简介
使用docx4j将多个docx文件,合并为一个docx文件,采用在文档最后一个段落追加内容的方式。
依赖
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.2</version>
</dependency>
工具方法
import org.apache.commons.io.IOUtils;
import org.docx4j.jaxb.Context;
import org.docx4j.openpackaging.exceptions.Docx4JException;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.PartName;
import org.docx4j.openpackaging.parts.WordprocessingML.AlternativeFormatInputPart;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.relationships.Relationship;
import org.docx4j.wml.CTAltChunk;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author gongl
* @date 2022-10-10
*/
public class PdfUtils {
private static final Logger log = LoggerFactory.getLogger(PdfUtils.class);
/**
* 合并word文件
* @param wordList 待合并文件集合
* @param outFilePath 输出文件路径
*/
public static void mergeDoc(List<String> wordList, String outFilePath) {
List<InputStream> streamList = new ArrayList<>();
for (String wordPath : wordList) {
try {
streamList.add(new FileInputStream(wordPath));
} catch (FileNotFoundException e) {
log.error("待合并文件流读取异常:", e);
e.printStackTrace();
}
}
try {
mergeDocStream(streamList, new FileOutputStream(new File(outFilePath)));
} catch (Exception e) {
log.error("临时文件创建异常:", e);
}
}
private static void mergeDocStream(List<InputStream> streamList, FileOutputStream out) throws Docx4JException, IOException {
WordprocessingMLPackage target = null;
final File generated = File.createTempFile("generated", ".docx");
int chunkId = 0;
for (InputStream is : streamList) {
if (is != null) {
if (target == null) {
OutputStream os = new FileOutputStream(generated);
os.write(IOUtils.toByteArray(is));
os.close();
target = WordprocessingMLPackage.load(generated);
} else {
insertDoc(target.getMainDocumentPart(), IOUtils.toByteArray(is), chunkId++);
}
}
}
if (target != null) {
target.save(generated);
FileInputStream fileInputStream = new FileInputStream(generated);
saveTemplate(fileInputStream, out);
}
}
private static void insertDoc(MainDocumentPart mainDocumentPart, byte[] bytes, int chunkId) {
try {
PartName partName = new PartName("/part" + chunkId + ".docx");
AlternativeFormatInputPart afiPart = new AlternativeFormatInputPart(partName);
afiPart.setBinaryData(bytes);
Relationship relationship = mainDocumentPart.addTargetPart(afiPart);
CTAltChunk chunk = Context.getWmlObjectFactory().createCTAltChunk();
chunk.setId(relationship.getId());
mainDocumentPart.addObject(chunk);
} catch (Exception e) {
log.error("文件合并临时文件异常:", e);
}
}
private static void saveTemplate(InputStream targetStream, FileOutputStream out) {
int byteread;
try {
byte[] buffer = new byte[1024 * 10];
while ((byteread = targetStream.read(buffer)) != -1) {
out.write(buffer, 0, byteread);
}
targetStream.close();
out.close();
} catch (IOException e) {
log.error("生成文件异常:", e);
}
}
}
测试用例
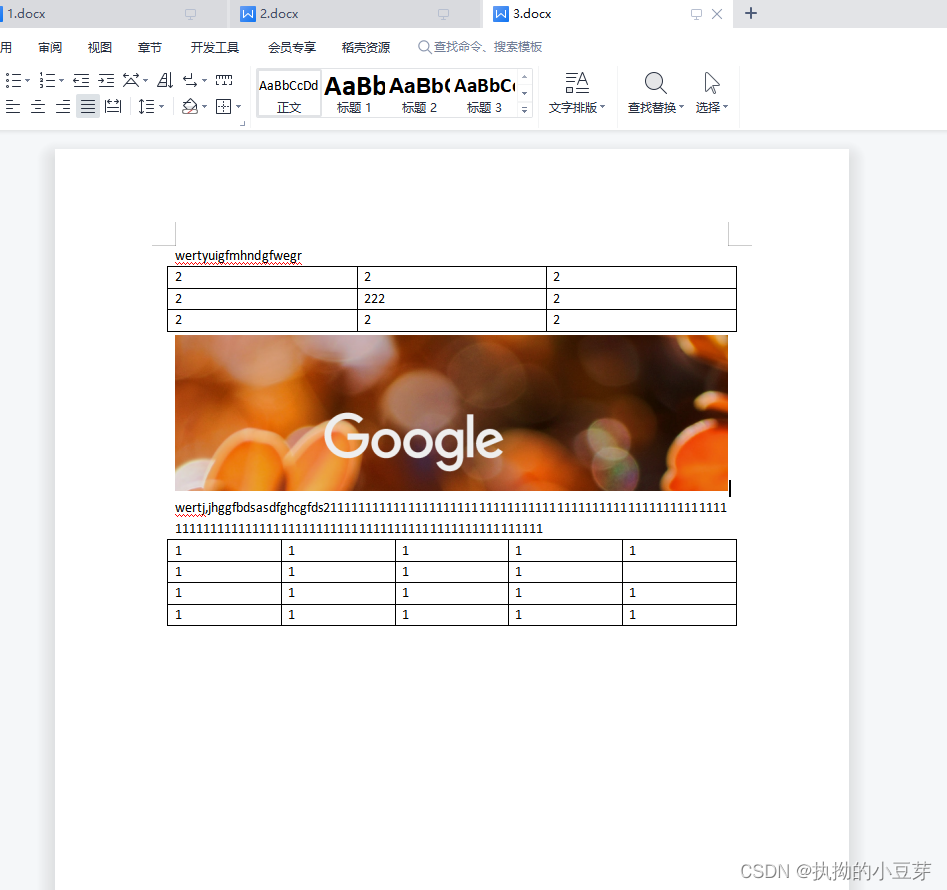
先创建两个docx文件:2.docx和1.docx
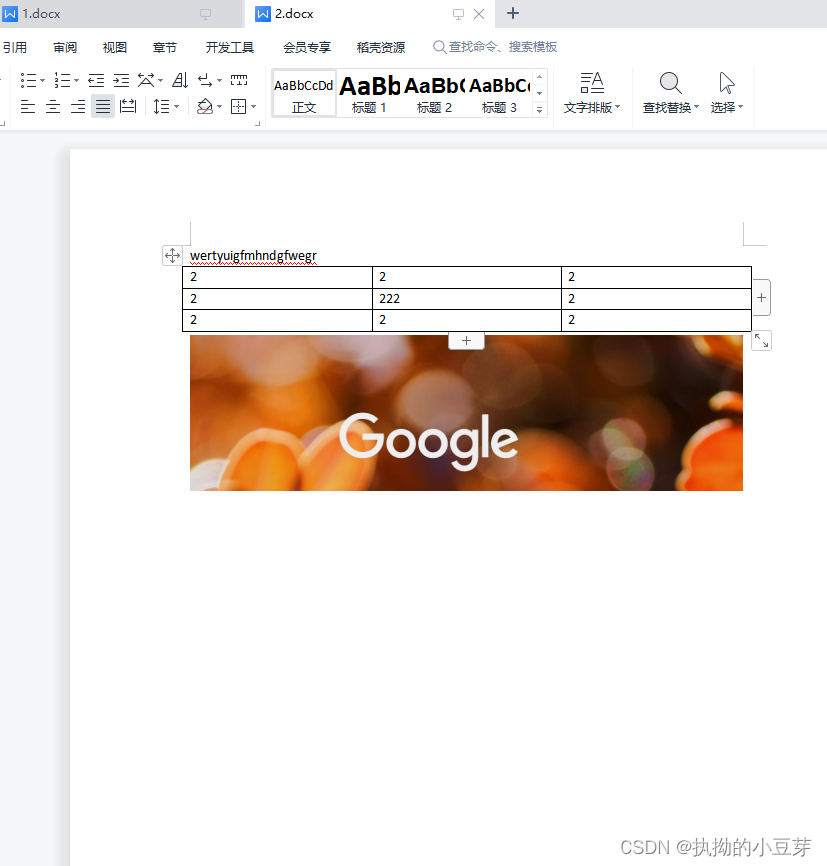
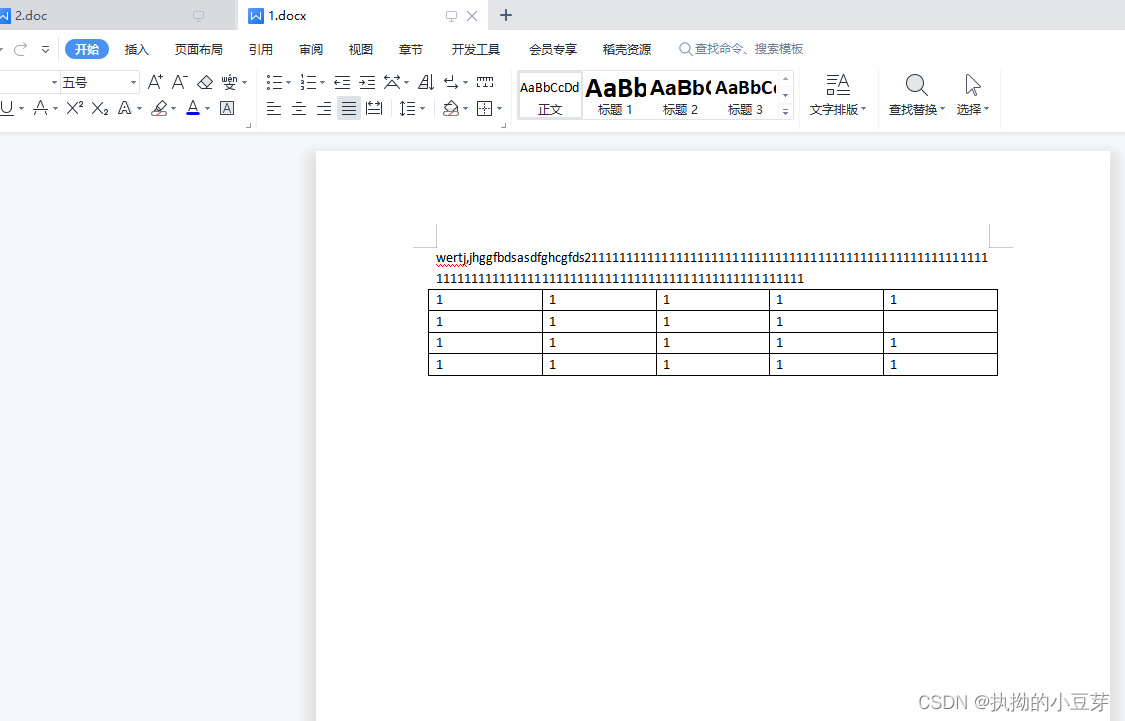
执行代码合并为3.docx
public static void main(String[] args) {
mergeDoc(Arrays.asList("C:\\Users\\E490\\Desktop\\2.docx", "C:\\Users\\E490\\Desktop\\1.docx"),
"C:\\Users\\E490\\Desktop\\3.docx");
}
结果如下图