性问题。由于缓存和数据库是两个独立的系统,所以当数据被更新或删除时,缓存中的数据可能会过期或失效,导致缓存中的数据和数据库中的数据不一致。这可能会导致一些问题,例如:
-
脏数据的问题:缓存中的数据已经失效或过期,但是客户端仍然从缓存中获取了这些数据。这可能会导致错误或不正确的结果。
-
数据丢失的问题:当数据库中的数据被删除时,缓存中的数据仍然存在,这会导致缓存中的数据变得不一致。
为了解决这些问题,需要确保在更新或删除数据库中的数据时,相应的缓存数据也被更新或删除。可以使用以下策略来确保数据库和缓存之间的一致性:
1.延时双删方案
这是一种简单有效的方案,其核心思想是在更新数据库时,先删除缓存中的数据,再更新数据库,最后再次删除缓存中的数据。这样做可以保证当缓存失效时,不会从数据库中读取旧数据。
但是,由于删除缓存和更新数据库都需要时间,因此需要在代码中增加适当的等待时间,保证在缓存失效之前完成数据库的更新。此外,如果在等待时间内缓存已经被其他操作重新写入,这种方案就可能失效。
2.更新缓存方案
这种方案的核心思想是在更新数据库时,先更新数据库,再更新缓存中的数据。这样可以确保在缓存中的数据始终是最新的。
但是,这种方案会面临一个问题:当多个请求同时更新同一个数据时,缓存中可能会出现脏数据。为了解决这个问题,可以引入分布式锁或者乐观锁来避免并发更新。
3.双写一致性方案
这种方案的核心思想是在更新数据库时,同时更新缓存中的数据,确保缓存中的数据和数据库中的数据始终一致。
但是,这种方案会面临一个问题:如果更新数据库失败,而缓存中的数据已经被更新,那么缓存中的数据就会变成脏数据。为了解决这个问题,可以采用事务来保证数据的一致性,如果更新数据库失败,则回滚事务,同时将缓存中的数据也进行回滚。此外,还可以采用写后读一致性的方案,先更新数据库,再更新缓存,确保缓存中的数据一定是最新的。如果读取到的缓存数据已经过期,则重新从数据库中读取数据。
4.利用消息队列
通过将数据更新操作放入消息队列中,先更新数据库,再通过消息队列异步更新缓存,确保缓存和数据库数据一致。通过消息队列可以实现高可靠、高性能的异步更新,同时避免了缓存和数据库之间的直接交互。需要注意的是,使用消息队列会增加系统的复杂度和延迟,需要在实际情况中进行权衡。