1. 业务场景
1)查询慢。当时工单数据库里面有1000万左右的客服工单时,每次查询时需要关联其他近10个表,一次查询平均花费13秒左右。
2)打开工单慢。工单打开以后需要调用多个接口,分别将用户信息、订单信息以及其他客服创建的单据信息列出来(如退款、赔偿、充值、投诉等)。打开工单详情页需要近5秒。
之前针对于大量数据的问题使用过冷热分离的方案,但是进一步调研以后才发现,还有个工单类型转换的场景,即原本客户只是咨询,沟通中发现了问题,然后就转投诉了,但是系统设计的功能中,是不能修改工单类型的。也就是说,有些客服工单表面上只是咨询,其实是投诉。
所以考虑查询分离:即将更新的数据放在主数据库里,而查询的数据放在另外一个专门针对搜索的存储系统里。
2. 查询分离简介
何为查询分离?
查询分离即每次写数据时保存一份数据到其他的存储系统里,用户查询数据时直接从中获取数据。
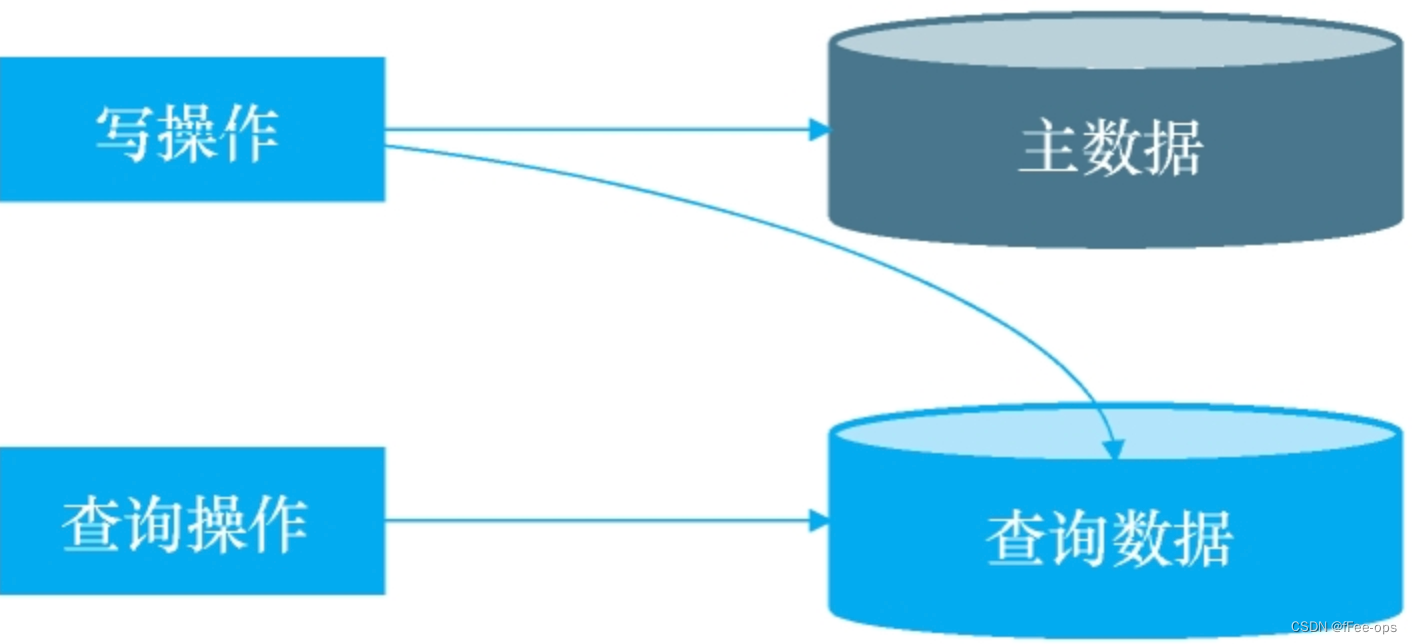
何种场景下使用查询分离?
1)数据量大:比如单个表的行数有上千万,当然,如果几百万就出现查询慢的问题,也可以考虑使用。2)查询数据的响应效率很低:因为表数据量大,或者关联查询太过复杂,导致查询很慢的情况。
3)所有写数据请求的响应效率尚可:虽然查询慢,但是写操作