目录
小知识点:linux下的c++后置——.cpp / .cc / .cxx
./a.out 1> stdout. txt 2>stderr. txt 解释:
./a.out 1> stdout. txt 2>stderr. txt的意义:
(1)LBA地址转换为CHS地址( 磁柱(Cylinder),磁面(Head),扇区(Sector) )
为什么SB (super block)记录整个区的数据,把它和最前面的 Boot Block 放在一样的位置都只有一份不就行了?
2.一个inode(文件,属性)如何和属于自己的内容Datablocks关联起来呢?
(4)我知道自己所处的目录,就能知道目录的inode吗? (了解)
(3)为什么创建普通文件,硬链接数默认是1?创建目录的硬链接数默认是2?
(4)为什么在目录mydir中再创建一个目录dir1,目录mydir的硬链接数会由2—>3呢?
(静态库本质:把源文件.c翻译成.o文件,再把所有.o文件打包起来)
(1)将自己的头文件和库文件拷贝到系统路径下即可!——库的安装-不推荐,会污染系统库和系统头文件
(1)和静态库一样操作:将自己的头文件和库文件拷贝到系统路径下
① 将动态库拷贝到系统路径下:lib64-- 安装的过程,进程链接和运行都能找到这个库
② 通过导入环境变量的方式——程序运行的时候,会在环境变量中查找自己需要的动态库路径-- 环境变量:LD_ LIBRARY_ PATH
一.myshell中实现重定向
1.myshell中实现重定向
ChangeDir
#include <stdio.h>
#include <string.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <ctype.h>
#define SEP " "
#define NUM 1024
#define SIZE 128
//跳过 //ls -a -l>> log.txt 的>>和log.txt之间空格操作:
#define DROP_SPACE(s) do { while(isspace(*s)) s++; }while(0)
char command_line[NUM];
char *command_args[SIZE];
char env_buffer[NUM]; //for test
#define NONE_REDIR -1
#define INPUT_REDIR 0
#define OUTPUT_REDIR 1
#define APPEND_REDIR 2
int g_redir_flag = NONE_REDIR;
char *g_redir_filename = NULL;
extern char**environ;
//对应上层的内建命令
int ChangeDir(const char * new_path)
{
chdir(new_path);
return 0; // 调用成功
}
void PutEnvInMyShell(char * new_env)
{
putenv(new_env);
}
void CheckDir(char *commands)
{
assert(commands);
//[start, end)
char *start = commands;
char *end = commands + strlen(commands);
// ls -a -l
while(start < end)
{
if(*start == '>')
{
if(*(start+1) == '>')
{
//ls -a -l>> log.txt --追加
*start = '\0';
start += 2;
g_redir_flag = APPEND_REDIR;
DROP_SPACE(start);
g_redir_filename = start;
break;
}
else{
//ls -a -l > log.txt -- 输出重定向
*start = '\0';
start++;
DROP_SPACE(start);
g_redir_flag = OUTPUT_REDIR;
g_redir_filename = start;
break;
}
}
else if(*start == '<')
{
// 输入重定向
*start = '\0';
start++;
DROP_SPACE(start);
g_redir_flag = INPUT_REDIR;
g_redir_filename = start;
break;
}
else
{
start++;
}
}
}
int main()
{
//shell 本质上就是一个死循环
while(1)
{
g_redir_flag = NONE_REDIR;
g_redir_filename = NULL;
//不关心获取这些属性的接口, 搜索一下
//1. 显示提示符
printf("[张三@我的主机名 当前目录]# ");
fflush(stdout);
//2. 获取用户输入
memset(command_line, '\0', sizeof(command_line)*sizeof(char));
fgets(command_line, NUM, stdin); //键盘,标准输入,stdin, 获取到的是c风格的字符串, '\0'
command_line[strlen(command_line) - 1] = '\0';// 清空\n
//2.1 ls -a -l>log.txt or cat<file.txt or ls -a -l>>log.txt or ls -a -l
// ls -a -l>log.txt -> ls -a -l\0log.txt
CheckDir(command_line);
//3. "ls -a -l -i" -> "ls" "-a" "-l" "-i" 字符串切分
command_args[0] = strtok(command_line, SEP);
int index = 1;
// 给ls命令添加颜色
if(strcmp(command_args[0]/*程序名*/, "ls") == 0 )
command_args[index++] = (char*)"--color=auto";
// = 是故意这么写的
// strtok 截取成功,返回字符串其实地址
// 截取失败,返回NULL
while(command_args[index++] = strtok(NULL, SEP));
//for debug
//for(int i = 0 ; i < index; i++)
//{
// printf("%d : %s\n", i, command_args[i]);
//}
// 4. TODO, 编写后面的逻辑, 内建命令
if(strcmp(command_args[0], "cd") == 0 && command_args[1] != NULL)
{
ChangeDir(command_args[1]); //让调用方进行路径切换, 父进程
continue;
}
if(strcmp(command_args[0], "export") == 0 && command_args[1] != NULL)
{
// 目前,环境变量信息在command_line,会被清空
// 此处我们需要自己保存一下环境变量内容
strcpy(env_buffer, command_args[1]);
PutEnvInMyShell(env_buffer); //export myval=100, BUG?
continue;
}
// 5. 创建进程,执行
pid_t id = fork();
if(id == 0)
{
int fd = -1;
switch(g_redir_flag)
{
case NONE_REDIR:
break;
case INPUT_REDIR:
fd = open(g_redir_filename, O_RDONLY);
dup2(fd, 0);
break;
case OUTPUT_REDIR:
fd = open(g_redir_filename, O_WRONLY | O_CREAT | O_TRUNC);
dup2(fd, 1);
break;
case APPEND_REDIR:
fd = open(g_redir_filename, O_WRONLY | O_CREAT | O_APPEND);
dup2(fd, 1);
break;
default:
printf("Bug?\n");
break;
}
//child
// 6. 程序替换, 会影响曾经子进程打开的文件吗?不影响
//exec*?
execvp(command_args[0]/*不就是保存的是我们要执行的程序名字吗?*/, command_args);
exit(1); //执行到这里,子进程一定替换失败
}
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("等待子进程成功: sig: %d, code: %d\n", status&0x7F, (status>>8)&0xFF);
}
}// end while
}

二.标准输出与标准错误
小知识点:linux下的c++后置——.cpp / .cc / .cxx
1. 示例解释
./a. out > stdout. txt 解释:
默认:把 标准输出 重定向到 stdout. txt 。
./a.out 1> stdout. txt 2>stderr. txt 解释:
1> stdout. txt:把 标准输出 重定向到 文件stdout. txt ;
2>stderr. txt:把 标准错误输出 重定向到 文件stderr. txt ;
./a.out 1> stdout. txt 2>stderr. txt的意义:
可以区分哪些是程序日常输出哪些是错误!——日志等级
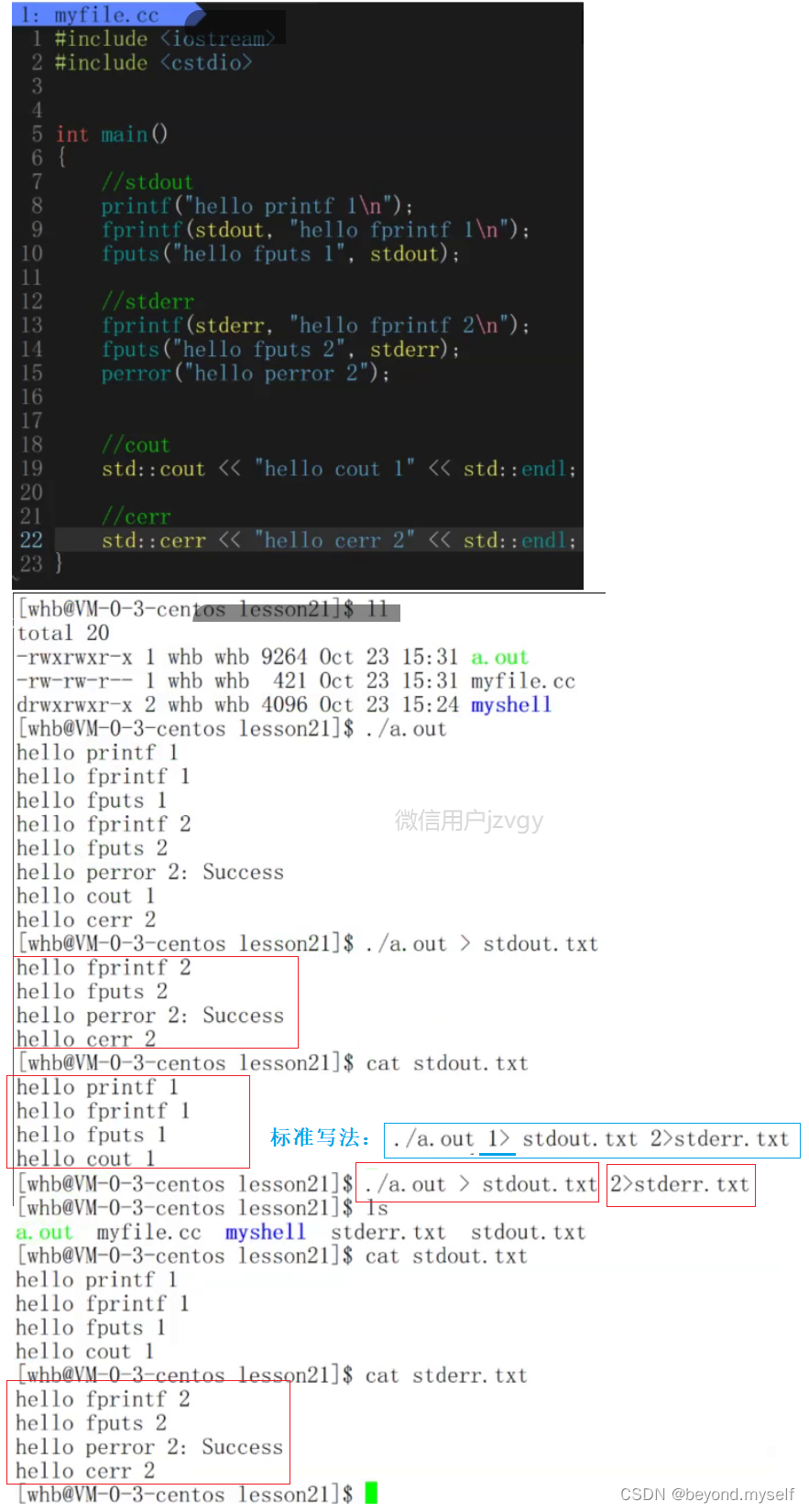
./a. out > all. txt 2>&1:
把标准输出和标准错误混着输到一个文件:
- 先将标准输出重定向到 all. txt文件,然后将标准错误重定向到标准输入(这时候的标准输入已经是指向文件了,所以也就是将标准错误重定向到文件)

解释:./a.out > all.txt 是普通的把标准输出重定向到文件all.txt ——把[1]指向了文件all.txt,
(0-标准输入;1-标准输出;2-标准输出;)2>&1是把[1]拷贝给[2],即:把标准错误重定向到标准输出——把[2]也指向了文件all.txt。
(如果是1>&2 就是: 将标准输出重定向到标准错误。在这条语句中,>是重定向符号 &2是在重定向使用时标准错误的一种特殊写法,是语法规定)
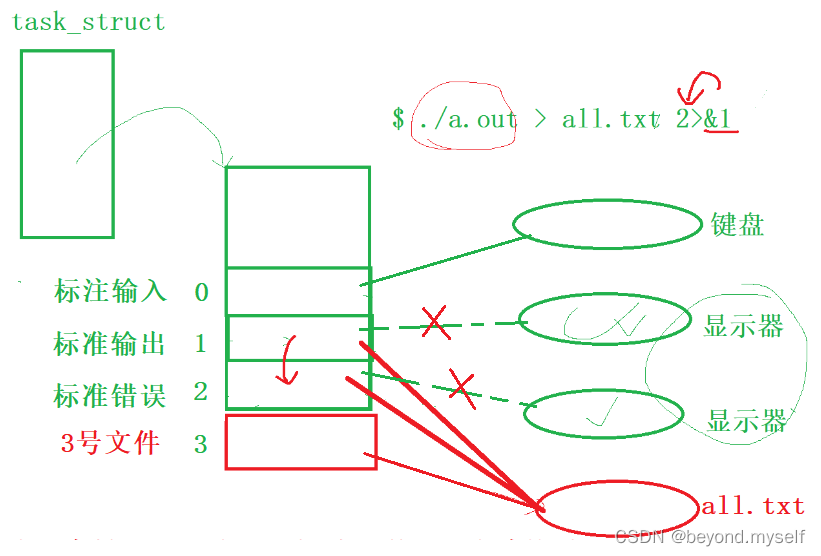
2.perror和模拟实现

errno:C语言有一个全局变量,记录最近一次C库函数调用失败的原因!
三.文件系统
上面我们学到的所有的东西,全部都是在内存中,但是不是所有的文件都被打开了——大量的文件就在磁盘上 静静的躺着,这批文件非常多,杂,乱
磁盘基本的文件管理,本质工作和快递点的老板做的工作是一样的。磁盘基本的文件管理就叫文件系统。
所以我们要把视角从内存中移开,迁移到磁盘上!
1. 磁盘的物理结构
磁盘是我们电脑上的唯一的一个存储结构是机械的设备,目前,同学们笔记本上,可能已经不用磁盘了。而是SSD(固态硬盘)(SSD耐用性不如磁盘,比磁盘贵,但是效率快)
你的文件数据,就在这个盘面上。
磁盘图片:

一个面,一个磁头!
机械式+外设 = 磁盘一定是很慢的(CPU,内存)
磁盘存储数据:磁铁分NS极,磁盘的一面有很多个类似磁铁的单元,通过磁头改变磁铁单元的NS几来改变01。
磁性:N,S极
改变NS极——>就是改变了01

2.磁盘的存储结构
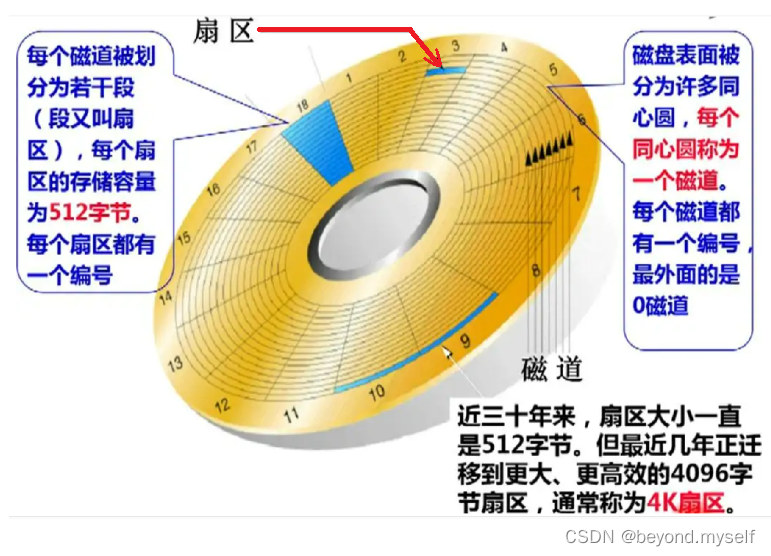
磁盘上存储的基本单位是扇区512字节
读写磁盘的时候,磁头找的是某一个面 的某一个磁道 的某一个扇区
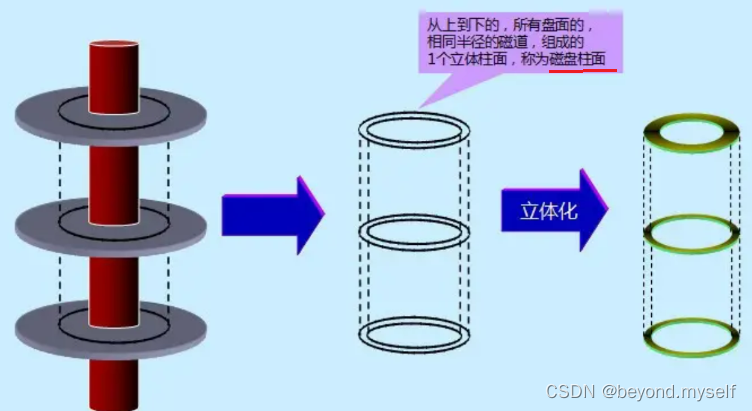
是哪一个面由哪一个磁头决定;哪个磁道——>要知道是哪一个柱面的——>距离圆心的半径——>也是由哪一个磁头决定;哪一个扇区——>磁道上的一段——>由盘面旋转决定的
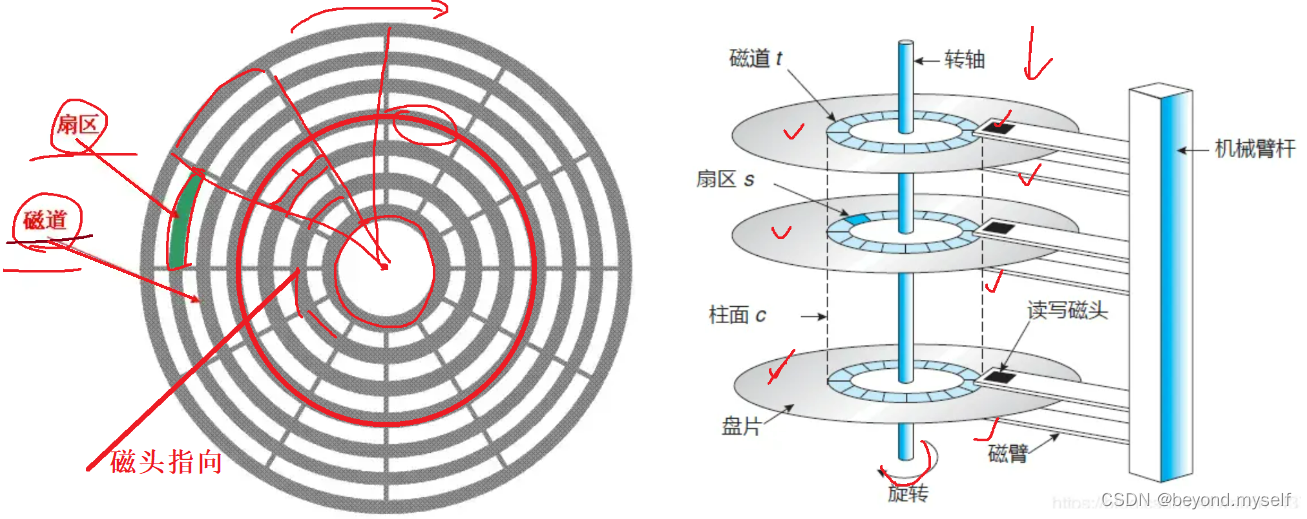
柱面:
文件系统:什么文件,对应了几个磁盘块!
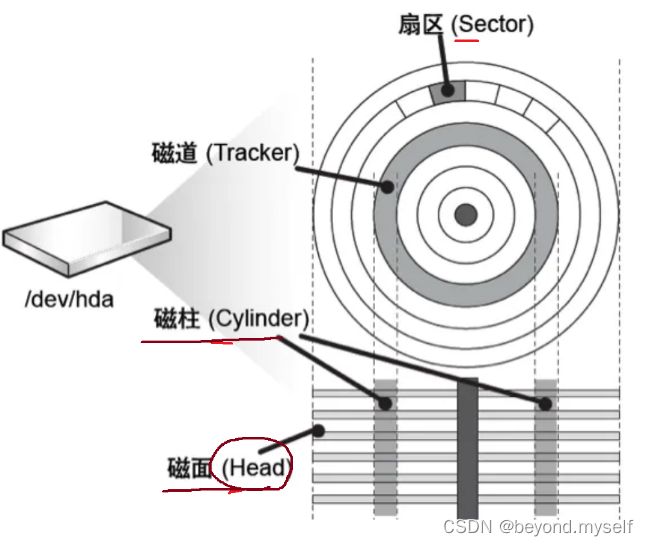
物理上查找某一个扇区的寻址方式叫 CHS地址(对应下图 磁柱(Cylinder),磁面(Head),扇区(Sector)):只要我们能找到磁盘上的盘面,柱面(磁道),扇区找到一个存储单元。用同样的方法,我们可以找到所有的基本单元! !
3.磁盘的逻辑抽象结构
类比磁带,磁带可以全部拉出来成一个长条,磁盘也可以抽象成一个数组:把磁盘每一个盘面的每一个磁道抽出来拉直成一条线,每个扇区就是一个数组元素,整个盘面的磁道挨着排列,再把每个盘面挨着排列,就成了一个大数组。假设有10000000个扇区,每个扇区是512字节,类型是sector
则对磁盘的管理,转化成为了对数组空间的管理! !定位一个sector,只要找到下标就行了!这里的下标叫做 LBA(logic block address 逻辑块地址)

(1)LBA地址转换为CHS地址( 磁柱(Cylinder),磁面(Head),扇区(Sector) )
假如要找第3234个扇区,假如有4个磁盘面,4个磁盘面放在一个数组,一面假设是1000个扇区,3234/1000=3,第一面是0~1000,第二面是1000~2000,第三面是2000~3000,第四面是3000~4000。所以3234这个扇区在第4面,磁面H=4,假设一个磁盘面上有20个磁道,3234%1000=234,234/20=11,磁柱C=11,假设一个磁道有20个扇区,234%20=14,扇区S=14,即可得到CHS地址的三个值

(2)IO的基本单位是4KB
IO的基本单位是4KB,即文件系统访问磁盘的基本单位是:4KB,一个扇区是512字节,也就是8个扇区为单位
磁盘的基本单位是:扇区(常规512字节),操作系统访问磁盘(IO交互)的基本单位是:4KB,原因:
1. 提高IO效率
2. 不要让软件(OS)设计和硬件(磁盘)具有强相关性,换句话说,就是解耦合!(解耦举例:写计算器,把main函数的+-*/功能由全部写在main函数中——>写成一个个独立函数,就叫解耦)
四.文件系统管理
1.文件系统管理基本结构
文件=内容+属性——这俩都是数据——都要存储——Linux采用的是将内容和属性数据分开存储的方案!
文件内容:存在一个block中,空间大小为4KB,文件内容是可以不断增多
文件属性数据:存在一个inode中(inode中就是磁盘上的另一份空间),空间大小为28字节,文件属性数据是稳定的,不会增长。
先对总的磁盘500GB分成几个区,再把其中一个100GB的区划分为20个组,每组5GB;再把每组划分成5个1GB的空间。对如何管理500GB的文件,变成了对一个1GB的小组数据的管理。
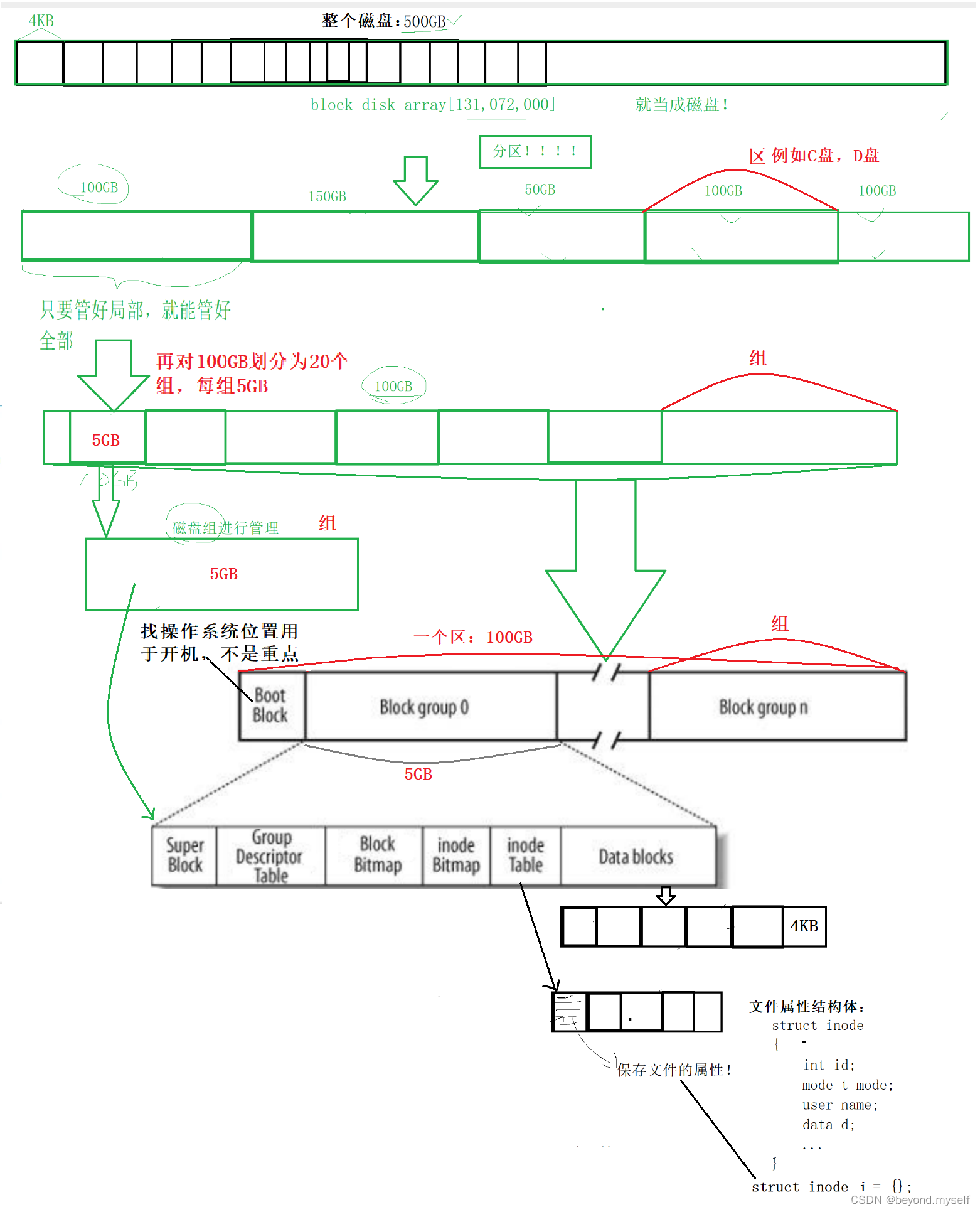
Boot Block:存储开机信息(包括分区表,OS软件位置等)<非重点>
Data blocks: 以数据块(一块是4KB)为单位,进行文件内容的保存!(1个Block group中Data blocks占80%空间)
inode table: 以128字节为单位,进行inode属性的保存,即保存文件属性,一个inode就是一个文件。每个128字节的块就对应一个inode编号。( inode属性里面有一个inode编号。这个inode编号是全局的,任何文件的inode编号都不一样。所以找到一个inode就能确定这个文件在整个分区的哪个块组的哪个具体位置。找到inode就找到了所有文件的数据!(找到inode就能找到inode块组具体在哪,inode块组又有文件属性和blocks数据块的编号,进而找到文件数据)一般而言,一个文件对应一个inode号!(证明是下图 )

Block Bitmap:用位图表征Date blocks的使用情况,一个位是1就是占用,是0就是未占用。假设Date blocks有1000个4KB的数据块,那位图就有1000 bits ,0000 0000 - > 0001 1001 代表编号为0,3,4的数据块被占用。
inode Bitmap: inode 块是否被占用! inode bitmap表征inode Table的使用情况!
GDT(Group Descriptor Table 块组描述符):管理整个分区内一个块的数据,即:记录1GB的block group的属性,例如:有多少inode,起始的inode编号,有多少个inode被使用,有多少block被使用,还剩多少,你的总group大小是多少。
SB (super block): 管理整个100GB分区数据,是我们文件系统的项层数据结构了! 比如:硬盘分区上一共有多少个block group、硬盘分区中每个block group的大小、以及每个block group中inode Table,Date blocks的使用情况,整个分区在磁盘的位置区间等等
为什么SB (super block)记录整个区的数据,把它和最前面的 Boot Block 放在一样的位置都只有一份不就行了?
答:用于备份。防止一个 super block 损坏导致整个分区100GB都不能用,假如有10个Block group,会有2~3个Block group保存有 super block,剩下的没有 super block ,即:有块组的有 super block,有的块组没有 super block
2.一个inode(文件,属性)如何和属于自己的内容Datablocks关联起来呢?
inode Table中一个块保存的(重写听这一块还有2:26:00)
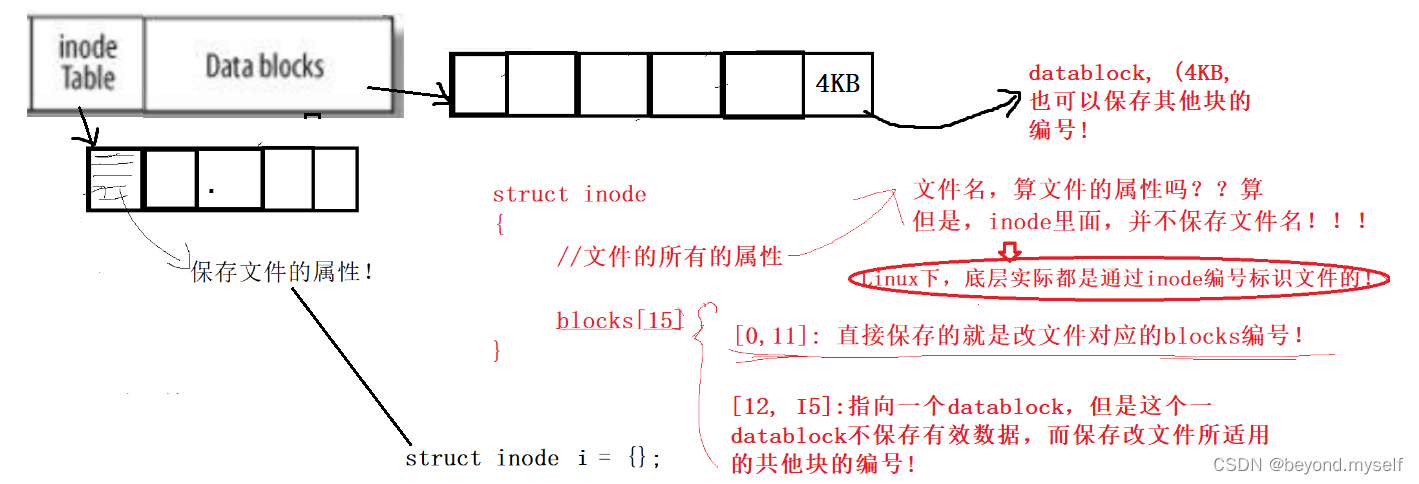
inode Table中的一个块struct inode内包含文件所有属性+一个数组blocks[15],[0,11]:直接保存的就是该文件对应的blocks编号!
[12,15]:指向一个datablock,但是这个datablock不保存有效数据,而保存该文件所适用的共他块的编号!即:通过inode编号找到 inode块, inode块通过一级索引[0,11]找到对应数据块,还可以通过二级索引[12,15]的方式来找到更多的数据块,解释:[12,15]指向Data blocks中的一个datablock数据块,这个数据块内存着更多的其他数据块编号,因此可以找到更多对应的数据块。
inode里面不保存文件名解释以及几个问题:
因为文件名在目录中,目录内容中存着文件名和 inode编号的映射关系
①文件名,算文件的属性吗? ?——算。但是inode里面并不保存文件名! ! !
因为Linux下,底层实际都是通过inode编号标识文件的。
②linux下一切皆文件,那目录是文件吗?——是的
目录是文件,文件=内容(blocks)+属性(inode)
目录的inode Table包含它自己的inode和它自己的属性等等,目录内容(数据块)存的是 文件名和 inode编号的映射关系!因为文件名和 inode编号也是数据。
③Linux同一个目录下,可以创建多个同名文件吗?
——不能。文件名本身就是一个具有Key值的东西!(一个文件名不可能对多个inode编号,但一个inode编号可能对多个文件名——因为硬链接)
关于目录权限的问题!
进入一个目录需要x权限,创建一个文件需要目录的w(因为要把文件的inode和文件名链接关系写入目录),查看文件名需要目录的r(因为读取目录内容中的文件的inode和文件名链接关系)
(1) 当我们创建一个文件,操作系统做了什么?
因为创建一个文件的时候,一定是在一个目录下。有了新文件的 文件名和inode编号—>找到自己所处的目录—>根据目录的inode,找到目录的datablock—>将文件名和inode编号的映射关系写入到目录的数据块中! !
(2)请问删除一个文件,OS做了什么? ?
文件名是唯一的,查找文件名就找到inode编号,通过inode编号找到对应block group,在把该文件的俩位图 inodeBitmap和blockBitmap 由1置0。再把该文件所在目录中存的文件名和inode编号的映射关系去除掉,就完成了文件删除!此时整个block group都失效了,可以被覆盖。即:所以操作系统(包括linux)并没有真正的清除数据,而是清除了文件的标记位和文件名与inode编号的映射关系。
(3)恢复文件
linux系统支持恢复的做法:当我们删文件时,此文件的inode编号会在系统的日志文件中保存,只需从日志中找到inode编号,通过特定工具把位图进行由0置1即可恢复。所以最怕删除一个文件后,还频繁写入,标记位(位图)被复用,覆盖了原来的位图,导致文件无法恢复。
(4)我知道自己所处的目录,就能知道目录的inode吗? (了解)
不能,需要找到目录的目录名和inode的映射关系。比如 /a/b/c/d,只知道d的文件名,想要找到d的inode,就要去d的 父目录(c) 的目录内容找d的文件名和inode编号的映射关系。找d的 父目录(c) 的目录内容又需要找到c的inode,知道c的文件名想找到c的inode,就要去c的 父目录(d) 的目录内容找d的文件名和inode编号的映射关系。递推下去,需要一直找到根目录。
五.软硬链接
软硬链接的区别:软连接是一个独立文件,有自己独立的inode和inode编号。硬链接不是一个独立文件 (是什么? )他和目标文件使用的是同一个inode!
1.软链接(符号链接)
软链接:就是在linux下的快捷方式。软链接会创建新的文件,所以要分配inode
例子1:“软链接就是在linux下的快捷方式”证明例子

例子2:(主要)
(下图红色是硬链接,绿色是软链接)这里看绿色
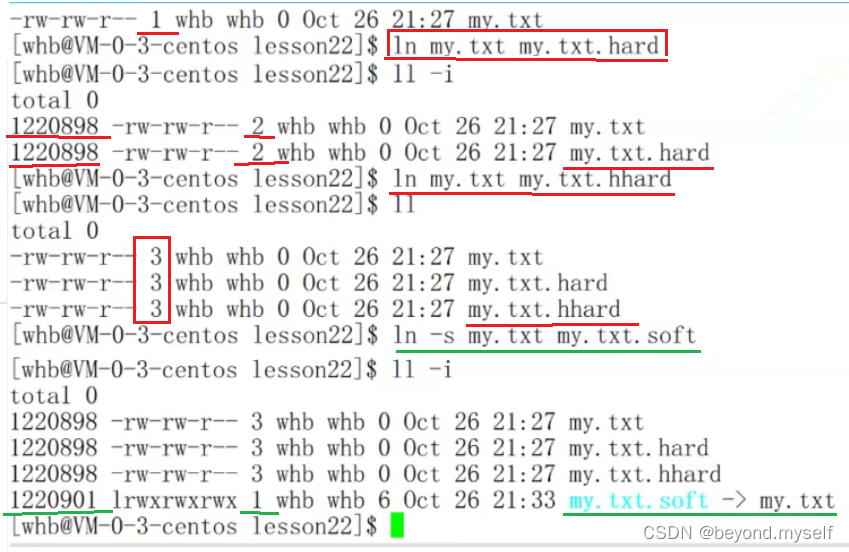
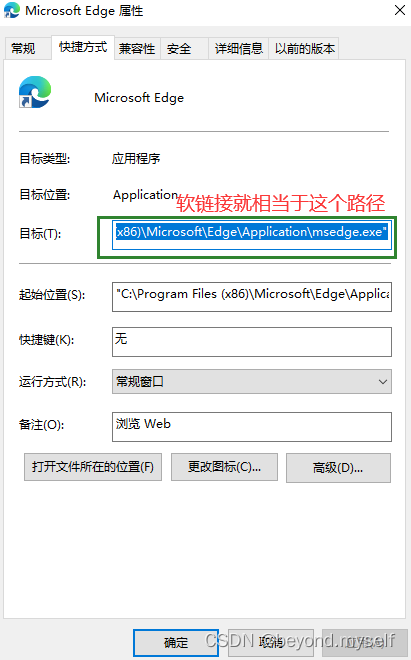
my.txt.soft是一个独立的文件。既然是一个独立文件,inode是独立的,那软连接的文件内容是什么呢?——保存的是指向的文件的所在路径(是系统级别上的)。这个文件就是个可执行程序,这也是为什么直接./my.txt.soft就可以直接执行文件my.txt
2.硬链接
(1)概念
硬链接:就是单纯的在Linux指定的目录下,给指定的文件新增文件名,并增加一个这个新文件名与inode编号的映射关系!
ln my.txt my.txt.hard
(2)什么是硬链接数?(权限后面的那个值就是硬链接数)
inode编号,不就是一个”指针“的概念吗?(指针定义:标定唯一性资源,并能提供这个标识找到资源,就叫指针)
硬链接数:本质就是改文件inode属性中的一个计数器,就是一个count,作用:标识有几个文件名和我的inode建立了映射关系。简言之,就是有几个文件名指向我的inode(就是文件本身!)(下图红色是硬链接,绿色是软链接)这里看红色
(3)为什么创建普通文件,硬链接数默认是1?创建目录的硬链接数默认是2?
①创建普通文件硬链接数默认是1:因为普通文件的文件名本身就和自己的inode具有映射关系,而且只有这一个映射关系。
②创建目录的硬链接数默认是2:首先目录mydir目录名本身就和自己的inode具有映射关系,第二 进入目录后 . 也是和目录具有映射关系的( . 就是个文件,文件名就叫 " . ",这也就解释了:如果目录下有个mmm.exe,我们直接./mmm.exe就可以执行)

(4)为什么在目录mydir中再创建一个目录dir1,目录mydir的硬链接数会由2—>3呢?
答:因为目录dir1中的 .. 这个文件指向了上级目录,也就是目录mydir,所以目录mydir又多了一个引用,所以硬链接数会加1。

(5)硬链接有什么用?. 文件和 .. 文件是什么?
硬链接的作用:路径间切换!
. 文件:. 就是个文件,文件名就叫 " . ",他指向当前目录,这也就解释了:如果当前目录下有个mmm.exe,我们直接./mmm.exe就可以执行。
.. 文件:.. 就是个文件,文件名就叫 " .. ",他指向上级目录,这也就解释了:cd .. 可以返回上级目录
例子:目录mydir中的 . 指向所在目录 /home/ whb/104/ phase-104/lesson22/mydir ;目录mydir中的 .. 指向上级目录 /home/ whb/104/ phase-104/lesson22
( -d:只显示目录)

3.删除软硬链接文件操作:unlink
unlink my.txt.hard
unlink my.txt.soft(unlink 也可以删除正常的文件)————————————————————————————
4.软连接可以跨文件系统进行链接,硬链接不可以
软链接文件是一个独立的文件有自己的inode节点,文件中保存了源文件路径,通过数据中保存的源文件路径访问源文件
硬链接是文件的一个目录项,与源文件共用同一个inode节点,直接通过自己的inode节点访问源文件(其实本质上来说与源文件没区别)
不同分区有可能有不同文件系统,软连接可以跨文件系统进行链接;硬链接不可以,就算系统相同,也会导致节点号有歧义冲突,因此硬链接不能跨分区建立。
六.动静态库
静态链接,链接静态库,每个程序将自己在库中用到的指令代码单独写入自己可执行程序中,程序运行时无依赖,加载运行速度快,但是程序运行后有可能会有冗余代码在内存中。静态库重新编译,需要将应用程序重新编译
加载问题:动态链接的程序一旦库中代码发生改变,重新加载一次动态库即可,但是静态链接代码是写入程序中的,因此库中代码发生改变,必须重新链接生成程序才可以
1.生成静态库过程
1.—生成.o文件

gcc -c mypath.c -o mypath.o
gcc -c myprint.c -o myprint.o
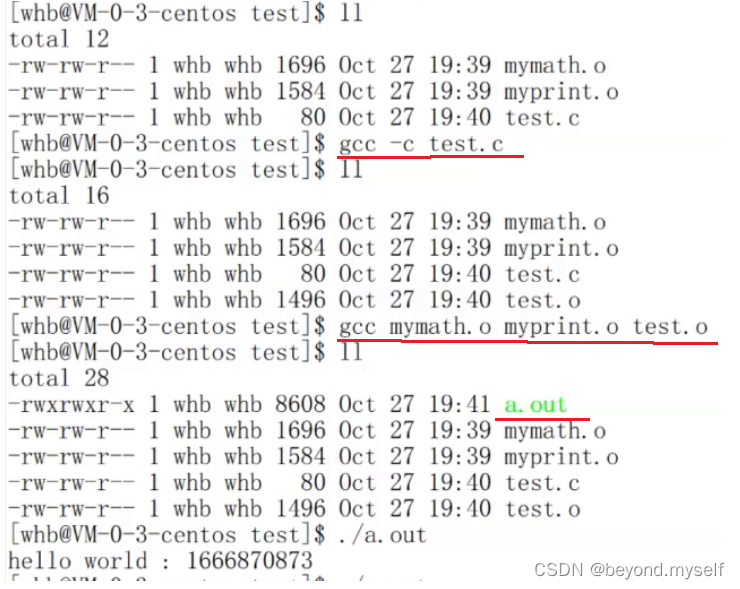
首先把所有的.c源文件翻译成.o文件。然后链接。链接:把所有的.o链接形成一个可执行程序。
如果我把我的所有的. o给别人,别人能链接使用吗?——答:能:
请看下图例子:
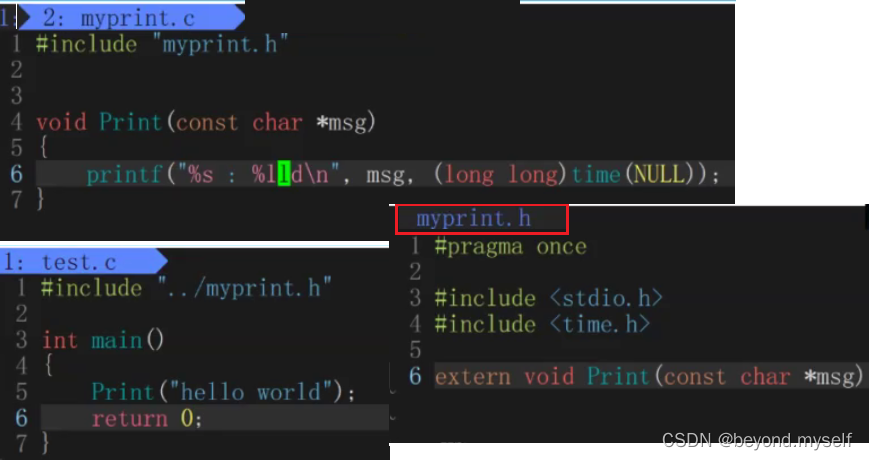
你在用库的时候,需要什么东西呢?
库文件,头文件
给别人用了
2.—把.o文件打包成静态库
ar -rc libmymath.a mymath.o myprint.o
ar是把后面的几个.o文件打包(归档 archive),选项 -rc 表示(replace and create)
c(create):静态库本来不存在,creat生成。r(replace):当打包一次后,其中的.o文件更新,就会把旧的进行替换。libmymath.a:静态库名

3.—生成库文件libmymath.a
前面有打包,则make直接自动执行1~6行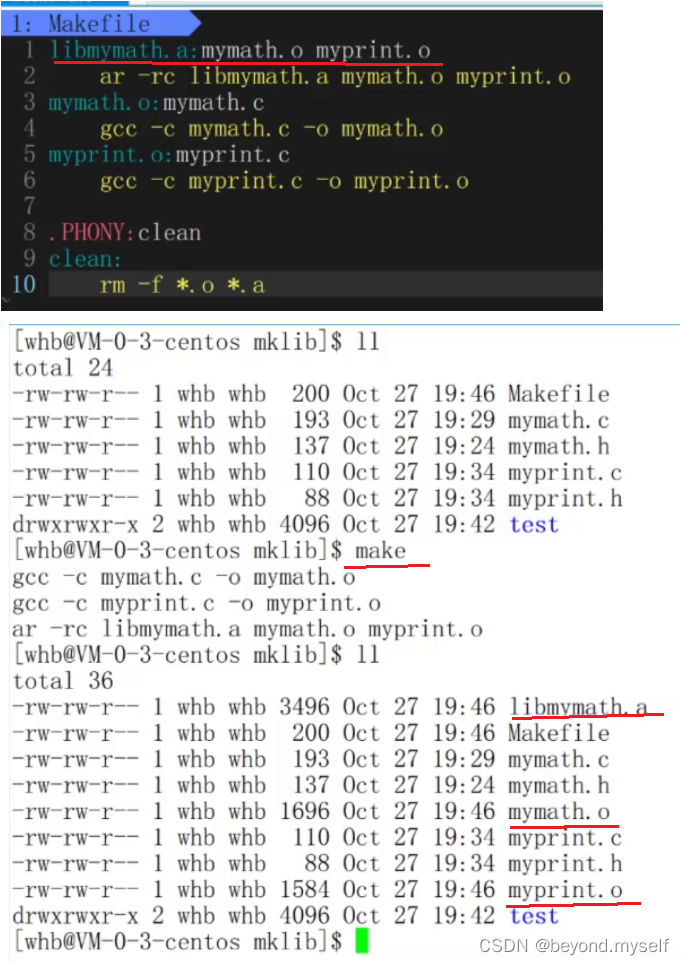
(静态库本质:把源文件.c翻译成.o文件,再把所有.o文件打包起来)
4.—发布静态库
mkdir -p lib-static/ lib 创建一个路径lib-static/ lib
mkdir -p lib-static/ include 创建一个路径lib-static/ include
cp *.a lib-static/lib 把所有.a库文件拷贝进第 lib路径下
cp *.h lib-static/ include 把所有.h头文件拷贝进第 include路径下

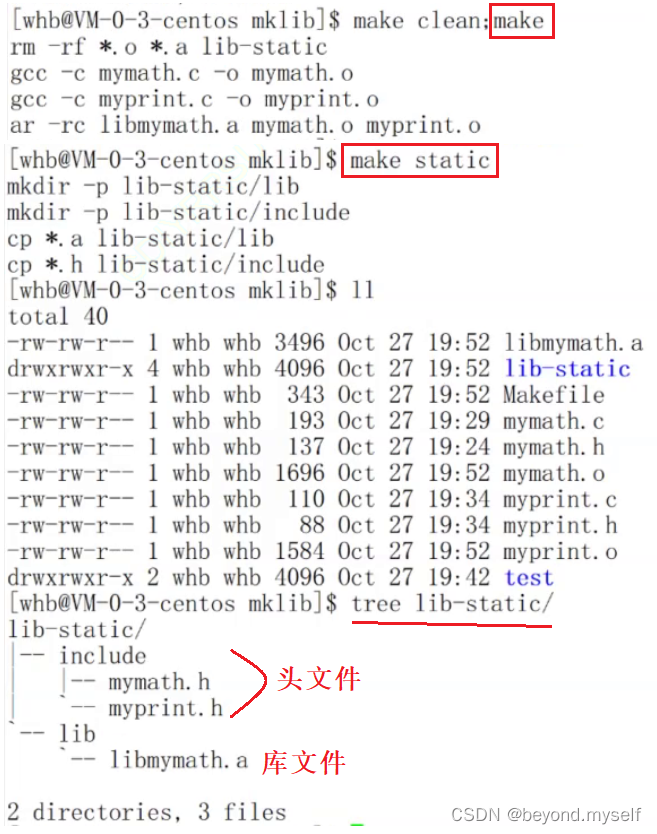
2.生成动态库过程
1.—生成.o文件
gcc -fPIC -c mymath.c -o mymath.o gcc -fPIC 产生的.o文件产生与位置无关码
gcc -shared -o libmymath.so *.o 形成动态库
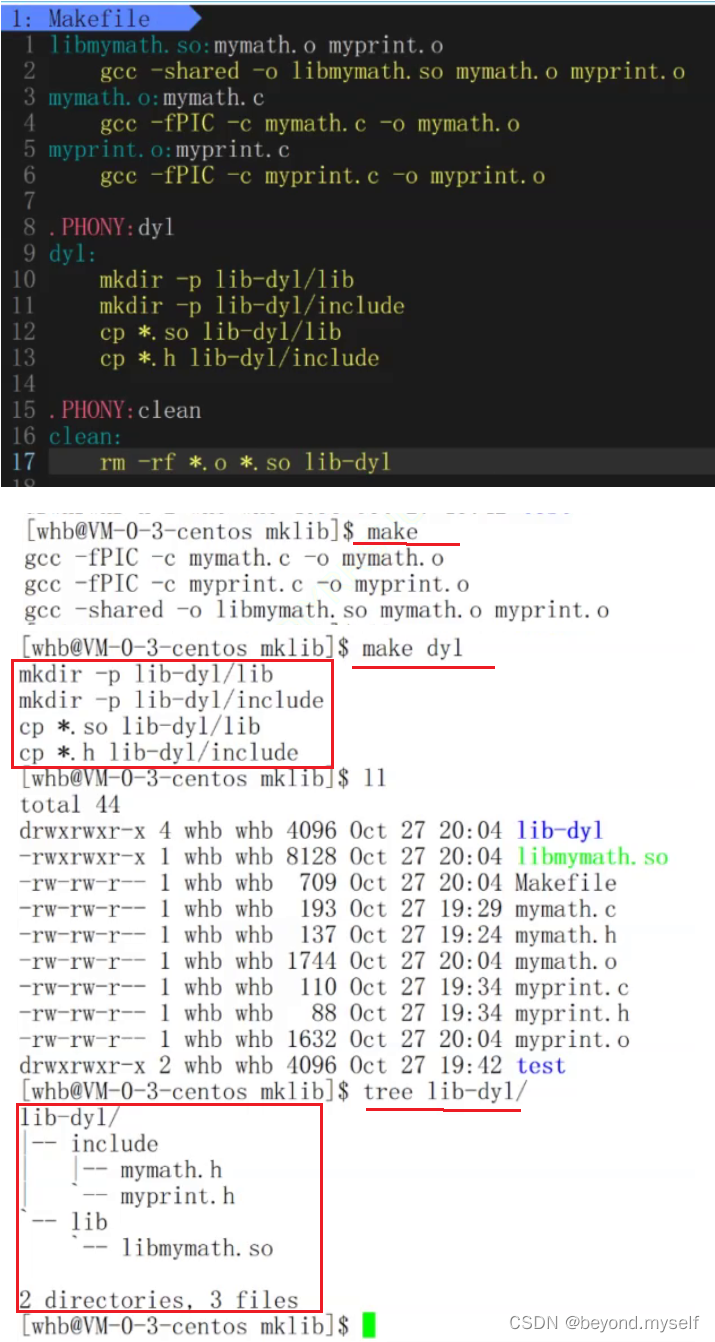
静态库和动态库合并:
下面静态库要把生成的.o文件改一下名,如果.o名字一样,打包时把上面动态库的.o文件打包了,就不执行生成静态库的.o文件了。

.PHONY:all
all: libmymath.so libmymath.a
libmymath.so:mymath.o myprint.o
gcc -shared -o libmymath.so mymath.o myprint.o
mymath.o:mymath.c
gcc -fPIC -c mymath.c -o mymath.o
myprint.o:myprint.c
gcc -fPIC -c myprint.c -o myprint.o
libmymath.a:mymath_s.o myprint_s.o
ar -rc libmymath.a mymath_s.o myprint_s.o
mymath_s.o:mymath.c
gcc -c mymath.c -o mymath_s.o
myprint_s.o:myprint.c
gcc -c myprint.c -o myprint_s.o
.PHONY:lib
lib:
mkdir -p lib-static/lib
mkdir -p lib-static/include
cp *.a lib-static/lib
cp *.h lib-static/include
mkdir -p lib-dyl/lib
mkdir -p lib-dyl/include
cp *.so lib-dyl/lib
cp *.h lib-dyl/include
.PHONY:clean
clean:
rm -rf *.o *.a *.so lib-static lib-dyl 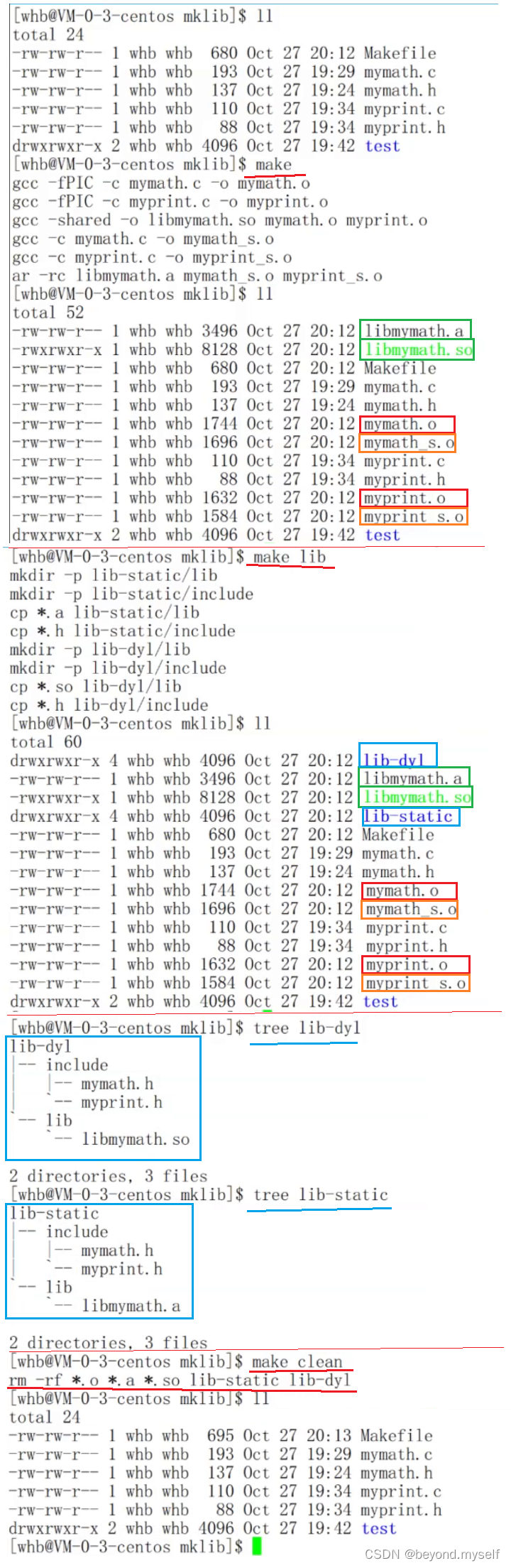
3.使用动静态库
如何使用.a 以及 如何使用. so
头文件的搜索路径: " " <>
- #include <头文件> : 编译器只会从系统配置的库环境中去寻找头文件,不会搜索当前文件夹。通常用于引用标准库头文件。
- #include "头文件" : 编译器会先从当前文件夹中寻找头文件,如果找不到则到系统默认库环境中去寻找。一般用于引用用户自己定义使用的头文件。
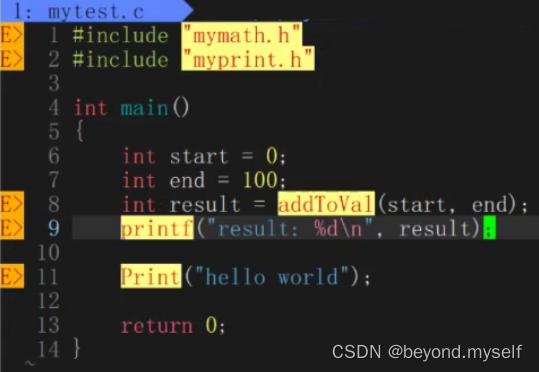
但是自己的头文件和库文件既不在当前路径,又不在系统头文件路径,怎么办?
使自己静态库的头文件和库文件可被找到的方法:
谁在找头文件? 编译器,vs2019, gcc ->进程在找
(1)将自己的头文件和库文件拷贝到系统路径下即可!——库的安装-不推荐,会污染系统库和系统头文件
其实,我们之前没有用过任何第三方库!系统不认识我们自己添加的库,要用gcc mytest.c -l(link 指明我要链接的第三方库的名称) libmymath. a库名称去掉前缀和后缀是mymath

(2)指定路径头文件搜索路径
-I+你的头文件搜索路径(-l是include缩写,表示指定头文件的搜索,中间带不带空格都行) , -L+你的库路径 即可(-L是link缩写,表示指定库的路径,中间带不带空格都行),-l库名 (表示你要链接哪一个库,-l库名之间尽量不带空格,带也没错)
gcc mytest.c -o mytest -I ./lib-static/include/ -L ./lib-static/lib/ -lmymath


使自己静态库的头文件和库文件可被找到的方法:
(1)和静态库一样操作:将自己的头文件和库文件拷贝到系统路径下
(2)和静态库不太一样的操作:指定路径头文件搜索路径
和静态库一样指定路径头文件搜索路径的操作却无法通过 gcc mytest.c -o mytest -I ./lib-static/include/ -L ./lib-static/lib/ -lmymath
(ldd查看程序依赖的库)
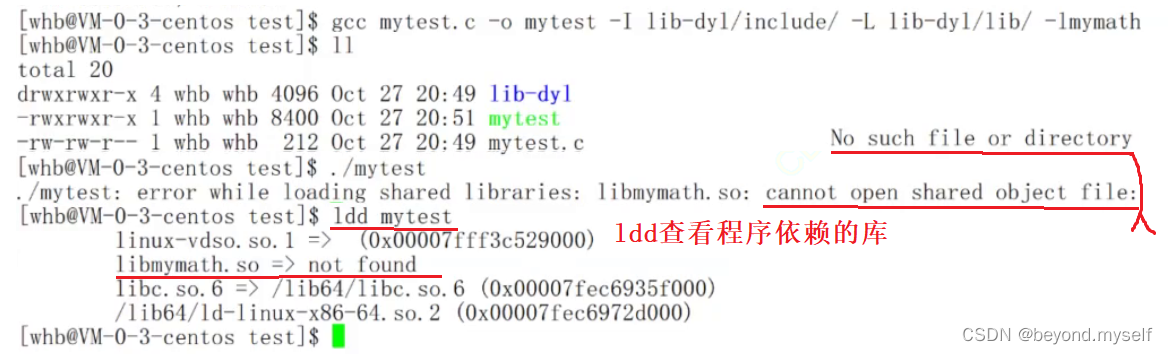
原因: gcc mytest.c -o mytest -I ./lib-static/include/ -L ./lib-static/lib/ -lmymath 只是告诉gcc这个编译器动态库在哪,当./mytest变成进程后,进程还是找不到动态库

①那么静态库的时候,怎么没有这个问题呢? ?——因为静态库在形成可执行程序之后,已经把需要的代码拷贝进我的代码中,运行时,不依赖你的库! 则不需要运行时查找
②为什么动态库会有这个问题? ——在本大标题的第4条解释,程序和动态库,是分开加载的!
如何解决动态库这个问题?想办法让进程找到动态库即可!
① 将动态库拷贝到系统路径下:lib64-- 安装的过程,进程链接和运行都能找到这个库
② 通过导入环境变量的方式——程序运行的时候,会在环境变量中查找自己需要的动态库路径-- 环境变量:LD_ LIBRARY_ PATH
→1 先找动态库的绝对路径:

→ 2 (放大图)把库的路径加入环境变量LD_ LIBRARY_ PATH中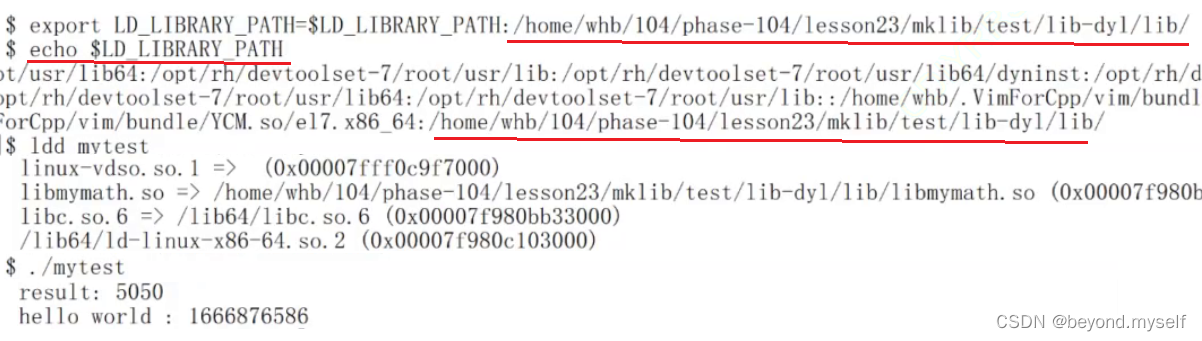
这是全览图:
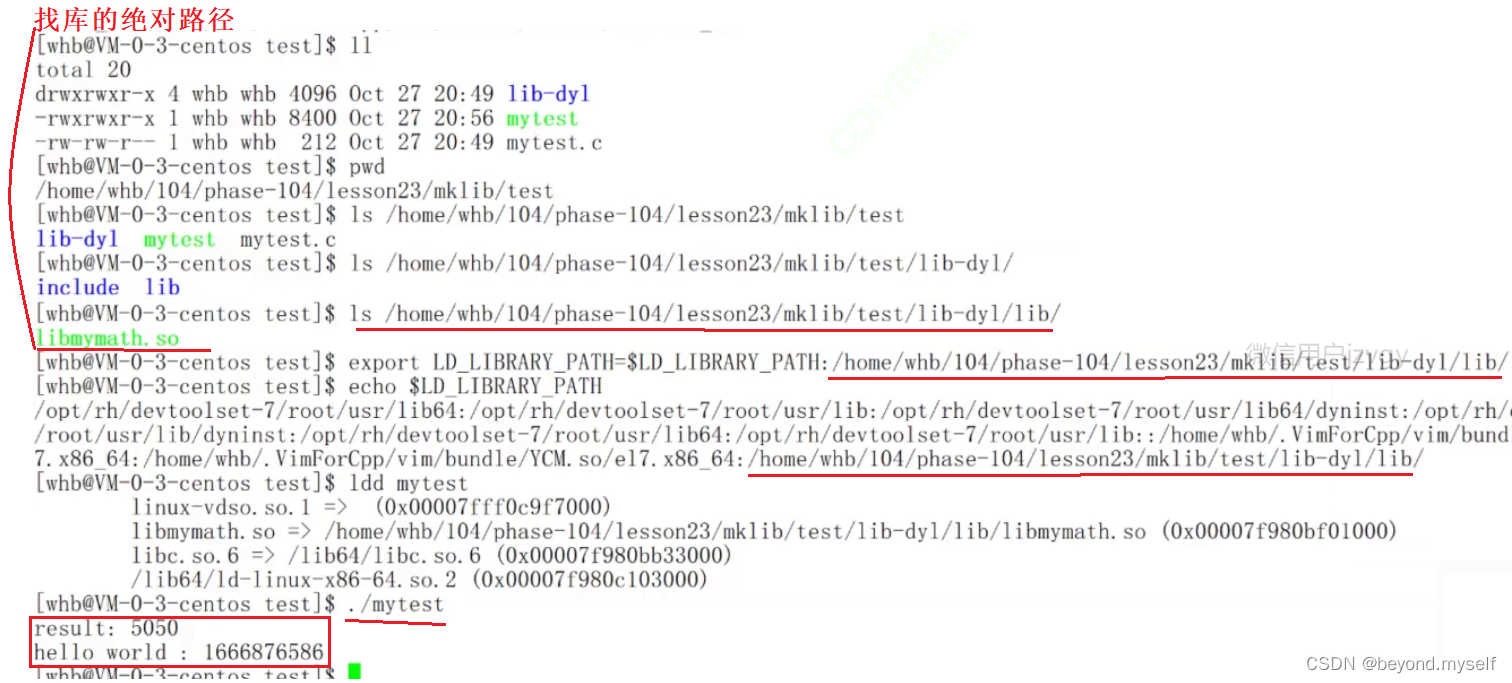
手动改变环境变量是内存级的,重启xshell读的是配置文件中最原始的环境变量,我们改的环境变量LD_ LIBRARY_ PATH就没了。只能通过③ 系统配置文件来做
③ 在系统配置文件中添加库路径来做,即可让程序运行时找到库
/etc/ld.so.conf.d/ 这个系统路径下表明系统中如果自定义了动态库,系统在扫描系统路径时,除了扫描系统库路径对应的库之外,还会读取下面的配置文件内容,找到动态库。(这些配置文件非常简单,cat 一下,发现这些配置文件就是路径)
[zsh@ecs-78471 11-1]$ ls /etc/ld.so.conf.d/
bind-export-x86_64.conf kernel-3.10.0-1160.53.1.el7.x86_64.conf kernel-
3.10.0-957.el7.x86_64.conf mariadb-x86_64.conf
sudo ldconfig ldconfig:让配置文件生效——>ldconfig会把配置文件加载到系统对应的内存空间里,我们就能找到这个配置文件了
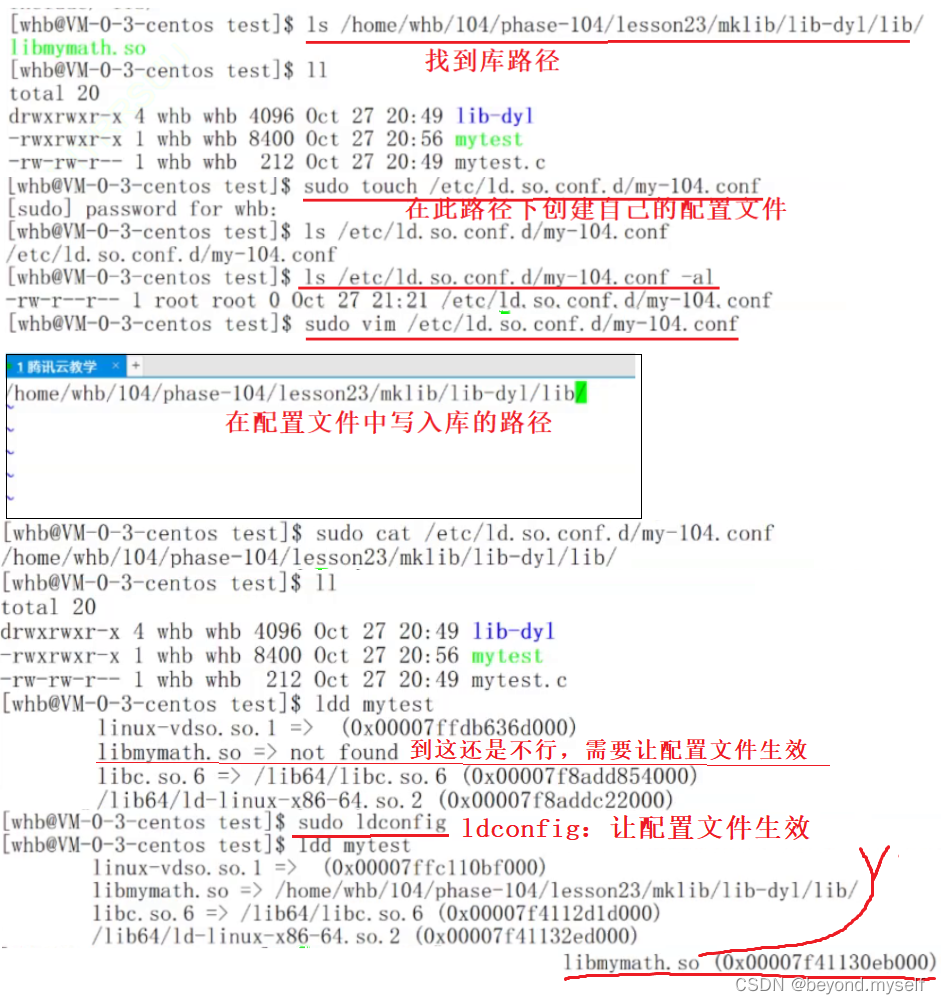
删除配置文件:sudo rm /etc/ld. so. conf. d/my-104. conf
④ 软连接方案
在系统路径lib64中建立库的软连接,因为头文件在当前路径/系统路径下都会找到,但库文件只能在系统路径下找

头文件在当前路径/系统路径下都会找到,但库文件只能在系统路径下找:库文件在当前路径下建立软连接进程就找不到

4.动态链接的过程
回答为什么动态库指定路径头文件搜索路径时,进程找不到对应的动态库?在下面
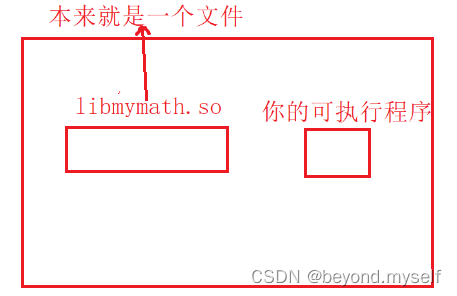
因为我的可执行程序是动态链接,和动态库产生了关联,可执行程序中有代码是需要跳转到库中运行的。跳转到库中运行的前提条件:必须将你的库加载到内存中
将自己的库加载到内存中后,页表会把内存中的库映射到进程的虚拟地址空间中的共享区中。则在自己的地址空间中,就可以执行所有的代码(自己的和库的)
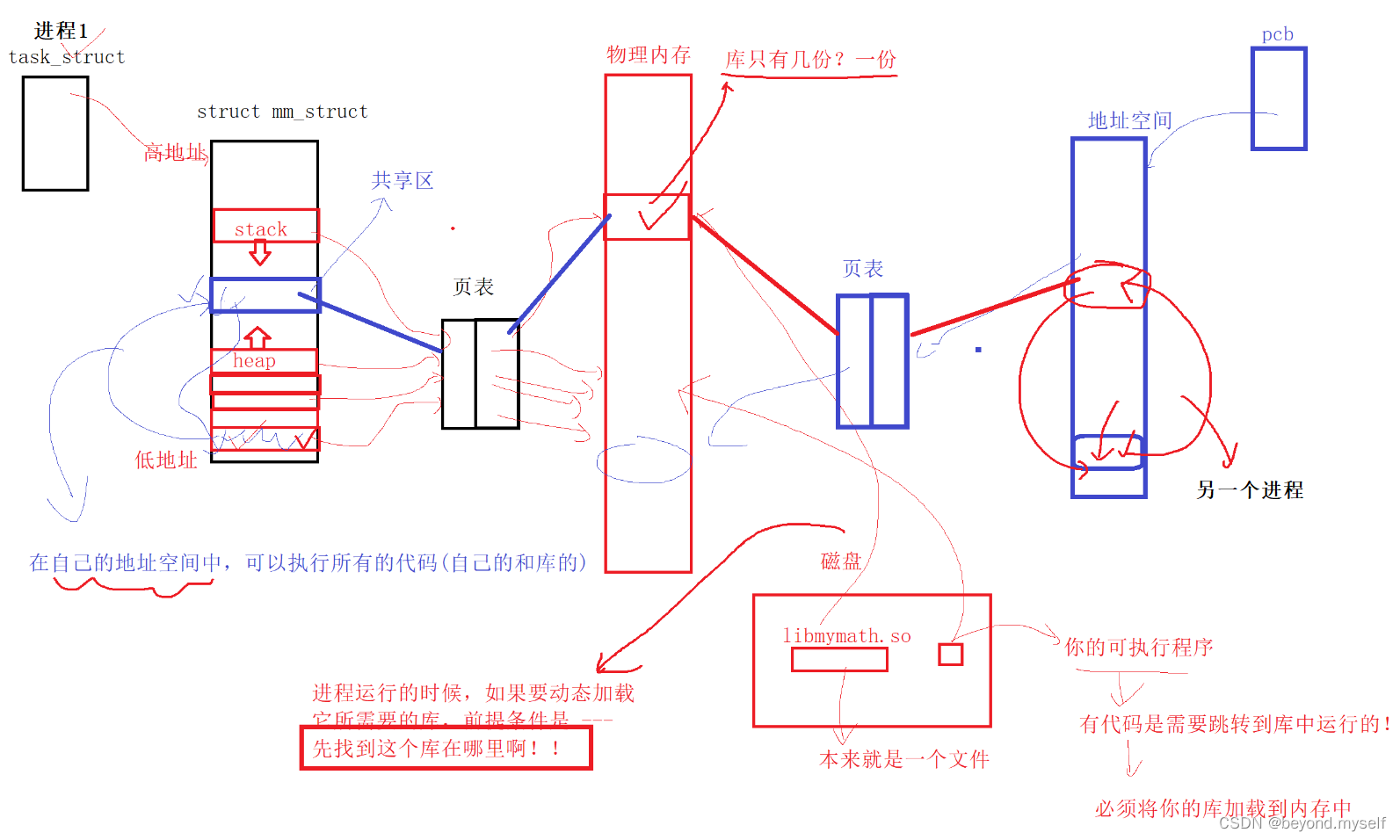
动态库叫共享库:因为动态库在运行期间,可以被多个进程共享
回答为什么动态库指定路径头文件搜索路径时,进程找不到对应的动态库?
答:——因为 程序和动态库,是分开加载的。进程在运行的时候,要动态加载它所需要的库。将自己的库加载到内存中后,页表会把内存中的库映射到进程的虚拟地址空间中的共享区中。然后在自己的地址空间中,才能执行自己和库的代码。但是加载动态库的前提条件 是先找到这个库在哪里。上面因为进程找不到动态库,所以进程无法把动态库加载到内存,导致进程的虚拟地址空间中的共享区中没有映射的库,最终无法执行自己和库的代码——>进程退出。
在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
ncurses -- linux下的图形界面库--yum安装 ncurse 库 sudo yum install -y ncurses -devel
boost库--安装一下 sudo yum install -y boost-devel