目录
这个系列的其他文章:
CrateDB初探(一):CrateDB集群的Docker部署
CrateDB初探(四):乐观并发控制 (Optimistic Concurrency Control )
分区
官方文档:PARTITIONED TABLES
A partitioned table is a virtual table that can be created by naming one or more columns by which it is split into separate internal tables, called
partitions.
分区表是一个虚拟表,它被分割为独立的内部表
基本语法
CREATE TABLE parted_table (
id bigint,
title text,
content text,
width double precision,
day timestamp with time zone
) PARTITIONED BY (day);
如果表中存在主键,那么主键必须被包括在分区值中,且不能包含非主键列
(1)异常: 存在单主键,但分区列为非主键

(2)异常:存在单主键,分区列为主键+非主键
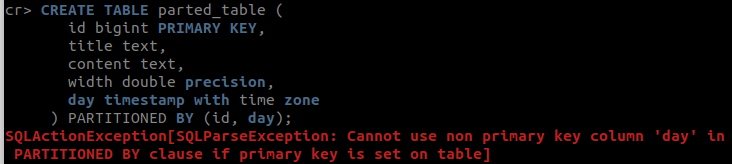
(3)正常:存在单主键,分区列为主键

(3)正常:多主键,以全部主键或者部分主键为分区列

查看分区信息
SELECT table_schema as schema,
table_name,
number_of_shards as num_shards,
number_of_replicas as num_reps,
clustered_by as c_b,
partitioned_by as p_b,
blobs_path
FROM information_schema.tables
WHERE table_name='parted_table';
(这里分片数num_shards是系统设置的)
通过information_schema.table_partitions查看目前表的分区,由于没有数据,分区数为0

插入数据,并查看分区情况。
INSERT INTO parted_table (id, title, width, day)
VALUES (1, 'Don''t Panic', 19.5, '2014-04-08'),
(2, '12345', 20.0, '2014-04-08'),
(3, '67890', 21.0, '2019-10-01'),
(4, '00000', 22.1, '2020-03-12');
SELECT partition_ident, "values", number_of_shards
FROM information_schema.table_partitions
WHERE table_schema = 'doc' AND table_name = 'parted_table'
ORDER BY partition_ident;
根据day列分区,目前有三个分区,每个分区又有6个分片(分片数是db自动设置的,如何设置分片数下面会介绍)

控制台上的可视化结果

限制
分区列的值不能被更新,会抛异常

查询
查询时最好带上分区列,这样db会过滤分区,提高查询效率
UPDATE,DELETEandSELECTqueries are all optimized to only affect as few partitions as possible based on the partitions referenced in theWHEREclause.
分片
官方文档:SHARDING
Shards are then distributed across the cluster. As nodes are added to the cluster, CrateDB will move shards around to achieve maximum possible distribution.
表分片后每个shard在集群上分布。集群在动态增加节点后,cratedb会调整shards在各节点上的分布,以达到可能的最大化分布。对用户来说,在查询时并不用关心sharding,在表级别(table-level) sharding对用户是透明的,
基本语法
CLUSTERED INTO <number> SHARDS
注意:分片数可以在运行时调整,但是在调整结束前此表会是read-only状态。
![]()
注意:上述方式,对于分区表(partitioned table)分片数量调整只针对新分区,对于已经存在的分区没有影响。
如果要对已存在的分区进行调整,需要指定分区
ALTER TABLE parted_table PARTITION (day=1396915200000) SET (number_of_shards = 5)路由(routing)的语法
通过routing column来计算表中每一行属于哪个shard,这个routing column可以在建表时制定。
CLUSTERED BY (<column>)
CREATE TABLE tmp_table (
id bigint,
title text,
content text,
width double precision,
day timestamp with time zone
) CLUSTERED BY (title) INTO 3 SHARDS;
如果设置了主键,路由列可以忽略,cratedb默认通过主键进行routing
如果设置了路由列,且存在主键,那么路由列必须包含一个主键,官方示例:
create table my_table9 (
first_column integer primary key,
second_column text primary key,
third_column text
) clustered by (first_column) into 3 shards;控制台可见分片结果

确定分片数量
官方文档:SHARDING GUIDE (best practice guide for CrateDB)
shards数量与数据类型,查询类型与硬件类型有关(type of data you're processing, the types of queries you're running, and the type of hardware you're using.)
根据官方文档,设置与集群能用到的CPUs个数相同或者略超过(a little over-allocation) CPUs的shards数量是比较合理的,
但是,当大多数节点的表均shards(shards per table) 超过了他们能用到的CPUs数量时,性能会下降。
If you have fewer shards than CPUs in the cluster, this is called under-allocation, and it means you're not getting the best performance out of CrateDB.
A little over-allocation is desirable. But if you significantly over-allocate your shards per table, you will see performance degradation.
When you have slightly more shards per table than CPUs, you ensure that query workloads can be parallelized and distributed maximally, which in turn ensures maximal query performance.
However, if most nodes have more shards per table than they have CPUs, you could actually see performance degradation.
懒人做法:
根据每个nodes有两个CPUs的假设,让CrateDB来做决定(猜测)
If you don't manually set the number of shards per table, CrateDB will make a best guess, based on the assumption that your nodes have two CPUs each.
副本
什么是Replication
Replication指的是每个主分片(primary shard)额外储存了N份副本. Replication是为了增加数据库读的性能以及实现高可用.
Replication of a table in CrateDB means that each primary shard of a table is stored additionally on so called secondary shards. This can be useful for better read performance and high availability.
控制台对sharding的可视化 ,my_table9每个分片有两个副本,其中一个是primary shard

information_schema.tables查看上面my_table9这个表的num_reps列为0-1复制,这个是cratedb的默认设置

基本语法
在新建表时可以设置副本数,当设置为0时可以在控制台看到只有一个主shard
create table my_table10 (
first_column integer,
second_column text
) with (number_of_replicas = 0);
可以对副本个数进行动态调整,例如将表my_table10的副本数设置为1个,那么除了一个主分片还有一个额外的副本
ALTER TABLE ONLY my_table10 SET (number_of_replicas = 1);

