使用 Ray 处理NYC Taxi数据集
本教程将介绍:
- 读取 Parquet 数据
- 查看大型 Ray 数据集的元数据
- 计算数据集的一些常见全局和分组统计信息
- 删除列和行
- 添加派生列
- 清洗数据集
- 将数据集分片并将其提供给并行消费者(训练器)
- 将批量(离线)推断应用于数据
本案例的环境为Anaconda建立的名为RayAIR的环境,具体创建过程见以下链接的第2节:《机器学习框架Ray -- 1.3 Ray Clusters与Ray AIR的基本使用》。
为了在ipynb中可视化rich notebook output,需要安装ipywidges。可视化进度条需要安装tqdm。
pip install ipywidgets -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tqdm首先导入Ray,并启动local Ray Cluster
import ray
ray.init()1. 1 读取和检查数据
从数据集中读取文件。这种读取是惰性的,其中读取和所有未来的转换都会延迟,直到下游操作触发执行(例如使用 ds.take() 消费数据)。可以使用流式处理的方式处理整个数据集(或者使用多节点 Ray 集群并行处理所有数据,但将在large-scale examples中介绍这些内容)。
数据集是从AWS的S3数据桶中下载,下载速度视网络波动在1min至10min不等。
# Read two Parquet files in parallel.
# 用时视网络情况,约1-10 min
ds = ray.data.read_parquet([
"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_01_data.parquet",
"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_02_data.parquet"
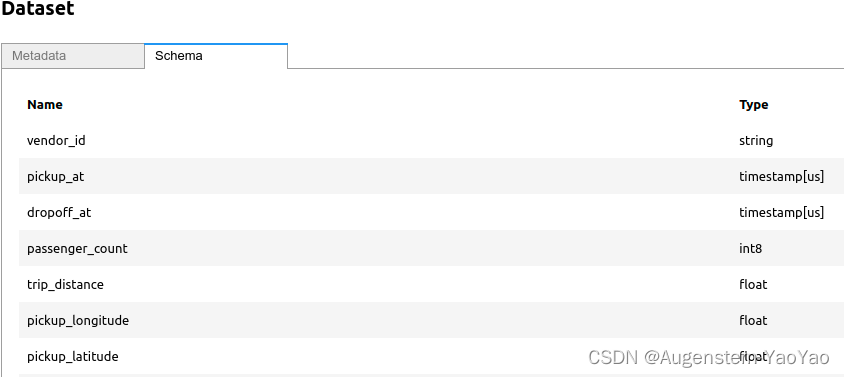
])可以轻松查看此数据集的模式。对于 Parquet 文件,不必读取实际数据即可获取模式;可以从轻量级 Parquet 元数据中读取。
# 从底层Parquet元数据获取模式
ds.schema()
# .schema()用于获取数据集的模式或结构
输出如下:
vendor_id: string
pickup_at: timestamp[us]
dropoff_at: timestamp[us]
passenger_count: int8
trip_distance: float
pickup_longitude: float
pickup_latitude: float
rate_code_id: null
store_and_fwd_flag: string
dropoff_longitude: float
dropoff_latitude: float
payment_type: string
fare_amount: float
extra: float
mta_tax: float
tip_amount: float
tolls_amount: float
total_amount: float
-- schema metadata --
pandas: '{"index_columns": [{"kind": "range", "name": null, "start": 0, "' + 2524NYC Taxi 数据集是一个关于纽约市出租车行程的数据集,其中包含以下字段:
- vendor_id:字符串类型,代表出租车供应商的标识符。
- pickup_at:微秒级时间戳类型,代表乘客上车的时间。
- dropoff_at:微秒级时间戳类型,代表乘客下车的时间。
- passenger_count:int8 类型,表示此次行程的乘客数量。
- trip_distance:float 类型,表示行程的距离(单位:英里)。
- pickup_longitude:float 类型,表示上车地点的经度。
- pickup_latitude:float 类型,表示上车地点的纬度。
- rate_code_id:空值,表示费率代码的标识符(本数据集中未使用)。
- store_and_fwd_flag:字符串类型,表示行程记录是否在车载设备中存储并稍后转发。
- dropoff_longitude:float 类型,表示下车地点的经度。
- dropoff_latitude:float 类型,表示下车地点的纬度。
- payment_type:字符串类型,表示付款方式(例如:现金、信用卡)。
- fare_amount:float 类型,表示行程的基本费用。
- extra:float 类型,表示额外费用(如:夜间附加费)。
- mta_tax:float 类型,表示应用于此次行程的 Metropolitan Transportation Authority 税。
- tip_amount:float 类型,表示乘客支付的小费金额。
- tolls_amount:float 类型,表示行程中的过路费金额。
- total_amount:float 类型,表示总金额(包括费用、附加费、税收、小费和过路费)。
可以使用ds.count()获得元数据行数,无需完整读取元数据。
ds.count()输出为NYC Taxi的数据集行数

2749842可以通过ds直接查看元数据信息。
ds输出在VS code中安装ipywidges插件时,显示为
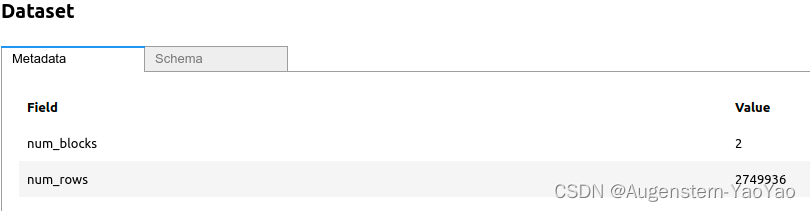
或者直接显示为
Dataset(num_blocks=2, num_rows=2749936, schema={vendor_id: string, pickup_at: timestamp[us], dropoff_at: timestamp[us], passenger_count: int8, trip_distance: float, pickup_longitude: float, pickup_latitude: float, rate_code_id: null, store_and_fwd_flag: string, dropoff_longitude: float, dropoff_latitude: float, payment_type: string, fare_amount: float, extra: float, mta_tax: float, tip_amount: float, tolls_amount: float, total_amount: float})可以查看单行数据,由于这只返回来自第一个文件的一行,因此尚未触发第二个文件的读取。
ds.take(1)输出为
[{'vendor_id': 'VTS',
'pickup_at': datetime.datetime(2009, 1, 21, 14, 58),
'dropoff_at': datetime.datetime(2009, 1, 21, 15, 3),
'passenger_count': 1,
'trip_distance': 0.5299999713897705,
'pickup_longitude': -73.99270629882812,
'pickup_latitude': 40.7529411315918,
'rate_code_id': None,
'store_and_fwd_flag': None,
'dropoff_longitude': -73.98814392089844,
'dropoff_latitude': 40.75956344604492,
'payment_type': 'CASH',
'fare_amount': 4.5,
'extra': 0.0,
'mta_tax': None,
'tip_amount': 0.0,
'tolls_amount': 0.0,
'total_amount': 4.5}]为了更好地了解数据大小,可以计算完整数据集的字节大小。
请注意,对于Parquet文件,这个大小(以字节为单位)将从Parquet元数据中获取(不触发数据读取),因此可能与内存中的大小有很大差异!
为了获得内存中的大小,可以触发完整的数据集读取并检查字节大小。
ds.size_bytes()输出元数据的字节数,为226263578字节。
2262635781.2 高级提示 - 读取分区Parquet数据集
除了能够读取多个单独文件的列表之外,ray.data.read_parquet()(以及其他ray.data.read_*() API)可以读取包含多个Parquet文件的目录。特别是对于Parquet来说,支持按特定列分区的Parquet数据集的读取,这样可以进行基于路径的(零读取)分区过滤,并在路径中直接包含文件路径中指定的分区列值的已读表数据。
对于NYC Taxi数据集,可以读取整个2009年的目录,而不是逐月读取Parquet文件。2009年的数据集以0.01的比例下采样时,磁盘上占用为50.2 MB,内存中约147 MB,因此请谨慎在内存有限的计算机上触发完整读取!这是数据集Lazy reading的一个优点:数据集不会急切地执行任何读取任务,将执行最少数量的文件读取以满足下游操作的要求,这使我们能够在无需读取整个数据集的情况下检查数据的子集。
# Read all Parquet data for the year 2009.
year_ds = ray.data.read_parquet("s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_full_year_data.parquet")数据集在其repr中打印的元数据保证不触发所有文件的读取;诸如行数和模式之类的数据是直接从Parquet元数据中获取的。
year_ds.count()计算2009年的数据集的行数,结果为1710629。
1710629删除数据的方法为
del year_ds2.1 数据分析和清理
计算一些统计数据以更好地了解数据。
1)计算极值
计算最长的行程距离,最大的小费金额和最多的乘客数量是多少
ds.max(["trip_distance", "tip_amount", "passenger_count"])计算结果为
{'max(trip_distance)': 50.0,
'max(tip_amount)': 100.0,
'max(passenger_count)': 6}2)删除指定列
删除store_and_fwd_flag或mta_tax列:
ds = ds.drop_columns(["store_and_fwd_flag", "mta_tax"])3)按照指定键值计数
假设我们想知道每个乘客数量对应的行程次数。统计每个不同的乘客数量(例如:1个乘客,2个乘客,3个乘客等)分别有多少次行程。通过这种统计,我们可以更好地了解数据集中的行程分布。
ds.groupby("passenger_count").count().take()输出为
[{'passenger_count': -48, 'count()': 3},
{'passenger_count': 0, 'count()': 91},
{'passenger_count': 1, 'count()': 1865548},
{'passenger_count': 2, 'count()': 451452},
{'passenger_count': 3, 'count()': 119406},
{'passenger_count': 4, 'count()': 55547},
{'passenger_count': 5, 'count()': 245332},
{'passenger_count': 6, 'count()': 12557}]其中,出现负数乘客数量(如 -48)的原因可能是数据收集过程中的错误,或者是数据中的异常值。在现实生活中,负数乘客数量是不合理的。因此,在对数据进行分析和预处理时,我们需要注意这些异常值并对其进行处理,例如过滤掉负数乘客数量的记录。这样可以确保我们在进行分析和建模时使用的数据是有效的和准确的。
4)过滤异常值
假设想知道每个乘客数量有多少趟行程。 同样,看起来还有一些荒谬的乘客数量,即负数。让我们也过滤掉这些。过滤掉负乘客数的记录。
ds = ds.map_batches(lambda df: df[df["passenger_count"] > 0])5)数据分组
判断乘客数量是否影响典型的行程距离,需要按乘客数量分组的平均行程距离。
ds.groupby("passenger_count").mean("trip_distance").take()输出为
[{'passenger_count': 1, 'mean(trip_distance)': 2.543288084787955},
{'passenger_count': 2, 'mean(trip_distance)': 2.7043459216040686},
{'passenger_count': 3, 'mean(trip_distance)': 2.6233412684454716},
{'passenger_count': 4, 'mean(trip_distance)': 2.642096445352584},
{'passenger_count': 5, 'mean(trip_distance)': 2.6286944833939314},
{'passenger_count': 6, 'mean(trip_distance)': 2.5848625579855855}]2.2 投影和过滤下推(Projection and Filter Pushdown)
Projection和Filter Pushdown是数据存储和查询优化技术,通常用于大规模的列式存储格式(如Parquet)和数据库系统。这些技术可以提高查询性能,减少I/O开销,并降低计算资源的消耗。
-
Projection(投影):投影指的是仅选择所需的列,而不是读取整个数据表。当我们对大型数据集进行查询时,通常只需要一部分列来完成任务。通过仅读取所需的列,可以减少从磁盘读取数据的时间和资源消耗。在Parquet等列式存储格式中,投影操作可以在读取时直接应用,避免不必要的I/O操作。
-
Filter Pushdown(过滤下推):过滤下推是指将过滤条件应用到数据存储层,而不是在数据加载到计算引擎之后再进行过滤。这样可以减少从存储层读取的数据量,从而降低I/O开销。当数据存储系统能够识别和执行过滤条件时,过滤下推可以显著提高查询性能。
在使用Ray Datasets等数据处理库处理Parquet文件时,可以利用这些优化技术来提高数据读取和处理的性能。例如,当我们从Parquet文件中读取数据时,可以在读取时指定所需的列(投影)和行过滤条件(过滤下推),从而避免不必要的I/O操作和计算资源消耗。请注意,Ray数据集的Parquet阅读器支持投影(列选择)和行过滤下推,可以将上述列选择和基于行的过滤推送到Parquet读取。如果在Parquet读取时指定列选择,那么未选择的列甚至不会从磁盘上读取。基于行的过滤器是通过Arrow的数据集字段表达式指定的。有关更多信息,请参阅读取Parquet数据的功能指南。
# Only read the passenger_count and trip_distance columns.
import pyarrow as pa
filter_expr = (
(pa.dataset.field("passenger_count") <= 10)
& (pa.dataset.field("passenger_count") > 0)
)
pushdown_ds = ray.data.read_parquet(
[
"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_01_data.parquet",
"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_02_data.parquet",
],
columns=["passenger_count", "trip_distance"],
filter=filter_expr,
)
# Force full execution of both of the file reads.
pushdown_ds = pushdown_ds.fully_executed()
pushdown_ds输出为


删除下推数据集。删除数据集对象。将释放集群中的底层内存。
del pushdown_ds3. 摄取至模型训练器
将这个数据集输入到一些虚拟模型训练器中。首先,对数据集进行全局随机洗牌,以消除这些样本之间的相关性。
ds = ds.random_shuffle()定义一个虚拟训练器actor,其中每个训练器将批量消费数据集分片并模拟模型训练。在真实的训练工作流中,我们将把数据集ds传递给Ray Train,它会在后台为我们进行数据分片和创建训练actor。
@ray.remote
class Trainer:
def __init__(self, rank: int):
pass
def train(self, shard: ray.data.Dataset) -> int:
for batch in shard.iter_batches(batch_size=256):
pass
return shard.count()
trainers = [Trainer.remote(i) for i in range(4)]
trainers这个代码中的Trainer类只是一个示例,用于展示如何将数据集划分为多个shard并将其传递给多个Trainer实例。在这个例子中,train方法没有实际的训练过程,仅为dummy model trainers,简单地遍历了数据shard的批次。
输出为
[Actor(Trainer, 795f130bcefdde5dcb84643901000000),
Actor(Trainer, 93126200e1a813962a70068a01000000),
Actor(Trainer, 463c88ce3eb501a455ebfbdb01000000),
Actor(Trainer, 429a0ee80ff248985bee6d1401000000)]接下来,将数据集分成与训练器数量相等的分片,确保每个分片的大小相等。
shards = ds.split(n=len(trainers), equal=True)
shards输出为
[Dataset(num_blocks=1, num_rows=687460, schema={vendor_id: object, pickup_at: datetime64[ns], dropoff_at: datetime64[ns], passenger_count: int8, trip_distance: float32, pickup_longitude: float32, pickup_latitude: float32, rate_code_id: object, dropoff_longitude: float32, dropoff_latitude: float32, payment_type: object, fare_amount: float32, extra: float32, tip_amount: float32, tolls_amount: float32, total_amount: float32}),
...
Dataset(num_blocks=1, num_rows=687460, schema={vendor_id: object, pickup_at: datetime64[ns], dropoff_at: datetime64[ns], passenger_count: int8, trip_distance: float32, pickup_longitude: float32, pickup_latitude: float32, rate_code_id: object, dropoff_longitude: float32, dropoff_latitude: float32, payment_type: object, fare_amount: float32, extra: float32, tip_amount: float32, tolls_amount: float32, total_amount: float32})]最后,我们模拟训练过程,将每个分片传递给相应的训练器。返回的结果是每个分片的行数。
ray.get([w.train.remote(s) for w, s in zip(trainers, shards)])输出为
[687460, 687460, 687460, 687460]4. 并行批量推理
在我们训练好一个模型之后,我们可能需要在这样的表格数据集上进行批量(离线)推理。通过Ray Datasets,这就像一个ds.map_batches()调用一样简单!
首先,我们定义一个可调用的类,它将在其构造函数中缓存模型的加载。
import pandas as pd
def load_model():
# A dummy model.
def model(batch: pd.DataFrame) -> pd.DataFrame:
return pd.DataFrame({"score": batch["passenger_count"] % 2 == 0})
return model
class BatchInferModel:
def __init__(self):
self.model = load_model()
def __call__(self, batch: pd.DataFrame) -> pd.DataFrame:
return self.model(batch)在使用ds.map_batches()中的actor池计算策略时,BatchInferModel的构造函数仅在每个actor工作器上调用一次。
ds.map_batches(BatchInferModel, batch_size=2048, compute="actors").take()如果想在GPU上执行批量推理,只需指定每个批量推理工作器提供的GPU数量。
ds.map_batches(
BatchInferModel,
batch_size=256,
#num_gpus=1, # 若使用GPU进行计算推理,请取消本行注释
compute="actors",
).take()推理结果为
[{'score': False},
{'score': True},
{'score': False},
...
{'score': False},
{'score': True}]我们还可以配置这个推理阶段使用的自动缩放actor池,设置actor池大小的上限和下限,甚至调整批量预取与推理任务排队之间的权衡。
from ray.data import ActorPoolStrategy
# actor池至少有2个工作器,最多有8个工作器。
strategy = ActorPoolStrategy(min_size=2, max_size=8)
ds.map_batches(
BatchInferModel,
batch_size=256,
num_gpus=1, # Uncomment this to run this on GPUs!
compute=strategy,
).take()以上代码中,首先从ray.data导入ActorPoolStrategy。然后,定义了一个策略,设置了actor池的最小大小为2,最大大小为8。调用ds.map_batches()方法,传入BatchInferModel、batch_size=256和计算资源分配策略strategy。最后,使用.take()方法获取推理结果。
输出结果为
{'score': False},
{'score': True},
...
{'score': False},
{'score': True}]