浅谈RAID写惩罚(Write Penalty)与解决方案闪存荷尔蒙(FlashHormone)
介绍
通常在讨论不同RAID保护类型的性能的时候,结论都会是RAID-1提供比较好的读写性能,RAID-5读性能不错,但是写入性能就不如RAID-1,RAID-6保护级别更高,但写性能相对更差,RAID10是提供最好的性能和数据保护,不过成本最高等等。其实决定这些性能考虑的因素很简单,它就是RAID Write Penalty(写惩罚)。
RAID5的三种写方式
- 整条写(Full Stripe Write)
如果一次磁盘写操作的数据正好映射满一个Stripe,则相应的校验值可根据新的数据块的值就直接计算出来,该过程可以在RAID的缓存中直接完成。整条写不需要任何多余的读操作,是RAID5中效率最高的一种写操作。
- 重构写(Reconstruct Write)
如果一次写磁盘的数据包括一个Stripe中的多数个数据块时,则在产生新的校验信息时必须先将没有更新的数据读到缓存中,计算出新的校验信息,然后将新用户数据与新校验信息一起写到磁盘的相应位置。重构写比整条写多一个读旧数据操作,所以其效率比整条写低。
- 读改写(Read-Modify-Write)
如果一次写磁盘的数据包括一个Stripe中的极小部分数据块时,为计算新的校验值,需要先读出Stripe中即将被更新旧数据、旧校验信息,然后与新数据计算校验信息,再将新数据和新校验信息一起写到磁盘上,该操作称为"读改写".
写效率排列顺序为:整条写>重构写>读改写
RAID-5 Write Penalty的例子
存储方案规划的过程中,最基本的考虑因素有两个,性能和容量。性能上的计算看可以分为IOPS和带宽需求。计算IOPS,抛开存储阵列的缓存和前端口不谈。计算后端物理磁盘的IOPS不能简单的把物理磁盘的最大IOPS相加而获得。原因是,对于不同的RAID级别,为了保证当有物理磁盘损坏的情况下可以恢复数据,数据写入的过程中都需要有一些特别的计算。比如RAID-5,条带上的任意磁盘上的数据改变,都会重新计算校验位。如下图所示,一个7+1的RAID-5的条带中,7个磁盘存储数据,最后一个磁盘存储校验位。
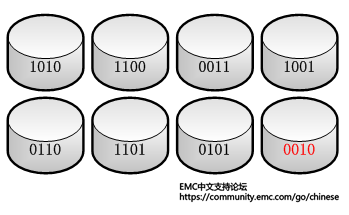
对于一个数据的写入,我们假设在第五个磁盘上写入的数据为1111,如下图所示,整个RAID-5需要完成写入的过程分为以下几步:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2izlVv0p-1675673955613)(null)]](https://img-blog.csdnimg.cn/772d0c8e9b7f440b96ac15d5bcf16b30.png)
- 读取原数据0110,然后与新的数据1111做XOR操作:0110 XOR 1111 = 1001。
- 读取原有的校验位0010。
- 用第一步算出的数值与原校验位再做一次XOR操作:0010 XOR 1001 = 1011。
- 然后将1111新数据写入到数据磁盘,将第三步计算出来的新的校验位写入校验盘。
由上述几个步骤可见,对于任何一次写入,在存储端,需要分别进行两次读+两次写,所以说RAID-5的写惩罚为4
不同RAID级别的Write Penalty
| RAID | Write Penalty |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 5 | 4 |
| 6 | 6 |
| 10 | 2 |
RAID-0:直接的条带,数据每次写入对应物理磁盘上的一次写入
RAID-1和10:RAID-1和RAID-10的写惩罚很简单理解,因为数据的镜像存在的,所以一次写入会有两次
RAID-5:RAID-5由于要计算校验位的机制存在,需要读数据、读校验位、写数据、写校验位四个步骤,所以RAID5的写惩罚值是4
RAID-6:RAID-6由于两个校验位的存在,与RAID-5相比,需要读取两次校验位和写入两次校验位,所以RAID-6的惩罚值是6
计算IOPS:
根据上文的描述,在实际存储方案设计的过程中,计算实际可用IOPS的过程中必须纳入RAID的写惩罚计算。计算的公式如下:
物理磁盘总的IOPS = 物理磁盘的IOPS × 磁盘数目
可用的IOPS = (物理磁盘总的IOPS × 写百分比 ÷ RAID写惩罚) + (物理磁盘总的IOPS × 读百分比)
假设组成RAID-5的物理磁盘总共可以提供500 IOPS,使用该存储的应用程序读写比例是50%/50%,那么对于前端主机而言,实际可用的IOPS是:
(500 ×50% ÷ 4)+ ( 500 * 50%) = 312.5 IOPS
闪存荷尔蒙(FlashHormone)
实现原理
FlashHormone与宏杉科技自主研发的存储操作系统ODSP相结合,主要解决了RAID写惩罚 过多、RAID条带冲突和SSD磁盘磨损均衡等问题。
在开启FlashHormone的全闪存设备上,系统针对每次写入数据(无论是追加新写还是改写现有数 据),都会重新分配一个空间写入,无论什么类型的业务模型,所有的写数据都可以均匀的分布 到不同的硬盘上,并且可以将业务数据合并为一个满条带后一次写入。
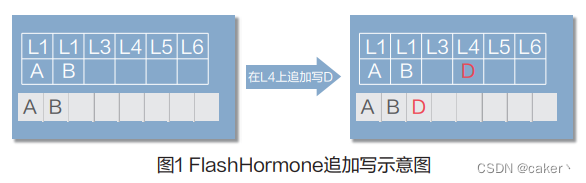
例如,在追加写时,L1和 L2上已经写入数据A和B, 当主机要在L4追加写入数 据D时,系统会新分配一个 空间写入数据D,并将地址 指向新分配的空间,如图1所示。
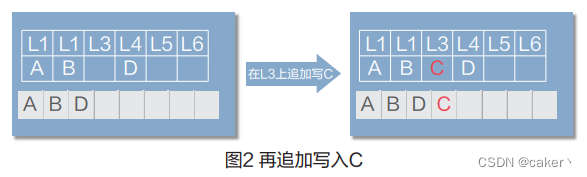
同理,再在L3追加写入C时,系统会继续分配 一个新的空间写入C,如图2所示。
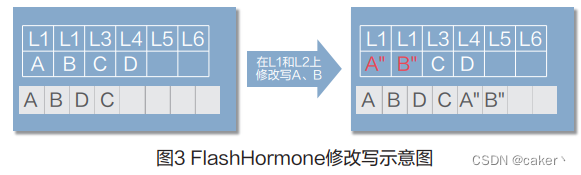
在修改写原有数据时,假设在L1和L2上修改写成A″、B″,系统会新分配空间写入A″和B″,并将地址 指向新分配给A″和B″的空间,如图3所示。同时,原数据A和B所在地址将会被标记,在系统后台会进行 统一的空间回收。
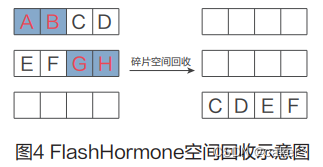
当系统不断修改之后,就会产生碎片空间,这时系统会启用一个后台进程进行非满条带空间整理,自动回 收碎片空间,释放空闲条带,从而做到数据可以一直合并成满条带写入。如图4所示,只有数据C、D、E、F 是有效数据,A、B、G、H的空间已经被标记为无效数据,这导致产生了两个非满条带空间。这时,系统 会自动将C、D、E、F重新分配空间以满条带写入,从而将两个非满条带空间释放出来得到两个可以被重 新分配的满条带空间。
FlashHormone技术优势
规避RAID写惩罚
传统RAID读写算法中,IO写流程处理可能需要多次回读和校验写,写惩罚比较多。比如RAID5的 写惩罚值为4。而使用FlashHormone技术后,写入的IO都是满条带写入在新的空白条带上,不再 需要多次回读数据重新校验再写入,避免了RAID算法写惩罚,不管是什么RAID级别,写惩罚值均 接近于1。
RAID条带零冲突
多个IO命中同一个RAID条带时,这些IO需要串行处理,这在传统RAID算法上不可避免。RAID条 带越大,IO条带冲突会更多,严重影响IO性能和延时。FlashHormone技术将每个写IO均写在新 的条带上,而不针对之前的条带进行变动,因此,也不存在某些条带发生IO冲突,条带冲突为零。
SSD负载均衡
全闪存存储系统中SSD磁盘需要保证磨损均衡,SSD的使用寿命会影响到全闪存系统的稳定性, 而传统读写算法并不考虑这一点。