segmentation后
mask二值图片数据转换成coco对应的json格式
import os, json, numpy as np
from tqdm import tqdm
from imantics import Mask, Image, Category, Dataset
import cv2
dataset = Dataset('foot') # 先定义一个数据库对象,后续需要往里面添加具体的image和annotation
path1 = r'\\10.214.150.97\Public\datasets\real_foot\real_foot_2021_03' # image对应的mask的文件路径
for index, j in enumerate(tqdm(os.listdir(path1))):
if str(j)[-1] == 'r' or str(j)[-1] == 'l':
path = os.path.join(path1, j, 'masks')
if not os.path.exists(path):
path = os.path.join(path1, j, 'mask')
for index, i in enumerate(tqdm(os.listdir(path))):
mask_file = os.path.join(path, i)
name = i.split('.')[0]
file = os.path.join(path1, j, '{}.jpg'.format(name))
image = cv2.imread(file)[:,:,::-1]
image = Image(image, id=index+1) # 定义一个Image对象
image.file_name = '{}.jpg'.format(name) # 为上面的Image对象添加coco标签格式的'file_name'属性
image.path = file # 为Image对象添加coco标签格式的'path'属性
mask = cv2.imread(mask_file, 0)
ret, mask = cv2.threshold(mask, 0, 255, cv2.THRESH_BINARY)
t = cv2.imread(file)
if t.shape[:-1] != mask.shape:
h, w, _ = t.shape
mask = cv2.resize(mask, (w, h), cv2.INTER_CUBIC)
mask = Mask(mask) # 定义一个Mask对象,并传入上面所定义的image对应的mask数组
categ = 'foot'
t = Category(categ) # 这里是定义Category对象
t.id = 1
image.add(mask, t) # 将mask信息和类别信息传给image
dataset.add(image) # 往dataset里添加图像以及gt信息
t = dataset.coco() # 将dataset转化为coco格式的,还可以转化为yolo等格式
with open('foot.json', 'w') as output_json_file: # 最后输出为json数据
json.dump(t, output_json_file)
转出来之后的json数据中segmentation部分会有一些问题,它不是一个1 * n维度的数据 而是包含了很多段,需要合并
如图:
合并之前:

合并之后,所有的边缘点在一个list中:

最终转好的格式如下图:

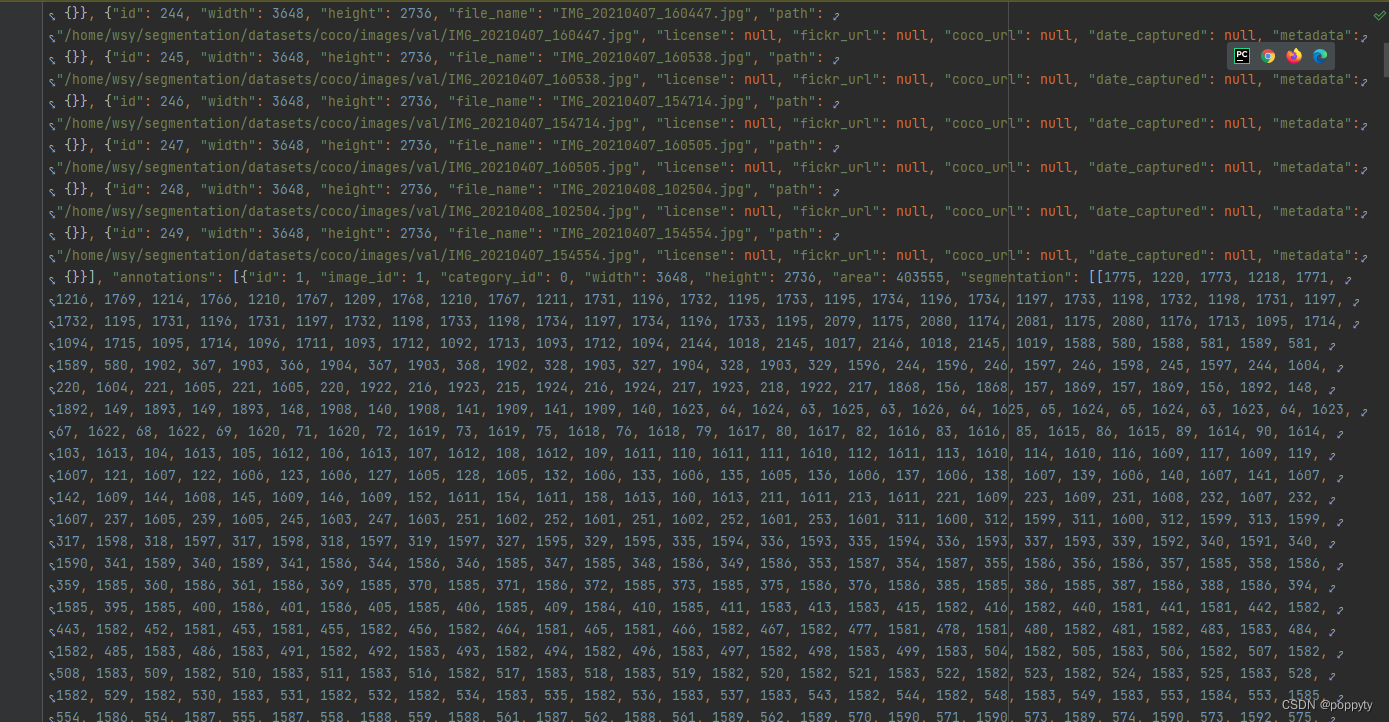
合并代码:
import os
import json
import numpy as np
from tkinter import _flatten
with open('foot1.json','r') as f:
load_dict = json.load(f)
list1 = load_dict["annotations"]
for i in range(0, len(list1)):
a = list(_flatten(list1[i]["segmentation"]))
b = np.asarray(a).reshape(1, len(a)).tolist()
load_dict["annotations"][i]["segmentation"] = b
# print(len(list1))
# print(np.asarray(list1).shape)
with open("test.json",'w',encoding='utf-8') as f:
json.dump(load_dict, f,ensure_ascii=False)