Hadoop启动相关配置
文章目录
格式化节点的情况
什么情况下Hadoop需要进行格式化节点?
Hadoop需要在以下情况下格式化NameNode:
- 首次安装Hadoop:在第一次搭建和配置Hadoop集群时,需要对NameNode进行格式化。格式化操作会创建HDFS的元数据存储结构并初始化NameNode。注意,在之后的操作中,不需要再次格式化NameNode,除非要重置整个HDFS。
- 重置HDFS:如果希望重置整个HDFS,删除所有数据和元数据,那么可以重新格式化NameNode。但是注意,这将导致所有HDFS上的数据丢失。
要格式化NameNode,运行以下命令:
$HADOOP_HOME/bin/hadoop namenode -format
Hadoop启动步骤
Hadoop的启动步骤只是start-dfs.sh即可吗
start-dfs.sh脚本仅用于启动Hadoop分布式文件系统(HDFS)相关的组件,如NameNode、Secondary NameNode(如果配置了)和DataNode。运行此脚本后,HDFS服务将启动并运行。
然而,Hadoop生态系统还包括其他组件,如YARN(用于资源管理和任务调度)。要启动YARN组件,需要运行以下命令:
$HADOOP_HOME/sbin/start-yarn.sh
这将启动ResourceManager和NodeManager。
因此,为了完全启动Hadoop集群,需要运行两个脚本:start-dfs.sh和start-yarn.sh。这将启动HDFS和YARN组件。如果只关心HDFS功能,那么运行start-dfs.sh就足够了。
hdfs的web管理页面参数说明
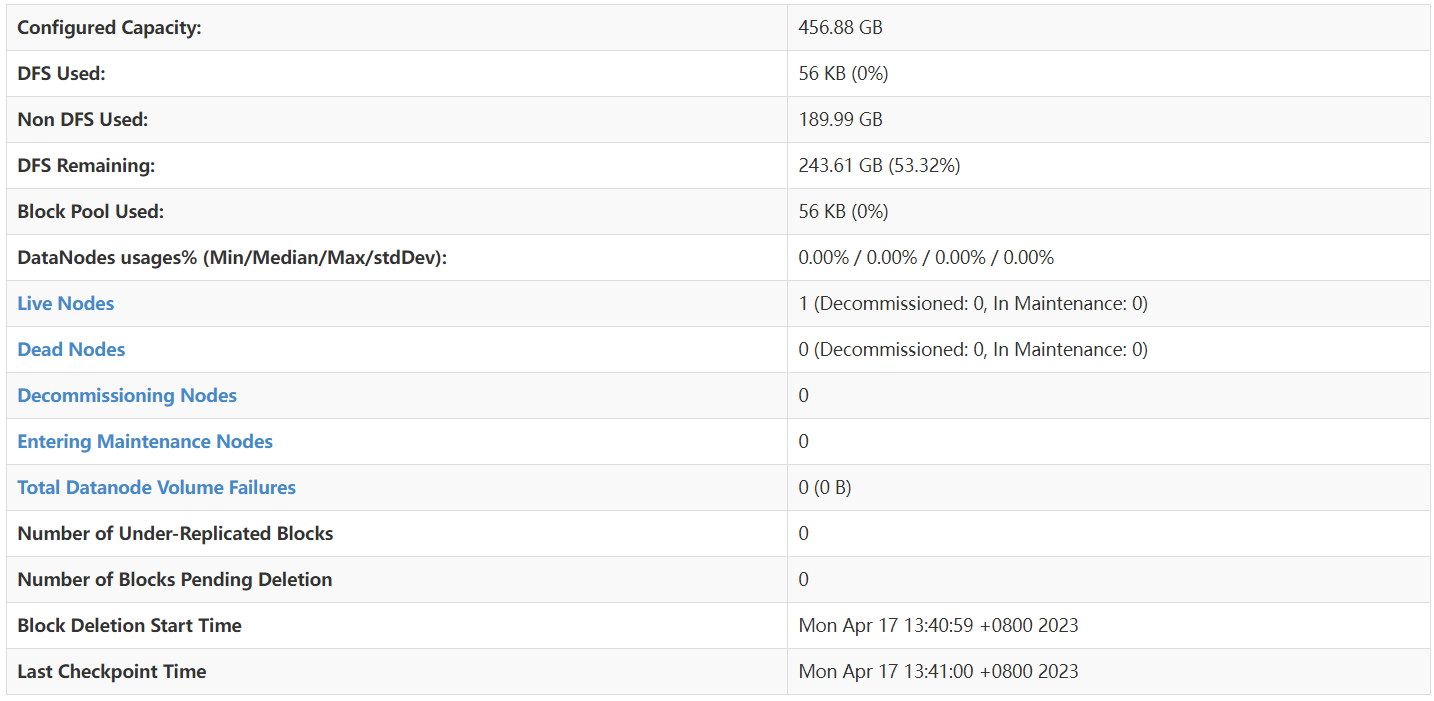
- Configured Capacity: 配置容量是HDFS集群中所有DataNode的总存储容量。在这个例子中,配置容量为456.88 GB。
- DFS Used: DFS已使用的存储空间。这是HDFS中已存储的数据量。在这个例子中,已使用56 KB。
- Non DFS Used: 非DFS已使用的存储空间。这是DataNode上用于其他目的(非HDFS)的存储空间。在这个例子中,非DFS已使用189.99 GB。
- DFS Remaining: DFS剩余的存储空间。这是HDFS集群中尚未使用的存储空间。在这个例子中,剩余243.61 GB(占配置容量的53.32%)。
- Block Pool Used: 块池已使用的存储空间。这是HDFS中已分配给块池的存储空间。在这个例子中,已使用56 KB。
- DataNodes usages% (Min/Median/Max/stdDev): DataNode使用率的统计信息,包括最小、中位数、最大和标准差。在这个例子中,所有这些值都是0.00%。
- Live Nodes: 当前运行中的DataNode数量。在这个例子中,有1个活动的DataNode(未被停用或处于维护状态)。
- Dead Nodes: 当前不可用或已宕机的DataNode数量。在这个例子中,没有死亡的DataNode。
- Decommissioning Nodes: 正在停用的DataNode数量。在这个例子中,没有正在停用的DataNode。
- Entering Maintenance Nodes: 正在进入维护状态的DataNode数量。在这个例子中,没有正在进入维护状态的DataNode。
- Total Datanode Volume Failures: 数据节点磁盘故障的总数。在这个例子中,数据节点磁盘故障为0。
- Number of Under-Replicated Blocks: 副本数量低于配置值的块数量。在这个例子中,没有低于配置值的副本。
- Number of Blocks Pending Deletion: 待删除的块数量。在这个例子中,没有待删除的块。
- Block Deletion Start Time: 块删除开始的时间。在这个例子中,块删除开始于2023年4月17日13:40:59(UTC+8)。
- Last Checkpoint Time: 最近一次检查点的时间。在这个例子中,最近的检查点发生在2023年4月17日13:41:00(UTC+8)。
参数的评价场景
- 集群健康监控:这些参数有助于监控HDFS集群的健康状况,以确保集群正常运行。例如,通过查看**"Live Nodes"和"Dead Nodes"参数,可以了解数据节点的运行状态**,从而判断集群是否正常运行。
- 存储空间管理:了解存储空间的使用情况对于集群管理至关重要。例如,通过查看"Configured Capacity"、“DFS Used”、"Non DFS Used"和"DFS Remaining"等参数,可以了解集群的存储空间使用情况,从而判断是否需要扩容或进行存储空间优化。
- 数据复制和一致性监控:某些参数有助于评估数据的复制和一致性状态。例如,"Number of Under-Replicated Blocks"表示副本数量低于配置值的块数量,这可能导致数据丢失风险增加。监控这些参数有助于确保数据的可靠性和一致性。
- 性能优化:某些参数可以帮助了解集群的性能和负载情况,例如"DataNodes usages%",可以通过这个参数了解数据节点的使用率。这些信息有助于优化集群配置,提高集群性能。
- 故障排查和恢复:在发生问题时,这些参数可以帮助识别问题的原因。例如,"Total Datanode Volume Failures"参数表示数据节点磁盘故障的总数,这可能导致数据丢失或集群性能下降。了解这些参数有助于快速诊断和解决问题。